UNIVERSITE DE MONTREAL
DEPARTEMENT DES SCIENCES ECONOMIQUES
FACULTE DES ARTS ET DES SCIENCES
Prévisibilité des rendements excédentaires des actifs
financiers : le papier de Bandi et Perron (2008)
revisité.
Rapport de recherche présenté en vue de l’obtention du grade de
Maitrise en Sciences Economiques
Par:
Dario Lebelon
Sous la direction de:
Silvia Gonzalvez
1
Avant propos et remerciements
Je remercie le Grand Architecte de l’Univers qui m’a donné l’intelligence et aussi la motivation nécessaires pour mener à termes ces études de maitrise.
Un remerciement très spécial à Mme Silvia Goncalves qui a été ma professeure d’économétrie et qui est aussi ma directrice de recherche. Elle a été très patiente avec moi tout au long de cet atelier de recherche et son aide a été plus que précieuse dans la finalisation de ce papier. Merci Mme !!!
Je tiens à remercier ma famille, particulièrement mes parents qui m’ont toujours encouragé à poursuivre de nouvelles études et dont je suis l’un des plus beaux rendements.
Mes remerciements vont enfin à mes amis (es) et aussi tous ceux et celles qui d’une manière ou d’une autre m’ont aidé à atteindre cet objectif.
2
Résumé
Ce rapport de recherche tente de tester l’hypothèse de prévisibilité des rendements excédentaires d’un actif financier. Le papier de Bandi et Perron (2008) y est revisité où notre préoccupation est de voir si les résultats de ces derniers tiennent quand on utilise un autre écart-type pour corriger les problèmes d’autocorélation des erreurs recensés au niveau de la littérature. Car selon Ang et Bekaert (2007), les résultats de la prévision des rendements excédentaires d’un actif financier varient selon l’écart-type utilisé. Dans un premier temps nous reprenons le modèle économétrique de Bandi et Perron (2008) où la volatilité réalisée est utilisée comme variable explicative et où l’écart-type de Newey-West (1987) a été utilisé pour tenir compte des problèmes d’autocorélation. Tout comme ces derniers, on a trouvé que la volatilité réalisée est un bon prédicteur sur le long terme (72 à 120 mois). Ensuite il a été question de voir si on peut améliorer la capacité du modèle en y ajoutant le ratio dividende-prix ou encore le ratio consommation-richesse agrégée introduit par Lettau et Ludvigson (2001).
Finalement, la capacité de la volatilité réalisée à prévoir les rendements futurs est testée avec une méthode d’inférence utilisant les écart-types proposés par Hodrick (1992). Dans le cadre du modèle non contraint, on ne peut rejeter l’hypothèse nulle de non prévisibilité pour les différents niveaux d’agrégation considéré tandis que dans le cadre du modèle contraint on confirme les résultats de Bandi et Perron (2008).
3
Abstract
This research report explores the predictability of stock excess return. The paper by Bandi and Perron (2008) is revisited where we want to verify if their results change when we use a different approach to compute robust standard errors to correct the autocorrelation error problem very well reported on the literature. Ang and Beckaert (2007) point out that the statistical inference at long horizons critically depends on the choice of standard errors. First we use the model of Bandi and Perron (2008) where the realized volatility is used as the independent variable and the Newey-West (1987) inference method is used to correct autocorrelation problems. As them, we found that the realized volatity is a good predictor in the long run (72 – 120 months). Then we explore the possibility to improve the capacity of the model including new variables like the dividend yield and the aggregate wealth consumption (Cay) introduced by Lettau and Ludvigson (2001).
Finally we test if the predictability is still valid when we use the inference method proposed by Hodrick (1992). In the unconstrainded model, we cannot reject the null hypothesis of non predictability for all the aggregation level considered while in the constrainded model we confirm the results found by Bandi and Perron (2008).
4
Table des matières
Avant propos et remerciements ... 1
Résumé ... 2
Abstract ... 3
Table des matières ... 4
1- Introduction ... 5
2- Revue de la littérature ... 9
2.1.- Relations théoriques ... 9
2.2 Études empiriques ... 11
3- Les données. ... 14
3.1- Construction des séries ... 14
3.2.- Description statistique des données ... 15
4.- Prévisibilité de l’excès des rendements à partir du modèle de Bandi et Perron (2008). ... 20
4.1 Estimation du modèle ... 20
4.2 Volatilité réalisée vs Autres prédicteurs ... 22
5.- Inférence en utilisant l’estimateur de Hodrick (1992) ... 26
6.- Conclusion ... 29
5
1-
Introduction
L’hypothèse d’efficience des marchés financiers est à la base de tout un débat dans la littérature financière. Cette dernière qui a été introduite par Fama (1970) a notamment servi aux travaux ayant abouti au modèle MEDAF (CAPM1), largement utilisé en économie financière. Selon cette hypothèse, dans un marché suffisamment large où l'information se répand instantanément, comme c'est le cas en particulier du marché boursier, les opérateurs réagissent correctement et quasi immédiatement aux informations s'ils ont la capacité cognitive de les interpréter avec justesse. En conséquence, les cours équivaudraient toujours au juste prix et évolueraient selon une marche aléatoire au gré des surprises qu'apportent les nouvelles informations, d’où l’idée de non prévisibilité du prix d’un actif financier2
. Autrement dit, sur un marché efficient, le prix d’un titre incorpore toute l’information disponible et élimine la possibilité de faire des profits économiques par les investisseurs puisque l’information est à la portée de tout le monde. Mais dans la réalité, l’acquisition de l’information a un coût et donc si le marché est efficient, c’est à dire que toute l’info est contenue dans le prix de l’actif, alors aucun agent n’est incité à acquérir l’information sur lesquelles sont fondés le prix de ce dernier d’où le fameux paradoxe Grossman Stiglitz (1980).
En montrant une certaine incohérence dans la théorie des marchés efficients, ces derniers permettent d’entrevoir l’idée de prévisibilité des rendements d’un actif. En effet, dès le début des années 80, les chercheurs se penchent sur la question et essaient de trouver quelles sont les variables qui permettent de capter le mieux les variations des rendements d’un actif. Certains se sont penchés sur des variables liées à la valorisation des firmes telles que le ratio dividende-prix connu aussi sous le nom de dividend yield, le earning price ratio Fama et French (1988), Campbell et Shiller (1988). D’autres ont opté pour des variables macroéconomiques et financières telles que le taux d’intérêt de court ou de long terme, le book-to-market ratio3, le taux
1 Capital Asset Pricing Model
2 Samuelson (1965) a démontré formellement que sous certaines conditions précises, l’évolution du prix d’une action ou d’un titre doit être imprévisible.
