CONTRIBUTIONS
A
LA DETECTION DES ANOMALIES ET AU
DEVELOPPEMENT DES SYSTEMES DE RECOMMANDATION
par
Wu Shu
These presentee au Departement d’informatique en vue de Tobtention du grade de Philosophic Doctor (Ph.D.)
FACULTE DES SCIENCES UNIVERSITE DE SHERBROOKE
1+1
Library and Archives Canada Published Heritage Branch Bibliotheque et Archives Canada Direction du Patrimoine de I'edition 395 Wellington Street Ottawa ON K1A0N4 Canada 395, rue Wellington Ottawa ON K1A 0N4 CanadaYour file Votre reference ISBN: 978-0-494-93263-6 Our file Notre reference ISBN: 978-0-494-93263-6
NOTICE:
The author has granted a non
exclusive license allowing Library and Archives Canada to reproduce, publish, archive, preserve, conserve, communicate to the public by
telecomm unication or on the Internet, loan, distrbute and sell theses
worldwide, for commercial or non commercial purposes, in microform, paper, electronic and/or any other formats.
AVIS:
L'auteur a accorde une licence non exclusive permettant a la Bibliotheque et Archives Canada de reproduire, publier, archiver, sauvegarder, conserver, transmettre au public par telecomm unication ou par I'lnternet, preter, distribuer et vendre des theses partout dans le monde, a des fins com merciales ou autres, sur support microforme, papier, electronique et/ou autres formats.
The author retains copyright ownership and moral rights in this thesis. Neither the thesis nor substantial extracts from it may be printed or otherwise reproduced without the author's permission.
L'auteur conserve la propriete du droit d'auteur et des droits moraux qui protege cette these. Ni la these ni des extraits substantiels de celle-ci ne doivent etre imprimes ou autrement
reproduits sans son autorisation.
In compliance with the Canadian Privacy A ct some supporting forms may have been removed from this thesis.
W hile these forms may be included in the document page count, their removal does not represent any loss of content from the thesis.
Conform em ent a la loi canadienne sur la protection de la vie privee, quelques
form ulaires secondaires ont ete enleves de cette these.
Bien que ces form ulaires aient inclus dans la pagination, il n'y aura aucun contenu manquant.
C O NTR IBUTIO N S TO O U TLIER D ET EC TIO N A ND
RECOM M ENDATION SYSTEM S
Shu Wu
Faculte des Sciences
Universite de Sherbrooke
A thesis subm itted for th e degree of
D octor o f P hilosophy
Le 20 juillet 2012
le jury a accepte la these de Monsieur Shu Wu dans sa version finale.
Membres du jury
Professeur Shengrui Wang Directeur de recherche Departement d’informatique
Professeur Andre Mayers Evaluateur interne Departement d’informatique
Professeur Philippe Foumier-Viger Evaluateur exteme
Departement d’informatique Universite de Moncton
Professeur Ernest Monga President rapporteur Departement de mathematiques
A ck n o w led g em en ts
F irst and foremost, I would like to th an k my supervisor Professor Shengrui Wang for his dedicated supervision during my Ph.D . study. I have benefited so much in my research from the inspiration, m otivation and encouragement th a t Prof. Wang constantly provided. He introduced me to the research field of outlier detection and recom m endation systems which really m atched my skill-set and interest. I also like to thank him for giving me the abundant freedom to explore various research directions. Working w ith him was really memorable and fun experience.
I was partly supported by the Ph.D. Scholarship program of the C hina Scholar ship Council (CSC) during my studies at the Universite de Sherbrooke. P a rt of the research work reported in this thesis was funded by Discovery and Discovery Accel erator Supplements programs of N atural Sciences and Engineering Research Council of C anada (NSERC) granted to Prof. Shengrui Wang. I would like to express my sincere thanks to NSERC and CSC.
I would also like to thank m y com m ittee president Dr. Ernest Monga, com m ittee members, Dr. Andre Mayers, Dr. Philippe Fournier-Viger, and Dr. Shengrui Wang for their tim e and their feedback on my thesis. T heir reviews and com m ents are really helpful to improve the thesis.
I would like to thank all my colleagues and friends in Prospectus Lab and in Universite de Sherbrooke for sharing the good tim e in Sherbrooke.
Finally, I would like to thank my parents and my brother for their endless encour agement and belief in me.
S om m aire
Le forage de donnees, appele egalement “Decouverte de connaissance dans les bases de donnees” , est un jeune domaine de recherche interdisciplinaire. Le forage de donnees etudie les processus d ’analyse de grands ensembles de donnees pour en extraire des connaissances, et les processus de transform ation de ces connaissances en des struc tures faciles a comprendre et a utiliser par les humains. C ette these etudie deux taches im portantes dans le domaine du forage de donnees : la detection des anomalies et la recom m andation de produits. La detection des anomalies est l ’identification des donnees non conformes aux observations normales. La recom m andation de produit est la prediction du niveau d ’interet d ’un client pour des produits en se basant sur des donnees d ’achats anterieurs et des donnees socio-economiques. Plus precisement, cette these porte sur 1) la detection des anomalies dans de grands ensembles de donnees de type categorielles; et 2) les techniques de recom m andation a p artir des donnees de classements asymetriques.
La detection des anomalies dans des donnees categorielles de grande echelle est un probleme im portant qui est loin d ’etre resolu. Les methodes existantes dans ce domaine souffrent d ’une faible efficience et efficacite en raison de la dim ensionnalite elevee des donnees, de la grande taille des bases de donnees, de la complexity elevee des tests statistiques, ainsi que des mesures de proximite non adequates. C ette these pro pose une definition formelle d ’anomalie dans les donnees categorielles ainsi que deux algorithmes efficaces et efficients pour la detection des anomalies dans les donnees de grande taille. Ces algorithmes ont besoin d ’un seul param etre : le nom bre des anom a lies. Pour determ iner la valeur de ce param etre, nous avons developpe un critere en nous basant sur un nouveau concept qui est l’holo-entropie.
Plusieurs recherches anterieures sur les systemes de recom m andation ont neglige un type de classements repandu dans les applications Web, telles que le commerce electronique (ex. Amazon, Taobao) et les sites fournisseurs de contenu (ex. YouTube). Les donnees de classements recueillies par ces sites se differencient de celles de classe ments des films et des musiques par leur distribution asym etrique elevee. C ette these propose un cadre mieux adapte pour estim er les classements et les preferences quan- titatives d ’ordre superieur pour des donnees de classements asymetriques. Ce cadre perm et de creer de nouveaux modeles de recom m andation en se basant sur la fac torisation de m atrice ou sur l’estim ation de voisinage. Des resultats experim entaux sur des ensembles de donnees asymetriques indiquent que les modeles crees avec ce cadre ont une meilleure performance que les modeles conventionnels non seulement pour la prediction de classements, mais aussi pour la prediction de la liste des T o p -N produits.
