Assouplir les contraintes des architectures SIMT à faible coût
Texte intégral
Figure





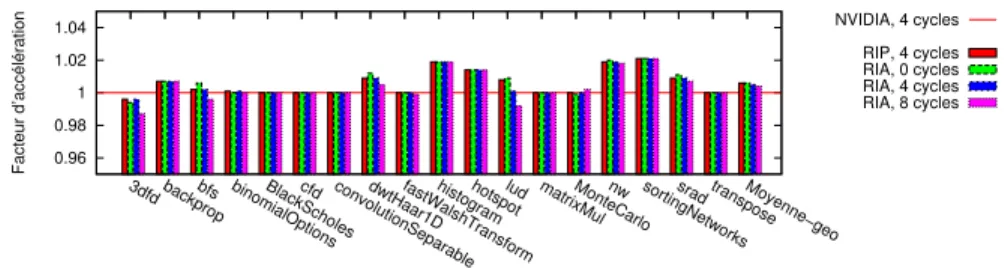
Documents relatifs
In [BBF15], we used projection complexes to embed M CG(Σ) in a finite product of hyperbolic spaces where the Masur–Minsky distance formula was a key ingredient.. We would like to
— We show that for any group G that is hyperbolic relative to subgroups that admit a proper affine isometric action on a uniformly convex Banach space, then G acts properly on
Les r´esultats de l’extraction des cin´etiques pour les deux m´ethodes utilis´ees sont pr´esent´es respectivement dans les figures 6.36 (pour la m´ethode NMF-ALS) et 6.37 (pour
pour L n,p tel que deux éléments suessifs dièrent d'une et une seule position. L ′ n,p ) est l'ensemble des mots de Fibonai (resp. Luas) ayant.. un nombre impair
d'une sortie suppl_ émentaire VTc à coefficient de température négatif. Cette sortie sera spécialement utile pour asservir la tension de commande d'afficheurs à
4.2 Use Property Precedence Graph in Creating Common Generic View Over Multiple Data Source. 4.3 Use property precedence Graph in
[r]
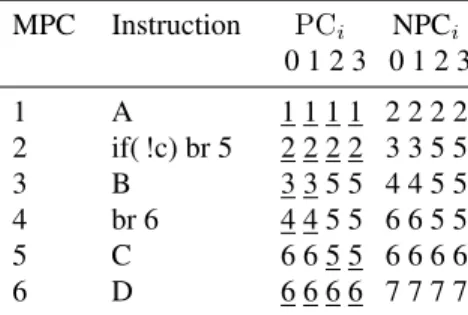
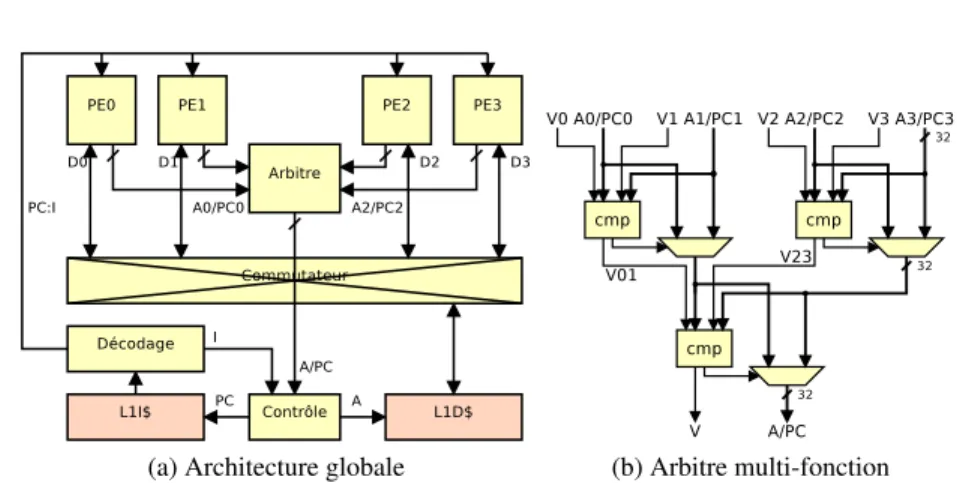
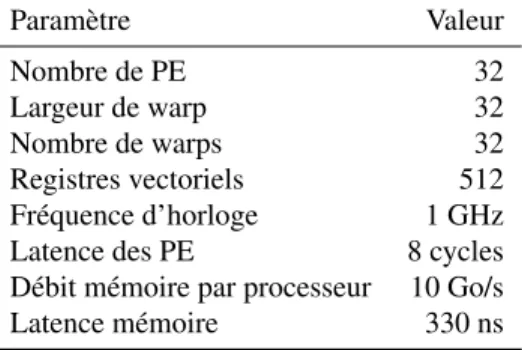
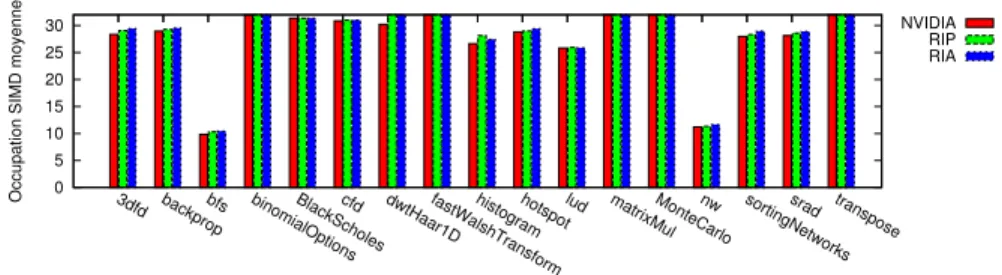
One of them is Novak’s loop scheduling [8] which consists in allowing threads to reconverge inside loops at different iterations to increase warp occupancy.. The model most
