Comparaison des questions de sondage pré-électoral
dans leur capacité à prédire le résultat d'une élection et
à diminuer le biais causé par l'inattention envers la
corrélation - une analyse expérimentale
Mémoire
Rudy Hamel
Maîtrise en économique - avec mémoire
Maître ès arts (M.A.)
Comparaison des questions de sondage pré-électoral
dans leur capacité à prédire le résultat d’une élection
et à diminuer le biais causé par l’inattention envers la
corrélation - une analyse expérimentale
Mémoire
Rudy Hamel
Sous la direction de:
Résumé
Par leur utilité, les sondages sont devenus des éléments importants de toute campagne élec-torale. Ils ont d’ailleurs beaucoup évolué au fil du temps et on les retrouve maintenant sous plus d’une forme. En effet, inspirés par les marchés de prédiction, les sondeurs ont développé un type de questionnement complémentaire aux sondages classiques interrogeant les indivi-dus sur leurs propres préférences. Cette autre méthode invite plutôt les participants à faire part de leurs anticipations sur le comportement agrégé de la population. Néanmoins, aucune de ces deux approches n’est parfaite. Leur pouvoir prédictif peut être affecté par plusieurs facteurs. Parmi ceux-ci, on compte l’inattention envers la corrélation, un biais cognitif sus-ceptible d’affecter les réponses des individus sondés. À la lumière de qui précède, ce mémoire a pour premier objectif de comparer le pouvoir prédictif de ces deux types de méthode afin de distinguer la plus performante. Le second objectif est de mesurer l’effet potentiel du biais d’inattention envers la corrélation sur les réponses de participants à des sondages. Pour y ar-river, des sujets ont été invités à participer à une expérience en laboratoire où ils ont occupé à la fois le rôle de sondé et de preneur de décision. Les résultats de l’expérience montrent que l’inattention envers la corrélation affecte significativement les réponses de participants à des sondages. De plus, certains facteurs personnels semblent être associés à une probabilité plus élevée d’être victime du biais.
Table des matières
Résumé iii
Table des matières iv
Liste des tableaux v
Liste des figures vi
Remerciements vii
Introduction 1
1 Revue de littérature 4
1.1 L’inattention envers la corrélation. . . 4
1.2 Les marchés de prédiction . . . 6
2 Méthodologie 10 2.1 Le dispositif expérimental . . . 10
2.2 Le plan expérimental . . . 12
2.3 Traitements de l’expérience . . . 13
2.4 Les différents types de questions utilisés dans les sondages . . . 16
3 Résultats de l’expérience 20 3.1 Statistiques descriptives . . . 20
3.2 Pouvoir prédictif des sondages. . . 21
3.3 Le biais d’inattention envers la corrélation . . . 24
3.3.1 Mesure de l’inattention envers la corrélation . . . 24
3.3.2 Analyse des facteurs déterminants . . . 33
Conclusion 38
Bibliographie 40
Liste des tableaux
2.1 Informations présentées aux sujets . . . 12
2.2 Paramètres des huit traitements . . . 14
2.3 Gains potentiels en fonction du coût associé au vote et de l’option choisie . . . 15
2.4 Types de question posés dans les sondages pré-électoraux . . . 19
3.1 Statistiques descriptives des participants . . . 21
3.2 Répartition des sujets (Traitement 1). . . 22
3.3 Écarts entre les prédictions des questions de sondage et le vote effectif . . . 23
3.4 Valeurs-P (Questions probabilistes). . . 24
3.5 Valeurs-P (Questions binaires) . . . 24
3.6 Table de contingence . . . 25
3.7 Table de contingence applicable à l’expérience . . . 25
3.8 Exemple de réponse d’un participant . . . 26
3.9 Table de contingence (Borne #1) . . . 27
3.10 Table de contingence (Borne #2) . . . 27
3.11 Probabilités conjointes théoriques du Traitement 1 . . . 28
3.12 Probabilités conjointes théoriques du Traitement 1 (Groupe des verts) . . . 28
3.13 Corrélations théoriques des quatre traitements . . . 29
3.14 Mesure de l’inattention envers la corrélation . . . 30
3.15 Biais moyens minimaux . . . 32
3.16 Variables explicatives . . . 34
3.17 Coefficients du modèle . . . 35
Liste des figures
3.1 Corrélation théorique bornée . . . 29 3.2 Corrélation théorique non bornée . . . 30
Remerciements
Je tiens à remercier Sabine Kröger, ma directrice de recherche, pour son support et ses conseils judicieux. Nos discussions m’ont aidé grandement à trouver des solutions aux problèmes rencontrés. L’expertise du Professeur Kröger a été essentielle à la réalisation de ce mémoire. J’en profite également pour remercier mes parents pour leur soutien moral et financier tout au long de mes études. Ils m’ont toujours appuyé dans mes projets et mon parcours universitaire n’a pas fait exception.
Introduction
Un vieil adage affirme que celui qui détient l’information détient le pouvoir. Ceux qui adhèrent à cette pensée ne s’étonnent pas devant tous les efforts déployés dans nos sociétés modernes pour la quête d’information de tout genre. Ce désir de connaissance nous pousse même à vouloir prédire la réalisation d’événements futurs. À cet effet, il s’avère que l’information dis-ponible aujourd’hui peut se révéler utile afin d’y parvenir. On n’a qu’à penser aux campagnes électorales, alors qu’on utilise des sondages pré-électoraux pour anticiper le dénouement de celles-ci. En effet, les sondeurs utilisent les anticipations des individus sur leur propre inten-tion de vote afin de prédire le suffrage final. Néanmoins, l’histoire nous a appris que le pouvoir prédictif des sondages pré-électoraux n’est pas sans faille, d’où le développement de méthodes complémentaires. Parmi ces méthodes, on compte les marchés de prédiction. Cette méthode estimée par plusieurs économistes peut se révéler utile afin de prédire le dénouement d’évé-nement de tout genre. En effet, ces marchés invitent des participants à réaliser des paris sur des pronostics d’événement comme des élections, des résultats sportifs et même l’évolution du box-office américain.
Dans le cadre de ce mémoire, on s’intéresse aux deux types de méthode mentionnés ci-haut, c’est-à-dire les sondages électoraux conventionnels et les marchés de prédictions. Plus pré-cisément, l’objectif est de faire ressortir le pouvoir prédictif de ces deux méthodes dans un esprit de comparaison. Ces dernières diffèrent notamment par le type d’information qu’elles permettent d’obtenir du participant. Alors que les sondages conventionnels invitent les indi-vidus à révéler leur propre préférence, les marchés de prédiction les interrogent plutôt à savoir leurs anticipations sur le comportement agrégé de la population.
Tenter de prédire le résultat des campagnes électorales s’avère utile dans nos sociétés démo-cratiques. En effet, les sondages sont l’un des modes de communications les plus importants entre les politiciens et les citoyens. D’un côté, les candidats peuvent s’en servir pour ajuster leurs plateformes, de manière à ce que leurs propositions correspondent davantage aux be-soins de la population. Puis, les électeurs peuvent les utiliser pour coordonner leur vote. Si les sondages annoncent une lutte serrée par exemple, cela peut amener les électeurs à se mobiliser pour aller voter. Ceci étant dit, on comprend que les sondages pré-électoraux peuvent affecter
le bien-être social. Dans l’éventualité où leurs résultats sont biaisés, c’est l’introduction de politiques publiques socialement inefficaces qui peut voir le jour. On a donc tout intérêt à comprendre leur fonctionnement et les facteurs qui peuvent affecter leur pouvoir prédictif.
À cet égard, un problème persiste : les facteurs affectant le pouvoir prédictif sont nombreux. Il n’est pas surprenant de constater l’important nombre de fois où les sondages ne sont pas parvenus à prédire l’aboutissement d’une campagne électorale. Par exemple, tout récemment au Canada lors des élections de 2015, personne ne pouvait prédire l’arrivée d’un gouverne-ment libéral majoritaire en se basant sur les résultats des sondages. C’est pourtant ce qui s’est passé alors que les libéraux ont remporté 184 sièges. Une majorité de sondages crédibles leur prédisaient aux alentours de 140 sièges, ce qui est bien loin des 170 requis pour une majorité. En outre, aucun sondage n’avait prédit la dégringolade du Nouveau Parti démocratique, qui n’a fait élire que 42 députés, soit beaucoup moins que ce qui avait été prédit.
