Spécification, validation et satisfiabilité [i.e. satisfaisabilité] de contraintes hybrides par réduction à la logique temporelle
249
0
0
Texte intégral
Figure
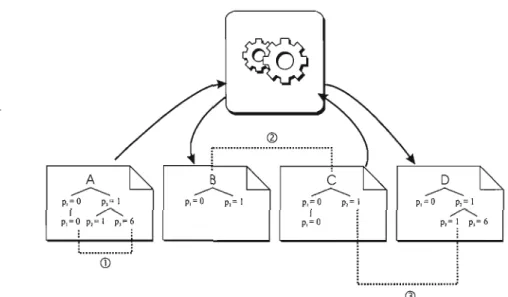

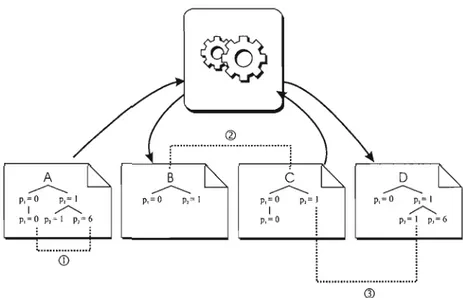
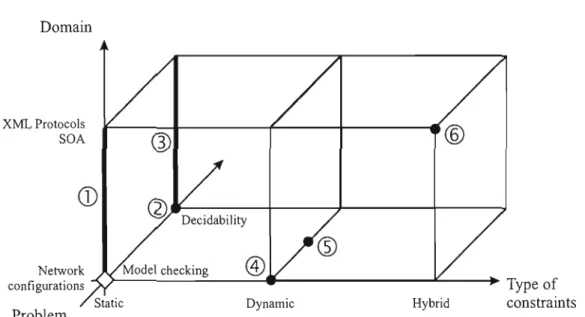
+7
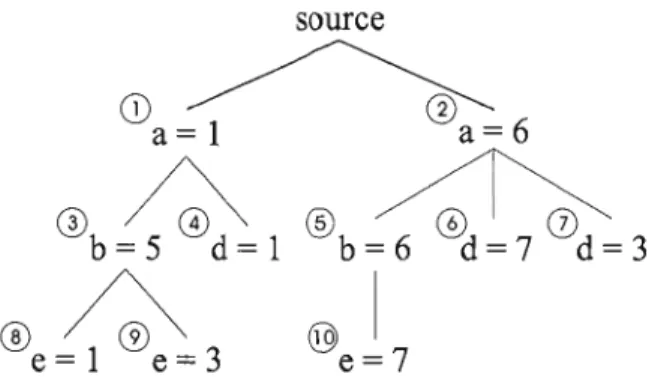
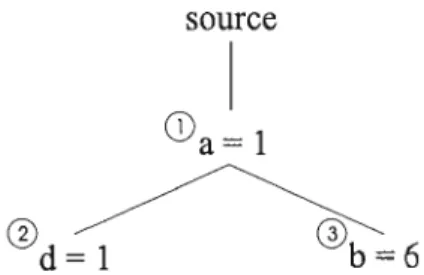

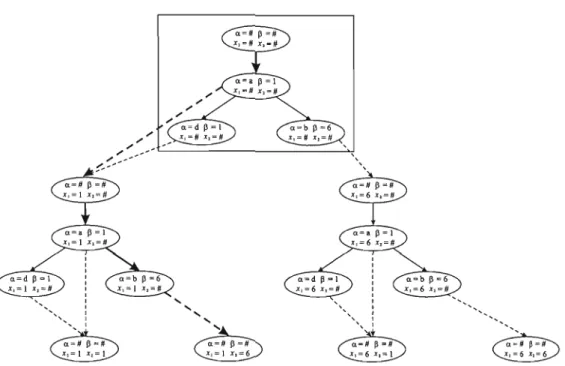
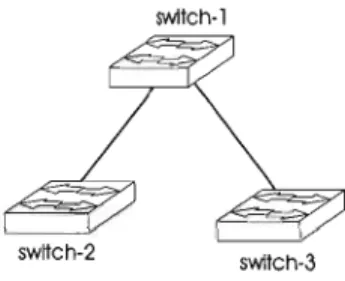
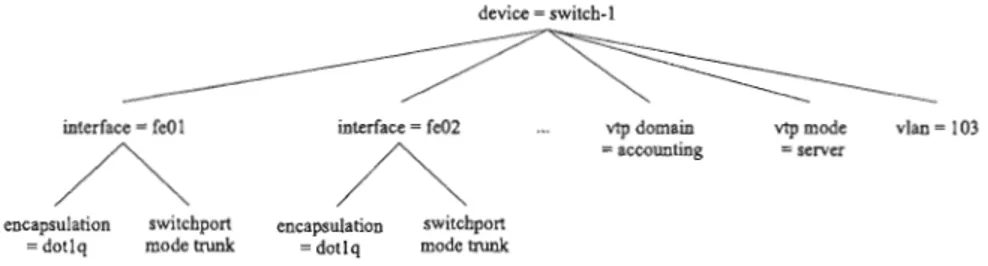
Documents relatifs