A b stra ct
D ata mining, also called Knowledge Discovery in Databases, is a relatively young and interdisciplinary research field of com puter science. It is the process of analyzing large-scale datasets, extracting knowledge, and then transform ing this knowledge into a hum an-understandable structure for further use. O utlier detection and recommen dation systems are two im portant tasks in d a ta mining. Outlier detection refers to detecting observations in a given d ataset th a t do not conform to norm al observations, while recommendation systems try to predict user’s preference tow ards item s from historic d a ta of purchase and other related socio-economic d ata of th e users. The m ain focus of this thesis is to study two key issues in outlier detection and recom m endation systems: outlier detection from (or in) large-scale categorical datasets and recommendation systems from highly-skewed rating datasets.
Detecting outliers in large-scale categorical datasets is a very im portant and open significant topic in outlier detection. Existing methods in this area suffer from low ef fectiveness and low efficiency due to high dimensionality and large size of the datasets, high-complexity of statistical tests or inefficient proximity-based measures. In this thesis, we provide a formal definition of outlier in the categorical datasets, and design two effective and efficient algorithms with only one param eter for th e task of outlier detection in large-scale categorical datasets.
Previous research on recommendation system s has neglected one significant rating scenario, which broadly exists in m any real Web applications, such as e-commerce (e.g. Amazon, Taobao) and content provider websites (e.g. Youtube). T he rating d atasets collected from these websites have different characteristics from the traditional movie and music rating datasets. Their ratings distributions are with high skewness. After
examining the properties of this kind of rating datasets, we propose a new fram e work for estim ating rating and quantitative high-order preference for skewed rating datasets. This framework allows to generate novel and more effective m atrix fac torization and neighborhood models. Experim ental results on typical highly-skewed datasets show th a t new models created under this framework can generate b e tter performance th an the conventional m ethods on th e skewed rating d atasets for not only rating prediction b u t also for T o p -N recom m endation.
C o n ten ts
A ck n o w led g em en ts i S om m aire iii A b str a c t v 1 I n tr o d u c tio n 1 1.1 O utlier D e te c tio n ... 1 1.1.1 Approaches of Existing M e th o d s ... 31.1.2 Classification of Unsupervised O utlier Detection M ethods . . . 4
1.2 Recomm endation S y s t e m s ... 6 1.2.1 Collaborative F i l t e r i n g ... 8 1.2.2 Content-based Filtering ... 12 1.2.3 Hybrid A p p r o a c h ... 13 1.2.4 Evaluation M e t r i c s ... 14 1.3 C ontribution of this T h e s is ... 16 1.3.1 Contributions to O utlier D e t e c t i o n ... 16
1.3.2 Contributions to Recom m endation Systems ... 17
2 O u tlier D e te c tio n in L arge-scale C a teg o rica l D a ta 21 2.1 Introduction ... 23
2.1.1 Unsupervised Categorical O utlier D e t e c t i o n ... 25
2.1.2 Objectives and C o n tr ib u tio n s ... 26
2.2.1 Proxim ity-based M e t h o d s ... 27
2.2.2 Rule-based M e t h o d s ... 28
2.2.3 Inform ation-theoretic M e th o d s ... 29
2.2.4 O ther M e t h o d s ... 29
2.3 M easurement for O utlier D e t e c t i o n ... 30
2.3.1 Entropy and Total C o rre la tio n ... 30
2.3.2 Holo-entropy ... 32
2.3.3 A ttrib u te W e i g h t i n g ... 34
2.3.4 A Formal Definition of the O utlier D etection P ro b le m ... 36
2.4 New Outlier D etection A lg o rith m s... 37
2.4.1 A New Concept of the O utlier F a c t o r ... 38
2.4.2 U pdating the O utlier F a c t o r ... 41
2.4.3 Upper Bound on Outliers ... 42
2.4.4 ITB-SP and ITB-SS A lg o rith m s ... 43
2.5 E x p e rim e n ts... 45
2.5.1 Com pared M ethods and Experim ent Outline ... 46
2.5.2 Effectiveness T e s t ... 47
2.5.3 Efficiency Test ... 53
2.6 C onclusion ... 55
3 R a tin g and P refere n c e F ram ew ork for H ig h ly S k ew ed U ser R a tin g D a ta se ts 57 3.0.1 User-specific Highly Skewed Rating D istribution... 60
3.0.2 Objectives and contributions... 64
3.1 Related W o r k ... 67
3.1.1 Approaches for Recommender S y s t e m s ... 67
3.1.2 Classic Work on CF ... 68
3.1.3 Related Work on T o p -N Recom m endation... 70
3.2 Rating and Preference (RP) F ram ew ork... 71
3.2.1 Rating and Q uantitative Pairwise P re fe re n c e ... 71
3.2.3 R P Learning Algorithm ( L e a r n R P ) ... 74
3.3 Learning models with R P ... 75
3.3.1 M atrix Factorization Approach ... 76
3.3.2 Neighborhood A p p r o a c h ... 78
3.4 Experim ents and analysis ... 79
3.4.1 Experim ent D e s i g n ... 80 3.4.2 Convergence R a t e ... 83 3.4.3 Effectiveness Analysis ... 83 3.4.4 Im pact of Coefficient a ... 89 3.4.5 Efficiency A n a l y s i s ... 92 3.5 C o n clu sio n ... 94
4 C o n clu sio n and F u tu re W ork 95
L ist o f F igu res
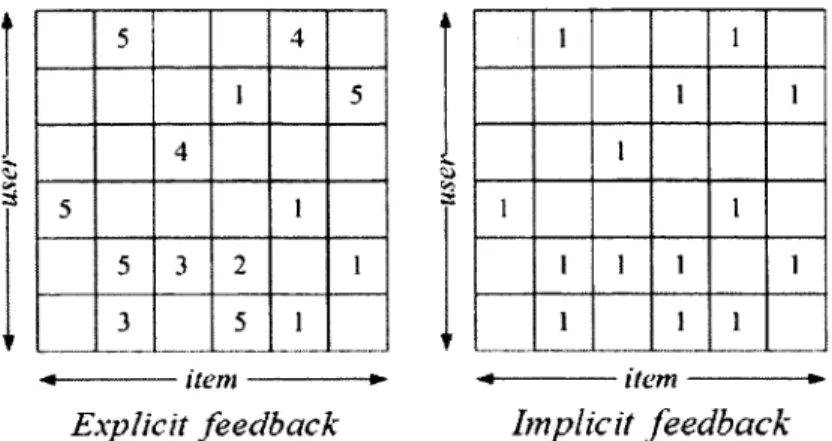
1.1 Examples of two different user feedbacks illustrated in the user-item matrixes. Explicit user feedback is listed in the left m atrix, and implicit feedback is dem onstrated in the right m atrix ... 7
2.1 Entropy, Total Correlation and Holo-entropy for Outlier D etection . . 34
2.2 G raph Drawing of the Synthetic D a t a s e t ... 49
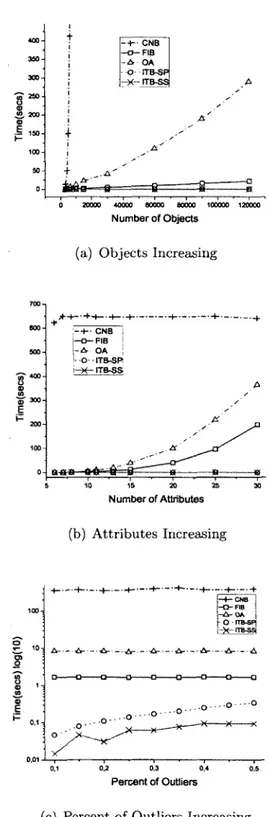
2.3 Results of Efficiency Test on Synthetic D a t a s e t s ... 54
3.1 The average user-specific rating distributions of Netflix, Movielens 10M, Movielens 1M and Epinions, Amazon, Ciao datasets. T he average skewness of these datasets is (5= 0.6023), (<S=0.5647), (5=0.5536), (5=1.7014), (5=1.3387), (5=0.7214) respectively... 63
3.2 G raphical representation of the R P framework. On the left side, the shaded regions are the observed rating set R t and th e personalized pairwise preference Rn. The transform ation rule from R t to R n is in dicated implicitly. The right side shows the predicted datasets. The middle p art of this figure represents the rating metric M t of O ptRP, which trains the model from R t , and the personalized pairwise prefer ence m etric M n, which trains from Rn . These two metrics compose our new O ptR P criterion M c. LearnR P can be used to tra in CF models w.r.t. O p tR P ... 76
3.3 Empirical comparison of th e convergence of M F and M F-R P on the Epinions and Amazon datasets, w ith / = 1 0 ... 83
3.4 Prediction accuracy and rank accuracy of M F-RP on the Epinions dataset, m easured by R M S E (a = 0, 0.0001, 0.001, 0.01, 0.1, 0.2, 0.5 and 1) and N D C G respectively, w ith varying coefficient a ... 90 3.5 Efficiency results of models in the M F group w ith / = 10... 92
C h a p ter 1
In tro d u ctio n
D ata mining is a relatively young research field of com puter science. Utilizing m ethods at the intersection of artificial intelligence, machine learning, statistics, and database systems, d a ta mining aims to ex tract knowledge from trem endous d a ta and tra n s form it into a hum an-understandable stru ctu re for further use. O utlier detection and recom m endation systems are two fundam ental tasks in this research area. In this chapter, we will review the background of these two tasks.