Parmi les facteurs pouvant expliquer ces erreurs de prédiction, il y a le type de question uti-lisé (Manski, 1990). Il semblerait que la capacité des individus à prédire leurs comportements futurs soit faible. Malgré tout, il serait possible d’obtenir de meilleurs résultats lorsque les répondants peuvent faire preuve d’incertitude dans leurs réponses. Par ailleurs, l’honnêteté des répondants peut entrer en ligne de compte, alors que les sondages conventionnels n’offrent aucun incitatif à être honnête. Les sondages eux-mêmes peuvent également influencer le com-portement des électeurs et des candidats (Erikson et collab.,2002).
Dans ce contexte, cette recherche vise également à analyser l’un des facteurs qui pourraient affecter la capacité des questions de sondage pré-électoral à prédire le résultat d’une élec-tion. Il s’agit de l’inattention envers la corrélation, un biais cognitif qui amène les individus à déroger du modèle de rationalité très répandu en science économique. Selon ce modèle, les acteurs économiques sont des êtres rationnels qui, considérant toute l’information disponible, prennent les meilleures décisions possible afin de maximiser leur utilité. Pourtant, plusieurs études ont démontré que la prise de décision humaine n’est pas toujours rationnelle. À ce propos, on qualifie de biais cognitifs les causes de cette dérogation.
La corrélation entre divers paramètres peut se révéler être un élément à considérer afin de prendre de bonnes décisions. On n’a qu’à penser à la sélection d’un portefeuille d’actifs finan-ciers. Afin de diminuer le risque de perdre de l’argent, les investisseurs choisissent des actifs diversifiés qui ont des rendements négativement ou faiblement corrélés. De cette manière, il devient peu probable qu’ils aient un rendement négatif sur tous leurs actifs.
On parle donc d’inattention envers la corrélation lorsque les individus ne prennent pas en considération la corrélation entre les paramètres d’intérêt lors d’une prise de décision. Qu’ils
en soient conscients et qu’ils la négligent, ou qu’ils n’en captent pas l’importance, les individus souffrant d’inattention envers la corrélation amènent une source de biais dans leurs raison-nements. En ce qui concerne un électeur, la probabilité qu’il vote pour son candidat préféré est négativement corrélée avec son coût de participation aux élections. Évidemment, plus le coût d’aller voter est important chez une personne, que ce soit au niveau physique ou psycho-logique, moins de chances elle aura de voter pour son candidat préféré le jour de l’élection. Il a donc été intéressant dans le cadre de ce mémoire d’évaluer la capacité des individus à prendre en considération la corrélation entre ces différents facteurs au moment de répondre à des questions de sondage.
Un dispositif expérimental a notamment été mis sur pied afin de distinguer si l’une des mé-thodes permet de diminuer le biais causé par l’inattention envers la corrélation. Par ailleurs, les résultats expérimentaux nous ont permis de distinguer si certains facteurs individuels sont associés à une probabilité plus élevée de faire preuve d’inattention envers la corrélation.
Les résultats de cette recherche ont des implications importantes, alors qu’ils contribuent à la littérature sur le biais d’inattention envers la corrélation. Peu d’études se sont intéressées à l’influence de ce phénomène dans le cadre de sondages pré-électoraux. Nous espérons que les conclusions de ce travail enrichiront les connaissances sur le sujet.
La suite de ce mémoire est ordonnée de la manière suivante. La prochaine section présente une revue de littérature, traitant principalement du biais d’inattention envers la corrélation et des marchés de prédiction. Par la suite, une section est consacrée à la méthodologie, où le dispositif expérimental est expliqué. Finalement, la dernière section présente les différents résultats de l’expérience et les constats qui en découlent.
Chapitre 1
Revue de littérature
1.1
L’inattention envers la corrélation
Parcourir la littérature sur le biais d’inattention envers la corrélation est un bon moyen pour en saisir les implications. En effet, cela permet de constater que les individus peuvent en souffrir dans plusieurs situations. On se familiarise également avec les différents dispositifs expérimentaux qui ont été mis sur pied.
Kroll et collab. (1988) sont les premiers à avoir remarqué une incohérence dans les décisions d’investissement des individus. Lors d’une expérience en laboratoire où ils cherchaient à tes-ter les hypothèses du théorème de séparation, ainsi que le modèle d’évaluation des actifs financiers, ils ont constaté que les individus ne sont pas affectés par les changements dans la matrice variance-covariance des titres risqués lorsqu’ils prennent des décisions d’allocation. On ne parlait pas d’inattention envers la corrélation à l’époque, mais l’idée était soulevée.
Ce n’est que depuis quelques années que les économistes s’intéressent davantage au phéno-mène. Kallir et Sonsino (2009) ont voulu vérifier si des changements de corrélation entre le retour de deux actifs allaient avoir un impact sur les décisions d’investissement. Ils ont effec-tué l’expérience avec des étudiants en finance, alors que ces derniers devraient être conscients de l’importance de considérer les effets de corrélation. Cinq problèmes différents leur ont été présentés, où la corrélation entre le rendement des actifs A et B variait entre +2/3 et -2/3. Ces actifs pouvaient donner des rendements élevés ou faibles, mais la distribution margi-nale de retour sur A dominait toujours celle sur B. Ainsi, un individu rationnel se devait d’allouer l’ensemble de ses ressources sur l’actif A. Une allocation vers l’actif B se justifiait seulement à mesure que la probabilité conjointe d’observer des rendements élevés pour B et des rendements faibles pour A augmentait. Les chances d’observer cette dernière situation augmentaient à mesure que la corrélation variait de +2/3 vers -2/3. À la suite de l’expé-rience, les auteurs ont constaté que l’allocation pour l’actif dominé B n’augmentait pas à
mesure que le niveau de corrélation avec A diminuait, même si les individus reconnaissent le changement dans la corrélation au fil des problèmes. Les décisions d’allocation ont plutôt été affectées par la magnitude du retour des deux actifs, et non pas par le niveau de corrélation.
Eyster et Weizsäcker (2011) y sont allés d’une approche complémentaire. Alors que Kallir et Sonsino (2009) ont fait varier la structure de leurs mises en situation pour constater que le comportement des participants ne changeait pas à travers celles-ci, Eyster et Weizsäcker ont présenté des problèmes économiquement identiques et constaté que le comportement des in-dividus n’était pas constant au fil de ceux-ci. Pour chaque paire de problèmes, les participants devaient allouer leur dotation initiale entre deux actifs dont le rendement historique pouvait être corrélé. Ces paires de problèmes étaient ordonnées de manière à ce qu’il soit possible pour les participants de déterminer une allocation qui allait leur donner le même niveau d’utilité pour chacun des problèmes de la paire. Puisque le rendement espéré des actifs était le même dans certaines paires de problèmes, donc corrélé, l’allocation d’un être rationnel se devait d’être la même pour chaque problème présentant des effets de corrélation. Or, les résultats ont montré que les gens ont tendance à traiter les actifs corrélés comme étant indépendants. Une majorité aurait plutôt tendance à suivre une simple heuristique "1/n", ce qui veut dire investir une part égale des fonds dans tous les actifs disponibles. Ces résultats sont intéres-sants, alors que l’on constate que les investisseurs peuvent se retrouver avec des portefeuilles comprenant du risque non désiré et évitable.
Dans un autre contexte, Enke et Zimmermann (2014) ont fourni des évidences expérimentales que plusieurs individus souffrent d’inattention envers la corrélation. Ils ont étudié l’effet de la corrélation entre les différentes sources d’information sur la formation d’anticipations des indi-vidus. C’est que les informations avec lesquelles nous sommes en contact peuvent provenir de la même source. On n’a qu’à penser à une agence de presse qui fournit de l’information à dif-férents médias qui vont ensuite la divulguer. C’est en quelque sorte ce qu’ils ont voulu recréer avec leur expérience. Les participants devaient faire part de leur anticipation sur la réalisation future d’une variable aléatoire à l’aide de différentes sources d’information. L’expérience a été effectuée en deux traitements où les sources d’information étaient corrélées dans un seul de ceux-ci. Il est également important de mentionner que les participants étaient informés de la présence de cette corrélation. Malgré tout, les résultats attestent que les individus ont une tendance forte à négliger la corrélation entre les différentes sources d’information lorsqu’ils forment leurs anticipations. Enke et Zimmermann se sont également intéressés aux causes de ce biais cognitif. À cet effet, ils suggèrent deux hypothèses. La première est que les individus procèderaient à un calcul coût-bénéfice et que l’appât du gain ne soit pas assez grand pour donner un effort supplémentaire afin de comprendre les effets de la corrélation. La deuxième est que les gens sont pris avec une limite d’attention, et qu’ils n’arrivent pas à distinguer les aspects d’un problème où il est primordial de s’attarder. Parmi ces hypothèses, ils croient
que la plus plausible est celle sur la limite d’attention auquel les gens sont contraints. Tout bien considéré, cette étude a considérablement fait avancer la recherche dans le domaine. Elle fournit une explication plausible de la présence du biais cognitif en mettant l’emphase sur l’attention portée par les individus dans le processus de croyance.