3
6
d’intérêt sans risque4
, le ratio consommation-richesse agrégée (Cay) utilisé par Lettau et Ludvigson (2001) ou plus récemment la volatilité réalisée utilisée par Bandi et Perron (2008).
L’idée principale de ces travaux est de tester la prévisibilité ou non des rendements d’un actif. Les résultats des études empiriques sur le sujet sont assez contradictoires. Ceux qui sont en faveur de la prévisibilité plaident surtout pour une prévisibilité à long terme des rendements d’un actif (Fama et French 1988), Hodrick (1992), Bandi et Perron (2008). Les détracteurs de la prévisibilité avancent comme raison les nombreux problèmes économétriques qui se posent dans le contexte des régressions utilisées, ce qui invalide les résultats d’inférence. En effet, beaucoup des prédicteurs utilisés dans la littérature sont très persistants. Ceci peut mener à un biais dans l’estimation de l’intercepte et de la pente de l’équation utilisée pour la régression. Des méthodes de corrections analytiques ont été proposées : Stambaugh (1999), Nelson et Kim (1993), Amihud et Hurvich (2004) ou encore d’autres basées sur des simulations comme le bootstrap et le Jackknife :Maliaropulos (1996), Chiquoine et Hjalmarsson (2009). Autre problème soulevé est le fait que la distribution à échantillon fini des statistiques de test t est souvent très éloignée de la loi normale asymptotique5 ce qui cause des distorsions dans la taille des tests. Aussi le problème se complique davantage pour un horizon supérieur à 1 car le chevauchement sur plusieurs périodes lors du calcul des rendements entraine de l’autocorélation dans le résidu de la régression ce qui requiert l’utilisation d’écarts-type robuste à la présence d’hétérocédasticité et d’autocorrélation (HAC).
Un aspect récent de cette littérature sur lesquelles se penchent les chercheurs est la prévision hors échantillon (OOS). Welch et Goyal (2008) affirment que la meilleure façon de prédire les rendements est d’utiliser la moyenne historique car ayant mis la majorité des prédicteurs connus dans la littérature à l’épreuve de l’analyse OOS, ils concluent qu’ils ont un très faible pouvoir de prévision hors échantillon. Campbell et Thompson (2008) montrent qu’en
4 Le T-bill rate est utilisé généralement comme taux d’intérêt sans risque dans la littérature.
5 Des méthodes d’inférence alternatives ont été proposées comme le subsampling : Goetzman et Jorion (1993), Wolf (2000) ou encore des méthodes basées sur les bornes : Campbell et Yogo (2006), Dufour et Campbell (1995).
7
imposant certaines restrictions sur le vecteur des paramètres de la régression, ce résultat peut être inversé.
Dans le cadre de ce rapport, il sera essentiellement question d’analyser la prévisibilité des rendements d’un actif financier. Pour cela nous allons revisiter le papier de Bandi et Perron (2008) où ces derniers ont utilisé la variable volatilité réalisée comme prédicteur des rendements. Nous nous intéressons à deux questions principales. Dans un premier temps, il sera question d’explorer comment on peut améliorer la capacité prédictive du modèle de base utilisé par ces derniers en ajoutant d’autres variables qui sont reconnues comme de bons prédicteurs des rendements dans la littérature financière. Nous opterons particulièrement pour les variables Dividend yield, et le ratio Consommation-richesse agrégée. Dans un second temps, nous tenterons de voir comment évoluent les conclusions de Bandi et Perron (2008) quand on applique les écarts- types de Hodrick (1992)6 pour corriger les problèmes d’autocorrélations des erreurs. Cette dernière démarche semble pertinente car selon Ang et Bekaert (2007), les résultats de l’inférence statistique sur le long terme varient selon le choix de l’écart-type utilisé. Ces derniers suggèrent aussi que l’écart-type de Hodrick fait mieux que le Newey-West (1987) et le Hansen-Hodrick (1980) car il évite la sommation des matrices d’autocovariance.
Ce rapport est organisé de la façon suivante : la section 2 sera consacrée à une revue non exhaustive de la littérature où dans un premier temps nous présenterons quelques équations jugées pertinentes dans le cadre de ce travail et d’autre part nous présenterons une synthèse de trois (3) papiers qui illustrent bien l’idée de contradiction retrouvée au niveau de la littérature concernant la prévisibilité des rendements. La section 3 est consacrée à une description des données et aussi aux tests de racine unitaire sur nos différentes séries. La section 4 est consacrée à l’estimation du modèle et à la présentation des différents résultats. Notons que nous reprenons le même modèle utilisé par Bandi et Perron (2008) où ils ont utilisé les écarts-types de Newew-West (1987) pour corriger les problèmes d’héterocécédasticité et d’autocorélation. Puis nous tenterons d’améliorer la capacité prédictive du modèle en ajoutant d’autres variables. Dans la
6
8
section 5, nous tenterons de voir comment évoluent les conclusions de Bandi et Perron quand on applique les écart-types proposés par Hodrick (1992). Puis nous conclurons.
9
2-
Revue de la littérature
2.1.- Relations théoriques
Tel que mentionné ci haut, les chercheurs ont essayé de dériver des relations algébriques entre le rendement d’un actif et des variables de valorisation des firmes, macroéconomique et financière. Nous pensons qu’il est important de commencer par définir7
certaines variables pertinentes dans le cadre de notre travail. Rt : Rendement de l’actif financier au temps t ; Pt : Prix de l’actif au
temps t ; Dt : Dividendes versées sur l’actif au temps t ; RVt : Volatilité réalisée au temps t ;
CAY: Ratio consommation-richesse agrégée.
Parmi les travaux ayant tenté de lier le rendement d’un actif financier à une variable de valorisation des firmes, Campbell et Shiller (1988) ont présenté un modèle simple de valeur actuelle du cours des actions spécifié de la façon suivante :
k t k k j j t t t E r D P
0 0 exp 1)où E dénote l’opérateur espérance conditionnel sur l’information publique disponible au temps t t
et r le taux de discount qui satisfait la relationt
t t t t t P D P E r Exp 1 . En utilisant une
transformation de Taylor, ils ont montré qu’une approximation du logarithme du ratio dividende-prix peut être écrite comme suit :
0 j j t j t j t tp
h
r
d
d
2)Où est un paramètre plus petit que l’unité et h une constante qui ne joue aucun rôle dans l’analyse. L’équation 2 représente le modèle dynamique de croissance des dividendes et sous
7 Notons que nous donnerons plus de détails à la section description des données concernant le calcul de chacune de nos séries. Nous noterons aussi que les minuscules représentent les variables en log.
