KD2R: a Key Discovery method for semantic Reference Reconciliation in OWL
Texte intégral
Figure
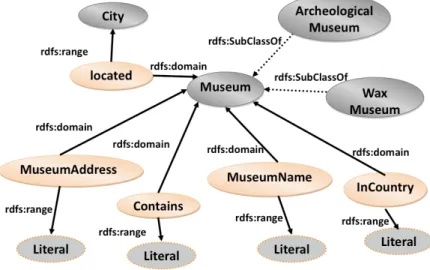



Documents relatifs
One of the important tasks related to the implementation of the Digi- tal Economy program is to improve cybersecurity when creating digital plat- forms, as
The procedure of generating of positional indication of non-positional code (fig. 1) laid in the base of method of operational data control in residue classes.. In that way,
It is known that the development of suffusion processes intensity of geodynamic changes of local sites of geological environment characterized by much greater performance than that
Por último, la instanciación del metamodelo de testing permitirá probar las transformaciones que se realizan tanto en el primer nivel (de fuentes de datos a estructura de
Some combinations of property expressions are nei- ther keys nor non keys: set of property expressions is called an undetermined key for a class if it is not a non-key and there
(3) In the case where the decision maker wants to merge two consecutive categories with E lectre T ri -C she/he cannot keep the two characteristic reference actions that define
Then, in Section 3, we present a new generic method to enumerate various classes of directed polycubes the strata of which satisfy a given property.. In Section 4 this method is
Barplots of optimum cost (left) and dissimilarity between pairs of reconciliations with the most frequent optimum cost (right) obtained on the datasets derived from the SBL x%