The stru ctu re of our introduction is as follows. Section 1 focuses on discussion of outlier detection, including outlier definitions, outlier detection’s applications, clas sification of existing methods, and evaluation metrics. Section 2 describes the basic concepts about recommendation systems including classification of existing methods, background and classification of collaborative filtering, as well as evaluation metrics. Finally, we conclude this chapter w ith a discussion of the contributions of this thesis on outlier detection and recommendation systems, and provide th e related publication list of th e author. The m aterials in this chapter help to understand the subsequent chapters of this thesis.
1.1
O u tlie r D e t e c t io n
T he datasets collected from the real world always suffer from unusual observations [34]. These unusual objects may be “due to several factors, including: ignorance
and hum an errors, rounding errors, transcription error, inherent variability of the domain, instrum ent malfunction and biases” [34]. These observations m ay affect the application of an advanced d a ta analysis m ethod, b ut may also indicate interesting phenomena or findings resulted from rare but correct actions/behaviour, and m otivate further investigation.
Outlier detection is an im portant and challenging task th a t has been tre a te d w ithin diverse domains and research areas such as statistics, machine learning, d a ta mining, information theory [22, 52, 23, 117]. Generally, in d a ta mining, outlier detection refers to the problem of finding and, where appropriate, removing objects in a d ataset which are considerably dissimilar, exceptional and inconsistent w.r.t. th e m ajority of objects in a dataset [6]. These non-conforming objects are called outliers, also referred to as anomalies, surprises, aberrations, exceptions, surprises, novelties, peculiarities, contam inants, etc, in different domains [6, 22], Correspondingly, th e problem of identifying unusual observations is nam ed as outlier detection, novelty detection, anomaly detection, noise detection, deviation detection or exception mining [22].
The term outlier originally stems from the field of statistics [52], Previous work in statistics, machine learning and d a ta mining, has proposed several definitions for an outlier, b u t seemingly there does not exist a universally accepted definition [6]. Here, we list some classical definitions of an outlier or outliers
D efin itio n 1. (Hawkins’ definition [45]) ^4n outlier is an observation, which deviates so much from other observations as to arouse suspicions that it was generated by a different mechanism.
D efin itio n 2. (G rubbs’ definition) [38] A n outlying observation, or outlier, is one that appears to deviate markedly from other members o f the sample in which it occurs. D efin itio n 3. (Definition of B arnett and Lewis) [123] A n outlier is an observation
(or subset o f observations) which appears to be inconsistent with the remainder o f that set of data.
D efin itio n 4. (Definition of Moore and M cCabe) [91] A n outlier is an observation that lies outside the overall pattern o f a distribution.
D e fin itio n 5. (Definition of Aggarwal and Yu) [6] Outliers m ay be considered as noise points lying outside a set o f defined clusters, or alternatively outliers m ay be defined as the points that lie outside o f the set o f clusters but are also separated from the noise.
These definitions capture th e meaning of outliers from a general point of view. Then; are many other definitions of outliers [64, 92, 49], which are dependent on particular detection methods.
O utlier detection not only can be im plem ented as a pre-processing step prior to the application of an advanced d a ta analysis m ethod, but also can be used as an effective tool to discover interest p attern s such as the expense behavior of a to-be- bankrupt credit cardholder. T he process of outlier detection is an essential step in a variety of practical applications including intrusion detection [71], health sys tem m onitoring [52] and criminal activity detection in E-commerce [8], and can also be used in scientific research for d a ta analysis and knowledge discovery in biology, chemistry, astronomy, oceanography and other fields [52]. There are is some typical applications, e.g. fraud detection, intrusion detection, fault diagnosis, satellite image analysis, medical condition monitoring, public health monitoring, etc [52].
1.1.1
A p p roach es o f E x istin g M eth o d s
According to [22, 52], if the existing m ethods for outlier detection are classified accord ing to the availability of labels in the training datasets, there are three fundam ental categories: supervised, semi-supervised and unsupervised approaches. The general idea of three broad categories of outlier detection techniques are discussed below.
The supervised approach makes an assum ption th a t the dom ain knowledge on both normal and abnorm al d a ta exists and can be used to build a classification model. This approach learns classifier from the labelled objects and assigns appropriate labels to test objects. If a test object lies in a region of norm ality it is classified as normal, otherwise it is flagged as an outlier. Sometimes, this classification problem may be highly imbalanced, and m ay contain m ultiple normal a n d /o r abnorm al classes. The supervised approach to outlier detection has been studied extensively and many
m ethods have been developed [39, 13, 119, 108, 35, 57].
The semi-supervised approach [134, 40] constructs a model representing normal behavior from a given training dataset of normal objects, and then com putes the likelihood of a test o b ject’s being generated by this model. This semi-supervised approach is more applicable th an th e previous approach since only labelled normal objects are required. However, this approach tends to classify previously unseen normal objects as outliers, causing high false alarm rate.