Tout récemment, Levy et Razin (2015) se sont intéressés aux implications positives et nor-matives de l’inattention envers la corrélation sur les résultats électoraux dans le cadre d’une élection. Plus précisément, ils ont cherché à caractériser de quelle manière ce biais affecte le niveau de polarisation des opinions. Ils ont également analysé de quelle manière ce biais affecte la polarisation dans les plateformes politiques. Leur modèle prédit que l’inattention envers la corrélation entraine la polarisation des opinions. Toutefois, cela ne conduit pas nécessai-rement à un résultat inefficace. Un individu souffrant du biais capte deux signaux corrélés comme étant indépendants. Dès lors, si ces signaux correspondent à l’état du monde optimal, l’opinion de cet individu se rapprochera davantage de cet état optimal que celle d’un indi-vidu rationnel qui voit que les signaux sont identiques. C’est dans ce sens que la présence d’individus souffrant d’inattention envers la corrélation dans une population peut mener à un résultat efficace. Du côté de la polarisation des plateformes politiques, les auteurs affirment que la présence du biais dans la population peut autant la rendre plus grande ou plus petite. Tout dépendamment des hypothèses qu’ils posent, les deux situations sont possibles.
Dans le cadre de ce mémoire où on s’intéresse aux sondages pré-électoraux et aux marchés de prédiction, on souhaite mesurer la sensibilité des individus vis-à-vis la corrélation entre la probabilité de voter pour leur candidat préféré et la probabilité de participer aux élections. Ces deux probabilités peuvent être corrélées par les bénéfices et les coûts reliés au vote. Dans un contexte réel, on peut imaginer ces coûts de manière physique, en temps ou en déplacement, et même au niveau psychologique, via la peur de voter pour un mauvais candidat. Donc, ce qu’il faut comprendre, c’est que plus le coût d’aller voter est élevé pour quelqu’un, plus sa probabilité de participer aux élections diminue. Par le fait même, les chances de voter pour un candidat se retrouvent également à la baisse.
1.2
Les marchés de prédiction
Depuis un certain temps, l’étude des marchés de prédiction a la cote chez plusieurs chercheurs en sciences sociales. L’idée que ces marchés peuvent prédire avec précision le résultat d’événe-ments futurs est séduisante. Ils correspondent à des plateformes où des contrats sont échangés. Ces contrats correspondent à des pronostics d’événements et la possession de ceux-ci engendre une rémunération basée sur le résultat de ces événements futurs incertains. Le plus connu de ces marchés est certainement l’Iowa Electronic Market. Ayant ouvert en 1988, il offre depuis des prédictions pour chaque campagne présidentielle américaine.
Les marchés de prédictions permettent donc d’agréger des opinions et d’extraire des consensus non biaisés en temps réel. De plus, contrairement aux sondages conventionnels, ces marchés n’ont pas besoin d’un échantillonnage représentatif de participants pour fonctionner. Ils visent simplement à attirer ceux qui possèdent de l’information pertinente dans l’optique de fournir une vue dynamique de l’intelligence collective. Selon l’hypothèse d’efficacité des marchés, les prix auxquels ces contrats s’échangent sont les meilleures estimations de certains paramètres reliés à la probabilité de réalisation de ces événements. Le prix des contrats varie selon l’offre et la demande.
En survolant la littérature sur les marchés de prédiction, on réalise que les opinions sont par-tagées. D’une part, on a les défenseurs de ceux-ci (Forsyth, Nelson, Neuman et Wright, 1992 ; Wolfers et Zitzewitz, 2004, 2006b ; Kou et Sobel, 2004 ; Arrow, Forsythe, Gorham, Hahn, Hanson, Ledyard, Levmore, Litan, Milgrom, Nelson, Neumann, Ottaviani, Schelling, Shiller, Smith, Snowberg, Sunstein, Telock, Varian, Wolfers, Zitzewitz, 2008 ; Snowberg, Wolfers, Zit-zewitz, 2013), d’autre part, les partisans des sondages conventionnels (Manski, 2006 ; Erikson et Wlezien, 2008, 2012).
Arrow et collar. (2008) fournissent un exemple qui illustre bien le concept d’un marché de type winner-takes-all. Imaginez un contrat qui rémunère 1$ si le candidat X gagne l’élection. Selon les lois du marché, le prix de ce contrat peut varier entre 0 et 1$ :
(1E0) ∼ prix 1 ∗ P (E) + 0 ∗ (1 − P (E)) = prix P (E) = prix
De ce fait, si le prix courant pour la prédiction X est de 0,53$, le marché annonce que le candidat X a 53 % de chance de gagner. Selon l’hypothèse d’efficacité des marchés, le prix courant, où il y a autant d’acheteurs que de vendeurs, correspondrait à la meilleure prédiction du résultat de l’événement.
Il existe également deux autres types de marchés de prédiction. Dans les marchés de type index, le gain varie selon une variable continue, comme le pourcentage de vote obtenu par un candidat. Dans ce cas-ci, le prix de ce type de contrat indique le pourcentage de vote moyen que le marché accorde au candidat. Finalement, dans un marché de type spread, plutôt que de parier sur la réalisation d’un événement, les participants vont, par exemple, parier qu’un candidat obtiendra plus qu’un certain pourcentage de vote. Au final, ces marchés peuvent
permettre d’identifier la valeur médiane associée à un événement.
Les fervents des marchés rapportent également que le pouvoir prédictif de ceux-ci repose sur le fait que le potentiel de profit crée un fort incitatif à collecter de l’information. En conséquence, puisqu’ils sont facilement accessibles, ils permettraient d’agréger l’information pertinente qui est largement répandue parmi les agents économiques. Les marchés de prédiction attirent donc les individus croyant que l’information dont ils disposent peut leur rapporter des bénéfices. Le prix d’entrée, soit le coût d’achat d’une prédiction, permet en quelque sorte de faire cette sélection. Ce coût vise à décourager les individus ne détenant pas d’information pertinente de prendre part à ceux-ci, car la participation de ces derniers peut biaiser les prédictions des marchés.
En plus des arguments théoriques, certains auteurs ont relaté des évidences empiriques afin d’appuyer les marchés. Wolfers et Zitzewitz (2004) ont comparé les prédictions des marchés et des sondages au cours de la semaine menant au vote pour quatre campagnes présidentielles américaines. Les marchés ont prédit le pourcentage de vote des démocrates et de républi-cains avec une moyenne d’erreur absolue d’environ 1,5 %. En comparaison, pour les quatre mêmes élections, les derniers sondages Gallup ont fourni des prédictions avec une moyenne d’erreur absolue de 2,1 %. Les données montrent également que cette moyenne d’erreur se situe à seulement 5 % pour les marchés lorsque l’on remonte à 150 jours avant l’élection. Une moyenne qui est considérablement plus petite que celle des prédictions des sondages à pareille date.
De leur côté, les partisans des sondages invitent à ne pas sauter aux conclusions trop rapide-ment lorsque l’on observe les prédictions des marchés. Selon eux, les deux types de prévisions ne sont pas comparables. C’est que les prix des marchés prédisent le dénouement de l’élec-tion, tandis que les sondages conventionnels agrègent les préférences des individus le jour des sondages. Erikson et Wlezien (2008) ont d’ailleurs montré qu’il est possible de transformer l’information donnée par les sondages en projection pour le jour de l’élection. Même que leurs projections ont donné des prévisions plus précises que ce que les marchés avaient offert pour trois campagnes présidentielles sur cinq. Par ailleurs, il semblerait que les marchés soient im-précis pour prédire le dénouement d’événement à faible probabilité de réalisation (Snowberg et Wolfers, 2005).
On peut aussi se questionner sur la présence de biais dans la prise de décision des partici-pants aux marchés. À l’aide d’évidences empiriques, Forsythe et al. (1992) ont montré que les préférences des individus peuvent influencer leurs décisions et que ces mêmes individus peuvent surestimer leur pouvoir prédictif. Malgré tout, ces derniers ont évoqué que même si une majorité de participants dans un marché souffre de ces types de comportements, les
prédictions qui en découlent peuvent être précises, car les prix sont déterminés par l’action des participants marginaux qui n’en souffrent pas.