10
entend que si le ratio dividende-prix est élevé, les agents anticiperont des rendements élevés dans leurs portefeuilles car le prix de l’actif est faible, donc sous évalué ou un faible taux de croissance des dividendes.
Parmi les papiers ayant utilisé des variables macroéconomiques comme prédicteurs, Lettau et Ludvigson (2001) ont montré que le ratio consommation-richesse agrégée8 (cay) pouvait bien expliquer les variations des rendements d’un actif et même faire mieux que le ratio dividende-prix sur le court et le moyen terme. Ils ont dérivé la relation suivante :
r
r
c
z
E
cay
y
a
c
cay
i i t i t h i t a i t t t
1
1
1
0 , , 3)Où c est log de la consommation, a est le log de la richesse financière, y représente le log du revenu du travail. ra,ti est le rendement espéré de l’actif financier et le rh,ti est le rendement
espéré sur le capital humain,
C C W
est le ratio des nouveaux investissements ; z est une variable aléatoire de moyenne zéro et qui est stationnaire dans le log du capital humain
t t z y k
h . Lettau et Ludvigson (2001) notent que la consommation agrégée, la richesse financière et le revenu du travail partage une tendance commune sur le long terme mais peuvent dévier l’une de l’autre sur le court terme. Selon eux, ces déviations ont un lien direct avec les variations dans les rendements futurs d’un actif. L’intuition c’est que les investisseurs qui veulent garder le même profil de consommation à travers le temps vont tenter de lisser les mouvements transitoires dans leur patrimoine dû aux variations des rendements espérés. En effet, s’ils anticipent une hausse dans l’excès des rendements futurs, ils réagissent en augmentant le niveau de consommation à partir de leur patrimoine et de leur revenu (au temps t) ce qui
8 L’équation du cay a été dérivée en appliquant un développement d’ordre 1 de Taylor de l’équation dynamique de la richesse agrégéeWt1
1Rw,t1
Wt Ct
, avec Wt : richesse agrégée et Rw,t1 : rendement net sur la11
provoque une déviation de la consommation au delà de la tendance commune avec les autres variables du cay. La même analyse se fait s’ils anticipent une baisse des rendements futurs…
Bandi et Perron (2008) ont montré que la volatilité réalisée pourrait être un bon prédicteur de l’excès des rendements d’un actif. Pourquoi la volatilité réalisée ? C’est tout simplement parce que cette dernière est un estimateur convergent de la variation du logarithme des prix d’un actif en asymptotique. Comme l’admettent les auteurs c’est néanmoins un prédicteur moins naturel que le dividend yield qui incorpore le prix ou encore le cay. Toutefois, ils l’utilisent pour prévoir les variations des rendements et trouvent qu’il donne de meilleurs résultats que le deux prédicteurs précités. h t t t h t h h h t t R, 2 , , 4)
où Rt,thdénote l’excès de rendement entre les mois t et t+h, 2th,tdénote le « past market
variance » et t,th l’erreur, ils trouvent qu’entre 6 et 10 ans, cette variable permet de capter les variations de l’excès des rendements entre 26 et 73%.
2.2 Études empiriques
Fama et French (1988) ont étudié la prévisibilité des rendements financiers annualisés continûment composés en utilisant la variable dividende yield comme prédicteur. Dans leur étude qui est l’un des papiers les plus cités de la littérature, les auteurs ont trouvé que la capacité du dividende yield à prévoir le stock des rendements (mesuré par le R2) augmente avec l’horizon des rendements utilisés dans la régression. Ils offrent une explication en deux parties. D’une part, le fait qu’il y ait une forte autocorrelation dans les rendements espérés entraine que la variance des rendements espérés augmente plus vite que l’horizon des rendements. D’autre part, l’augmentation de la variance des rendements non espérés avec l’horizon est atténué par le ¨discount rate effect¨ c'est-à-dire que les chocs sur les rendements espérés génèrent des chocs opposés sur les prix courants. Ils ont utilisé la relation suivante :
T t t t T T T t t a Y r, , 5)
12
Où rt,tT dénote les rendements réels et nominaux continûment composé d’un mois à 4 ans et T
Y dénote le dividende yield à la période T. Pour la période 1941-1986, les auteurs ont trouvé un
R2 très faible sur le court terme, soit moins de 5%, tandis que entre 2 a 4 ans, les variations des rendements expliquées par le dividende yield sont entre 13 et 65% selon le modèle considéré. Ils concluent donc que l’hypothèse de non prédictibilité des rendements est rejetée sur le long terme9.
L’une des reproches concernant les conclusions de Fama et French (1988) c’est que la variable dividende yield soit très persistante, ce qui cause des problèmes d’autocorélation sérielle dans les résidus. Hodrick (1992) examine les propriétés statistiques de trois méthodes10 alternatives pour faire de l’inférence et de la prévision sur le long terme en utilisant le dividend yield comme prédicteur du stock des rendements. Dans la première méthode que nous retenons pour la suite de notre travail, l’auteur reprend l’équation de base11 déjà utilisée par Fama et French (1988). Il propose un écart-type12 qui a deux aspects très importants : 1) cet estimateur est semi-définie positive contrairement à l’estimateur de Hansen-Hodrick (1980) qui n’est pas garanti de l’être. 2) Si la sommation des matrices en échantillon fini donne des propriétés pauvres pour les tests statistiques, les propriétés des tests statistiques en échantillon fini semblent beaucoup mieux avec cet estimateur. En outre, il permet d’éviter la sommation des matrices d’autocovariance source de biais selon l’auteur.
Il a trouvé des résultats qui vont dans le même sens que ceux de Fama et French (1988) et donc confirme l’idée de prévisibilité à long terme des rendements d’un actif. En effet, pour les trois méthodologies, l’auteur rejette l’hypothèse de non prévisibilité à partir d’un horizon de 12 mois
9 Fama et French (1988) ont utilise les écarts-types de Hansen-Hodrick (1980) pour tenir compte des problèmes d’hétérocédastité et d’autocorélation.
10 Voir Hodrick (1992) pour plus de détails sur les deux autres approches utilisées. 11 Equation 5.
12 Nous donnerons un développement plus détaillé sur l’écart-type propose par Hodrick, 1ere méthodologie dans la section 5 de notre rapport.
