Université de Montréal
Inferring API Usage Patterns and Constraints: a Holistic Approach
par
Mohamed Aymen Saied
Département d’informatique et de recherche opérationnelle Faculté des arts et des sciences
Thèse présentée à la Faculté des études supérieures et postdoctorales en vue de l’obtention du grade de Philosophiæ Doctor (Ph.D.)
en Informatique
Août, 2016
Résumé
Les systèmes logiciels dépendent de plus en plus des librairies et des frameworks logiciels. Les programmeurs réutilisent les fonctionnalités offertes par ces librairies à travers une interface de pro-grammation (API). Par conséquent, ils doivent faire face à la complexité des APIs nécessaires pour accomplir leurs tâches, tout en surmontant l’absence de directive sur l’utilisation de ces API dans leur documentation. Dans cette thèse, nous proposons une approche holistique qui cible le problème de réutilisation des librairies, à trois niveaux. En premier lieu, nous nous sommes intéressés à la réutili-sation d’une seule méthode d’une API. À ce niveau, nous proposons d’identifier les contraintes d’uti-lisation liées aux paramètres de la méthode, en analysant uniquement le code source de la librairie. Nous avons appliqué plusieurs analyses de programme pour détecter quatre types de contraintes d’uti-lisation considérées critiques. Dans un deuxième temps, nous changeons l’échelle pour nous focaliser sur l’inférence des patrons d’utilisation d’une API. Ces patrons sont utiles pour aider les développeurs à apprendre les façons courantes d’utiliser des méthodes complémentaires de l’API. Nous proposons d’abord une technique basée sur l’analyse des programmes clients de l’API. Cette technique per-met l’inférence de patrons multi-niveaux. Ces derniers présentent des relations de co-utilisation entre les méthodes de l’API à travers des scénarios d’utilisation entremêlés. Ensuite, nous proposons une technique basée uniquement sur l’analyse du code de la librairie, pour surmonter la contrainte de l’existence des programmes clients de l‘API. Cette technique infère les patrons par analyse des re-lations structurelles et sémantiques entre les méthodes. Finalement, nous proposons une technique coopérative pour l’inférence des patrons d’utilisation. Cette technique est axée sur la combinaison des heuristiques basées respectivement sur les clients et sur le code de la librairie. Cette combinaison permet de profiter à la fois de la précision des techniques basées sur les clients et de la généralisabilité des techniques basées sur les librairies. Pour la dernière contribution de notre thèse, nous visons un plus haut niveau de réutilisation des librairies. Nous présentons une nouvelle approche, pour identi-fier automatiquement les patrons d’utilisation de plusieurs librairies, couramment utilisées ensemble, et généralement développées par différentes tierces parties. Ces patrons permettent de découvrir les possibilités de réutilisation de plusieurs librairies pour réaliser diverses fonctionnalités du projets.
Mots clés : Compréhension de programme, utilisabilité des API, inférence de patrons et contraintes d’utilisation, documentation des API.
Abstract
Software systems increasingly depend on external library and frameworks. Software developers need to reuse functionalities provided by these libraries through their Application Programming Inter-faces (APIs). Hence, software developers have to cope with the complexity of existing APIs needed to accomplish their work, and overcome the lack of usage directive in the API documentation. In this thesis, we propose a holistic approach that deals with the library usability problem at three levels of granularity. In the first step, we focus on the method level. We propose to identify usage constraints related to method parameters, by analyzing only the library source code. We applied program anal-ysis strategies to detect four critical usage constraint types. At the second step, we change the scale to focus on API usage pattern mining in order to help developers to better learn common ways to use the API complementary methods. We first propose a client-based technique for mining multi-level API usage patterns to exhibit the co-usage relationships between API methods across interfering usage scenarios. Then, we proposed a library-based technique to overcome the strong constraint of client programs’ selection. Our technique infers API usage patterns through the analysis of structural and semantic relationships between API methods. Finally, we proposed a cooperative usage pattern mining technique that combines client-based and library-based usage pattern mining. Our technique takes advantage at the same time from the precision of the client-based technique and from the gener-alizability of the library-based technique. As a last contribution of this thesis, we target a higher level of library usability. We present a novel approach, to automatically identify third-party library usage patterns, of libraries that are commonly used together. This aims to help developers to discover reuse opportunities, and pick complementary libraries that may be relevant for their projects.
Keywords: Program comprehension, API usability, usage pattern mining, usage constraint inference, API documentation.
Contents
Résumé . . . ii Abstract . . . iii Contents . . . iv List of Tables . . . ix List of Figures . . . xi Dedication . . . xiii Acknowledgments . . . xiv Chapter 1: Introduction . . . 1 1.1 Research context . . . 1 1.2 Problem statement . . . 21.3 Research objectives and main contributions . . . 4
1.4 Dissertation organization . . . 5
Chapter 2: Related Work . . . 7
2.1 Empirical studies on API usability . . . 7
2.2 API documentation techniques . . . 10
2.3 API property inference . . . 12
2.3.1 Unordered usage patterns . . . 12
2.3.2 Sequential usage patterns . . . 14
2.3.3 API constraint . . . 15
2.3.4 API migration and mapping . . . 16
I
Library usability at the API method scope
19
Chapter 3: API Usage Constraints Inference . . . 20
3.1 Introduction . . . 20
3.2 Motivating examples . . . 21
3.3 Approach . . . 23
3.3.1 Constraint type selection . . . 23
3.3.2 Detection strategies . . . 24
3.3.2.1 Nullness not allowed analysis . . . 24
3.3.2.2 Nullness allowed analysis . . . 25
3.3.2.3 Range limitation analysis . . . 26
3.3.2.4 Type restriction analysis . . . 26
3.4 Evaluation . . . 28
3.4.1 Detection validity evaluation . . . 28
3.4.1.1 Setting . . . 28
3.4.1.2 Results . . . 30
3.4.2 Detection usefulness evaluation . . . 31
3.4.2.1 Setting . . . 31
3.4.2.2 Results . . . 35
3.5 Threats to validity . . . 41
3.6 Conclusion . . . 42
II
Library usability across complementary API methods
43
Chapter 4: Mining Multi-level API Usage Patterns . . . 444.1 Introduction . . . 44
4.2 Motivation examples . . . 45
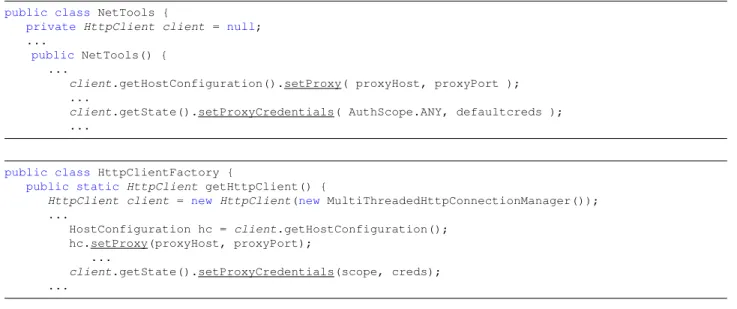
4.2.1 HttpClient Authentication . . . 45
4.2.2 The Swing GroupLayout’s interface . . . 47
4.3.1 Multi-level API usage patterns . . . 48
4.3.2 Approach overview . . . 50
4.3.3 Information encoding of API methods . . . 50
4.3.4 Clustering algorithm . . . 51
4.3.5 Incremental clustering . . . 52
4.4 Evaluation . . . 55
4.4.1 Systems studied . . . 56
4.4.2 Comparative evaluation . . . 57
4.4.3 Metrics and experimental setup . . . 58
4.5 Results analysis . . . 60
4.5.1 Patterns cohesion (RQ1) . . . 60
4.5.2 Patterns generalization (RQ2) . . . 61
4.6 Discussion . . . 65