Requiring no prior knowledge of the dataset, the unsupervised outlier detection approach detecting outliers in an unlabeled d ataset [10, 6, 110, 127, 76] is based on the assum ption th a t the m ajority of objects in this d ataset are normal. This approach is more widely applicable and popular, as in most applications there are no training d a ta available. The remainder of this section is devoted for the classification of the unsupervised approach, since the unsupervised scenario is our focus in this thesis.
1.1.2
C lassification o f U n su p e rv ised O u tlier D e te c tio n M e th
od s
Unsupervised approach to outlier detection encompasses a broad spectrum of tech niques, drawn from the full gam ut of com puter science and statistics. The exist ing detection m ethods in this approach prim arily can be classified into four groups: statistics-based methods, clustering-based m ethods, distance-based m ethods and density- based m ethods [43]. Since C hapter 2 provides detailed review on the unsupervised m ethods of categorical datasets, here we focus on th e im portant m ethods of numerical datasets. The detailed introduction about these four groups is given as follows.
In a typical statistics-based m ethod, the normal objects are assumed to follow a known distribution, e.g. Gaussian, Poisson, etc., and outliers deviate strongly from this distribution. If the underlying distribution is not known, a searching process is required to find out the best distribution to fit w ith the dataset. But this process is very tim e consuming and does not always work, especially for d a ta th a t come from different sources w ith different distributions. Furtherm ore, for many applications, the underlying distribution is unknown [124]. Overall, statistics-based techniques
are simple in principles, but inapplicable for d a ta with more th a n three dimensions. Related work about statistics-based m ethods can be found in [13].
Clustering-based m ethods are based on the assum ption th a t norm al d a ta points belong to large and dense clusters while outliers do not. The typical framework of such m ethods can be described as: performing a clustering process on the dataset; analyzing the obtained clusters to assess their significance; outputting outliers which are objects th a t do not fit into any clusters or belong to clusters w ith low membership. Usually outliers lack formal definition in the clustering-based approach, and are by products of clustering. This limits capabilities of clustering-based m ethod in providing intuition on the detected results. Some examples of this category can be found in [39, 40, 6, 47],
Distance-based outlier detection m ethods generally exploit distances of objects to their corresponding neighborhood in a dataset. These methods use a candidate’s average distance to its k nearest neighbours [11] (or alternatively, th e distance to its
kth. nearest neighbour [98]) as the anomalous score and return the top few objects
in a dataset whose score is the highest. These m ethods also can simply count the total num ber r-neighbours, i.e. the num ber of d a ta points within th e distance r, of each object [64], Normally, distance-based m ethods do not assume any distribution of the dataset as statistical techniques do, but suffer expensive com putational cost of searching nearest neighbourhood.
Density-based methods, e.g. LOF [17], LOCI [93], generally assign to each object a factor describing the relative density of this o b ject’s neighbourhood. Similar to distance-based approach, density-based approach also involves in the com putation of objects’ nearest neighbours. However, th e m easurem ent of an object to its nearest neighbours is then compared to the same m easurem ents of neighbours. The purpose of doing so is to overcome different effects of dense and sparse clusters on p oints’ neighbourhood in detecting outliers. C om putational costs of these m ethods become even more expensive th an th a t of distance-based methods. Because of the applica bility for large and high-dimensional data, such kind of methods still a ttra c t much attention from th e research community [75, 17, 93].
1.2
R e c o m m e n d a tio n S y s te m s
Recommendation systems (or recommender systems) try to profile a user preference over items by the user feedback and seek to recommend items from the overwhelming set of choices to fit user’s tastes. A more specific definition of recom m endation systems is given by Burke [18].
D e fin itio n 6 . (Burke’s definition) System s that produce individualized recommen
dations as output or have the effect o f guiding the user in a personalized way to interesting or useful objects in a large space o f possible options.
Individualized (or personalized) is the m ain keyword in this formal definition. This term indicates th a t each user will be provided w ith different items by the rec om m endation systems.
Recently, recom m endation systems have become more and more popular on appli cation websites. For instance, web-based services help users in discovering interesting products on Am azon1, promising movies on Netflix2, videos on Youtube3 and Hulu4, websites on Stum bleUpon5, news on Digg6, music on Last.fm 7 and iTunes8, and social content and users on Facebook9, T w itter10, etc. These recommendation system s can generate personalized recommended items which well m atch users’ taste. According to [70], two thirds of the movies rented by Netflix are recommended, Google news recommendations result in 38% more clickthroughs, and 35% of the product sales on Amazon.com are recommended items.
In recom m endation systems, there are two types of user feedback, i.e. explicit feedback and implicit feedback, which are utilized in profiling the preference of users. These two kinds of feedbacks are illustrated in the user-item m atrixes in Fig. 1.1. In
1 http: / / www. amazon, com / 2littp ://w w w . netflix. com / 3http://w w w .youtube.com / 4http://w w w .hulu.com / 5http://w w w .stum bleupon.com / 6h ttp ://w w w . digg.com / 7h ttp ://w w w .last.fm / 8h ttp ://w w w .apple.com /itunes/ 9http: / /w w w . facebook .com / 10http: / /tw itter.com /
1 1 1 1 1 1 I 1 1 1 1 1 1 1 5 4 I 5 4 5 1 5 3 2 1 3 5 1 • * ---i t e m---► -*---i t e m--- * ■
Explicit feedback Implicit feedback
Figure 1.1: Examples of two different user feedbacks illustrated in the user-item matrixes. Explicit user feedback is listed in the left m atrix, and implicit feedback is dem onstrated in the right m atrix.
the case of explicit feedback, users explicitly express their opinion by ratin g values towards items. The rating indicates how a user feels about a particular item . In contrast, implicit feedback is inferred from observing user behaviors. T he implicit feedback of a particular user is generated from the w atching/brow sing/purchasing actions of this user. For instance, a user listens to a song for a long tim e, from which we can infer th a t the user like this song. Im plicit feedback can be collected from various sources, such as number of times used, web click-through, purchase action, etc. Normally, a distinction between explicit and implicit feedback needs to be m ade for building a recommendation system. O ur research work in this thesis deals w ith the recommendation problem w ith the explicit feedback.
For recommendation from the explicit feedback, rating prediction is th e typical and concrete task, where the objective of this task is to predict the ’ra tin g ’ th a t a user would give to an item (such as music, books, or movies) or social element (e.g. people or groups) they had not yet considered, using a model built from th e characteristics of item s (content-based approaches) or the user’s social environment (collaborative filtering approaches) [102].
Previously proposed m ethods for building recommendation system s can be cate gorized into three prim ary approaches [4], respectively, Collaborative F iltering (CF), Content-Based filtering (CB) and a hybrid approach. Here, we sum m arize th e basics
concepts, and then respectively discuss the detailed inform ation of these approaches.
1. Collaborative filtering collects and merges preference information of users, and generates predictions for an individual user based on sim ilarity m easurem ents of users and (or) items [30, 107, 53, 104].
2. Content-based filtering [36, 90, 95, 80] generates recom m endations utilizing con ten t profiles of item s and profiles of users th a t describe th e types of item the users like. In other words, this approach tries to recommend item s which are similar to those th a t a user liked in the past.
3. Hybrid approach [19, 18] typically combines collaborative filtering and content- based filtering, and can be more effective in some cases.