13
et conforte bien la capacité du ratio dividende prix à prévoir à long terme les rendements d’un actif.
Un peu plus tard, Ang et Becker (2007) en utilisant des données pour plusieurs pays arrivent à la conclusion de la non validité de la prévisibilité à long terme du ratio dividende-prix. En utilisant les écart-types proposés par Hodrick (1992) ils concluent que le dividend price ratio n’a pas un pouvoir prédictif sur le long terme contrairement à ce que veut la sagesse conventionnelle mais conçoivent que le ratio-dividende prix et le taux d’intérêt de court terme peuvent prévoir13 l’excès des rendements continûment composés d’un actif sur le court terme. Ceci s’explique par le fait que bon nombre de papiers de la littérature ont utilisé les écart-types de Hodrick-Hansen (1980) et Newey-West qui conduisent à rejet excessif de l’hypothèse nulle de non-prévisibilité tandis que l’estimateur proposé par Hodrick (1992) a tendance à rejeter moins. Ce constat a permis aux auteurs de conclure que les résultats de l’inférence dépendaient de l’écart-type utilisé, d’où notre intérêt dans le cadre de ce rapport de réévaluer le modèle de Bandi et Perron (2008) en utilisant l’écart-type de Hodrick (1992).
13
14
3-
Les données.
Dans notre étude nous utiliserons les mêmes données que Bandi et Perron (2008) qui proviennent du Center for Research in Security Prices (CRSP). Comme indicateur des rendements nous utiliserons l’indice NYSE/Amex avec dividende. Pour le rendement sans risque nous utilisons les rendements sur trente jours du T-bill. Ces données ont été fournies par M. Benoit Perron pour la période janvier 1952 - décembre 2009. Nous avons aussi téléchargé le Cay à partir du site web de Sydney Ludvigson : (http://www.econ.nyu.edu/user/ludvigsons/) pour la période 1952 -2010. Rappelons que seule le cay est en fréquence trimestrielle, toutes nos autres séries étant mensuelles.
3.1- Construction des séries
Séries des rendements (Rt)
Pour obtenir les rendements mensuels excédentaires continument composés, nous avons soustrait les rendements sans risque des rendements avec dividendes sur une période d’un mois suivant la
relation :
t t t n j n j t f n j t t tr
r
R
1 / / 1, où nt est le nombre de jours ouvrables au mois t.
Les rendements excédentaires entre le mois t et le mois t+h sont exprimées de la façon suivante :
h i i t i t h t t R R 1 , 1, h étant l’horizon de prévision. Notons qu’à chaque horizon d’agrégation, on
perd h-1 observations.
Série volatilité réalisée (Rv)
La volatilité réalisée sera notre principale variable explicative de l’évolution des rendements. Notons que cet estimateur a une longue histoire en finance, mais est tout de même moins populaire que le ratio dividende yield qui incorpore les prix. On considère un mois quelconque avec nt jours ouvrables. On dénote par rtj/nt le j
eme
rendement journalier continûment composé.
La volatilite réalisée est donnée par :
t t n j n j t t t r 1 / 2 1 , 2
15
rendements journaliers sur une période. Pour un horizon h>1 mois, l’estimateur devient :
h i i t i t h t t 1 , 1 2 , 2 .Série dividende yield
Pour construire la série dividende yield, on soustrait le logarithme des rendements sans dividende du log des rendements avec dividende comme dans Cochrane (2007). Cette série notée dy commence en janvier 1953 puisque qu’on perd les douze premières données en prenant la moyenne annualisée de l’année précédente afin d’éliminer les effets saisonniers dans cette variable.
Série indicateur consommation-richesse agrégée Cay
Comme mentionné plus haut, cette série a été téléchargée du site de Sidney Ludvigson et est sous frequence trimestrielle. Elle commence au premier trimestre 1952 et finit au 2eme trimestre de l’année 2010.
3.2.- Description statistique des données
Le tableau ci-dessous résume la description statistique des données utilisées dans ce rapport.
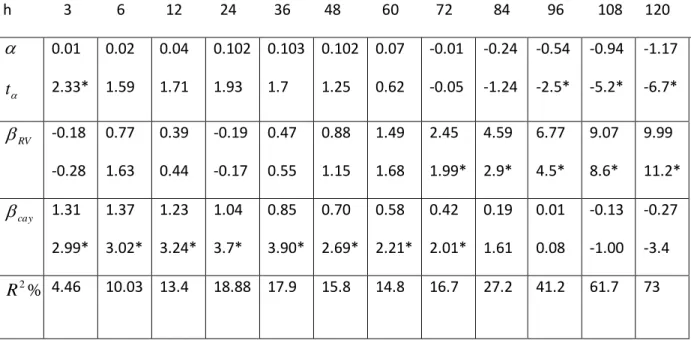
Tableau 1.- Description statistique des données (1952 - 2009)
Statistiques Rendements Volatilité Dividend yield Cay
Moyenne 0.005281 0.001803 0.001167 0.000126
Variance 0.001886 0.000015 5.83e-07 0.000229
Ecart-type 0.043432 0.003948 0.000763 0.015134
Kurtosis 5.082905 127.2125 4.230208 2.689362
Skewness -0.5763 9.90979 1.343614 0.150556
16
Prenons d’abord le cay et le dy. Ces deux variables ont une distribution proche de la loi normale puisque leur coefficient d’aplatissement (Kurtosis) est proche de 3, kurtosis de la loi normale. Toutefois le dividend yield présente une allure leptocurtique tandis que le cay est plutôt platicurtique. Du point de vue skewness, sauf les rendements ont une asymétrie vers la gauche, toutes nos autres variables ayant une asymétrie vers la droite. Le coefficient d’asymétrie (skewness) négatif des rendements traduit des cas de pertes extrêmes (crise de 1987, crise du subprime 2008) ; il est aussi combiné à un excédent de kurtosis. On retrouve pour la volatilité un excès de kurtosis très élevé combiné à une asymétrie vers la droite avec une queue épaisse. Ceci traduit l’idée que les déviations de la variance sont dues à des déviations peu fréquentes mais extrêmes, donc une grande volatilité.
Je m’intéresse à présent au degré de corrélation entre nos deux principales variables : les rendements excédentaires et la volatilité réalisée. Le graphique 1 donne une idée de l’évolution des deux variables pour quatre niveaux d’agrégation : h = 1, 12, 60, 120 mois. Comme on peut le constater la corrélation entre les deux séries est peu claire pour h = 1 mois. Mais au fur et mesure qu’on augmente le niveau d’agrégation, une apparente corrélation est révélée.
