Analyse de sensibilité d'un multimodèle hydrologique
Texte intégral
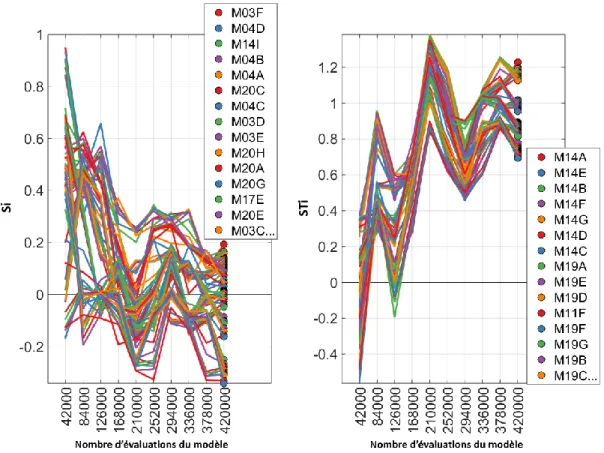
Figure

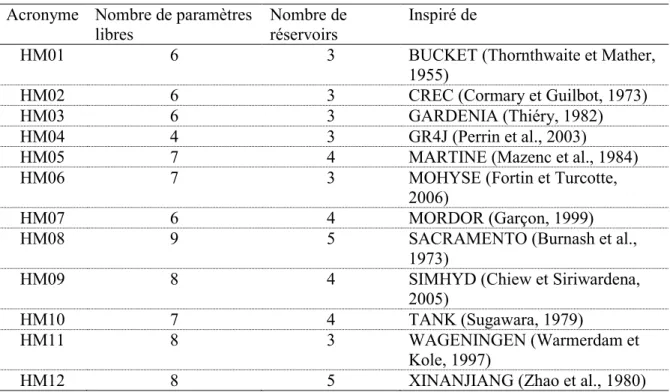
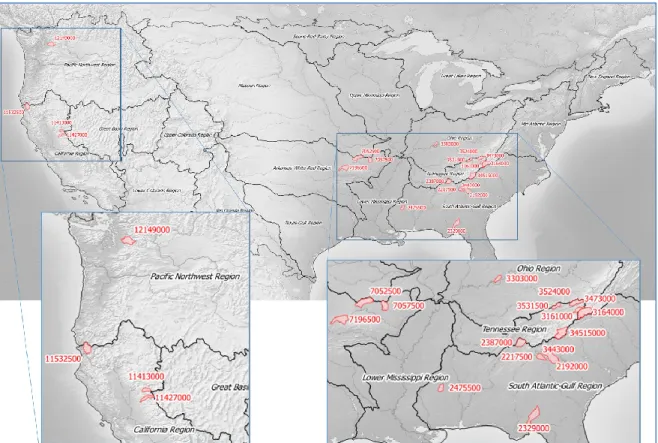



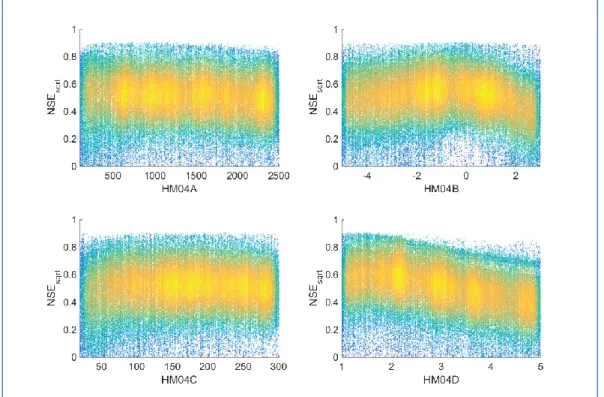

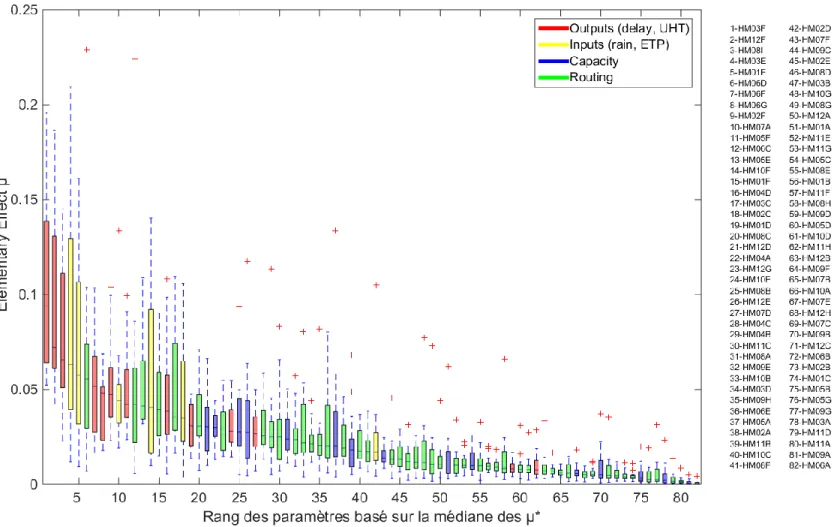
Documents relatifs
Les résultats obtenus sont très encourageants et plaident pour une utilisation accrue de l’approche variationnelle afin d’aborder les problématiques clés que sont l’analyse de
Le but de ce papier est de d´eterminer, en effectuant une analyse de sensibilit´e globale, les param`etres influents dans deux mod`eles permettant de d´ecrire l’interaction pneu/sol,
Figure 4 - Relations between topographic index and soil properties, Rochereau watershed.. Figure 5 - La Moine, relations entre les classes d’indice topographique et les propriétés
1.4.5 Redu ing the number of fun tion alls : use of importan e sampling methods 57 1.4.6 Lo al polynomial estimation for rst-order Sobol' indi es in a reliability on-
L’analyse de sensibilit´ e est souvent un crit` ere de s´ election des param` etres ` a esti- mer dans la mod´ elisation des ph´ enom` enes agronomiques et environnementaux et il
Dans ce papier, une approche d’analyse de sensibilit´e pour des mod`eles de type boˆıte noire, pr´esentant des param`etres qui suivent une distribution arbitraire a ´et´e
Introduction The Orb case-study Spatial inputs Scale issues General conclusion.. Spatially
L’analyse de sensibilit´ e est souvent un crit` ere de s´ election des param` etres ` a esti- mer dans la mod´ elisation des ph´ enom` enes agronomiques et environnementaux et il