En somme, malgré tout l’espoir qu’ils suscitent, les marchés de prédiction ne sont pas sans faille. Au regard de ce qui précède, on devrait plutôt les utiliser comme des compléments et non des substituts aux sondages conventionnels.
Chapitre 2
Méthodologie
2.1
Le dispositif expérimental
Afin de répondre aux objectifs de recherche, une expérience en laboratoire a été effectuée. Le dispositif expérimental utilisé est une version légèrement modifiée de celui développé par Allodehou (2015). Dès lors, divers scénarios de processus électoraux ont été proposés à des participants qui ont eu à répondre à des questions de sondage. Le dispositif expérimental a été conçu de manière à ce que l’on puisse mesurer la sensibilité des participants aux différents niveaux de covariance entre la probabilité de voter pour un candidat et la probabilité de participer au vote. Il a également été conçu afin de permettre la comparaison des pouvoirs prédictifs des marchés de prédiction et des sondages conventionnels. Rothschild et Wolfers (2011) ont montré à l’aide de sondages pré-électoraux que les anticipations des individus sur le comportement agrégé de la population ont un meilleur pouvoir prédictif que les intentions de vote. En proposant une démarche complémentaire, l’expérience effectuée dans le cadre de ce mémoire permet de tester cette conclusion. Ceci étant dit, nous n’avons pas reproduit exactement le fonctionnement des marchés de prédiction. L’approche utilisée par les marchés de prédiction a été intégrée dans l’expérience sous forme de sondage. En effet, les marchés ont été remplacés par des questions interrogeant les participants sur le comportement des autres sujets. Il y a donc eu des questions où les participants ont été invités à donner leurs anticipations sur le comportement agrégé de la population. Ainsi, l’information n’a pas été agrégée par le marché, mais plutôt par les répondants.
Lors de l’expérience, les participants jouent à la fois le rôle de sondé et celui de preneur de décision au moment du vote final. Lorsqu’ils sont sondés, ils doivent dans un premier temps faire part de leurs anticipations sur le comportement agrégé de la population. Ensuite, ils doivent indiquer leur propre intention de vote. On a donc pu observer l’écart entre les antici-pations des individus et leurs prises de décision au moment du vote final. C’est ce qui nous a permis de comparer le pouvoir prédictif des deux méthodes.
L’expérience propose aux participants trois options différentes. Ils doivent choisir entre l’op-tion A, l’opl’op-tion B ou ne pas faire de choix. Chacune des opl’op-tions A et B est associée à une valeur et un coût. Ce coût vise à représenter le coût d’aller voter dans une situation réelle, qui peut être physique ou psychologique. Il ne s’agit pas d’un cout d’opportunité associé au choix d’une option plutôt qu’une autre. Il peut se révéler être élevé (cH) ou faible (cL) et sa réalisation dépend de probabilités connues par les sujets. Les participants ont donc à faire des choix en se basant sur le gain net, soit la valeur associée à un choix moins son coût. Ceux qui décident de ne faire aucun choix obtiennent un gain alternatif.
Les participants sont associés à l’un des quatre types de personnes qui composent la popu-lation. Ces types, représentés par des couleurs, sont les bleus (B), les verts foncés (VF), les verts pâles (VP) et les jaunes (J). L’expérience est programmée pour qu’il y ait autant de personnes de chaque type. Néanmoins, les valeurs associées aux trois options varient à travers les types.
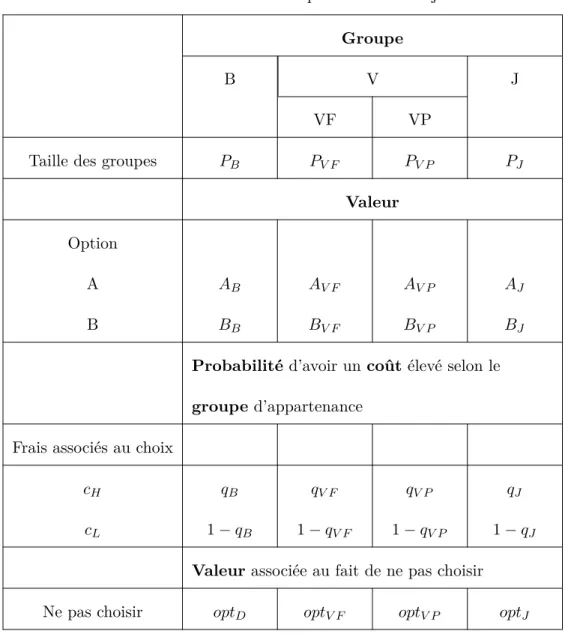
Dans l’expérience, l’information permettant aux participants de faire des prédictions est pré-sentée telle qu’ordonnée dans le tableau 2.1. Pour chaque type de personne, ce tableau indique la valeur des paramètres Pi, Ai, Bi, qi et opti. Ils représentent respectivement la taille du groupe, la valeur de l’option A, la valeur de l’option B, les probabilités associées à chaque coût et la valeur de l’alternative de ne pas voter. Dans tous les cas, les coûts de participation ont été fixés à 60 pour le coût élevé (cH) et 0 pour le coût faible (cL).
Tableau 2.1 – Informations présentées aux sujets
Groupe
B V J
VF VP
Taille des groupes PB PV F PV P PJ
Valeur
Option
A AB AV F AV P AJ
B BB BV F BV P BJ
Probabilité d’avoir un coût élevé selon le groupe d’appartenance
Frais associés au choix
cH qB qV F qV P qJ
cL 1 − qB 1 − qV F 1 − qV P 1 − qJ
Valeur associée au fait de ne pas choisir
Ne pas choisir optD optV F optV P optJ
2.2
Le plan expérimental
Les sujets participent à 16 tours de l’expérience. Ils sont rémunérés en fonction de leurs dé-cisions prises à la fin de chaque tour. Pour ce qui est de la valeur des paramètres, ils varient au fil de l’expérience. Voici en détail les 3 différentes étapes qui composent un tour. Le plan expérimental complet contenant les questions est présenté en annexe.
Étape 1 : Les participants ne savent pas à quel type ils appartiennent, mais ils sont informés
de la valeur des paramètres qui composent le tableau 2.1. Ils doivent prédire la décision de vote d’une population de 100 personnes contenant 25 individus de chaque type. Ils répondent soit à la question 1 ou à la question 2 et soit à la question 3a ou la question 3b. Les questions
auxquelles ils ont à répondre sont déterminées de manière aléatoire.
Étape 2 : À cette étape, les participants sont informés par l’ordinateur du groupe auquel ils
appartiennent. Pour ce qui est des bleus et des jaunes, ils n’ont aucune incertitude quant à leur groupe d"appartenance. Par contre, les verts ne savent pas s’ils sont vert foncé ou vert pâle. Ils ont toujours un peu d’incertitude sur la valeur de leurs paramètres. Par ailleurs, les participants ne savent pas plus précisément le niveau de coût qui se réalisera. Suite à ces changements, ils doivent faire part de leur propre intention de vote. Ils répondent soit à la question 4a ou à la question 4b et soit aux questions 5a et 5b ou à la question 6.
Étape 3 : Tous les participants connaissant le groupe auquel ils appartiennent et les frais
associés au vote pour un candidat. Ils doivent décider de faire ou non un choix en répondant à cette dernière question.
Quelle option choisissez-vous ?
Je choisis l’option A Je choisis l’option B
Je ne choisis aucune des deux options : je ne fais pas de choix
2.3
Traitements de l’expérience
Au total, huit traitements différents ont été construits afin de tester l’effet du biais causé par l’inattention envers la corrélation. Les paramètres de décision (Ai, Bi, qi et opti) varient
d’un traitement à l’autre. À partir de ceux-ci, on peut calculer les probabilités théoriques de voter pour un candidat et de participer au vote pour chaque traitement. Les paramètres sont d’ailleurs choisis afin que la covariance entre ces deux probabilités varie d’un traitement à l’autre. De ce fait, il nous a été possible de mesurer la sensibilité des sujets à différentes intensités de corrélation. Le tableau suivant présente les valeurs des paramètres pour les huit traitements.
