Two-level Mixtures of Markov Trees
Texte intégral
Figure
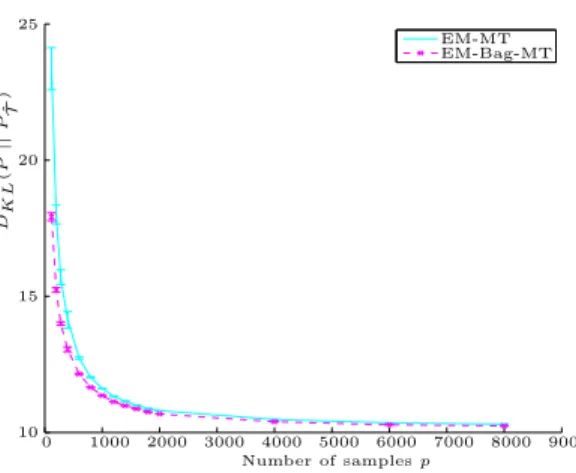
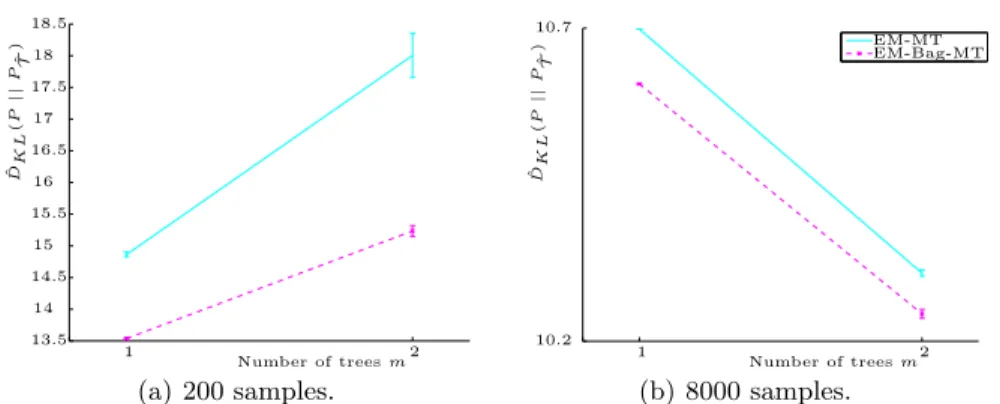
Documents relatifs
For this, we propose a Monte Carlo Markov Chain (MCMC) method that simultaneously estimates all parameters and their uncertainties, the spectral index included, as an alternative to
In the next section we will develop a Dirichlet eigenproblem point of view for general finite irreducible generators and show that it is convenient to extend the state space into
Une dernière pièce, sur fragment épais d’os de mammouth, est de morphologie très irrégulière (fig. Le support semble correspondre à un fragment de
Mordell de surfaces cubiques pour lesquelles le principe de Hasse est faux1. Mordell’s construction of cubic surfaces for which the Hasse
De plus, il est clairement rapporté dans la littérature que les androgènes présents dans le poumon retardent le développement pulmonaire et la production de surfactant par les
ب - للا ماظنلا يناثلا يوغ : ّللاب قلعتي َّتلا عوضوم ةغ ،أشنلما ةغل ىلإ ةفاضلإاب رارقتسالاو تابثلاب زيمتيو ،ملع ّللا ماظنلا نوكل ،ةيوق طباور
Notice that the emission densities do not depend on t, as introducing periodic emission distributions is not necessary to generate realalistic time series of precipitations. It
