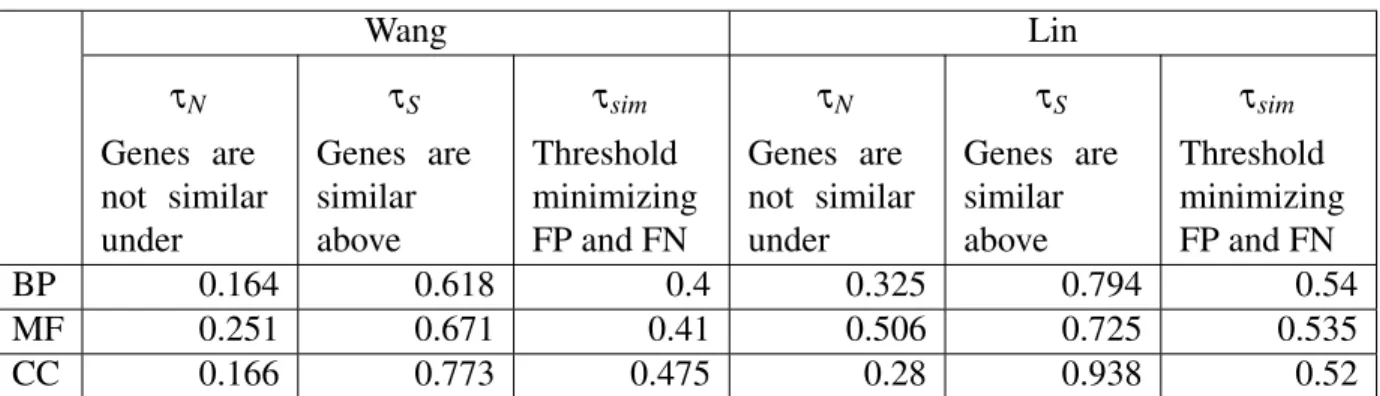
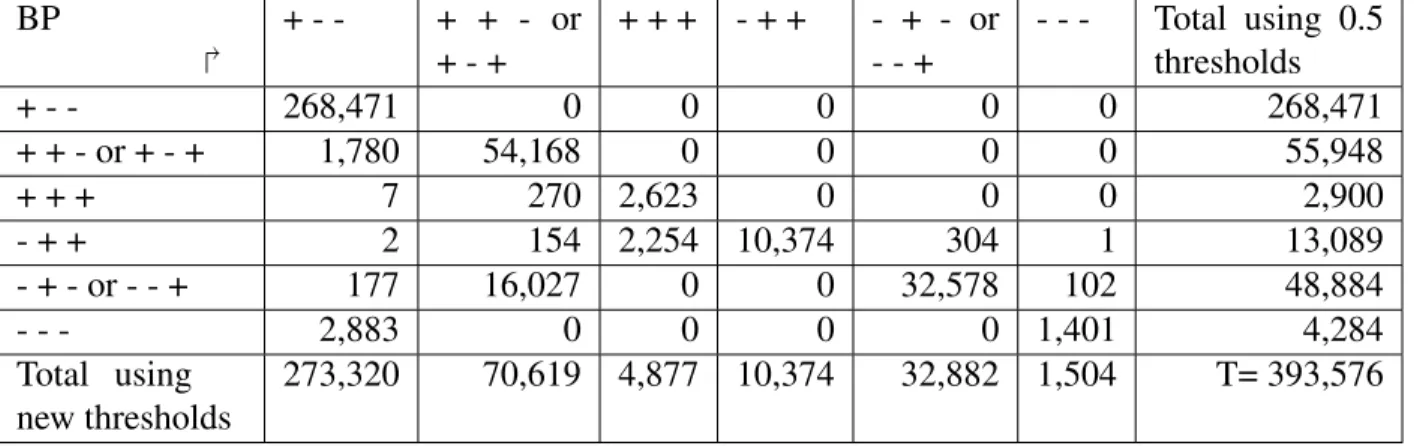
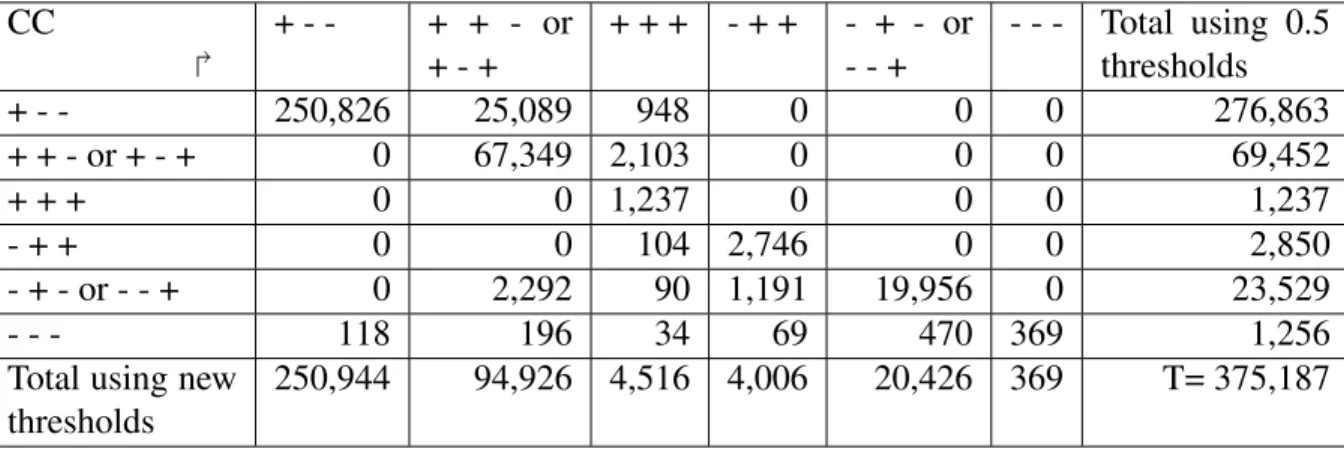
Optimal Threshold Determination for Interpreting Semantic Similarity and Particularity: Application to the Comparison of Gene Sets and Metabolic Pathways Using GO and ChEBI
Texte intégral
Figure


Documents relatifs
However, these techniques focus on utilizing few word-to-word (word-level) similarity measures, without giving due consideration to activity- level aggregation methods. The
13 Yet when the W3C asked the Linked Data community if they would want to consider HTTPS URIs to be equivalent to HTTP URIs, 14 this was not accepted due to the fact that the
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
<sentence> <intro> For the purposes of this Directive and of the regulatory acts listed in Annex IV, save as otherwise provided therein: </intro>
5) First literal based convergence: walkers step onto similar literals after the first step - this is considered significant because it is the only step where the literals
a Upset plot representing overlaps between lists of enriched GO terms, b Clustering heatmap plot combining a dendrogram based on Wang ’ s semantic similarity distance and
• Indexing IBC related data with the workflow to enhance semantic search and mining of
école –université –Mairie –hôpital –aéroport –stade de football –Préfecture –médecin –Tribunal –église –gare – boulangerie.. Observe ce vieux plan de Marseille