T ableau 2.2 – P aramètres des h uit traitemen ts T raitemen t 1 T raitemen t 2 T raitemen t 3 T raitemen t 4 Group e B VF VP J B VF VP J B VF VP J B VF VP J T aille des group es 25 25 25 25 25 25 25 25 25 25 25 25 25 25 25 25 V aleur de l’option A 110 104 70 37 120 85 55 30 120 96 43 20 117 113 25 20 V aleur de l’option B 30 36 70 103 20 55 85 110 20 44 97 120 23 27 115 120 Probabilité d’a v oir un c oû t élev é 0.90 0.76 0.01 0.71 0.90 0.75 0.01 0.95 0.01 0.01 0.27 0.71 0.01 0.01 0.90 0.95 Option externe 30 36 70 37 20 55 55 30 20 44 43 20 23 27 25 20 T raitemen t 5 T raitemen t 6 T raitemen t 6 T raitemen t 8 Group e B VF VP J B VF VP J B VF VP J B VF VP J T aille des group es 25 25 25 25 25 25 25 25 25 25 25 25 25 25 25 25 V aleur de l’option A 103 70 36 30 110 85 55 20 120 97 44 20 120 115 27 23 V aleur de l’option B 37 70 104 110 30 55 85 120 20 43 96 120 20 25 113 117 Probabilité d’a v oir un c oû t élev é 0.71 0.01 0.76 0.90 0.95 0.01 0.75 0.90 0.71 0.27 0.01 0.01 0.95 0.90 0.01 0.01 Option externe 37 70 36 30 30 55 55 20 20 43 44 20 20 25 27 23
Afin d’illustrer le comportement d’un agent inattentif envers la corrélation, le tableau 2.3 pré-sente les gains potentiels lors du traitement 2 pour les groupes bleu et vert foncé en fonction du coût associé au vote et de l’option choisie.
Tableau 2.3 – Gains potentiels en fonction du coût associé au vote et de l’option choisie
Groupe Coût (probabilité) Gains
Option A Option B Ne pas voter
Bleu Élevé (90 %) 60 -40 20
Faible (10 %) 120 20 20
Vert Foncé Élevé (75 %) 25 -5 55
Faible (25 %) 85 55 55
En vue de maximiser ses gains, un individu du groupe Bleu devrait choisir l’option A, et ce, peu importe le coût auquel il fait face. En effet, même s’il fait face un coût élevé, choisir l’option A lui rapporte le gain le plus élevé, soit 60. La situation est différente pour les indi-vidus du groupe Vert foncé. En absence de coût, ces derniers obtiennent un gain de 85 s’ils choisissent l’option A et de 55 s’il choisissent l’option B. Ils ont donc une préférence pour l’option A. Toutefois, dans l’éventualité où un individu du groupe Vert foncé fait face à un coût élevé, choisir l’option A n’est pas l’option qui maximise ses gains. C’est plutôt l’option de ne pas voter qui lui offre le gain le plus élevé.
Face à cette situation, un agent inattentif envers la corrélation affirmera que les 25 indivi-dus du groupe Vert foncé choisiront l’option A. Celui-ci effectue sa prédiction en ne tenant compte que de la préférence des individus. De son côté, un agent rationnel affirmera que les 25 individus du groupe Vert choisiront l’option A seulement s’ils font face à un coût faible, dont la probabilité de réalisation est de 25 %. Il soutiendra donc qu’environ 6 individus du groupe Vert foncé choisiront l’option A.
Par ailleurs, les traitements cinq à huit correspondent aux traitements miroirs des traitements un à quatre. Par exemple, si on observe le groupe des jaunes du traitement 5, on constate que les paramètres sont les mêmes que pour le groupe des bleus du traitement 1, mais avec les valeurs des options A et B inversées. L’effet miroir est également observable entre le groupe des verts foncés et des verts pâles. Cette particularité nous a permis de tester l’impact de la disposition de l’information. À cet effet, des tests de Student pour échantillons indépendants ont été réalisés pour chaque paire de traitements miroirs. Un individu rationnel devrait traiter la probabilité de voter pour le candidat B des 25 personnes du groupe Jaune du traitement 5 de la même manière que la probabilité de voter pour le candidat A des 25 personnes du groupe Bleu du traitement 1. Les résultats des tests ne nous permettent pas d’affirmer avec
certitude que la disposition de l’information a eu un impact sur les prédictions des participants.
Ainsi, dans l’optique d’alléger l’analyse, les huit traitements ont été regroupés pour n’en for-mer que quatre. Une fois l’expérience terminée, des modifications ont été apportées à la base de données regroupant les réponses des sujets. Ainsi, si on s’en tient à l’exemple précédent, la manipulation de la base de données a fait que les prédictions de vote pour le candidat B concernant les 25 personnes du groupe Jaune du traitement 5 ont été traitées comme des prédictions de vote pour le candidat A concernant les 25 personnes du groupe Bleu du traite-ment 1. Selon cette même logique, les prédictions de vote pour le candidat B concernant les 25 personnes du groupe Vert pâle du traitement 6 ont été traitées comme des prédictions de vote pour le candidat A concernant les 25 personnes du groupe Vert foncé du traitement 2.
2.4
Les différents types de questions utilisés dans les
sondages
Les sondeurs ont recours à différentes méthodes afin d’évaluer les proportions de différentes caractéristiques d’une population. Deux types d’information sont exploités : les anticipations des individus sur leur propre comportement et les anticipations des individus sur le com-portement agrégé de la population. De surcroît, plusieurs formats de questions sont utilisés par les organismes de sondages. Les principaux formats utilisés sont les questions binaires, binaires avec incertitude et probabilistes. Les questions binaires sont celles dont les réponses donnent le moins d’information aux sondeurs. Le répondant ne peut faire preuve d’incertitude à propos de son choix. De leur côté, les questions probabilistes permettent au répondant de quantifier l’incertitude relative à son choix. Finalement, on peut voir les questions binaires avec incertitude comme un intermédiaire entre les questions binaires et probabilistes. La suite de cette section présente une courte description de l’utilisation de ces types de questions pour chacune des deux méthodes de sondages. Des questions tirées de l’expérience sont présentées à titre d’exemple.
Les trois principaux formats de questions peuvent être employés avec les deux méthodes de sondage. Dans le cadre de sondages conventionnels, les questions binaires invitent les répon-dants à révéler pour qui ils ont l’intention de voter. Le nombre de choix de réponses correspond au nombre de candidats.
Question binaire - Prédiction individuelle
Supposez que vous décidiez de choisir l’une des options. Laquelle des deux options choisiriez-vous ?
Si je décide de choisir l’une des options, je choisirai l’option A.
je choisirai l’option B.
Les questions binaires avec incertitude permettent aux répondants d’indiquer aux sondeurs s’ils sont indécis. La forme de la question peut être la même que pour une question binaire, mais le choix de réponses permet d’exprimer de l’incertitude. Le cas échant, une sous-question est généralement posée. Elle cherche à savoir vers quel candidat le répondant penche davan-tage.
Question binaire avec incertitude - Prédiction individuelle
Supposez que vous décidiez de choisir l’une des options. Laquelle des deux options choisiriez-vous ?
Si je décide de choisir l’une des options, je choisirai l’option A.
je choisirai l’option B.
je ne sais pas quelle option je choisirai.
Si vous n’êtes pas sûr de l’option que vous choisiriez, veuillez s’il vous plaît indi-quer l’option vers laquelle vous penchez le plus.
Je choisirai probablement l’option A Je choisirai probablement l’option B
Quant à elles, les questions probabilistes invitent les participants à indiquer leur probabilité de voter pour chacun des candidats. Ces questions permettent également aux répondants d’in-diquer une mesure quantifiable de l’incertitude relative à leur participation au vote. Il s’agit du type de question offrant le plus d’information aux sondeurs.
Question probabiliste - Prédiction individuelle
Quelles sont les chances que vous choisissiez chacune des options A et B ?
S’il vous plaît, indiquez la chance de choisir chaque option en termes de probabilités. "0" in-dique que vous êtes certain de ne pas vouloir choisir l’option concernée et "100" inin-dique que vous êtes certain de vouloir choisir l’option concernée. Si vous choisissez un nombre compris entre "0" et "100", vous indiquez que vous n’êtes pas certain de choisir l’option concernée. Plus le nombre choisi est proche de "100", plus vous êtes certain de choisir l’option concernée. Plus le nombre choisi est proche de "0", plus vous êtes certain de ne pas choisir l’option concernée.
Les chances que je choisisse l’option A sont de : (en %) ... Les chances que je choisisse l’option B sont de : (en %) ...
Les chances que je ne fasse pas de choix (ne choisisse aucune des deux options) sont de : (en %) ...
Ces types de questions peuvent également être utilisés par les sondeurs dans l’optique de faire dévoiler les anticipations des participants sur le comportement agrégé de la population, à sa-voir qui obtiendra le plus de votes. Les questions binaires et binaires avec incertitude invitent directement les répondants à se prononcer sur leur prédiction du candidat gagnant. Les choix de réponses suivent la même logique que pour les prédictions individuelles.
