Building up on SIDAN: improved and new invariants for a software hardening Frama-C plugin
Texte intégral
Figure



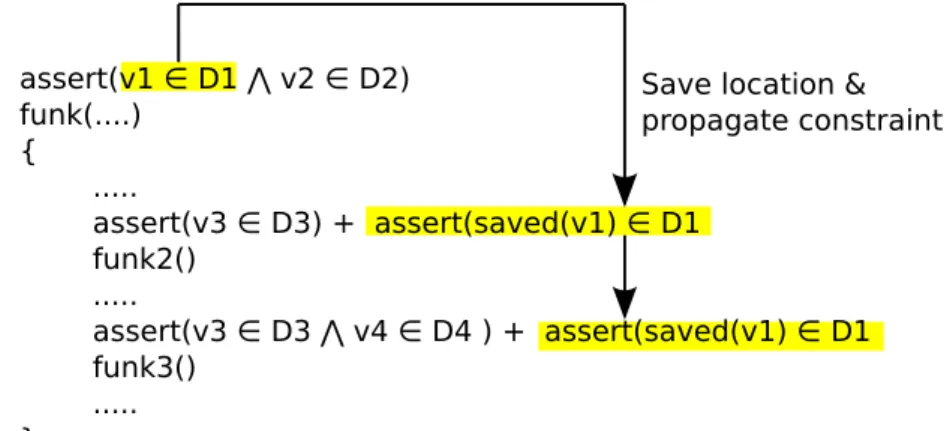
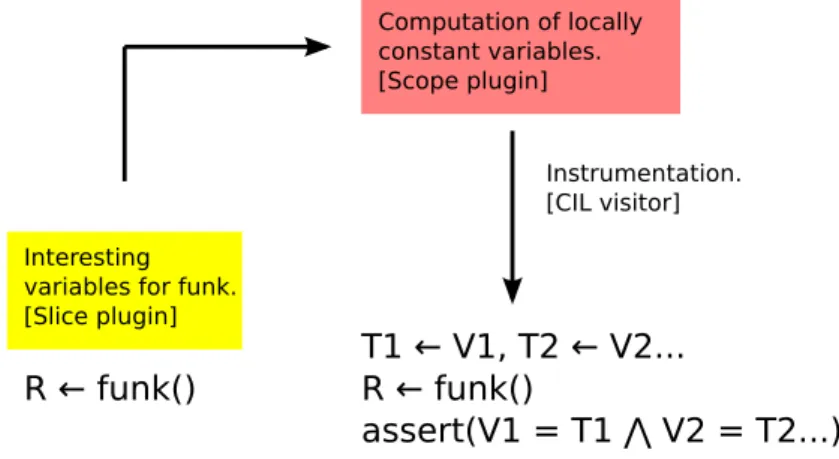
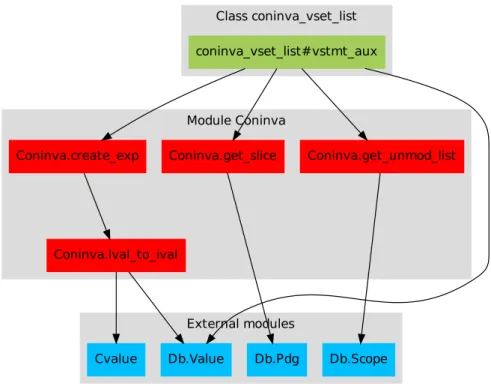
Documents relatifs
From the outset of the project, the music teachers all decided to focus their work upon using computer software to support student composition – a common usage in most
Conclusions: These findings show that future training programs will have to address the specific needs of clinical teachers who feel pressurized to accomplish different roles as well
The defining relations of canonical lifts of the Igusa invariants are given on the
sense we say that the Dirac operator exchanges positive and negative spinor fields.. This article is a first step in the project of investigating
prove it for elementary torsion AG-modules, and then we will use the fairly well developed theory of finitely generated Aj-modules (where J == Zp) to describe the
(ii) Since the genus g Gopakumar-Vafa invariants can be (very rough- ly) thought of as the “virtual number of genus g Jacobians” con- tained in the moduli space S(X, β ), any
We prove that there is a unique solution if the prescribed curve is non-characteristic, and for characteristic initial curves (asymptotic curves for pseudo- spherical surfaces and
The theory of algebraic cycles of complex algebraic varieties received a great impulse from Bloch-Srinivas contribution [11] who gave an elegant proof and various generalizations