1.2.1
C ollab orative F ilterin g
Collaborative Filtering (CF) is the most popular and, to date, the m ost successful approach to recommendation systems.- CF collects and merges a large am ount of users’ rating information to predict w hat users will like based on similarity m easure ments among users and (or) among items [107, 53, 104], The term collaborative filtering is first used in [41], which presents the T apestry system to filter emails us ing collaborative filtering. O ther im portant early work was done by [101] on their G rouplens system for recommending Usenet articles, and by [109] on their Ringo music recommender system.
Collaborative filtering methods can be categorized into two prim ary types accord ing to [16], which are memory-based approach and model-based approach. Memory- based approach operates on an entire rating dataset to generate recommended item s to a particular user, while model-based approach first m anipulates the given ratings to build a model, which then can be used to predict ratin g values for a given user-item pair.
M em o ry -b a sed m e th o d s
Memory-based m ethods utilize th e entire user-item ratings to generate a prediction. In the training phase of a memory-based m ethod, all ratings should be scanned and stored into the memory. Memory-based m ethods can be further divided into user- based and item-based methods, which are based on th e A -N ear est Neighbour al gorithm. The user-based m ethod com putes a set of K nearest neighbours of the target user by calculating the similarities between users’ rating profiles. Once the neighbours are obtained, we can calculate the prediction rating value of th e targ et user using a weighted average of th e neighbours’ item ratings. On the other hand, item -based m ethod focuses on finding K similar items rath er th an similar users [107]. Correspondingly, for a target item, prediction can be generated by taking a weighted average of the target user’s item ratings on these neighbour items. There are a variety of different ways to calculate the sim ilarity between item s or users. In a typical memory-based m ethod, the most commonly-used similarity between users or sim ilarity between items are calculated using cosine-based sim ilarity [16] or Pearson correlation similarity [101].
Here, we would like to introduce the item -based m ethod w ith cosine-based simi larity [107], which will be used as an original model for generating a new and more effective model by our proposed R P framework in C hapter 3. At first, let us assume a set U of n users and a set X of m items in a typical C F scenario. Each user u is associated w ith a set Xu, which contains all the item s the user has rated. T he dataset containing all users and all rated item s is denoted as V t (ZU x X . All observed ratings
r ui on the dataset V t are denoted as the rating d ataset lZt := {rui\(u,i) € T>t}.
At the beginning, we need to com pute the sim ilarity m atrix S which measures the similarities between the item s in the set X, where stJ denotes the sim ilarity of item i and item j . Here, we use the cosine-based sim ilarity [16]. More concretely, the cosine-based sim ilarity .stJ represents the cosine of the angle between two item vectors
where ||||2 means the L2 norm of the vector.
After the com putation of sim ilarity m atrix, we seek to calculate th e prediction
target user has rated. This prediction is generated by com puting a weighted average of the user’s ratings on these similar items.
M o d el-b a sed m e th o d s
Model-based m ethods first learn a model of user behavior from a rating d ataset in advance, and then use this model to generate recommendations. Com pared w ith memory-based m ethods, model-based m ethods usually scale b etter in term s of their resource requirem ents (memory and com puting tim e) and do not require keeping actual user profiles in memory for prediction. Besides, in a lot of applications, model- based m ethods outperform memory-based m ethods in term s of prediction accuracy
model building, such as Naive Bayes [16], restricted Boltzm ann machines [105], graph- theoretic approach [5], and latent factor [53, 65, 66, 96]. L atent factor techniques have been generating much interest and progress recently, because of its attra ctiv e accu racy and scalability. These models reduce the dimensionality of the space of user-item ratings and try to m ap both items and users to a joint latent semantic space [65]. The rating value can be predicted by the inner products of a user and an item in this space. Examples of latent factor techniques applied to recommendation include such as Singular Value Decomposition (SVD) [26], Probabilistic L atent Semantic Analysis (PLSA) [53], and M atrix Factorization (MF) [116].
The MF m ethod [116] is a simple and effective latent factor model. Here, we give a detailed introduction to this model, as it will be used as a com petitor in C hapter 3. In this MF m ethod, the /-dim ension factor vectors pu G W and qt G W describe the
latent characteristics of user u and item i, and th e predicted rating of this user-item pair can be calculated by f ul = q jp
u-rating for an item based on a set I * containing the k m ost similar item s th a t the
[102],
In order to estim ate the latent vectors pu and g*, we can solve the following least squares problem
E k , (<■„, - + a ( x ; lul p i+ ?.2)
where r uj means the given rating of user u. to item i and A controls the extent of regularization, which is usually estim ated by cross validation. Model param eters are determ ined by minimizing this regularized squared error function through stochastic gradient descent [66]. Looping over all known ratings in 1Zt , the upd atin g function of param eters can be com puted as follows
Qr 9. + 7 ((rui - q f p u)Pu + M i )
Pu< -Pu + 1 {{rui - q f pu)q[ + Ap u)
where 7 works as learning rates of these u pdating steps.
A d v a n ta g es o f co lla b o ra tiv e filterin g
Besides the effectiveness and scalability, the collaborative filtering approach has sev eral other significant strengths.
1. The greatest strength of CF is th a t it does not require any content inform ation about the product for recom m endation. Thus, this approach is suitable to be implemented for complex items, such as music and movies, of which th e content properties are difficult to extract [18].
2. Furtherm ore, the CF approach has the ability to recommend serendipitous items, which have very different content from the items th a t the user has chosen, and which the user would like b ut have not discovered yet [51].
3. Finally, according to [50], the CF approach takes into account th e quality of items in recommendation, especially in th e case of explicit feedback, and can prevent poor recommendations. For instance, two movies w ith same character istic features have very different qualities, CF may find out the difference and
recommend the item w ith high quality.
E x istin g p ro b lem s in co lla b o ra tiv e filterin g
According to the work presented in [55], the cold-start is one of the m ost serious problems of the CF approach. This problem refers to th e situation where a recom m endation system is in the start-u p phase, or when a new user or item is added into the system. In this situation, the CF system has difficulty in generating recommen dations.
The collaborative filtering approach has difficulty in predicting ratings from the sparse rating dataset, where some users have small sets of rated items [55]. According to Breese et al. [16], CF works well for a user only if a reasonable am ount of ratings of this user is available.
Finally, in [55] the idea of non-transitive associations among users or item s is presented. This means th a t if two similar item s have never been rated by the same user, or if two similar users have never rated the same item, their relationship may be lost. In this case, CF will not tre a t those two item s or two users as sim ilar ones, and this may affect the performance of the system.
1.2.2
C on ten t-b ased F ilterin g
Typically, Content-Based filtering (CB) [36, 90, 95, 80] creates a representative profile of a user’s interest utilizing characteristic features of his/h er rated item s, and then recommend other unrated items likely being most relevant to th a t user. In other words, m ethods in this approach generate a weighted content-based profile for a user, where the values of this user’s profile indicate the im portance of corresponding fea tures to this user, and then seek to recommend items which well suit the profile of this user. Using various techniques [36, 90, 95, 80], this weighted vector describing user’s preference can be calculated from individual feature vectors of rated items.