4.7 Conclusion . . . 66
Chapter 5: Mining API Usage Patterns only using the Library Source Code . . . 68
5.1 Introduction . . . 68
5.2 Motivation examples . . . 70
5.2.1 Java Security example . . . 70
5.2.2 AWT Example . . . 71
5.3 Approch . . . 71
5.3.1 Information encoding of API methods . . . 73
5.3.2 Similarity and distance metrics . . . 74
5.3.3 Incremental clustering . . . 75
5.4 Evaluation . . . 76
5.4.1 Comparative evaluation . . . 76
5.4.2 Experimental setup . . . 77
5.5 Results analysis . . . 78
5.5.1 Impact of used heuristics (RQ1) . . . 78
5.6 Discussion . . . 84
5.7 Conclusion . . . 85
Chapter 6: A Cooperative Approach for Combining Client-based and Library-based API Usage Pattern Mining . . . 86
6.1 Introduction . . . 86
6.2 Motivation examples . . . 87
6.3 Approch . . . 88
6.3.1 Overview . . . 88
6.3.2 Cooperative patterns mining . . . 90
6.3.2.1 Cooperative sequential combination . . . 90
6.3.2.2 Cooperative parallel combination . . . 92
6.4 Evaluation . . . 93
6.4.1 Comparative evaluation . . . 93
6.4.2 Experimental setup . . . 94
6.4.2.1 Impact of used combination strategies (RQ1) . . . 94
6.4.2.2 Comparative evaluation (RQ2) . . . 95
6.5 Results and discussion . . . 96
6.5.1 Impact of used combination strategies (RQ1) . . . 96
6.5.2 Comparative evaluation (RQ2) . . . 98
6.5.2.1 Number and size of inferred patterns . . . 98
6.5.2.2 Cross-validation . . . 99
6.5.3 Discussion and threats to validity . . . 101
6.6 Conclusion . . . 102
III
Library usability across complementary software libraries
103
Chapter 7: Automated Inference of Software Library Usage Patterns . . . 1047.1 Introduction . . . 104
7.2.1 Learning-environment example . . . 106
7.2.2 Web application frontend example . . . 107
7.2.3 Challenges: mining library usage . . . 107
7.3 Approach . . . 108
7.3.1 Approach overview . . . 108
7.3.2 Multi-layer library co-usage pattern mining . . . 109
7.3.3 Pattern visual exploration . . . 112
7.4 Empirical evaluation . . . 113
7.4.1 Data collection . . . 114
7.4.2 Sensitivity analysis . . . 115
7.4.2.1 Analysis method . . . 115
7.4.2.2 Results for RQ1 . . . 115
7.4.3 Evaluation of patterns cohesion . . . 119
7.4.3.1 Analysis method . . . 120
7.4.3.2 Results for RQ2 . . . 120
7.4.4 Evaluation of patterns generalization . . . 121
7.4.4.1 Analysis method . . . 121 7.4.4.2 Results for RQ3 . . . 123 7.5 Discussion . . . 125 7.6 Conclusion . . . 127 Chapter 8: Conclusion . . . 129 8.1 Contributions . . . 129 8.2 Future Perspective . . . 131 Bibliography . . . 133
List of Tables
3.I Selected APIs for the detection evaluation . . . 29
3.II Constraints detection precision . . . 30
3.III Constraints detection recall . . . 31
3.IV Selected APIs . . . 32
3.V Number of Detected Constraints . . . 35
3.VI Number of Detected Constraints in JDK 7 . . . 37
4.I Selected APIs for the case study . . . 56
4.II Client programs used in our case-study for HttpClient & Java Security . . . 56
4.III Client programs used in our case-study for Swing & AWT . . . 57
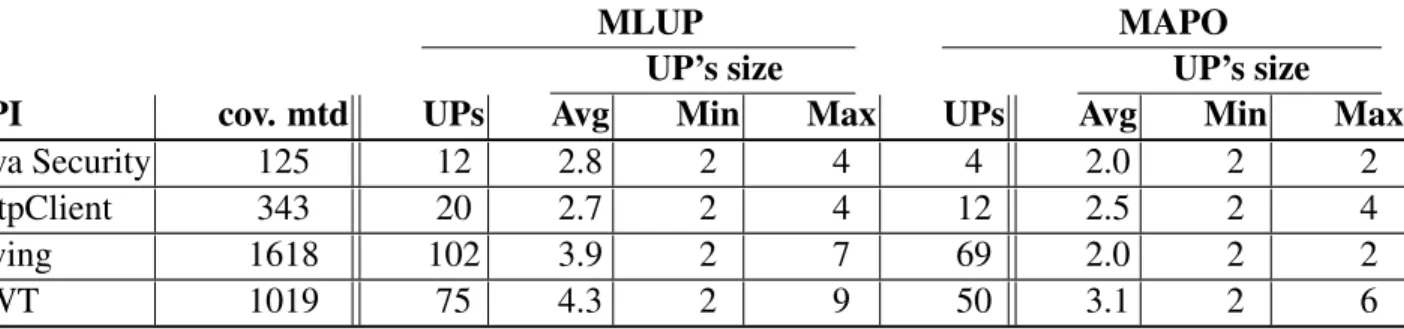
4.IV Overview on the number of covered/analyzed methods and the number of de-tected usage patterns per API . . . 61
4.V Average Cohesion of identified API usage patterns, for MLUP and MAPO. . . 61
4.VI Statistics on the Cohesion of identified API usage patterns for MLUP and MAPO , in validation clients . . . 63
4.VII Statistics on the Consistency of identified API usage patterns for MLUP and MAPO . . . 64
5.I Average Cohesion of identified API usage patterns, for NCBUPminer and MLUP . . . 83
5.II Overview on the number of covered/analyzed methods and the number of de-tected usage patterns per API . . . 84
6.I Average Cohesion of identified API usage patterns, for NCBUPminer, MLUP-miner and COUPMLUP-miner. . . 97
6.II Statistics on the Cohesion of identified API usage patterns for NCBUPminer, MLUPminer and COUPminer , in the contexts of validation clients . . . 100
6.III Statistics on the Consistency of identified API usage patterns for NCBUPminer, MLUPminer and COUPminer , across multiple validation clients. . . 101
7.I Dataset used in the experiment . . . 114 7.II Average cohesion and overview of the inferred usage patterns for LibCUP and
LibRec. . . 121 7.III Average Training and Validation Cohesion of identified usage patterns for LibCUP
and LibRec. . . 124 7.IV Recommendation recall rate and MRR results achieved by both LibCUP and
List of Figures
3.1 NullnessAnalysis example. . . 25
3.2 RangeLimitationAnalysis example. . . 27
3.3 Overview of the evaluation process. . . 33
3.4 side-by-side constraints description and javadoc. . . 34
3.5 Constraint classification taxonomy. . . 34
3.6 Documented vs non-documented constrains. . . 38
3.7 Explicit vs Implicit documentation. . . 39
3.8 Specific vs General documentation absence. . . 41
4.2 The cluster L2 which represents the MLUP of class GroupLayout: L0 repre-sents the GroupLayout’s core usage pattern, then the cluster L1/L2 includes partially/totally the GroupLayout’s peripheral usage pattern. . . 49
4.3 The usage vector representation of five API methods with seven client methods. 51 4.4 Resulting clusters of applying the incremental algorithm to API methods of Figure 4.3. . . 55
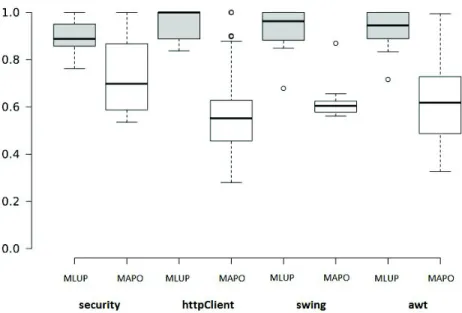
4.5 Cohesion values of identified API usage patterns, for MLUP (gray boxes) and MAPO (white boxes). . . 62
4.6 Cohesion values of identified API usage patterns, for MLUP and MAPO in the contexts of validation clients . . . 63
4.7 Consistency values of identified API usage patterns for MLUP and MAPO, across multiple validation clients. . . 65
5.1 Code snippets of Raster from GanttProject . . . 72
5.2 The state vector representation of 4 API methods. In this API, 8 fields (C1.f1 ... C4.f2) of 4 different classes (C1 ... C4) are manipulated by the API methods. . . 73
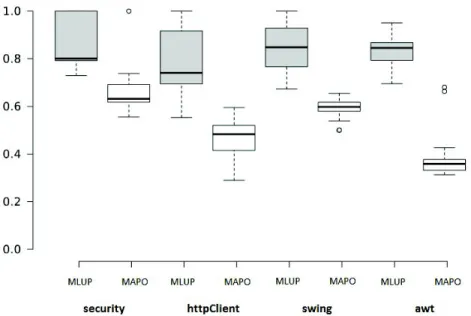
5.3 Average cohesion of inferred patterns using different heuristics . . . 79
5.4 Average number of inferred patterns using different heuristics . . . 80
5.6 Code snippet for validating certificate Chain, in method checkServerTrusted
from class Handler in Waterken. . . 83
6.1 Sequential combination start with the client-based mining . . . 91
6.2 Parallel combination start with the client-based mining . . . 92
6.3 Numberof inferred patterns using different techniques . . . 98
6.4 Average size of inferred patterns using different techniques . . . 99
6.5 Cohesion values of identified API usage patterns, for NCBUPminer, MLUP-miner and COUPMLUP-miner in the contexts of validation clients . . . 100
6.6 Consistency values of identified API usage patterns for NCBUPminer, MLUP-miner and COUPMLUP-miner across multiple validation clients. . . 101
7.1 The dependency vector representing the dependency between eight client pro-grams and eight libraries. . . 110
7.2 Resulting clusters of applying the incremental algorithm using ε-DBSCAN to the library dataset presented in Figure 7.1. . . 111
7.3 circle packing visualization . . . 113
7.4 Effect of varying maxE psilon parameter on the average cohesion of the identi-fied patterns. . . 116
7.5 Effect of varying maxEpsilon parameter on the number of identified patterns. . 117
7.6 Effect of varying maxE psilon parameter on the average number of clients per pattern. . . 118
7.7 Effect of varying the dataset size on the average pattern cohesion maxE psilon = 0.5. . . 118
