Approches Ensemblistes de Classification et Sélection des Prédicteurs pour la Reconnaissance de Formes
191
0
0
Texte intégral
Figure

+7
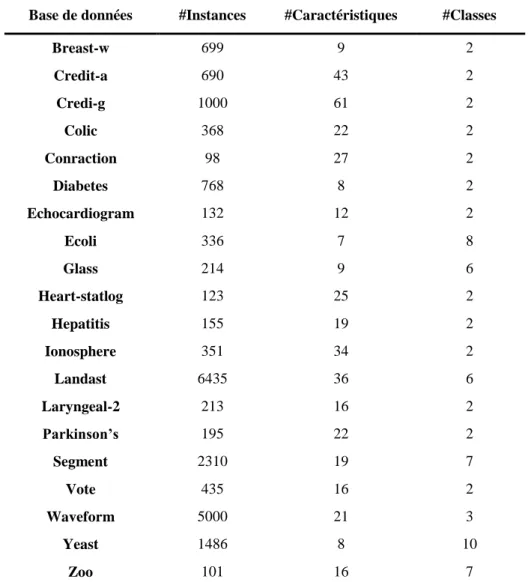
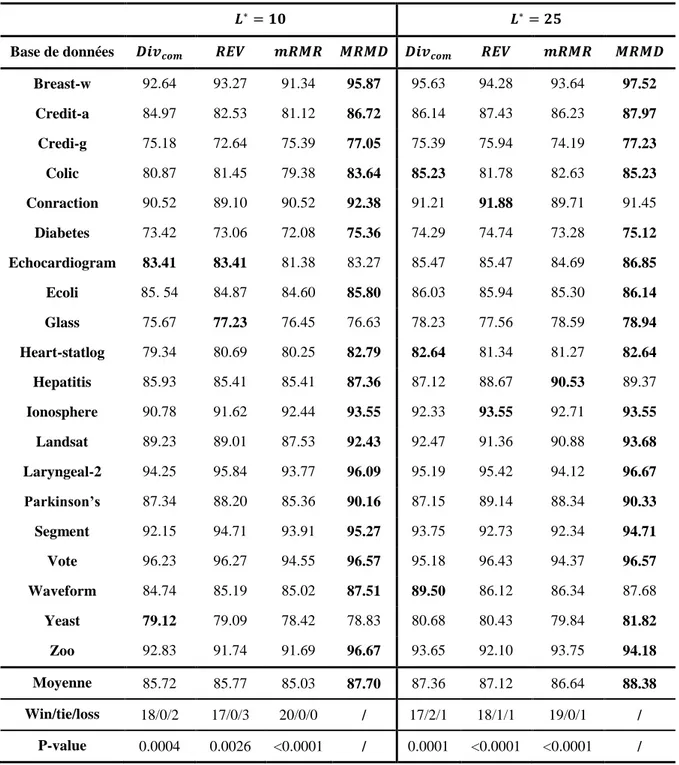
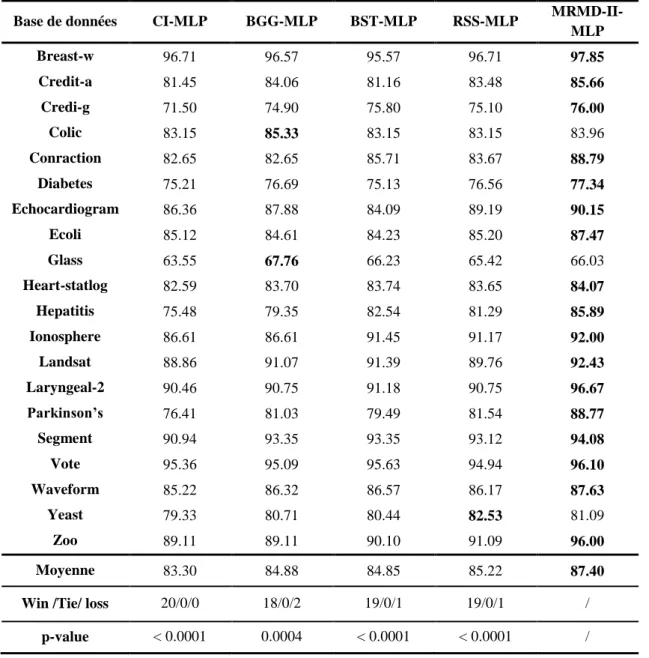
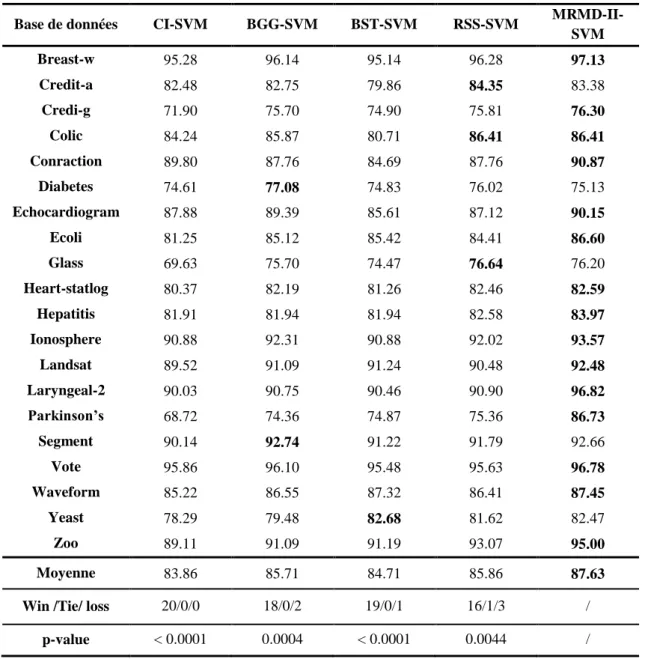
Documents relatifs