Graphique 1 : Evolution des rendements excédentaires et de la volatilité réalisée suivant l’agrégation. -.2 -.1 0 .1 .2 Re nd eme nt s exce de nt aire s 0 .02 .04 .06 Volatilite realisee
17 -.6 -.4 -.2 0 .2 .4 Re nd eme nts exce nd eta ire s 0 .05 .1 .15 .2 Volatilite realisee
Agregation niveau: 12 mois
-.5 0 .5 1 Re nd eme nts exce de nta ire s .05 .1 .15 .2 .25 .3 Volatilite realisee
Niveau d'agregation: 60 mois
-.5 0 .5 1 1.5 Re nd eme nts exce de nta ire s .1 .2 .3 .4 .5 Volatilite realisee
18
Pour poursuivre les caractéristiques statistiques des données, je m’intéresse à présent à la stationnarité14 de mes différentes variables. Pour ce je mène un test de Dickey fuller augmenté sur chacune d’elle en considérant les différents modèles possibles : sans constante ni tendance, avec constante sans tendance. L’hypothèse nulle de ce test stipule que la variable contient une racine unitaire tandis que l’alternative indique que la série est générée par un processus stationnaire. Pour choisir le nombre de retards à inclure dans la régression, nous avons opté pour le critère Akaike (AIC). Les résultats du test sont présentés dans le tableau ci-dessous.
Tableau 2- Résultats du test de Dickey-Fuller augmente (ADF) (Statistique de test)
Rt RV dy Cay
Lags retenu 0 0 5 0
Min AIC -2,390.063 -5,947.18 -9,292.556 -1,633.224
Statistique T (M1) -23.89 -14.57 -2.51 -3.68
Statistique T (M2) -23.59 -12.92 -1.307 -3.69
Pour des seuils de 1%, 5% et 10% les valeurs critiques sont respectivement de -3.43, -2.86 et -2.57 pour le modèle avec constante et de -2.5, -1.95 et -1.62 pour le modèle sans constante. Source : Calculs de l’auteur à partir de Stata
Les modèles 1 et 2 représentent respectivement un modèle avec constante et sans constante. Nous n’avons pas retenu le cas avec tendance car en analysant graphiquement chacune de nos séries, aucune tendance claire n’apparait pour notre période d’étude. Un test ADF a été appliqué sur chacune de nos séries après avoir retenu le nombre de retards (lag) suivant la valeur qui minimise le critère AIC. Pour les variables rendements excédentaires (Rt), volatilité réalisée (Rv) et indicateur consommation richesse agrégée (Cay), l’hypothèse nulle de racine unitaire est rejetée, ce qui nous suggère que ces trois variables pourraient suivre un processus stationnaire suivant les modèles 1 et 2. Par contre, pour la variable dividend yield l’hypothèse nulle de racine
14 Rappelons qu’ici nous nous intéressons à la notion de stationnarité au sens faible. Si la statistique t calculée est supérieure a la valeur critique ADF, on ne peut rejeter H0 et on conclut que la variable suit un processus de racine unitaire. Si la t calculée est inferieure à la valeur critique ADF, on rejette H0 et on conclut que la variable est stationnaire.
19
unitaire n’a pu être rejetée dans le cadre de nos 2 modèles. En effet, la statistique de test dans le cadre du modèle 1 est de -2.51 et est inferieur en valeur absolue aux différentes valeurs critiques -3.43, -2.86 et -2.57 soient des seuils respectifs de 1%, 5% et 10%. Pour le modèle 2, la statistique de test est de -1.307 ce qui est encore inferieure en valeur absolue aux différentes valeurs critiques de -2.5, -1.95 et -1.62 pour des seuils de 1%, 5% et 10% respectivement. On rejoint donc l’idée déjà très connue dans la littérature, à savoir que la variable dy est très persistante. On est donc tenté de conclure que dy suit un processus non stationnaire.
Cependant il est imprudent de conclure d’après un test ADF que cette série est non stationnaire. Lardic et Mignon (2002) attire notre attention sur la faible puissance du test lorsque les erreurs suivent un processus autorégressif conditionnellement hétérocédastique, situation très fréquente dès lors que l’on travaille avec des séries financières. Dans une telle situation, le test ADF conduirait trop souvent à la conclusion que les séries sont non stationnaires ; d’autant plus que les tests de racine unitaire ont très peu de puissance à rejeter l’hypothèse nulle de racine unitaire lorsque les processus sont stationnaires mais persistants15 comme c’est le cas pour la variable dividend yield. Sous ces considérations, nous poursuivons l’étude en supposant la stationnarité de la série dividend yield.
15
20
4.- Prévisibilité de l’excès des rendements à partir du modèle de
Bandi et Perron (2008).
4.1 Estimation du modèle
Nous avons commencé par répliquer les résultats16 de Bandi et Perron (2008) en faisant les régressions avec et sans constante de l’équation 4 pour la période 1952 -2006 qui est la période qu’ont utilisé ces derniers dans leur article. Pour tester la significativité de nos coefficients, nous avons utilisé l’estimateur de type HAC proposé par Newey-West (1987). Pour un coefficient, l’estimateur de la variance HAC est équivalent a :
ˆ 1 ˆ 2 1 1 ˆ 1 2 e NW n Var 6)Où ˆ2ereprésente la variance des résidus obtenus par moindre carres ordinaires, ˆ
est lacovariance des erreurs, n est le nombre d’observations, est une constante qui contrôle le degré
d’autocorrélation (fenêtre), le terme
1 pondère les autocovariances (noyau) et assure que
la variance estimée est toujours positive. Newey- West (1987) ont établi17 qu’on pouvait
choisir 9 2 100 4 n
. En appliquant ce critère, j’ai choisi une fenêtre 6 car notre plus petit échantillon contient 457 observations. Puis j’ai mené la régression. Les résultats sont présentés dans le tableau ci-après.
16
Notons que si nos résultats ne sont pas exactement les mêmes que ceux trouvés par Bandi et Perron (2008) car on a utilisé un indice différent. Les astérix indiquent que c significatif a un seuil de 5%.