7.8 Effect of varying the dataset size on the time efficiency with maxE psilon = 0.5. 119 7.9 PUC results of the identified library usage patterns in the contexts of training (T) and validation (V) clients achieved by each of LibCUP and LibRec. . . 124
I dedicate this thesis to my parents, AbdelKader & Hajer, my wife, Wafa, and my son, Ayoub.
Acknowledgments
First and formost, I would like to express my sincere appreciation and gratitude to my supervisor Professor Houari Sahraoui for his guidance during my research. His support and inspiring suggestions have been precious for the advancement of this thesis content. I appreciate all his contributions of time and ideas to make my Ph.D. experience productive. At difficult times, I draw my strength back from his energy and good mood, and his advices go beyond academic research. One simply could not wish for a better supervisor.
I would like to thank Professor Tien N. Nguyen for accepting to be my external examiner and for furnishing efforts to review my dissertation. I thank Professor Eugène Syriani for accepting to be on my PhD committee and for reviewing my dissertation. And I would also like to thank Professor Pierre Thibault for joining my PhD committee. Many thanks for Professor Sylvie Hamel for accepting to chair my doctoral committee.
Last but not least, I would like to salute the soul of my father. He would have been proud of me if he were among us today. I would like to express my special thanks to my mother. I would have never managed any of this without her support and sacrifices. My special thanks goes as well to my sister and my brother who never stopped believing in me. I would like to express my gratitude to my wife for her kindness and compassion she helped and encouragement me to outstrip all the diffuclties and finish my doctorate.
Chapter 1
Introduction
1.1 Research context
Software reuse is a common practice in the development and maintenance of a modern software system [26]. Indeed, modern industry builds software systems more and more by assembling features offered by libraries and application frameworks. This contributes in facilitating the development of complex systems with controlled costs while maintaining the delivery schedules, and quality [24].
Libraries expose the functionalities or services they provide through an interface API (Application Programming Interface). And software developers increasingly need to reuse functionality provided by external libraries through their APIs. Thus developers have to learn how to use existing APIs to benefit from them.
Documentation is an essential resource for software comprehension in general, but is a critical resource, in particular, for APIs usability and learning. API documentation usually specifies the way in which client software can interact with the library and reuse its functionalities independently of implementation details. Therefore, APIs benefits are dependent on documentation quality and completeness. Indeed, with an incomplete or missing documentation, the client application code may be inconsistent with the library implementation, and bugs may creep into the client programs [23]. Moreover, the benefits of using APIs do not come easily; different works on API usability showed that learning how to use APIs presents challenging barriers [37, 58, 59, 70, 72].
The number and the size of APIs are continuously growing, and developers have to cope with complexity of existing APIs that are needed to accomplish their work. Novice developers are faced with the significant difficulty of learning a large number of APIs. Even experienced developers must frequently learn newer parts of familiar APIs, or newly released APIs when working on new tasks. Moreover, with the emergence of the continuous deployment, frequent release of new versions, and time at their disposal, it is not possible for developers to learn all the APIs they need in depth. In this thesis, we are interested on how to help developers to easily learn common ways to correctly use the APIs.
1.2 Problem statement
Despite recent progress in API documentation and discovery, API usability is still a challenging problem. Client application developers have to deal with the library usability challenges at different levels. First, a developer has to cope with the library usability at the method level, when he is in-terested in a specific method of the API. Second, he has to deal with the usability at the global level of an API, when using complementary methods. Finally, developers often use more than one library and, then, they have to tackle the usability challenges when coordinating the use of distinct libraries that may be developed by different organizations. In the remainder of this section, we highlight the different problems and challenges addressed in this thesis that are mainly related to the identification of APIs usage patterns and constraints.
Library usability at the API method scope (first level)
Once an API method is selected, developers have to use it in a consistent way with its documen-tation and implemendocumen-tation. The main challenge is then to respect precondition on the method inputs, generally known as constraints on parameter values. Unfortunately, it often happens that the API us-age constraints are not explicitly described in the documentation. This may generate additional cost for debugging and correction, when the method usage constraints are violated. An interesting solution to the problem of undocumented usage constraints is to automatically recover them from the code.
Existing approaches are either interested in the redocumentation of a program in general [28, 67– 69] or interested specifically in the re-documentation of usage constraints of an API. For the second category, some existing works focused on the API side by analyzing the API documentation to infer API specifications [54]. Others specify API use constraints by manually adding annotations into the API code [33]. Such suggestions may be insufficient for large API and for the non-documented constraints.
To overcome the aforementioned problem, another piece of work, try to analyze client appli-cations, rather than the library documentation, to identify constraints [57, 86]. Regardless of the effectiveness of such approaches, the needs of client applications that cover the entire target library drastically limit their applicability.
Library usability across complementary API methods (second level)
The API methods are generally used by client programs jointly with other methods of the API. However, it is not obvious to deduce the co-usage relationships between API methods from their doc-umentations. The increasing size and complexity of APIs introduce an additional difficulty. Indeed large APIs are the most challenging to learn and use.
A large API may consist of several thousands public methods defined in hundreds classes. Since API classes are typically meant for a wide variety of usage contexts, the elaborated documentation of an API class may be very detailed as it tries to specify all aspects that a client might need to know about the class of interest. Hence, software developers might spend considerable time and effort to identify the subset of the class’s methods that are necessary to implement their task. Therefore, identi-fying usage patterns for the API can help to better learn common ways to use the API complementary methods.
