Construction du sens dans le Data Art
Texte intégral
Figure
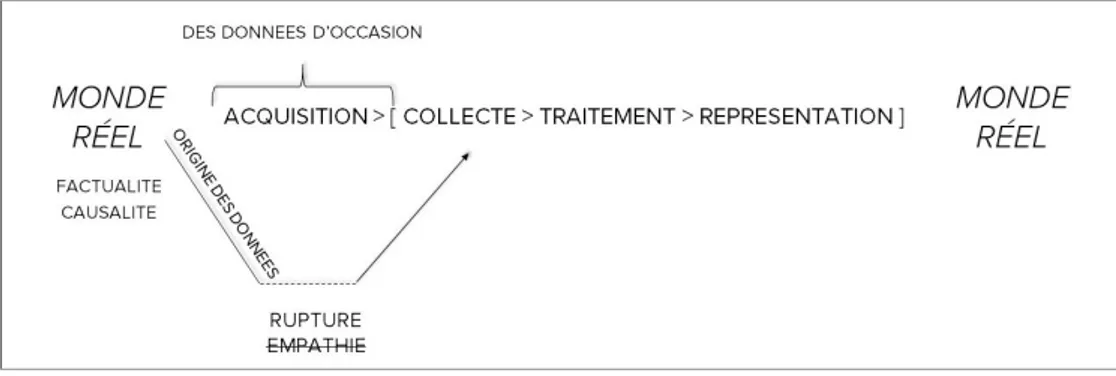
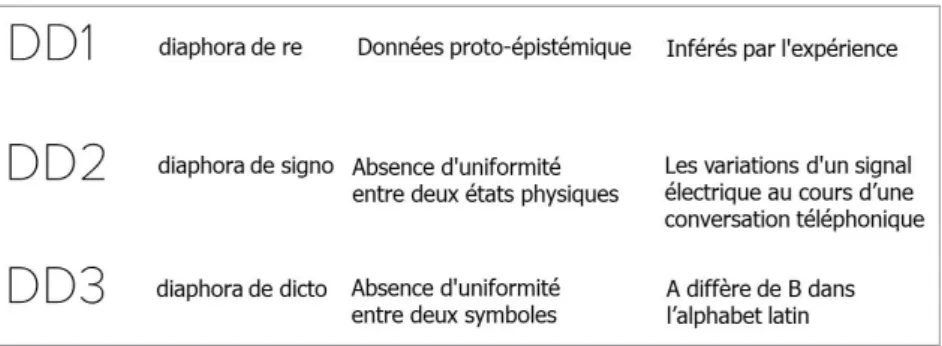

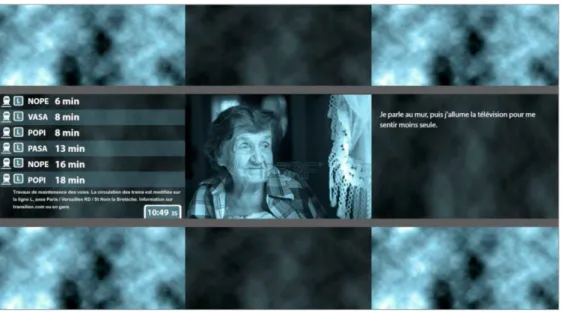
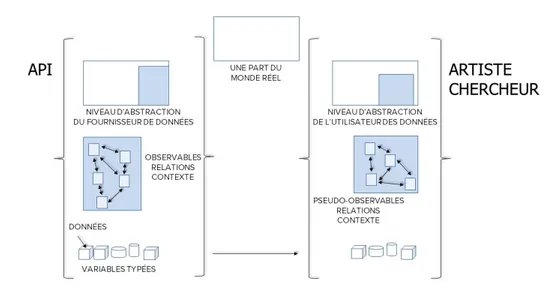
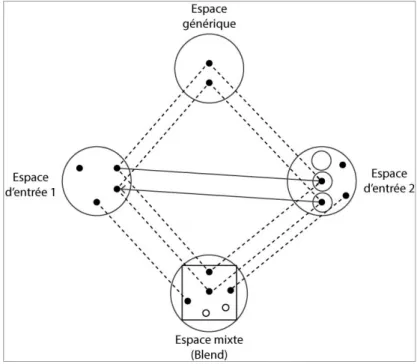
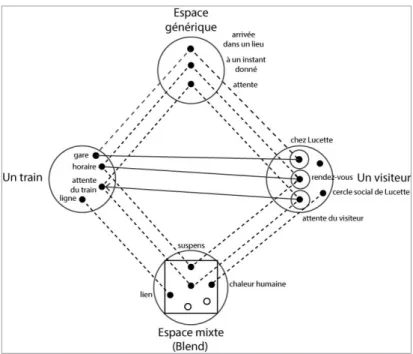
Documents relatifs
– En utilisant notre système de localisation, le scan ne peut pas être réalisé en même temps que l’acquisition des électrodes.. A la place, la méthode développée ici utilise
Nombre d'agents dans cette file d'attente de précision qui sont à l'état Non prêt, un état où les agents sont connectés mais n'effectuent aucune activité de traitement d'appel et
I nauguré en octobre 2014 1 , Pandor, puissant outil d’inter- rogation et de valorisation des ressources numériques, permet de localiser et d’accéder à un ensemble de données,
• En ce qui concerne les données issues du canal Vianavigo, les horaires de passages à l’arrêt sont fournis en temps d’attente exprimés en minutes.
Comme c’est plus facile, et que c’est pratique, nous allons créer quelques règles à la volée.. J’ai crée un watch sur le fichier /etc/passwd, qui relèvera toute tentative en
Capture intrusive des données modifiées issues de vos systèmes sources transactionnels. Requêtes SQL ou triggers de base de données gourmands en
2 il apparaît clairement que les points sont bien représentés dans un espace à trois dimensions (96,5% de l'inertie) et que ceux relatifs aux engrenages acceptables se groupent
Système de Gestion de Bases de Données SGBD Rappel sur les niveaux d’abstraction MySQL Principaux types de données disponibles Créer une BD phpMyAdmin Pour finir... Système de