17 Greene a suggéré qu’on pouvait choisir 4 1 n
tandis que Stock et Watson recommandent 3
1
4 3
21
Tableau 3- Résultats de la régression des rendements excédentaires sur la volatilité réalisée pour différents horizons pour la période 1952-2006. (Rtth h h th,t t,th
2 , ) h 1 3 6 12 24 36 48 60 72 84 96 108 120 t 0.006 4.02* 0.01 2.21* 0.03 2.93* 0.07 3.36* 0.16 4.63* 0.21 4.89* 0.23 4.28* 0.15 2.08* -.04 -.45 -.26 -3.1* -.35 -4.1* -.49 -6.3* -.53 -5.5* t -0.75 -1.49 1.23 1.98* 0.42 0.50 -0.15 -0.16 -1.29 0.19 -0.57 -0.81 0.02 0.04 1.51 2.00* 3.98 4.73* 5.9 9.0* 6.35 10.2* 6.97 13.9* 6.89 12.8* % 2 R 0.1 0.7 0.1 0.1 1.91 0.6 0.1 3.5 21.1 50.6 62.4 72.1 70.2
Les statistiques t nous indiquent que la volatilité réalisée prédit les rendements entre 3.5% et 72.1% pour un horizon variant entre 60 et 120 mois. Pour des horizons variant entre 1 et 48 mois, nos statistiques sont non significatives à l’exception de l’horizon h=3. Nous confortons donc les conclusions de Bandi et Perron (2008) à savoir que la volatilite réalisée prédit bien les rendements sur le long terme et que sa capacité de prédiction est d’autant plus grande que l’horizon augmente. Une restriction18
qui pourrait utile serait de contraindre la constante à être égale à zéro. Mais dans le cadre de nos estimations cette dernière est significative sur presque tous les horizons contrairement au papier de base de Bandi et Perron ou la constante n’était presque pas significative.
18
D’un point de vue statistique cette restriction est justifiable car elle peut augmenter la précision de la pente de notre équation. En effet, dans un modèle de régression uni variée avec des régresseurs prédéterminés x, la variance de la pente de l’estimateur va de
n i 1 xi x 2 2 à
n i 1xi 2 2 quand on impose la restriction.
22
Je reprends la même analyse en utilisant toute la période d’étude. Les résultats sont présentés dans le tableau ci-dessous.
Tableau 4 - Résultats de la régression des rendements excédentaires sur la volatilité réalisée pour différents horizons pour la période 1952-2009. (Rtth h h th,t t,th
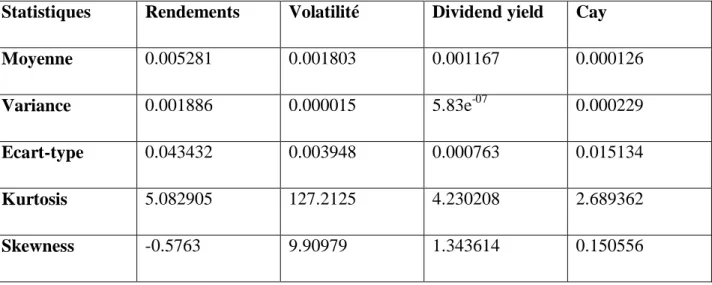
2 , ) h 1 3 6 12 24 36 48 60 72 84 96 108 120 t 0.007 4.27* 0.01 2.78* 0.02 2.27* 0.06 3.12* 0.14 3.94* 0.18 4.3* 0.22 4.37* 0.22 3.28* 0.16 1.88 -0.01 -0.13 -0.21 -1.88 -0.47 -6.0* -0.55 -6.0* t -1.06 -2.1* 0.05 0.07 0.81 1.55 -0.05 -0.07 -0.86 -1.01 -0.35 -0.53 -0.02 -0.05 0.61 0.99 1.57 2.00* 3.33 3.3* 4.89 5.26* 6.56 11.9* 6.81 13.3* % 2 R 0.8 0.1 1.3 0.1 0.9 0.1 0.1 0.9 6.4 21.8 36.5 55.3 61.4
Source : Calcul de l’auteur à partir de Stata
Le tableau précédent nous indique que les rendements excédentaires sont prédits par la volatilité réalisée à partir d’un horizon de 72 mois, tout comme les résultats retrouvés par Bandi et Perron (2008). En effet, entre 72 et 120 mois, les variations des rendements sont expliquées entre 6.4 et 61.4 %. Les valeurs de varient entre -1.06 et 6.81. A l’exception de la valeur h=1, nos statistiques t ne sont significatives qu’à partir de l’horizon h=72. Nous rappelons que nous avons utilisé les écarts-types de Newey-West pour tenir compte des problèmes d’autocorélation et d’hétérocédasticité. Nous notons que le R2
a diminué quand on tient compte de tout l’échantillon. Une explication possible est que la crise de 2008 a surpris tous les operateurs du marché, ce qui a grandement affecté la prévisibilité des rendements quand on étend l’échantillon.
4.2
Volatilité réalisée vs Autres prédicteursOn retrouve dans la littérature financière d’autres variables qui sont utilisées pour tenter de capter les variations de l’excès des rendements. L’une d’entre elle est le dividend yield19
. Je m’intéresse donc à présent à la question : comment on peut améliorer la capacité du modèle de
23
base utilisé précédemment en incluant la variable dy. J’ai régressé l’équation :
h t t t t h t h h t t dy R, 2 , ,
L’intuition c’est que si les prix d’un actif sont faibles, les dividendes (d/p) sont élevés, donc on peut s’attendre a des rendements élevés sur cet actif dans le futur d’où la capacité du dy à capter les variations des rendements. Les résultats sont présentés dans le tableau ci-dessous :
Tableau 5.- Résultats de la régression des rendements excédentaires sur la volatilité réalisée et le dividend yield pour différents horizons pour la période 1953-2009.
