Ontology Alignment at the Instance and Schema Level
Texte intégral
Figure
![Table 1: Results (precision, recall, F-measure) of instance, class, and relation alignment on OAEI datasets, compared with ObjectCoref [16]](https://thumb-eu.123doks.com/thumbv2/123doknet/8025515.268950/18.892.194.804.222.304/results-precision-instance-relation-alignment-datasets-compared-objectcoref.webp)


Documents relatifs
- In-vivo: Students enrolled in a course use the software tutor in the class room, typically under tightly controlled conditions and under the supervision of the
The CCITT V.22 standard defines synchronous opera- tion at 600 and 1200 bit/so The Bell 212A standard defines synchronous operation only at 1200 bit/so Operation
The purpose of this study is to investigate and analyze Azeri translation of English extraposition constructions involving copular verbs and followed by that–clause and
Current political developments in Nepal, India, Pakistan and China Ind the implications of these developments for resea rch carried out by European scholars.. The
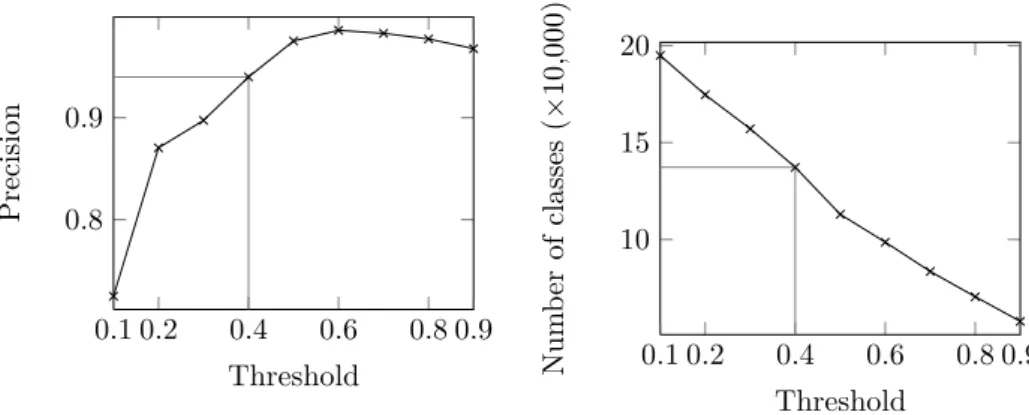
be further noted that, unlike all other approaches, paris did not even know that the relations and classes were identical, but discovered the class and relation equivalences by
It should be further noted that, unlike all other approaches, paris did not even know that the relations and classes were identical, but discovered the class and relation
The winding number of a closed curve around a given point is an integer representing the total number of times that curve travels anti-clockwise around the point.. The sign of
Dr Fortin thanks the patients and co-investigators of the Saguenay group associated with the Research Chair on Chronic Diseases in Primary Care.. Competing interests None