Question binaire - Prédiction agrégée
Considérez les valeurs des options et les frais associés au choix selon le groupe présentés dans le tableau ci-dessus. Il y a 25 personnes dans chacun des groupes bleu, vert foncé, vert pâle et jaune, soit au total 100 personnes.
Quelle est selon vous l’option qui sera choisie le plus souvent ?
L’option A sera choisie le plus souvent L’option B sera choisie le plus souvent
Question binaire avec incertitude - Prédiction agrégée
Considérez les valeurs des options et les frais associés au choix selon le groupe présentés dans le tableau ci-dessus. Il y a 25 personnes dans chacun des groupes bleu, vert foncé, vert pâle et jaune, soit au total 100 personnes.
Quelle est selon vous l’option qui sera choisie le plus souvent ?
L’option A sera choisie le plus souvent L’option B sera choisie le plus souvent Je ne sais pas
Si vous n’êtes pas sûr de l’option qui sera choisie, veuillez s’il vous plaît indiquer l’option vers laquelle vous penchez le plus
L’option A sera probablement choisie plus souvent que l’option B L’option B sera probablement choisie plus souvent que l’option A
De leur côté, les questions probabilistes invitent plutôt les répondants à se prononcer sur la probabilité que chacun des candidats remporte le scrutin final. Les répondants peuvent éga-lement être amenés à se prononcer sur le nombre de personnes qui ne participeront pas au vote.
Question probabiliste - Prédiction agrégée
Considérez les valeurs des options et les frais associés au choix selon le groupe présentés dans le tableau ci-dessus. Il y a 25 personnes dans chacun des groupes bleu, vert foncé, vert pâle et jaune, soit au total 100 personnes.
Quelle est votre prédiction du choix agrégé de ces 100 personnes ?
Nombre de personnes qui choisiront l’une des options A ou B (sur un total de 100) : ... Nombre de personnes qui ne choisiront aucune des deux options (sur un total de 100) : ...
Parmi ceux qui choisiront l’une des options, selon vous, combien de personnes choisiront chacune des options A et B ?
Svp, cochez si vous répondez de manière absolue ou relative et indiquez votre prévision.
Réponse absolue
- Je pense que ... personnes choisiront l’option A. - Je pense que ... personnes choisiront l’option B.
Réponse relative
- Je pense que ... % des personnes choisiront l’option A. - Je pense que ... % des personnes choisiront l’option B.
Tableau 2.4 – Types de question posés dans les sondages pré-électoraux
Question Information demandée Forme de la réponse
1 Anticipations de l’individu sur son propre Binaire
2 comportement Binaire avec incertitude
3 Probabiliste
4 Anticipations de l’individu sur le Binaire
5 comportement agrégé de la population Binaire avec incertitude
6 Probabiliste
L’expérience réalisée dans le cadre de ce mémoire exploite les six catégories de question présentées dans le tableau 2.4. Ce tableau résume en six catégories ces différentes variétés de questions selon la méthode de sondage utilisée et la forme de réponse demandée. Dès lors, même si l’objectif principal était de comparer le pouvoir prédictif des deux méthodes de sondage, les résultats de l’expérience permettent également de comparer le pouvoir prédictif des différents formats de question.
Chapitre 3
Résultats de l’expérience
3.1
Statistiques descriptives
L’expérience s’est déroulée au Laboratoire d’Économie Expérimentale de l’Université Laval (LEEL) durant les mois de mars, avril et mai 2017. Au total, 50 sujets ont participé à l’une des cinq séances proposées. Aucun d’entre eux n’a participé à plus d’une séance. Le groupe de participants a été recruté à l’aide du système de recrutement en ligne du LEEL. Celui-ci était composé d’étudiants, d’anciens étudiants et d’employés de l’Université Laval. L’âge moyen des sujets était de 33 ans, l’âge médian de 29 ans et le groupe était composé à 74 % d’homme. Les sujets devaient faire part de leur plus haut niveau de scolarité atteint et de leur domaine d’étude. À ce propos, 42 % des participants ont mentionné le premier cycle universitaire, 28 % le deuxième cycle et 30 % le troisième cycle. Quant aux domaines d’études, 22 % des sujets ont indiqué être un étudiant ou un diplômé en économique, les autres étant répartis parmi plusieurs programmes variés.
L’expérience a été conduite à l’aide du logiciel expérimental Z-tree. Avant d’y participer, les sujets devaient visionner une vidéo d’instructions d’une durée de 6 minutes. Ils avaient éga-lement accès à des instructions écrites tout au long de l’expérience. La durée moyenne pour parcourir les 16 tours de l’expérience a été de 45 minutes.
Les sujets ont été rémunérés pour leur participation. D’une part, l’ampleur du gain était fonc-tion de la chance, alors qu’à chaque tour, le hasard déterminait si les participants faisaient face à un coût faible ou élevé de voter. D’autre part, l’importance du gain dépendait de la prise de décision des sujets, alors qu’à la fin de chaque tour, ils devaient choisir parmi trois options associées à des gains différents, soit l’option A, l’option B ou ne pas voter. Afin de maximiser ses profits, un participant devait choisir l’option qui lui rapportait le gain net le plus important, ce qu’on qualifie de décision monotone dans le cadre de cette expérience. Si un participant décidait de ne pas voter, son gain net correspondait à la valeur associée à
cette option. Par contre, si l’une des options A ou B était choisie, le gain net du participant correspondait à la valeur de l’option choisie, à laquelle on soustrayait le coût associé au vote. L’analyse des décisions finales des sujets révèle que 8,38 % de celles-ci n’ont pas été mono-tones. En d’autres termes, lors de 67 des 800 tours effectués, un participant n’a pas pris la décision qui lui aurait rapporté le gain le plus important. La perte moyenne associée à chacune des décisions non monotones a été d’environ 1 dollar pour les sujets.
Les gains étaient comptabilisés en unité de paiement expérimentale (UPE) au cours de l’ex-périence pour ensuite être convertis en dollar canadien. Le taux de change était de 1 dollar canadien pour 50 UPE. Le paiement final incluait un montant fixe de 5$ pour couvrir les frais de transport. Les sujets ont obtenu un paiement moyen de 28$. Le gain minimum obtenu a été de 12$, pour un maximum de 33$.
Tableau 3.1 – Statistiques descriptives des participants
Variable Fréquence Moyenne Minimum Maximum
Âge 50 33 20 66 Sexe Homme 37 0,74 0 1 Femme 13 0,26 0 1 Scolarité Baccalauréat 21 0,42 0 1 Maîtrise 14 0,28 0 1 Doctorat 15 0,30 0 1 Économique 11 0,22 0 1 Temps (s) Tour 800 170 33 2059 Total 50 2727 1331 5120 Gain ($) 50 28,27 11,90 32,72 Décision monotone 733 0,92 0 1
3.2
Pouvoir prédictif des sondages
Au départ, l’idée était d’observer les décisions de vote finales des sujets et de les comparer aux prédictions des différentes questions de sondage. L’écart entre les décisions et les prédictions devaient nous permettre de comparer le pouvoir prédictif des deux méthodes de sondage et des trois types de questions. Nous avons cependant constaté, à la suite des analyses de la sec-tion précédente, que les participants n’ont pas toujours pris des décisions monotones. Or, les participants devaient faire leurs prédictions agrégées et individuelles en fonction de l’option qui maximisait les gains de chacun. Une comparaison entre les décisions et les prédictions n’était donc plus compatible.
Pour remédier à cette situation, nous avons créé une variable correspondant au maximum de gain que les participants pouvaient obtenir à chacun des tours selon les différents paramètres qui leur étaient présentés au moment du vote final. Lorsque cette nouvelle variable ne corres-pondait pas au gain réellement obtenu, nous avons modifié la décision finale en faveur de la décision qui aurait rapporté le gain net le plus élevé.
De plus, un facteur de correction a dû être appliqué aux décisions finales pour en permettre la comparaison avec les prédictions des questions agrégées. À chaque tour, les participants étaient attitrés à l’un des quatre groupes de manière aléatoire. Même si la probabilité d’ap-partenir à chacun des groupes était de 25 %, les sujets n’ont pas été répartis de manière égale entre ceux-ci. L’utilisation de facteurs de corrélation nous a permis de rendre compatibles le vote effectif et les prédictions agrégées des sujets concernant 100 personnes réparties de manière égale entre les quatre groupes. Le tableau suivant illustre la répartition des sujets entre les groupes pour le traitement 1.