h 1 3 6 12 24 36 48 60 72 84 96 108 120 t 0.007 2.58* -0.02 -1.32 -0.05 -1.95 -0.09 -1.65 0.003 0.04 -0.03 -0.22 -0.14 -0.93 -0.35 -2.3* -0.57 -4.5* -0.82 -6.8* -1.03 -7.5* -1.23 -7.1* -1.31 -7.8* RV -1.45 -3.8* -0.23 -0.34 0.54 1.23 0.72 1.05 -0.16 -0.20 0.28 0.38 0.91 1.29 1.81 2.77* 2.71 4.52* 3.82 5.9* 4.64 6.94* 5.42 9.23* 5.75 10.4* dy 0.069 0.04 10.28 2.5* 11.64 3.04* 9.69 2.83* 3.95 1.58 4.25 2.08* 5.21 3.02* 6.51 5.03* 7.05 8.62* 7.16 8.0* 6.96 6.05* 6.63 4.97* 5.91 5.17* % 2 R 1.4 2.4 5.4 6.95 2.9 4.8 9.6 19.36 34.52 52.9 65.7 71.8 74.5
Source : calcul de l’auteur à partir de Stata
L’inclusion de la variable dy a quelque peu renforcé la performance du modèle original. D’une part la statistique t liée au coefficient de RV est significative entre 60 et 120 mois contre 72 et 120 mois dans le modèle univarié. D’autre part, dans la version augmentée du modèle, le R2
est beaucoup plus élevé ce qui sous entend le caractère explicatif additionnel du dividend yield. En effet, dans le modèle bi variée, le dividend yield et la volatilité réalisée contribuent à expliquer les variations des rendements entre 19.36 et 74.5 % contre un intervalle de 6.4 et 61.4% dans le modèle univarié. Noter aussi le caractère très significatif du dividend yield sur presque tous les niveaux d’agrégation contrairement au RV. Ceci confirme l’idée que la volatilité réalisée permet bien de capter les variations des rendements sur le long terme.
24
Je refais la même démarche en incluant cette fois ci le cay et la volatilite dans la régression. J’ai régressé l’équation suivante : Rt,th h2th,t cayt t,th
J’ai utilisé les écarts-types de Newey-West (1987) pour tenir compte des problèmes d’autocorélation et d’hétérocédasticité bien connu dans la littérature. Les résultats son présentés dans le tableau suivant :
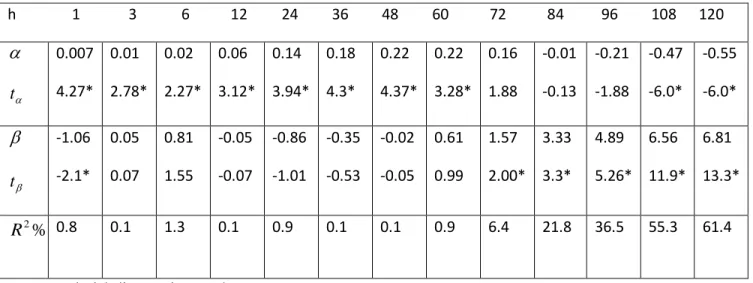
Tableau 6.- Résultats de la régression des rendements excédentaires sur la volatilité réalisée et le CAY pour différents horizons pour la période 1952-2009.
h 3 6 12 24 36 48 60 72 84 96 108 120 t 0.01 2.33* 0.02 1.59 0.04 1.71 0.102 1.93 0.103 1.7 0.102 1.25 0.07 0.62 -0.01 -0.05 -0.24 -1.24 -0.54 -2.5* -0.94 -5.2* -1.17 -6.7* RV -0.18 -0.28 0.77 1.63 0.39 0.44 -0.19 -0.17 0.47 0.55 0.88 1.15 1.49 1.68 2.45 1.99* 4.59 2.9* 6.77 4.5* 9.07 8.6* 9.99 11.2* cay 1.31 2.99* 1.37 3.02* 1.23 3.24* 1.04 3.7* 0.85 3.90* 0.70 2.69* 0.58 2.21* 0.42 2.01* 0.19 1.61 0.01 0.08 -0.13 -1.00 -0.27 -3.4 % 2 R 4.46 10.03 13.4 18.88 17.9 15.8 14.8 16.7 27.2 41.2 61.7 73
Source : Calcul de l’auteur à partir de Stata
Tout comme dans le cas précédent, l’inclusion du cay a contribué à augmenter la performance de notre modèle. En effet pour les horizons où le Rv est significatif, on enregistre un R2 entre 16.7 et 73% contre 6.4 et 61.4% dans le modèle uni varié. Noter que malgré l’inclusion du cay, la volatilité réalisée reste significatif à partir de 72 mois tout comme dans le cas uni varié, ce qui confirme encore une fois la capacité de cette variable à capter les variations des rendements sur le long terme.
Lettau et Ludvigson (2001) ont montré que le ratio consommation- richesse (cay) a un pouvoir explicatif des attentes futures sur les rendements plus élevés que le dividend yield. Mais dans les
25
deux régressions, nous remarquons que ces deux variables améliorent les performances du modèle original à peu près dans les mêmes proportions.
26
5.-
Inférence en utilisant l’estimateur de Hodrick (1992)
A présent nous allons tenter de voir comment vont évoluer les conclusions de Bandi et Perron (2008) quand on applique les écart-types proposés par Hodrick (1992). Comme il est mentionné dans la littérature financière, il existe un doute concernant la validité des tests de significativité lié au fait que la distribution en échantillon fini s’éloigne de la loi normale et aussi du fait de la présence d’autocorélation sérielle dans les résidus induits par l’agrégation sur plusieurs périodes des différentes variables utilisées lors de la régression. Donc pour tenir compte de ce problème, il est nécessaire d’utiliser des écart-types robuste à la présence d’autocorélation. Mais le choix de l’écart-type est très important ; comme l’ont mentionné Ang et Bekaert (2007), les résultats de la régression pourraient évoluer suivant le type d’écart-type utilisé…Aussi ils suggèrent que l’écart-type proposé par Hodrick (1992) fait mieux que le Newey-West (1987) et le Hansen-Hodrick (1980) car ces deux derniers conduisent à un rejet excessif de l’hypothèse nulle de non prédictabilité. Entre autre cet estimateur permet d’éviter la sommation des matrices d’autocorélation, source de biais selon l’auteur.
Commençons par considérer comment on calcule cet estimateur. Soit la régression linéaire suivante : t k t t t k t z u r , ' ,
Où zt
1,xt' 'et ˆ l’estimateur par moindre carré ordinaire (MCO) du coefficient. ˆ est tel que
N
VT ˆ d 0, où V A1BA1
L’estimateur de Hodrick (1992) de V est ˆ ˆ1~ˆ1 A B A V avec
T t t tz z T A 1 ' 1 ˆ et
T k t t twk wk T B~ 1 ' où
1 0 1 , 1 ˆ k i i t t t u zwk et uˆt1,1 représente les résidus obtenus pour la régression des rendements sur une période (h=1).