T he work [36] first presents a content-based information filtering, m atching user interests to tex t documents using two m atching m ethods and two types of user profiles. L ib r a system is a book recommender using Bayesian learning algorithm and extracts
inform ation of books for text categorization [90]. [95, 80] survey the field of content- based recommendation, including a m ethod for representing items and user profiles, and a m ethod for comparing items to the user to determ ine which to recommend.
The recommender system im plem ented on Pandora Internet Radio 11 is a popular example of CB. This system takes th e features of an initial seed provided by a user to build a station, which plays music w ith similar properties to the user. T hen the user’s feedback on these played songs is used to learn the interest profile of this user. W hen th e user likes a particular song, the system then emphasizes some certain features of this user, while this user dislikes a song, the system deemphasizes certain features. O ther examples of content-based recommender systems include R o tten Tom atoes12, Internet Movie D atabase13, Jin n i14 and Rovi C orporation15.
In contrast to CF, CB does not have cold-start problem for new items, since the features of a new item can be extracted when the item is added. In addition, the recommended items are more explainable th a n CF as they m atch the feature vector of user interests. T he main disadvantage of CB is th a t it is difficult to extract good feature vectors of complex items w ith trem endous properties such as music and movies. If possible, creating feature vectors for these items is generally a very laborious process. In addition, the content-based filtering can only recommend items from a narrow topic range; they are unable to provide serendipitous recom m endations [51].
1.2.3
H yb rid A pproach
Hybrid recommendation systems were developed in the recent years as an a ttem p t to overcome the weakness of pure content-based filtering or pure collaborative filtering methods. As stated in [18], “hybrid recommender systems combine two or more recommendation techniques to gain b etter performance w ith fewer of th e drawbacks of any individual one.” For example, this approach can be used to alleviate some
11 http://w w w .pandora.com / 12h ttp ://w w w . rottentom atoes.com / 13h ttp ://w w w .imdb.com/
14h ttp ://w w w .jinni.com/ 15http://www.rovicorp.com /
common problems, such as cold-start and sparsity, of other approaches [55]. The recommendation system of Netflix is a representative example of this approach, which offers movies recommendations based on users’ previous ratings (using collaborative filtering), and the characteristics of watched movies (utilizing content-based filtering).
T he hybrid approach can be implemented in many ways [4], for example by adding content-based characteristics to a collaborative-based m ethod (or vice versa) [12], or by combining predictions obtained separately using a content-based m ethod and a CF m ethod [88], or by model unification [97, 14]. O ther hybrid m ethods include Fab which makes use of profiles information to determ ine similar users for CF [12], combination of CF and content-based approaches using the prediction strengths [88], probabilistic m ixture models [97], a kernel-based m ethod which allows generalization across the user and item dimensions sim ultaneously [14]. [19] surveys the area of possible hybrid recommender systems and examines different types of combinations.
1.2.4
E valuation M etrics
Recommender systems have been evaluated in many, often incomparable, ways [51]. The work of [61, 51] review several different m etrics of predictive accuracy, cover age, learning rate, novelty and serendipity, and confidence. In this p art, we review some key m etrics which will be used in evaluating the rating prediction and T o p -N recom m endation of collaborative filtering in C hapter 3.
For evaluation of rating prediction, prediction accuracy is by far the m ost discussed characteristic of a recommendation system. There are much work which focuses on evaluating the accuracy property of a system [51]. Prediction accuracy empirically measures how close the predicted ratings of a system differs from the given ratings in the average sense, or for each user how well a system ’s predicted ranking of item s suits the given ranking order of items. Predictive accuracy m etrics and ranking accuracy metrics are two significant classes for evaluation of prediction accuracy.
For evaluating predictive accuracy, Mean Absolute Error (M A E ) and Root Mean Square Error (R M SE ) [65, 66, 102, 51] are two classic and widely-adopted m etrics.
The formal definitions of these two m etrics are as follows
M A B =
I«t
R M S E - ■' (r“ K , Y
l« .l
where values of these two m etrics close to zero show b etter performance, and R M S E tends to penalize larger errors more severely th a n M A E .
As mentioned in [51], “ranking accuracy metrics can be used to evaluate the ability of a recommendation algorithm to produce a recommended order of item s th a t matches how th e user would have ordered the same item s” . The average Discounted Cumulative Gain (D C G ) and Normalized Discounted Cum ulative G ain (N D C G ) [79, 130] of all test users are th e most com m only-adopted measures for the ranking accuracy. The formal definitions of average D C G and N D C G of all users are
i |w | N o r 2 _ 1 D C G @ N = —
E E
M Z Z log2(n + 1) \U\ N n n d c g&n A y l y ~ C ~ P \ t ^ { Z u ^ [ \ o g 2{n + l)where r" is the ground tru th rating value of th e item at the position n predicted by the algorithms. log ^ is a position discount factor. Highly relevant item s appearing lower in the recommendation list will be penalized by the discount factor. \U\ indicates the num ber of users in the test d ataset, Z u is the maximum value of X^nLi iog'^fn+'ij for the user u and works as a norm alization factor of this user. Since th e N D C G is normalized, it takes a value from 0 to 1.
T o p -N recommendation is another fundam ental property of recommenders [61,
58]. Evaluation of T o p -N recom m endation aims to evaluate w hether a set of items are the most appealing to a particular user. For evaluation of T o p -N recom m endation, the overall Recall [65, 82, 102] is the m ost widely-used measure, which is com puted by averaging over all users. T he Recall m etric is expressed as follows
d nr-, AT 1 # h i t s ( u , N ) Recall@N = — > 7^ —
-\U \ ^ l«l
where # h i t s ( u , N ) means whether the ids most appealing item in the test dataset appears in the predicted list w ithin the length N . Recall value increases w ith the length N and the maximum value is 1. Larger Recall values indicate b e tte r T o p -N recom m endation.
1.3
C o n tr ib u tio n o f t h is T h e s is
This thesis studies two fundam ental problems of d a ta mining, which are outlier detec tion from large-scale categorical datasets and recom m endation systems from highly- skewed rating datasets. The contributions of this thesis are twofold and will be briefly summ arized in the next two subsections.
1.3.1
C on trib u tion s to O u tlier D e te c tio n
For outlier detection from categorical data, over the years, a num ber of m ethods have been developed [75, 21, 37, 49, 92]. However, real-world datasets and environments present a range of difficulties th a t limit th e effectiveness of these m ethods. Exist ing m ethods for outlier detection from categorical datasets suffer from the following limitations:
1. F irst of all, there does not exist a formal definition of categorical outlier in the literature. Many m ethods are based on definitions of the numerical out liers, which usually cannot well reflect the characteristic of categorical outliers. W ithout a formal definition, m ethods of categorical outlier detection are often designed as an ad-hoc process.
high dimensionality and large size of the d ataset, high-complexity of statisti cal tests or inefficient proxim ity-based measures. For instance, the distance- based categorical outlier detection m ethods, such as CNB [75], are very time- consuming for large datasets. T he tim e complexity of CNB increases quadrat- ically w ith the number of objects. T he tim e costs of rule-based m ethods, FIB [49] and OA [92], also increase quadratically w ith th e num ber of attributes.