Existing techniques for mining API usage patterns are valuable to facilitate API learning and usage. However, existing techniques mainly identify flat usage patterns for specific usage scenario. Such techniques are proposed to recommend usage examples relevant to one task (e.g. [87]), and/or for auto-completion in a specific context (e.g. [50]). Accordingly, inferred usage pattern cannot reflect the different interfering API usage scenarios, which is definitely required to improve the API learning resource.
From another perspective and despite the different aspects they try to cover, existing techniques are all based on client programs’ code. Which is a strong constraint since client programs’ code is unfortunately not available for both newly released libraries and APIs which are not widely used. Moreover, it is not possible to collect client programs that cover all the potential usage scenarios of the API of interest. Indeed, client-based identification of API usage patterns can be used only for a subset of the API of interest that is the set of the API methods which are already used, multi-times, by different selected clients of the API.
Library usability across complementary software libraries (third level)
Nowadays, open source repositories provide a wide range of reuse opportunities of functionality provided by well-tested and mature third-party libraries. However, as software libraries are
docu-mented separately but intended to be used together, developers are unlikely to fully take advantage of these reuse opportunities.
Much research effort has been dedicated to the identification of API usage patterns [79, 81, 87]. The vast majority of existing works focus on usage patterns within a single library. Indeed, these approaches assume that the set of relevant libraries is already known to the developer. However, this assumption makes the task of finding relevant libraries and understanding their usage trends a tedious and time-consuming activity.
Software developers can spend a considerable amount of time and effort to manually identify libraries that are useful for the implementation of their software. Worse yet, developers may even be unaware of the existence of these libraries. Thus, they may tend to implement most of their features from scratch instead of reusing functionalities provided by third-party libraries as pointed out by several researchers [18, 79]. Therefore, we believe that identifying patterns of libraries that are commonly used together, can help developers to discover and choose libraries that may be relevant for their projects’ implementation.
All of these observations are at the origin of the work conducted in this thesis. In the next section, we give an overview of our research directions to address the above-mentioned problems.
1.3 Research objectives and main contributions
The main objective of this thesis is to propose a holistic approach that deals with the usability problem at the different levels of granularity when using external libraries. To overcome the previ-ously identified problems, we propose the following contributions, organized into three major parts, each corresponding to a specific level of library reuse.
Part 1: the method level
Our first contribution helps developers to comply with the constraints on API method parameters. We propose to identify constraints by analyzing only the library source code. We selected four critical usage constraint types related to method parameters. This is done by static and intra-procedural analysis on control flow graphs to detect the selected constraints.
We also conduct an observational study on a large set of libraries to evaluate the presence of selected constraints in the code and the degree of their documentation as an indication of the risk of constraint violation.
Part 2: the library level
Our second contribution is related to API usage pattern mining to help developers to better learn common ways to use the API complementary methods.
We first propose a client-based technique for mining multi-level API usage patterns to exhibit the co-usage relationships between API methods across interfering usage scenarios. Our technique is based on an adaptation of a clustering algorithm, and the analysis of the frequency and consistency of co-usage relations.
Then, we proposed a library based technique to overcome the strong constraint of client programs selection. Our technique infers API usage patterns through the analysis of structural and semantic relationships between API methods. This technique can even be applied to “new” APIs, for which client programs are not available yet.
Finally, we proposed a cooperative usage pattern mining technique that combines client-based and library-based usage pattern mining. Our technique takes advantage at the same time from the precision of client-based technique and from the generalizability of library-based techniques.
Part 3: the group of libraries level
Our third contribution adds a new dimension to the library usability problem. We present a novel approach, to automatically identify third-party library usage patterns, as a collection of libraries that are commonly used together by developers. This approach is meant to help developers to discover and use libraries that may be relevant for their projects. Thus we mine the ’wisdom of the crowd’ to discover usage patterns of software libraries. We evaluate the efficiency of our approach on an extremely large dataset of popular libraries and client systems.
1.4 Dissertation organization
This thesis is organized as follows. Chapter 2 discusses previous research contributions that are relevant to the main themes of this dissertation: API documentation techniques, API usage patterns
mining techniques and API usage constraints inference techniques. The first part of the thesis core consists of Chapter 3 that reports on our contribution for the detection of API usage constraints. The second part of the thesis includes three chapters. Chapter 4 describes our first technique for API usage pattern mining. We present our clustering adaptation to mine co-usage relations from API client programs. In Chapter 5, we detail our second technique for API usage pattern mining using only the library code. We investigate different library-based heuristics to infer patterns of complementary API methods. In Chapter 6, we investigate deferent strategies to combine the client-based and the library-based mining of API usage patterns. In the third part of the thesis (Chapter 7), we introduce a new dimension to the library usability, in which we consider usage patterns of groups of software libraries. Finally, Chapter 8 summarizes the contributions of the work presented in this thesis, underlines its main limitations, and describes our future research directions.
Chapter 2
Related Work
In this chapter, we provide a literature review on research work related to this thesis. First, we give an overview of empirical studies on API usability to highlight the factors that hinder the API usage and learning process (Section 2.1). Then, we present the work that targets the automation of API documentation to reduce the difficulty of learning how to use APIs (Section 2.2). Finally, we discuss the related work relevant to the main themes of this research work. This includes several approaches for extracting API usage information, and the related work according to the inferred API property (Section 2.3). We classify the inferred properties into mainly four classes: (i) unordered usage patterns, (ii) sequential usage patterns, (iii) API constraints, and (iv) API migration and map-ping considerations. We conclude this chapter with a discussion on the limitations of the presented research contributions (Section 2.4).
2.1 Empirical studies on API usability
Previous studies on API usability try to identify factors that hinder the usability and learnability of APIs.
Ellis et al. conducted a study, with twelve participants, to evaluation with five programming tasks the usability of the Factory pattern in API design as compared to constructors for object creation [20]. The authors observed that the participants spent significantly more time to create an object from factories used in APIs than with a constructor. Additionally, the results suggest that the use of factories in APIs should be avoided in many cases where other techniques, such as constructors, can be used instead. In the same context,
Stylos et al. conducted a user comparative study to assess how developers use APIs with required parameters in objects’ constructors as opposed to parameter-less "default" constructors [70]. Six pro-graming tasks and thirty professional developers were involved in the study. One may presume that parameters would create more usable and self-documenting APIs by guiding developers toward the
correct use of objects and preventing errors. However, the study reported that unexpectedly, develop-ers strongly preferred and were more efficient with APIs that did not require constructor parametdevelop-ers.
In another study, Stylos et al. evaluated the impact of method placement on the API usability. On which class or classes a method is placed is important since developers often start their exploration of an API from one "main" class. The study reports that participants were significantly faster at identi-fying relevant dependencies and combining objects when a class from which users generally start to explore an API had methods that reference other classes in the API. This significantly enhanced the productivity of the developers [72].
Other studies looked at the role of web resources in learning how to use APIs. Brandt et al. observed, in a lab study involving twenty participants and five tasks, that programmers used the Web primarily for just-in-time learning of new skills, and to clarify or remind themselves of previously acquired knowledge [9]. In a different study, Stylos et al. identified several challenges developers encounter when using the Web to find API elements and usage examples. For instance finding the right terminology to describe API concept, spending time looking at irrelevant search results. Even when a search did yield some relevant results, if the first few documents the developers browsed did not seem relevant, they would often give up [71].
The more recent studies were interested in understanding the difficulties encountered with unfa-miliar APIs. In his study, Robillard investigated the obstacles professional developers at Microsoft faced when learning how to use APIs [58]. Around 80 developers answered the survey and a se-ries of 12 interviews was conducted to identify what exactly does make an API hard to learn. The overarching result of this study is that the resources available to learn an API are important and that shortcomings in this area hinder the API learning progress.