27
Considérons à présent les modèles retenus dans la section 4 où on a régressé les rendements excédentaires sur la volatilité réalisée. On avait conclu que la volatilité réalisée permettait de prédire les variations des rendements sur le long terme, à partir d’un horizon de 72 mois pour le modèle avec constante. J’ai donc repris ces mêmes modèles, en utilisant cette fois ci les écart-types de Hodrick (1992) pour tenir compte des problèmes d’autocorélation. Nos résultats sont présentés dans le tableau ci-dessous :
Tableau 7 - Résultats de la régression des rendements excédentaires sur la volatilité réalisée pour différents horizons pour la période 1952-2009.
h 1 3 6 12 24 36 48 60 72 84 96 108 120 Modèle avec constante : Rtth h h th,t t,th
2 , H t 4.31* 2.77* 1.89 2.54* 2.48* 1.92 1.67 1.46 0.9 -0.05 -0.54 -0.96 -0.95 H t -1.97 0.05 0.86 -0.04 -.048 -0.19 -0.01 0.41 1.04 1.46 1.52 1.76 1.77 N t -2.1* 0.07 1.55 -0.07 -1.01 -0.53 -0.05 0.99 2.00* 3.3* 5.2* 11.9* 13.3* Modèle sans constante : Rtth h th,t t,th
2 , H t -0.73 0.9 1.76 1.73 1.61 1.87 2.15* 2.57* 2.8* 2.7* 2.59* 2.53* 2.6* N t -0.56 0.92 3.14* 2.7* 3.5* 5.69* 7.5* 7.7* 8.8* 10.9 13.1* 16* 19.3*
Source : Calcul de l’auteur à partir de RATS
Dans le modèle avec constante, la statistique t de Hodrick est inférieure à celle de Newey-West pour la pente de l’équation et confirme bien qu’elle permet d’éviter de rejeter trop souvent la nulle comme Ang et Beckaert (2007) l’ont souligne dans leur papier. Toutefois la t de Hodrick associée à la pente n’est significative sur aucune des périodes. Donc avec les écart-types de Hodrick (1992), on ne peut rejeter l’hypothèse nulle d’absence de prévisibilité des rendements excédentaires. Ceci remet en question la capacité de la volatilite réalisée à expliquer les variations des rendements que ce soit sur le court ou le long terme contrairement aux résultats trouvés par Bandi et Perron (2008). Du coup les suggestions de Ang et Beckaert semblent justes,
28
les résultats de la régression dépendent effectivement de l’écart-type utilisé pour corriger les problèmes d’hétérocédasticité et d’autocorélation sérielle recensés dans la littérature financière.
Le modèle contraint20 fonctionne beaucoup mieux. En effet, la statistique de Hodrick associe a la pente est significative mais seulement à partir de la quarante-huitième période (h=48). Nous remarquons une fois de plus que la t de Hodrick est de loin inferieure à celle de Newey-West (2.1 contre 7.5 pour un horizon h=48) ceci confirme encore une fois la capacité de cet estimateur à éviter de rejeter trop souvent l’hypothèse nulle d’absence de prévisibilité des rendements. Toutefois dans le cadre du modèle contraint, l’application de la t de Hodrick ne change pas profondément les résultats fondamentaux retrouvés dans le papier de Bandi et Perron (2008). La volatilité conserve bien sa capacité à prédire les rendements sur le long terme.
20
29
6.-
Conclusion
Ce rapport avait pour objectif de tester l’hypothèse de non prévisibilité des rendements excédentaires d’un actif financier. Pour ce, le papier de Bandi et Perron (2008) a été revisité ou il a été question de voir si les résultats de ces derniers tiennent quand on applique les écart-types proposés par Hodrick (1992). La suite de la recherche nous a permis de reconfirmer la capacité de la volatilité réalisée à capter les variations sur le long terme des rendements (72 à 120 mois) qu’elle explique entre 6.6 et 61.4% en utilisant les écart-types de Newey-West (1987). L’introduction du ratio dividende prix ou celui de l’indice consommation richesse agrégée dans le modèle de base ont contribué à améliorer la performance de la prévisibilité à long terme. Toutefois, l’utilisation de l’écart-type de Hodrick met un bémol par rapport aux résultats trouvés par Bandi et Perron (2008). En effet, dans le modèle avec constante, pour tous les niveaux d’agrégation considérés (h>1), les statistiques de Student ne sont pas significatif pour un seuil de 5% ; ce qui rejette les résultats retrouvés ci-haut et nous permet de douter de la capacité de la volatilité réalisée à prévoir les variations des rendements en présence de cet estimateur. Rappelons que dans la littérature, Ang et Bekaert (2007) avait trouvé des résultats contradictoires à ceux de Fama et French (1988) en utilisant les écart-types de Newey-West (1987) d’une part et ceux de Hodrick (1992) d’autre part.
Pourtant quant on contraint l’intercepte à prendre la valeur zéro, on confirme les résultats de Bandi et Perron (2008).
30
7-
Bibliographie
1. Ang, A. and G. Bekaert (2007), "Stock Return Predictability: Is it There?” The Review of Financial Studies, 651-707
2. Bandi, F. and B. Perron, (2008), “Long-run Excess-returns trade-offs”, Journal of Econometrics, 350-374
3. Fama, E. and K. French (1988), "Dividend Yields and Expected Stock Returns", Journal of Financial Economics, 22, 3-25.
4. Goyal, A. and I. Welch (2008), "A Comprehensive Look at the Empirical Performance of Equity Premium Prediction”, Review of Financial Studies, 1455-1508.
5. Hodrick, R.J. (1992), "Dividend Yields and Expected Stock Returns: Alternative Procedures for Inference and Measurement", Review of Financial Studies, 5, 357-386.
6. Lettau, M. and S. Ludvigson (2001), "Consumption, Aggregate Wealth, and Expected Stock Returns", Journal of Finance, 815-849.
7. Newey, W. and K. West (1987), "A Simple Positive Semi-Definite, Heteroskedasticity and Autocorrelation Consistent Covariance Matrix", Econometrica, 703-708.
8. John Y. Campbell and Robert J. Shiller (1986), “The dividend price ratio and expectations of future dividends and discout factors”, Cowles foundation discussion paper no 812.
9. Samuelson P. (1965), “Proof that Properly Anticipated Prices Fluctuate Randomly”, Industrial Management Review, pp. 6, 41-50.
10. Grossman S. et Stiglitz J. (1980), “On the Impossibility of Informationaly Efficient Markets”, American Economic Review, pp. 393-408.
11. Jacob Boudoukh, Mathew Richardson and Robert Whitelaw, “The myth of long run horizon predictability”, National bureau of economic research, Working paper no 11841.
12. Campbell J.Y. et Thompson S.B. (2008). Predicting Excess Returns Out of Sample:Can Anything Beat the Historical Average. Review of Financial Studies, 1509-1530.