3. Many m ethods for detecting categorical outliers [75, 49, 92], requires th a t the user provides param eters to m easure whether an object possesses properties sufficiently different from others to be qualified as an outlier. T he performances of these m ethods are heavily dependent on param eter settings, which are very difficult to estim ate w ithout background knowledge about th e data.
In this thesis, we propose inform ation-theory-based effective outlier detection m ethods for large categorical datasets. O ur work addresses th e existing lim itations mentioned above. First of all, we deal w ith the lack of a formal definition of outlier by using information theory. T he proposed definition helps to construct general out lier detection m ethods for categorical datasets. In fact, based on this definition, we propose an optim ization-based model for detecting outliers of categorical datasets, where a novel concept of weighted holo-entropy is utilized to capture the distribution and correlation information of a dataset. To avoid high time-complexity, we derive a new outlier factor function from the objective function and show th a t com puta tio n /u p d atin g of the outlier factor is solely determ ined by the object itself and can be performed efficiently w ithout th e need to estim ate th e joint probability distribu tion. Our proposed methods have a linear tim e complexity with the size of datasets, i.e. num ber of objects and dimensions of th e datasets, and need only the num ber of outliers as an input param eter.
1.3.2
C on trib u tion s to R ec o m m en d a tio n S y stem s
Primarily, existing methods for recom m endation systems take into account the rating datasets of movie or music, e.g. Netflix, Movielens, EachMovie and Yahoo Music datasets. In the rating scenario of these rating datasets, users are prone to choose
movies or musics belonging to some genres m atching their interests, and provide most objective ratings to these items while expecting the system to become more adapted to recommend most appealing items to them . The ratings of these datasets are more concentrated around the middle of th e ratin g range, and are more likely symm etric and evenly distributed on both side of the m ean rating.
However, there are also many rating datasets w ith skewed distributions which are very different from the distribution of the above m entioned datasets. These skewed rating datasets broadly exist in e-commerce and content provider websites, e.g. Amazon, Epinions and Youtube [24]. T he users on the e-commerce websites tend to give the highest ratings to the desired products, after they may have com pared these products to other similar ones. On th e other hand, on the content provider websites, the users are prone to provide most positive feedback tow ards a small portion of m ost-appealing items in order to express their opinion or influence others’ choice. In these cases, the ratings are likely w ith higher asym m etry and m ajority of ratings are in th e highest side of rating range.
In the existing m ethods of CF, the non-transitive correlations among users or items are also a problem. If two similar item s have never been rated by th e same user, or two similar users have never rated the same item, the sim ilarity relationship may not be well captured by existing methods. In these cases, the non-transitivity associations may affects the performance of the system.
To deal with these problems, we propose a new framework for estim ating the rating and quantitative high-order preference simultaneously. This framework allows to create novel and efficient models for skewed rating datasets. It relies on high-order quantitative preference of users to b etter capture th e users’ relative rating inform ation among items. At the same time, the transitive associations among the item s which are never rated together can be implicitly captured by th e constraints of high-order preference similarity. New models created under this framework can generate b etter performance th an the conventional m ethods on the skewed rating d atasets for not only rating prediction b u t also for T o p -N recommendation.
As evidence of the contributions, here is the list of the au th o r’s published or subm itted papers issued from his work in relation w ith this thesis.
• S. Wu and S. Wang, “A Q uantitative High-order Preference Framework for High-skewed R ating D atasets” , subm itted, 2012.
• H. Ni, B. A bdulrazak, D. Zhang, S. Wu, X. Zhou, K. Miao and D. Han, “M ulti-modal Non-intrusive Sleep P a tte rn Recognition in Elder Assistive Envi ronm ent” , In Proceedings of the 10th International Conference on Sm art Homes
and Health Telematics (IC O S T 2012).
• S. Wu and S. Wang, “Inform ation-theoretic O utlier Detection for large-scale
Categorical D ata” , IE E E Transactions on Knowledge and Data Engineering
(TKDE), Preprint.
h t t p : //www. co m p u ter. o r g / p o r t a l / w e b / c s d l / d o i / 1 0 .1 109/TKDE.2011.261
• H. Ni, B. Abdulrazak, D. Zhang, S. Wu, Z. Yu, X. Zhou, S. Wang, “Towards Non-intrusive Sleep P a tte rn Recognition in Elder Assistive Environm ent” , Jour
nal of Ambient Intelligence and Humanized Computing (AIHC), Springer, 2012.
h t t p : //www. s p r i n g e r l i n k . co m /c o n ten t/x 4 q l8 2 4 3 7 5 2 6 3 5 1 5 /
• S. Wu and S. Wang, “Param eter-free Anomaly Detection for Categorical D a ta ” , In Proceedings of the 7th International Conference on Machine Learning and
Data Mining (M LD M 2011), 2011.
• H. Ni, B. Abdulrazak, D. Zhang, S. Wu, “CDTOM : A Context-driven Task- oriented Middleware for Pervasive Homecare Environm ent” , International Jour
nal of UbiComp (IJU), Vol.2, N o.l, Jan. 2011.
h t t p : / / a r x i v . o r g / f t p / a r x i v / p a p e r s / 1 1 0 2 /1 1 0 2 .1 1 5 2 .pdf
• S. Wu and S. Wang, “Rating-based Collaborative Filtering Combined with Additional Regularization” , In Proceedings o f the 33rd International A C M SI-
GIR Conference on Research and Development in Information Retrieval (SIG IR 2011), 2011.
• H. Ni, B. A bdulrazak, D. Zhang, S. Wu, Z. Yu, X. Zhou, S. Wang, “Towards Non-intrusive Sleep P a tte rn Recognition in Elder Assistive Environm ent” , In
Proceedings of the 7th International Conference Ubiquitous Intelligence and Computing (UIC 2010), 2010.
• H. Ni, B. A bdulrazak, D. Zhang and S. Wu, “U nobtrusive Sleep Posture De tection for Elder-Care in Sm art Home” , In Proceedings o f the 8th International
C h ap ter 2
O u tlier D e te c tio n in L arge-scale
C a tegorical D a ta
In this C hapter, we are investigating outlier detection for categorical datasets. We have formulated outlier detection as an optim ization problem and proposed two prac tical, unsupervised, 1-param eter algorithm s for detecting outliers in large-scale cat egorical datasets. The effectiveness of our algorithms results from a new concept of weighted holo-entropy th a t considers b o th the d a ta distribution and a ttrib u te corre lation to measure th e likelihood of outlier candidates. T he efficiency of our algorithm s results from the outlier factor function derived from th e holo-entropy. A new outlier factor function is derived from the optim ization function and show th a t com puta tio n /u p d atin g of the outlier factor is solely determ ined by the object itself and can be performed efficiently w ithout th e need to estim ate the joint probability distribu tion. Besides, We also estim ate an upper bound for the num ber of outliers and an anomaly candidate set. This bound, obtained under a very reasonable hypothesis on the num ber of possible outliers, allows us to further reduce the search cost. The proposed algorithms have been evaluated on real and synthetic datasets. O ur exper iments in comparison with other algorithm s confirm the effectiveness and efficiency of the proposed algorithms in practice.