In an another study, Robillard et al. collected the opinions and experiences of over 440 profes-sional developers and report on the obstacles developers face when learning new APIs, with a special focus on obstacles related to API documentation [59]. The study shows that when developers learn a new API they struggle not so much in the mechanics of using the API, but in understanding how the API relates towards its problem domain. The study found that developers need help mapping desired scenarios in the problem domain to the content of the API, and in understanding what scenarios or usage patterns the API provider intends and does not intend to support. Thus showing a pattern of related calls is preferred to illustrations of individual methods. The study also found that developers
want to understand how the API’s implementation consumes resources, reports errors and has side effects.
In the same context, Duala-Ekoko et al. conducted a study in which twenty participants completed programming tasks using real-world APIs [19]. Through a systematic analysis of the screen captured videos and the verbalizations of the participants, the study isolated twenty different types of questions the programmers asked when learning to use APIs. Among the identified question, the following two held our attention.
– What is the valid range of values for a primitive argument, such as an integer, of a given method? – Is NULL a valid value for a non-primitive argument of a given method?
Discussion forums were also explored to understand developers’ needs. Hou et al. conducted an exploratory study in which they manually analyzed in detail 172 programmer discussions, from a newsgroup, about specific challenges that programmers had about software APIs [32]. The objective was to identify what makes APIs hard to use, and what can be done to alleviate the problems associ-ated with API usability and learnability. The study identified several categories of obstacles in using APIs. The most prominent observation was that developer asked for API usage solutions without ac-tually attempted anything concretely, especially when the programing tasks require the composition of API methods calls. Another arresting obstacle was the incorrect usage of APIs. In this case, the developer generally tries the right solution but the program does not work as expected due to mistakes in performing certain steps of the solution. Sometimes, a mistake was made by supplying the wrong parameter values to some API methods. And in some cases, this was because the programmer is unaware of the special constraints that the API method imposes [32]. A similar study was conducted by Wang et al. [82]. The study explored API usage obstacles through analyzing API-related posts regarding iOS and Android development from a Q&A website. The Study reported some scenarios that appear to be the common cause of API usage obstacles, and presented a list of iOS and Android classes that often cause usage obstacles without being frequently used.
2.2 API documentation techniques
The impact of documentation on the usability of APIs has also been an area of active research [16, 36, 44, 48, 73, 78]. Researchers attempt to make API documentation accessible and understandable to programmers.
Recent studies were interested in determining important types of knowledge conveyed in API ref-erence documentations. Maalej et al. report on a study of the nature and organization of knowledge contained in the reference documentation of hundreds of APIs [44]. They provided a global perspec-tive on 12 types of knowledge conveyed in API documentation and their distribution throughout the reference documentation. Maalej et al. found that functionality knowledge is pervasive and structure is common, while other types, such as concepts and purpose, are much rarer.
Similarly, Monperrus et al. performed an extensive empirical study on the directives of API docu-mentation [48]. The study proposed a taxonomy of 23 types of directives present in the docudocu-mentation of Java APIs. The taxonomy was constructed by analyzing more than 4000 API documentation items. The taxonomy consists of the following high-class directives.
– Method Call Directives: related to constraints and guidelines when calling a particular library method.
– Subclassing Directives: related to requirement that has to be satisfied when subclassing a library class.
– State Directives: related to requirement on the internal state of receivers of a given method call. – Alternative Directives: related to alternative implementations of given API element.
– Synchronisation Directives: related to concurrency on an API element.
– Miscellaneous Directives: directives related to software environment in general.
Dekel et al. worked on highlighting directives present in the Javadocs reference documentation [16]. Their tool, eMoose, makes programmers aware of important usage guidelines or directives from the documentation of API methods. The violation of such directives could lead to bugs. The tool provides several helpful directives, which can be identified in eMoose by means of tags in the documentation. API developers and contributors have to include such tags in the documentation, and it is difficult to identify directives in existing documentation that does not include tags.
The reference documentation is an important form of API documentation. However, studies found that developers use reference documentation only when they cannot get the needed information from other possible sources [53]. This could be due to the presentation or the content of the reference documentation. Nykaza et al. identified the importance of an overview section in API reference documentation [53], and Jeong et al. highlighted the importance of explaining the API exploration starting points to increase the quality of the documentation [34].
Kim et al. proposed eXoaDocs [36], a tool that integrates code snippets, mined from a source code search engine, into the Java API reference documentation. eXoaDocs queries the search engine for code examples that use a given API method, then eliminates from the code examples non relevant segments to the use of the API method, and integrates the resulting code snippet in the description section of the method in the API documentation. eXoaDocs was able to embed source code examples for more than 20,000 API elements.
Stylos et al. proposed Jadeite [73], a tool that takes advantage from usage statistics of the APIs classes and methods in code examples on the Web. It displays commonly used API elements more prominently in the documentation. The tool also integrates code snippet on how to create instances of API classes in the documentation. Additionally, Jadeite introduced the concept of “placeholders”, a feature which enables API designers or users to annotate the API documentation with classes they expect to exist in a given package of the documentation, or methods they expected to exist on a given class, and to add forward references to the actual parts of the APIs that should be used instead of the “placeholders”.
More recently Treude et al. proposed an approach to augmenting API documentation with in-sights sentences derived from Stack Overflow sentences that are related to a particular API type [78]. They proposed a machine learning based approach that uses as features the sentences themselves, their formatting, their question, their answer, and their authors as well as part-of-speech tags and the similarity of a sentence to the corresponding API documentation. The proposed approach outper-formed two state-of-the-art summarization techniques as well as a pattern-based approach for insight sentence extraction. Moreover, the results show that considering the metadata available on Stack Overflow along with natural language characteristics can improve existing approaches when applied to Stack Overflow data.
2.3 API property inference
Large APIs are difficult to use, because of hidden assumptions and requirements. Developers should be aware of different API properties, to correctly use the API. This is why many approaches have been proposed to infer these API properties. Each approach comes with a new definition of API properties, new techniques for inferring these properties, and new ways to assess their correctness and usefulness. In the following subsections we classify existing techniques into four broad categories.
2.3.1 Unordered usage patterns
A basic type of property that can be expressed about an API is that of an unordered usage pattern. Patterns are typically observed from the data as opposed to being formally specified by a developer. And usage patterns describe typical or common ways to use an API. Unordered usage patterns de-scribe references to a set of API elements that co-occur with a certain frequency within a population of usage contexts. As an example of unordered usage patterns, we may detect the pattern {open ; close}, which indicates that whenever client code calls an API method open, it also calls the method close, and vice versa. This pattern is unordered, as it does not encode any information about the sequence between open and close methods.
Michail was the first to explore the use of association rule mining between a client and its library to detect usage patterns [45, 46]. Michail’s idea was to help developers understand how to reuse classes in a library by indicating relationships such as “if a class subclasses class C , it should also call methods of class D”. Michail detects these relations by mining client code that uses the API of interest. This preliminary work seeded the idea of using association rule mining on software engineering artifacts. Michail targets the discovery of rules, and thus he applies his approach with very low support and confidence, observing that a filtering step is necessary for the approach to be feasible.
Unordered usage patterns can also be used to detect bugs. Li et al. used association rule mining, in PR-Miner, to automatically detect unordered usage patterns [40]. PR-Miner parses source code to store identifiers representing functions called, types used, and global variables accessed. The stored identifiers are then used as items in the mining algorithm. Once identified, the patterns are considered as rules and used to find violations. The assumption is that rule violations can uncover bugs. The tool
was evaluated on three C/C++ systems, with up to three million lines of code. PR-Miner extracted more than 32,000 programming rules from the evaluated systems, and detected around 82 violations to the extracted rules. However, Li et al. noted that a large number of the association rules are false positives, even with pruning steps.