Tableau 3.2 – Répartition des sujets (Traitement 1) Groupe Fréquence Fréquence relative (%)
Bleu 53 26,5
Vert foncé 55 27,5
Vert pâle 44 22,0
Jaune 48 24,0
Total 200 100
Facteur de correction (Bleu) = 0, 25/0, 265 = 0, 9434 (3.1) Facteur de correction (Vert foncé) = 0, 25/0, 275 = 0, 9091 (3.2) Facteur de correction (Vert pâle) = 0, 25/0, 220 = 1, 1364 (3.3) Facteur de correction (Jaune) = 0, 25/0, 240 = 1, 0417 (3.4)
En appliquant un facteur de correction, nous avons réduit le poids relatif dans le vote effectif des groupes contenant plus de 25 % des sujets et augmenté celui des groupes contenant moins de 25 % des sujets. Les choix du groupe Bleu pour le traitement 1 ont été pondérés par 0,9434 et ainsi de suite.
Le tableau 3.3 présente les écarts entre les prédictions des différentes questions de sondages et le vote effectif pour le candidat A. Du côté des questions interrogeant les individus sur le comportement agrégé de la population, les questions probabilistes ont fait meilleure figure. En effet, quel que soit le traitement, aucune des questions binaires n’a mieux prédit le résultat
final que les questions probabilistes. La moyenne des écarts pour la question binaire la plus performante est de 3,5 % supérieure à celle des questions probabilistes. Quant aux questions interrogeant les individus sur leur propre intention de vote, les questions binaires ont été lé-gèrement plus performantes. La meilleure question binaire présente un écart inférieur ou égal à la meilleure question probabiliste pour chaque traitement. La question binaire avec incerti-tude Q4B est notamment celle qui affiche la moyenne d’écart la plus faible parmi toutes les questions de l’expérience.
Tableau 3.3 – Écarts entre les prédictions des questions de sondage et le vote effectif Préd. agrégées Préd. individuelles Probabilistes Binaires Probabilistes Binaires
Q1 Q2 Q3A Q3B Q5 Q6 Q4A Q4B Traitement 1 0,07 0,08 0,13 0,08 0,05 0,08 0,05 0,03 Traitement 2 0,09 0,10 0,10 0,13 0,10 0,06 0,04 0,05 Traitement 3 0,01 0,00 0,10 0,08 0,01 0,07 0,06 0,01 Traitement 4 0,03 0,02 0,08 0,05 0,04 0,00 0,05 0,00 Moyenne 0,050 0,050 0,103 0,085 0,050 0,053 0,050 0,023
Les résultats du tableau 3.3 permettent également de comparer le pouvoir prédictif des deux méthodes de sondages. La différence d’écart n’est pas élevée si on compare par traitement, les questions probabilistes qui ont été les plus précises selon chaque méthode. La méthode individuelle a été plus performante pour trois des quatre traitements. Par contre, on ne re-trouve aucune différence de plus de 3 % entre les deux méthodes. Ces résultats ne permettent pas vraiment de distinguer si l’une des méthodes a été plus performante relativement aux questions probabilistes. Le constat n’est pas le même pour les questions binaires. Effective-ment, les prédictions binaires individuelles ont considérablement mieux prédit le vote final que les prédictions binaires agrégées. Pour chaque traitement, la meilleure prédiction binaire individuelle est plus proche du vote effectif que la prédiction binaire agrégée la plus précise. La différence entre les écarts est d’au moins 5 %, tandis que la différence moyenne est de 5,75 %. La question binaire avec incertitude 4B est celle qui a le mieux performé toutes méthodes confondues avec une moyenne d’écart de 2,3 %.
Afin de tester la robustesse de ces résultats, nous avons effectué des tests de Student pour échantillons indépendants. Ce test paramétrique est utile afin de comparer deux échantillons, alors qu’il permet de conclure si les moyennes de ceux-ci sont significativement différentes. Pour chacun des tests effectués, les hypothèses suivantes ont été posées :
H0 : X1 = X2 H1 : X1 6= X2
Dans un premier temps, nous avons comparé les moyennes des réponses aux questions pro-babilistes qui ont le mieux performé selon chaque méthode. Ensuite, nous avons fait la même chose pour les questions binaires. Les tableaux 3.4 et 3.5 présentent les valeurs-p découlant de chacun des tests effectués.
Tableau 3.4 – Valeurs-P (Questions probabilistes) Questions Traitement Valeur-P
Q1-Q5 1 0,335
Q1-Q6 2 0,863
Q2-Q5 3 0,664
Q2-Q6 4 0,446
Tableau 3.5 – Valeurs-P (Questions binaires) Questions Traitement Valeur-P
Q3B-Q4A 1 0,062
Q3A-Q4A 2 0,695
Q3B-Q4B 3 0,362
Q3B-Q4B 4 0,324
À un seuil de signification de 5 %, il nous est impossible de rejeter l’hypothèse nulle à la suite d’aucun des tests. Ces derniers résultats nous invitent à être prudents face aux premiers constats de l’analyse.
3.3
Le biais d’inattention envers la corrélation
3.3.1 Mesure de l’inattention envers la corrélation
Le dispositif expérimental a été conçu afin de tester l’effet du biais d’inattention envers la corrélation sur les réponses des participants. Les résultats nous ont permis de distinguer la part des répondants qui ont souffert du biais, et ce, pour chacun des traitements. De plus, nous proposons une mesure visant à quantifier l’effet, soit le biais moyen minimal.
Pour discerner les individus qui ont souffert du biais, nous avons comparé la corrélation théo-rique à celle perçue par les répondants. Le coefficient Phi a été utilisé afin de mesurer ces différentes corrélations. Ce coefficient permet de mesurer le degré de liaison entre deux va-riables binaires. Il s’exploite de la même manière que le coefficient de corrélation. Le codage entre -1 et 1 permet de détecter les attractions ou les répulsions entre les modalités. Un co-efficient proche de 0 indique une association faible entre deux variables. Si celui-ci est proche de 1 ou -1, cela indique qu’il existe une forte dépendance, positive ou négative. La table de contingence est obtenue en croisant les deux variables étudiées. Elle est toujours composée de deux colonnes et de deux lignes.
Tableau 3.6 – Table de contingence
0 1
0 P00 P01 Q1
1 P10 P11 P1
Q2 P2
Selon la notation de la table de contingence, le coefficient Phi se calcul comme suit :
φ = P00√P11− P01P10 P1Q1P2Q2
(3.5)
Dans le cadre de cette expérience, les deux variables binaires sont le vote et la préférence.
Tableau 3.7 – Table de contingence applicable à l’expérience
V=0 V=1
A PA0 PA1 P (A)
B PB0 PB1 P (B)
P0 P1
où V=1 si vote, V=0 si ne vote pas, A si A est préféré et B si B est préféré.
Dans ce tableau, la case PA1 correspond à la probabilité jointe de participation aux élections et de préférer A. À l’opposé, la case PB1 correspond à la probabilité jointe de participer aux
élections et de préférer B. Les questions de l’expérience ont été formulées afin de connaitre les croyances des participants quant à ces probabilités. Ainsi, pour chacune des questions, nous avons pu calculer la corrélation perçue par les sujets entre ces variables. On se rappelle qu’un individu souffrant d’inattention envers la corrélation néglige les différences de probabilité de participation à travers les groupes. En conséquence, la corrélation perçue par ce dernier sera égale à zéro, ou du moins inférieure à la valeur théorique. Ceci en raison de la probabilité de participer et des préférences (A ou B) qui ne sont pas constantes à travers les groupes. Il y a donc une corrélation entre le fait de préférer un certain candidat et la probabilité de voter.
Aucune question de l’expérience n’a été formulée afin de sonder les participants sur leurs perceptions des probabilités associées aux cases PA0et PB0, soient les probabilités de préférer
un candidat et de ne pas voter. Le plan était de les calculer nous-mêmes de la manière suivante :
PA0= P (A) − PA1 (3.6)
PB0= P (B) − PB1 (3.7)
Les vraies probabilités P (A) et P (B) pouvaient facilement être calculées à partir des préfé-rences indiquées dans le tableau des valeurs. Nous croyions que tous les participants allaient répondre aux questions en tenant compte de ces probabilités. Cependant, lorsque question-nés sur les probabilités PA1 et PB1, des sujets ont indiqué des valeurs supérieures à P (A) et P (B), ce qui est mathématiquement impossible. Par l’utilisation des équations 3.6 et 3.7, nous aurions calculé des valeurs négatives dans certains cas. En conséquence, le calcul de la corrélation perçue s’est plutôt fait sous forme de borne. Nous avons calculé, pour les réponses à chacune des questions, une borne minimale et une borne maximale de la corrélation perçue par le répondant. Par exemple, un sujet peut indiquer que 60 personnes participeront au vote selon les préférences suivantes.