The included paper has been accepted by IE E E Transactions on Knowledge and
Information-theoretic Outlier Detection for
Large-scale Categorical D ata
Shu Wu and Shengrui W ang1
A b s tr a c t
O utlier detection can usually be considered as a pre-processing step for locating, in a dataset, those objects th a t do not conform to well-defined notions of expected behavior. It is very im portant in d a ta mining for discovering novel or rare events, anomalies, vicious actions, exceptional phenomena, etc. We are investigating outlier detection for categorical datasets. This problem is especially challenging because of the difficulty of defining a meaningful sim ilarity measure for categorical data. In this paper, we propose a formal definition of outliers and an optim ization model of outlier detection, via a new concept of holo-entropy th a t takes both entropy and to tal correlation into consideration. Based on this model, we define a function for the outlier factor of an object which is solely determ ined by th e object itself and can be updated efficiently. We propose two practical 1-param eter outlier detection methods, named ITB-SS and ITB-SP, which are capable to identify the m ost likely outliers automatically. Users need only to provide the num ber of outliers they want to detect. Experim ental results show th a t ITB-SS and ITB-SP are more effective and efficient than m ainstream m ethods and can be used to deal with both large and high-dimensional datasets where existing algorithm s fail.
K eyw ords: Outlier detection, Holo-entropy, Total correlation, O utlier factor,
A ttrib u te weighting, Greedy algorithms
lrThe authors are with the Department of Computer Science, University of Sherbrooke, Sher brooke, QC J1K 2R1, Canada. E-mail: (shu.wu, shengrui. wang}@usherbrooke.ca.
2.1
I n tr o d u c tio n
Outlier detection, which is an active research area [22, 52, 23, 117], refers to the problem of finding objects in a d ataset th a t do not conform to well-defined notions of expected behavior. The objects detected are called outliers, also referred to as anomalies, surprises, aberrants, etc. O utlier detection can be im plem ented as a pre processing step prior to the application of an advanced d a ta analysis m ethod. It can also be used as an effective tool to discover interest p atterns such as the expense behavior of a to-be-bankrupt credit cardholder. O utlier detection is an essential step in a variety of practical applications including intrusion detection [71], health system m onitoring [52] and criminal activity detection in E-commerce [8], and can also be used in scientific research for d a ta analysis and knowledge discovery in biology, chemistry, astronomy, oceanography and other fields. [52].
According to [22] [52], if the existing m ethods for outlier detection are classified according to th e availability of labels in the training datasets, there are three broad categories: supervised, semi-supervised and unsupervised approaches. In principle, models within th e supervised or the semi-supervised approaches all need to be trained before use, while models adopting the unsupervised approach do not include the training phase. Moreover, in a supervised approach a training set should be provided with labels for anomalies as well as labels of normal objects, in contrast w ith the training set w ith normal object labels alone required by th e semi-supervised approach. On the other hand, the unsupervised approach does not require any object label information. Thus the three approaches have different prerequisites and lim itations, and they fit different kinds of datasets with different am ounts of label information. The three broad categories of outlier detection techniques are discussed below.
The supervised anomaly detection approach learns a classifier using labeled objects belonging to the normal and anomaly classes, and assigns appropriate labels to test objects. The supervised approach has been studied extensively and m any m ethods have been developed. For instance, the group of proximity-based m ethods includes the cluster-based ‘K -M eans+ID 3’ algorithm [39], which cascades A'-Means clustering and an ID3 decision tree for classifying anomalous and normal objects. T he work
of [13] is based on statistical testing and an application of Transduction Confidence Machines, which requires k neighbors. Moreover, one-class SVMs [119] [108] have been applied broadly in this field as they do not have to make a probability density estim ation. A variety of m ethods [35] [57] based on inform ation theory have also been proposed. The work of [35] proposes a m ethod to control the false positive rate in the novelty detection problem. In [57], a formal Bayesian definition of surprise is proposed.
The semi-supervised anomaly detection approach prim arily learns a model repre senting normal behavior from a given training d ataset of norm al objects, and then calculates the likelihood of a test ob ject’s being generated by the learned model. Zhang [134] proposes an adapted hidden Markov model for this approach to anom aly detection, while Gao [40] proposes a clustering-based algorithm which punishes devi ation from known labels. M ethods th a t assume availability of only the outlier objects for training are rare [52], because it is difficult to obtain a training d ataset which covers all possible abnorm al behavior th a t can occur in th e data.
The unsupervised anomaly detection approach detects anomalies in an unlabeled dataset under the assum ption th a t the m ajority of th e objects in the d ataset are nor mal. Angiulli et al. [10] propose a KNN distance-based m ethod. Clustering is another widely implemented m ethod, of which [6] is an example. Moreover, this approach is applied to different kinds of outlier detection tasks and datasets, e.g., conditional anomaly detection [110], context-aware outliers [127] and outliers in semantic graphs [76]. As this approach does not require a labeled training d ataset and is suitable for different outlier detection tasks, it is the most widely used.
To implement supervised and semi-supervised outlier detection methods, one m ust first label the training data. However, when faced w ith a large dataset w ith millions of high-dimensional objects and a low anomalous d a ta rate, picking th e abnorm al and normal objects to compose a good training d ataset is time-consuming and labor- intensive. The unsupervised approach is im portant not only for its low requirem ent in term s of a priori knowledge about the outliers b u t also for the role of preprocessing it can play. For instance, in a supervised approach, an unsupervised m ethod can be used as the first step to find a candidate set of outliers, which will help experts to
build the training dataset. The unsupervised approach is our research focus in this paper.
2.1.1
U n su p erv ised C ategorical O u tlier D e te c tio n
In real applications, a large portion or the entirety of th e dataset is often presented in term s of categorical attrib u tes. Examples of such datasets include transaction data, financial records in commercial banks, demographic data, etc. The problem of outlier detection in this type of d ataset is more challenging since there is no inherent m easurem ent of distance between the objects. Existing unsupervised outlier detection m ethods, e.g. LOF [17], LOCI [93] and [6] [11], are effective on datasets w ith numerical attributes. However they cannot be easily adapted to deal with categorical d ata.
O utlier detection m ethods for categorical d a ta can be characterized by the way outlier candidates are m easured w .r.t. other objects in th e dataset. In general, outlier candidates can be assessed based either on d a ta distribution or on a ttrib u te corre lation, which provides a more global measure. They can also be assessed using a between-object similarity or local density, which provides a local measure. Various techniques such as proxim ity-based [75], rule-based [49], and inform ation-theoretic [72] m ethods have been proposed (Section 2 provides a more detailed discussion) and fall into one of these two categories. T he common problem with the existing m ethods is the lack of a formal definition for the outlier detection problem. W ithout a formal definition, outlier detection is often designed as an ad-hoc process. In particular, sev eral user-defined param eters are often required to define whether an object possesses properties sufficiently different from others to be qualified as an outlier. Such m eth ods are heavily dependent on param eter settings, which are very difficult to estim ate w ithout background knowledge about the data. Many existing m ethods also suffer from low effectiveness and low efficiency due to high dimensionality and large size of the dataset, high-complexity statistical tests or inefficient proximity-based measures.