The tool DynaMine proposed by Livshits et al. shares the same goal [42]. It infers usage patterns by mining the change history of an API’s clients. The idea is that method calls that are frequently added to the source code simultaneously often represent a pattern. DynaMine automates the task of collecting and pre-processing revision history entries and mining for common patterns. Likely patterns are then presented to the user for review; runtime instrumentation is generated for the patterns that the user deems relevant, and patterns are checked by executing the client’s source code. Results of dynamic analysis are also presented to the user. The authors find only 56 patterns in the change history of Eclipse and jEdit using the chosen confidence and support thresholds, and only 21 of which are observed to occur at runtime. Additionally, the tool detected a total of 263 pattern violations.
Another approach that focuses on bug detection is the one of Monperrus et al. [47]. The objec-tive of this approach is to detect missing API method calls. They collect statistics about type-usages, a type-usage being simply the list of methods called on a variable of a given type in a given client method. Then, they use this information to detect other client methods that may need to call the miss-ing method. Their idea is implemented in a tool called DMMC (Detector of Missmiss-ing Method Calls). Monperrus et al. do not use any standard data mining algorithm as part of their approach. Rather, for a given variable x of type T, they generate the entire collection of usages of type T in a given code corpus. From this collection, the authors compute various metrics of similarity and dissimilarity between a type usage and the rest of the collection. The missing method calls are detected through the characterization of deviant code on top of similarity and dissimilarity metrics. The tool produces warnings for type-usages whose degree of deviance reaches a certain threshold.
Other techniques that detect unordered usage patterns have been proposed to recommend API elements useful for programming tasks. Bruch et al. proposed FrUiT, a tool to help developers learn how to use a framework by providing them with context-sensitive framework usage patterns, mined from existing code examples [10]. Based on these patterns, suggestions about other relevant parts of the framework or the API are presented to novice users. The tool combines data mining techniques with a context-dependent recommendation. Currently, FrUiT’s suggestions use the whole class in the
active editor as a context for recommendation. A more recent technique proposed by zhang et al. was interested in API method parameters recommendation [86]. The tool, called Precise, mines existing code base, uses an abstract usage pattern representation for each API usage scenario, and then builds a parameter usage database. Upon request, Precise queries the database for abstract usage patterns in similar contexts and generates parameter candidates by concretizing the patterns adaptively.
2.3.2 Sequential usage patterns
Sequential usage patterns differ from unordered patterns through considering the order in which API operations are invoked. Sequential pattern mining would be able, for instance, to alert the pro-grammer that open should precede close for the pattern {open; close}. The most common goals for mining sequential API usage patterns are API documentation and bug detection. Techniques devel-oped for API documentation infer some high-level patterns from a program, and assume that these patterns will be valuable for API documentation. On the other hand, techniques developed for bug detection typically go one step further. They detect usage patterns, and use these patterns for anomaly detection.
Sequential patterns can be derived from a wide variety of inputs. Inference techniques can be distinguished by the input they require. The main difference is naturally between dynamic and static approaches. Dynamic approaches typically read a single execution trace as input. Whereas for static approaches, the most popular strategy is to analyze API client programs source code. Gabel et al. proposed a runtime tool for inferring and checking simple temporal patterns using a sliding-window technique that considers a limited sequence of events and mine as usage patterns, regular expressions, with exactly two method calls involved in each regular expression [25]. The static technique by Whaley et al. uses interprocedural analysis and constant propagation to find call sequences of methods that may establish conditions of predicates that guard throw statements [85]. These sequences are considered illegal. Whaley et al. assume that programmers of languages with explicit exception handling make use of defensive programming: A component’s state is encoded in state variables, and state predicates are used to guard calls to operations and cause exceptions to be thrown if satisfied.
We further distinguish sequential mining approaches by the kind of mined patterns. A significant number of approaches mine instances of a single sequential pattern. Such sequential patterns can consist simply of an ordered pair of API elements, indicating that the usage of one element should
occur before the other element in a program’s execution. An example of this category is the previously mentioned approach proposed by Gabel et al. [25].
A further class of approaches mine instances of several patterns at once. Such patterns are gen-erally instances of special temporal patterns such as Initialization, Finalization, Push-Pop, or Strict Alternation [41]. Other approaches are also based on mining instances of certain patterns but describe these patterns using temporal formulas, boolean formulas or temporal logic [43].
Many techniques mine API usage patterns by encoding temporal order as finite-state automata [5], or using special representation models such as Groums. Groums are Graph-based object usage models a special-purpose property representation, used by Nguyen et al. in GrouMiner [52]. Groums associate events in a directed acyclic graph (DAG). In contrast to finite-state automata, this graph can hold special nodes to represent control structures, such as loops and conditionals. Furthermore, edges not only represent sequencing constraints, but also data dependencies.
Some approaches use frequent item set mining, and include temporal information in the definition of the elements in the item sets [84]. Other approaches directly mine sequential patterns by using closed frequent sequential pattern mining. This mining technique exhibits a higher computational cost, but has the advantage of retaining useful information like the frequency of elements. Most of these approaches use the BIDE algorithm [80]. For instance, Zhong et al. proposed MAPO, a tool that clusters frequent API method call sequences extracted from client programs, then use the BIDE algorithm to mine closed sequential patterns from the preprocessed method call sequences [87]. Thus, MAPO capture groups of API’s method that are frequently used together. Wang et al. build on MAPO and propose an approach that add pre and post clustering to reduce the number of redundant patterns and detects more succinct ones [81].
2.3.3 API constraint
A number of approaches have been developed to describe the valid and invalid behavior of the API when certain API properties are either met or more typically not met. One form of behavioral description is through constraint, such as pre-conditions, post-conditions, and invariants defined over an abstract data type or a class. A typical example of a pre-condition is that a value passed as an argument to a function should not be a null reference.
Existing techniques infer the API constraint through various analyses on the source code either of the API or its client program. To this end, two general strategies are used to generate behavioral specifications of APIs: the conjecture/refute strategy and the symbolic execution strategy.
Henkel et al. proposed an approach that follows the conjecture/refute strategy [29]. It systemati-cally explores the state space of the class for which specifications are generated. They first create an instantiation transition for the class, and then systematically construct a sequence of invocations of increasing complexity on this instance. Then they focus on the detection of invalid sequences. To in-validate the conjectured invariants the tool executes code corresponding to the synthetically generated transitions. When executions result in an exception, the corresponding sequence is flagged as invalid. Buse et al. proposed an exception documentation reverse-engineering approach [13]. The approach follows the symbolic execution strategy. The use of symbolic execution in this approach only identi-fies paths that result in an exception. Thus the tool produces for each (method, exception-type) pair, a path predicate that describes constraints on the values of the method’s variables that will result in a control-flow path ending in an exception of that type to be raised. Specifically, Buse et al. approach infers, for a given API method, the possible exception types that might be thrown, the predicates over paths that might cause these exceptions to be thrown, and human-readable statements that describe these paths.
2.3.4 API migration and mapping
APIs evolve continuously and in a very fast way, client program developers may need support to update clients of an API when the API evolves with backward-incompatible changes. Alternatively, and due to license constraints, client application may need to switch between different, but equivalent, APIs. In this context, several techniques have been proposed to infer migration mappings of elements declared in one API to the corresponding elements in a different API, or in a different version of the same API.
The most basic mappings are those that correspond to simple API refactorings, such as renaming API elements or moving them to a different module. For instance, RefactoringCrawler by Dig et al. infers mappings between refactored versions of an API [17]. It applies text similarity metrics to the signatures of API elements. After identifying the most similar API element pairs by performing a syntactic comparison between all API element pairs across the two API versions, RefactoringCrawler
validates each refactoring candidate by checking whether references to and from the old element are similar to the references to and from its candidate replacement element.