Tableau 3.8 – Exemple de réponse d’un participant
V=0 V=1
A PA0 40 P (A)
B PB0 20 P (B)
Les 40 personnes restantes (P0) sont réparties selon les deux extrêmes. Pour la borne #1, on considère que chez les personnes qui ne voteront pas, le candidat A est préféré par tous, alors que pour la borne #2, on considère que le candidat B est préféré par tous. Le même raisonnement est applicable avec les probabilités individuelles de voter pour les questions 5 et 6.
Tableau 3.9 – Table de contingence (Borne #1)
V=0 V=1 A 40 40 80 B 0 20 20 40 60 où φ1 = 40 ∗ 20 − 40 ∗ 0 √ 20 ∗ 80 ∗ 60 ∗ 40 = 0, 4082 (3.8)
Tableau 3.10 – Table de contingence (Borne #2)
V=0 V=1 A 0 40 40 B 40 20 60 40 60 où φ2 = 0 ∗ 20 − 40 ∗ 40 √ 60 ∗ 40 ∗ 60 ∗ 40 = −0, 6667 (3.9)
Le coefficient Phi est calculé pour chacune de ces tables de contingence. Ces deux coefficients permettent de borner la corrélation perçue par les sujets et de constater si la corrélation théorique se situe à l’intérieur de celles-ci. Le cas échant, nous ne pouvons pas conclure que les sujets ont souffert d’inattention envers la corrélation. À l’opposé, lorsque la corrélation théorique se situe à l’extérieur des bornes, nous pouvons conclure que les sujets ont souffert
d’inattention envers la corrélation.
La corrélation théorique est également calculée selon la formule du coefficient Phi. On utilise les probabilités conjointes théoriques pour former la table de contingence. Considérant qu’il y a 25 personnes dans chaque groupe, ces probabilités correspondent aux pourcentages des 100 participants qui seraient associés à chacune des cases de la table de contingence dans l’éventualité où chacun d’entre eux prend une décision monotone, soit celle qui maximise ses gains. Puisque la valeur des paramètres de l’expérience diffère à travers les traitements, la corrélation théorique a été calculée pour chacun de ceux-ci. Le tableau suivant présente les probabilités conjointes théoriques découlant des différents paramètres du Traitement 1.
Tableau 3.11 – Probabilités conjointes théoriques du Traitement 1
V=0 V=1 A 0,0425 0,5825 0,625 B 0,0425 0,3325 0,375 0,085 0,915 où φ = 0, 0425 ∗ 0, 3325 − 0, 5825 ∗ 0, 0425√ 0, 375 ∗ 0, 625 ∗ 0, 915 ∗ 0, 085 = −0, 079 (3.10)
Les sujets des groupes bleus et jaunes n’ont jamais d’incertitude à propos de leur meilleure option. Même s’ils font face à un coût élevé, voter pour leur candidat préféré reste toujours le meilleur choix. Dès lors, la corrélation théorique a également été calculée en ne prenant en compte que les groupes vert foncé et vert pâle. Nous avons utilisé cette corrélation pour l’analyse des questions où les participants ont été sondés sur leur propre intention.
Tableau 3.12 – Probabilités conjointes théoriques du Traitement 1 (Groupe des verts)
V=0 V=1
A 0,085 0,665 0,75
B 0,085 0,165 0,25
où
φ = 0, 085 ∗ 0, 165 − 0, 665 ∗ 0, 085√
0, 25 ∗ 0, 75 ∗ 0, 83 ∗ 0, 17 = −0, 261 (3.11)
Le tableau 3.13 présente les corrélations théoriques découlant des paramètres de chacun des traitements.
Tableau 3.13 – Corrélations théoriques des quatre traitements Traitement Tous les groupes Groupes des verts
1 -0,079 -0,261
2 0,472 0.762
3 -0,255 -0,375
4 0 0
Les résultats de l’analyse sont présentés dans le tableau 3.14. On retrouve une analyse dis-tincte pour chaque combinaison de traitement et question. À ce propos, seulement les réponses aux questions probabilistes (1,2,5 et 6) permettaient le calcul de la corrélation perçue. En conséquence, les réponses aux questions binaires (3 et 4) n’ont pas été considérées dans cette analyse.
Pour les trois premiers traitements, le tableau ordonne les sujets selon trois catégories. En premier lieu, on retrouve ceux pour qui la corrélation théorique se retrouve à l’intérieur des bornes. Pour ceux-ci, nous ne pouvons pas conclure qu’ils ont souffert du biais d’inattention envers la corrélation. Par contre, cela ne signifie pas qu’ils n’en aient pas souffert. Notre ana-lyse ne permet tout simplement pas de le confirmer. La figure 3.1 illustre ce type de situation. Les paramètres B1, B2 et t représentent respectivement la borne #1, la borne #2 et la cor-rélation théorique.
−1 B1 t 0 B2 1
Figure 3.1 – Corrélation théorique bornée
Ensuite, la deuxième ligne regroupe ceux pour qui la corrélation théorique n’est pas bornée. Notre analyse nous permet de conclure que ces sujets ont souffert du biais d’inattention envers la corrélation. Cette inattention est considérée comme étant partielle, car les sujets ont tout de même perçu un certain niveau de corrélation, mais plus faible que la valeur réelle. La figure
3.2 illustre ce type de situation.
−1 B1 0 B2 t 1
Figure 3.2 – Corrélation théorique non bornée
Finalement, on distingue à la dernière ligne la fréquence des participants pour laquelle nous avons calculé des bornes égales à zéro. Ces derniers n’ont perçu aucune corrélation. On consi-dère donc qu’ils ont souffert d’inattention absolue envers la corrélation.
L’analyse est différente pour le traitement 4. Lors de celui-ci, la probabilité de participation ne varie pas à travers les groupes. Les paramètres de ce traitement font en sorte que même face à des coûts élevés, tous les participants ont intérêt à voter. C’est pourquoi la corréla-tion théorique est de 0. Ainsi, pour ce traitement, les sujets pour qui nous avons calculé des bornes égales à zéro sont ceux ayant perçu la bonne intensité de corrélation. À l’opposé, nous considérons que ceux ayant perçu une corrélation non nulle ont souffert d’une autre forme d’in-attention envers la corrélation. Ils ont perçu un effet de corrélation alors qu’il n’y en avait pas.
Tableau 3.14 – Mesure de l’inattention envers la corrélation
Préd. Agrégées Préd. Individuelles
Q1 Q2 Q5 Q6
Total (%)
Fréq. % Fréq. % Fréq. % Fréq. %
Borné 102 89 68 80 28 72 40 67 80
Traitement 1 Non borné 0 0 2 3 1 2 2 3 2
Borne = 0 13 11 15 17 10 26 18 30 19
Borné 72 68 41 44 12 24 10 20 45
Traitement 2 Non borné 24 23 33 35 28 56 23 36 36
Borne = 0 10 9 20 21 10 20 17 34 19
Borné 75 69 43 47 20 60 21 42 56
Traitement 3 Non borné 8 8 12 13 6 19 7 14 12
Borne = 0 25 3 37 40 7 21 22 44 32
Traitement 4 Borné 49 45 48 52 26 53 29 55 50
Non borné 59 55 44 48 23 47 24 45 50
Total (%) Borné 68 55 50 47 58
On retire trois principaux constats des résultats du tableau 3.14. On constate tout d’abord que plus la corrélation théorique était élevée, plus les sujets ont souffert d’inattention envers la corrélation. En effet, 80 % des participants ont bien cerné la corrélation lors du traitement 1, contre 56 % lors du traitement 3 et 45 % lors du traitement 2. Quant au traitement 4, les
résultats montrent que seulement une personne sur deux a reconnu l’absence de corrélation entre la préférence et la probabilité de voter. Les résultats pour les trois premiers traitements illustrent une sous-estimation de la corrélation, tandis que ceux du traitement 4 mettent en évidence une surestimation de celle-ci. Finalement, les résultats permettent de distinguer si les participants ont été plus disposés à souffrir du biais selon l’une des méthodes de sondage. À cet égard, les résultats montrent que les sujets ont mieux perçu la véritable intensité de corrélation en répondant aux questions 1 et 2, soit celles demandant le même type d’informa-tion que les marchés de prédicd’informa-tion.
Les résultats du tableau 3.15 permettent quant à eux de quantifier l’effet du biais d’inattention envers la corrélation. Il présente par traitement et par question, la moyenne des écarts entre la corrélation théorique et la borne la plus près chez les sujets inattentifs envers la corrélation. Nous qualifions cette mesure de biais minimal moyen.