Other techniques go beyond standard refactorings by discovering more general mappings between API elements. SemDiff by Dagenais et al. is an example of such techniques [14]. SemDiff does not relate API elements by the syntactical similarity of their signatures. It rather identifies possible candidate replacements for a method by analyzing the change history of a client of the API that has already been migrated. SemDiff makes the hypothesis that, generally, calls to deleted methods will be replaced in the same change set by one or more calls to methods that provide a similar functionality. Having identified such change sets, SemDiff then ranks all detected replacements with respect to a popularity-based metric, as well as name similarity, and presents these as a ranked list to the user.
Other techniques also present some kind of migration guidelines that illustrate how references to the current element can be replaced by references to its target element(s). Nguyen et al. tool LibSync falls in this category by discovering these series of steps required to update a client [51]. LibSync represents API usages as directed acyclic graphs called GROUMs that basically capture reference and inheritance based usage of API methods and types, as well as various control structures and dataflow dependencies between them. Given some mapping between an initial set of elements in the current API version and their replacements set in a different version, LibSync first identifies GROUMs describing usages of the elements in the initial set in the old versions of client code, and then computes edit scripts to describe how those usages differ from the usages of the elements in the replacements set in the new versions of its client code. GROUM-based edit scripts are provided to frequent item set mining to generalize common edit operations.
2.4 Summary
Through this chapter, we presented a review of the existing work related to our contributions. We first presented different studies that motivate the importance of facilitating usability and learnability of APIs. We share with all the authors of these studies the idea that when developers learn a new API, they struggle not so much on the mechanics of using the API, but in understanding how the API elements are related to scenarios or usage patterns the API provider intends to support. Thus, showing a pattern of related calls is preferred to illustrations of individual detailed method usage.
Several approaches and tools have been proposed to deal with the learnability and usability prob-lems of APIs. We presented various techniques that range from intuitive solutions to very complex approaches. The majority of presented techniques either infer simple intuitive patterns or require high computational cost. However, efficient tools should be scalable to work with large code bases with millions lines of code and thousands of public API methods. To be inline with this requirement, we need a non-expensive technique useful during the early step of the API learning process. Thus, we opt for the mining of non-sequential usage patterns, and we avoid complicated data representations such as partial order graphs.
The majority of the used techniques rely on the existence of large collections of API client pro-grams to be effective. Consequently, newer APIs or non-popular parts of existing APIs may not have sufficient usage examples to infer API patterns. We try to overcome this strong constraint and pro-pose technique based on relationships inside the library itself. Our technique is thus applicable for non-popular API new releases and even new APIs.
As compared to approaches that infer unordered usage patterns, the majority of these approaches use a form of frequent itemset mining. Thus, the mined pattern tends to be many and redundant, posing significant barriers to their practical adoption, and introducing an additional effort to filter, classify and learn the patterns. Moreover, inferred patterns are flat and valuable only for recommen-dation or auto-completion in a specific context and for a specific usage scenario. To overcome these constraints, our technique should reflect interfering usage scenarios.
Through the presented overview of the usage patterns inference techniques, we can distinguish different targeted goals. Several techniques were interested in documentation of usage patterns, and others were interested in detection of violations to usage patterns or recommendation of API elements. In our case, we try to ease the understanding and learnability of APIs for the early step of API learning and usage process. The inferred constraints and patterns can then be easily integrated in an API exploration process or to enrich documentation.
In the next chapters, we describe our contributions for API usage constraints, and patterns detec-tion, and we show how to circumvent the above-mentioned problems.
Part I
Chapter 3
API Usage Constraints Inference
Nowadays, APIs represent the most common reuse form when developing software. However, the reuse benefits depend greatly on the ability of client application developers to use correctly the APIs. In this chapter, we present an observational study on the API usage constraints and their documentation. To conduct the study on a large number of APIs, we implemented and validated strategies to automatically detect four types of usage constraints in existing APIs. We observed that some of the constraint types are frequent and that for three types, they are not documented in general. Surprisingly, the absence of documentation is, in general, specific to the constraints and not due to the non-documenting habits of developers. These findings justify the importance of supporting library usability at the API method level. This contribution was published at the IEEE International Conference on Software Analysis, Evolution, and Reengineering[64].
3.1 Introduction
As mentioned earlier, much research effort has been dedicated to the redocumentation of APIs [12, 13, 30, 60], and proposed to recover various types of information such as usage constraints and usage examples. Nevertheless, most of these contributions were devoted to a specific type of constraints (method-call sequences, exceptions, etc.) and tried to redocument valid and invalid behavior of the API. None of these contributions could address all possible types of constraints. Consequently, some constraint types, especially those related to the parameters of API methods, may not be considered in redocumentation tasks.
This can be understandable if we conjecture that these constraints are not frequent, and if they are usually documented by the API developers. However, even if some studies were interested in building taxonomies of constraints [48], to our best knowledge, there is no empirical evidence about the frequency and documentation level of such constraint types.
In this chapter, we present an observational study that targets some usage constraints and their documentation in existing APIs. To conduct the study, we selected four critical usage constraint types
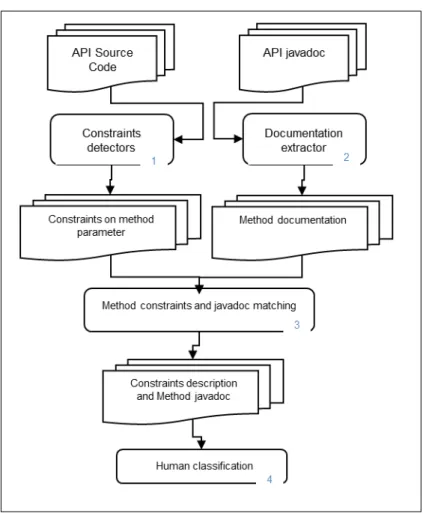
that deal with method parameters, namely, Nullness not allowed, Nullness allowed, Range limitation, and Type restriction. These were among the usage constraints identified in [48]. We implemented automated strategies for finding instances of the selected usage constraints and validated them, with subjects, on 13 APIs of JDK7.
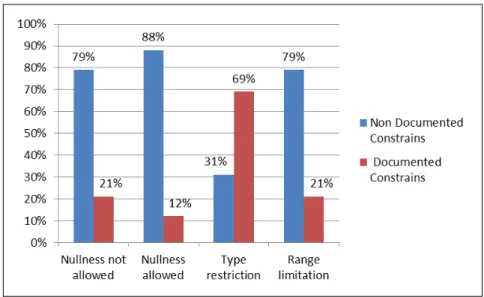
Our study was conducted on a sample of 11 real-world APIs excluding the 13 APIs used to validate the detection algorithms, except for one of the research questions. The results of our study show that some of the constraint types are used extensively and that for three types, these constraints are poorly documented in general. Moreover, the absence of documentation is, in many cases, specific to the constraints and not due to the non-documenting habits of developers.
This chapter is structured as follows. Section 3.2 discusses with examples the importance of identifying usage constraints. Section 3.3 describes the usage constraints selected for our approach and show their detection strategies. Section 3.4 gives the setting and the results of our observational study, including the validation of the detection algorithms. The threats to validity and a conclusion are provided respectively in sections 3.5 and 3.6.
3.2 Motivating examples
After deciding which method to call, providing the right values for the parameters is among the most important decisions when using an API. This is why client developers usually ask several ques-tions in relation to method’s parameters when they reuse an API [19]. Since the signature of a method is rarely enough expressive about most of the parameters’ usage constraints, it is necessary to be aware of such constraints. In this section, we provide examples showing that relying only on method signa-tures can induce the developer in error. That is why the explicit documentation of usage constraints is needed. The following examples are all extracted from the JDK7 APIs.
– Example 1. Consider the method public Object parseObject(String source, ParsePosition pos)from the Java class DateFormat which is a class for date and time formatting. This method parses a string to produce a Date. It attempts to parse text starting at the position given by pos.
Just from the method signature, a developer can possibly conjecture that if the pos parameter is not given (null), then the method is going to parse the whole text. However, the null value has no particular semantic here, and will result in an exception.
– Example 2. This example shows exactly the opposite situation, where the null value has a specific semantics important for the usage of the API method. Consider the following method public boolean hasListeners(String propertyName) from the utility class VetoableChangeSupport. The method in which we are interested checks if there are listeners for a specific property.
Based on the signature, a developer can legitimately understand that passing a null value is not allowed. Actually, when no property name is given, the method checks for listeners registered on all properties. As in the previous example, a documentation is required to explain how the null value is handled.
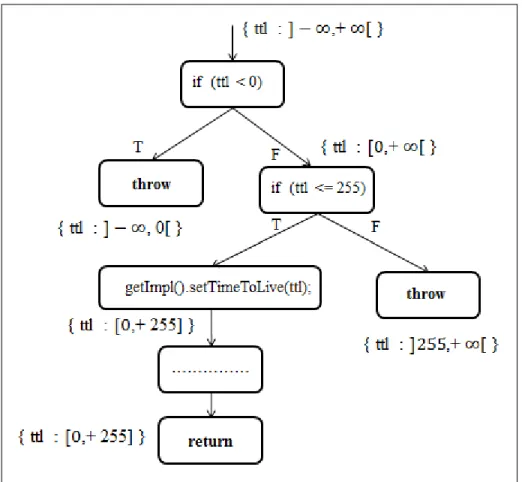
– Example 3. Another interesting example is one from the class MulticastSocket. This class is useful for sending and receiving IP multicast packets, with additional capabilities for joining groups of other multicast hosts on the Internet. The signature of the setTimeToLive method is public void setTimeToLive(int ttl). This method set the default time-to-live for multicast packets sent out on the considered MulticastSocket.
When looking at the declared type of the ttl parameter, the developer assumes that any integer value can be passed to specify the default time-to-live for multicast packets. Nevertheless, a restriction on the possible values of the parameter is imposed and only a value in the ranges [0, 255] is accepted, otherwise the parameter is considered as illegal.
– Example 4. The last example considered to show the importance of inferring usage constraints is found in class Proxy. The following method in this class uses a parameter having as type Object.
public static InvocationHandler getInvocationHandler(Object proxy) Although the signature uses a generic type, only instances of class java.lang.reflect.Proxy can be passed as arguments of the method, which returns the invocation handler for the specified instance. Otherwise, an IllegalArgumentException is going to be thrown.
These examples illustrate well the need to report such usage constraints, to API users. Still, it is important to study if these kinds of constraints are actually documented or not in the existing APIs.
3.3 Approach
This section presents our approach to infer API usage constraint from the library source code. For this study, we focus on usage constraint related to API method’s parameters. We first present the selected constraint types, for which we will inspect the presence in library source code and the degree of documentation. Then we describe the strategies defined to detect the selected constraints.
3.3.1 Constraint type selection
A clear understanding of what developers usually document will help us targeting a subset of usage constraints to include in our study. As mentioned earlier, Monperrus et al. in [48] conducted a study on API documentation to understand the kind of included directives. In their work, a directive is defined as a natural-language statement that makes developers aware of constraints and guidelines related to the API usage. As a result of the study, they extracted a taxonomy containing 23 directive types grouped into six categories. Almost the half of these directive types (11) belong to the method call category, which also includes the largest portion of directive occurrences in the studied APIs (43.7%). Among the 11 directive types of this category, the most frequent one refers to the fact that a parameter cannot be null (13%). Conversely, they also found that many directives refer to the possibility of passing a null value to a parameter and explain its semantic. This directive type is less frequent in general than the first one, but more frequent in some of the considered APIs such as in JDK.
In addition to the previous contribution, we also considered the exploratory study conducted by Duala-Ekoko and Robillard on the questions asked by client developers when using unfamiliar APIs [19]. Among the frequent questions, many are related to values that can be passed to the methods and especially the valid types and value ranges.
Consequently, we retained the following constraint types:
Nullness not allowed: A situation in which a null parameter, passed as an argument to a method in the library, causes failures during execution.
Nullness allowed: A situation in which the argument passed to a method can be null. This value has a specific semantics for this parameter.
Type restriction: A situation in which the type declared by the method parameter is not enough to be aware of various restrictions on the parameter type. Only a subset of type is allowed to avoid the execution failures.
Range limitation: A situation in which the restriction on the values of a numeric parameter goes beyond possible restrictions through the declared types.
3.3.2 Detection strategies
Almost all the occurrences of the selected usage constraints can be detected using a static intra-procedural analysis, which is applied to the control flow graph (CFG). The analysis for some con-straint types is flow-sensitive whereas, the one of the others is path-sensitive [49].
3.3.2.1 Nullness not allowed analysis
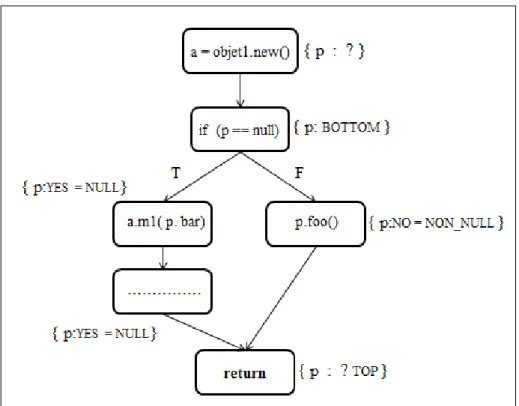
The objective of this analysis is to identify situations that prohibit a method parameter from being null. To this end, we defined and combined two forward branched flow analyzes. More precisely, the CFG is traversed from the entry node and, for each node, we determine if a given parameter is, before this statement, definitely not null (NON_NULL tag), definitely null (NULL tag), both values are possible (TOP tag) or we just don’t know (BOTTOM tag). The first analysis method, named NullnessAnalysis starts from the basic idea that a variable x (the parameter in our case) is consid-ered not-null after instructions of the form ’x = new()’, ’x = this’ or any other assignment of something not derived from x itself, we can also know that the parameter is not null if tests such as ’x instanceof T’ succeed. In addition, we can deduce that the variable x is null on the true branch after conditional expressions that test the nullness of the variable. This node tagging is then used in a second analysis that locates statements containing references to arrays, field references, method invocations and monitor statements. These types of statements may generate unchecked exceptions when the manipulated variables are null. Thus, the objective of our analysis is to detect the use of the parameters in one of the statements mentioned above. If the analysis couldn’t determine that the considered parameter is always not null before such statements, a Nullness not allowed constraint is then detected.
Figure 3.1: NullnessAnalysis example.
In the example of Figure 3.1, the NullnessAnalysis tags the nodes of the CFG for a parameter p. Then, the second analysis traverses the CFG and locates the statement ’a.m1(p.bar)’ in which the field bar is accessed while the node is tagged NULL for p. Consequently, a Nullness not allowed constraint is detected for the analyzed method.
3.3.2.2 Nullness allowed analysis
One can conjecture that if the previous analysis does not detect a Nullness not allowed constraint, then, null is allowed for the method parameters. However, the fact that it is allowed to pass a null value as an argument to a method, does not mean that the null value has a particular semantics that should be known by the client developer. For this reason, we are only interested in methods where a null value is not prohibited for a parameter and where the null value has a semantic which is reflected by a particular behavior of the method. The intuition behind our analysis is to consider each parameter as a potential candidate for the Nullness allowed constraint, from the moment we can be sure using the NullnessAnalysis, that the parameter in question is definitely null, at a given node, and that this node