Estimation simplifiée de la variance pour des plans complexes
Texte intégral
Figure


Documents relatifs
• pour accepter ou rejeter l’hypothèse selon laquelle p est la proportion d’un caractère dans la population ;.. • pour déterminer si un échantillon issu de la population
En classe de 1 ère , la loi binomiale a été utilisée pour mettre en place des intervalles de fluctuation au seuil de 95%, c’est-à-dire un intervalle regroupant les valeurs
Il s’av`ere ainsi qu’une m´ethode MCMC comme l’´echantillonneur de Gibbs peut n´ecessiter un tr`es grand nombre de simulations avant de cerner les vrais valeurs des param`etres
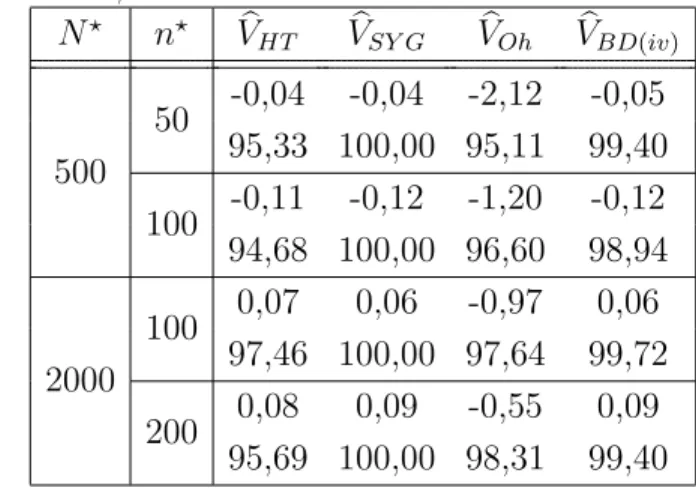
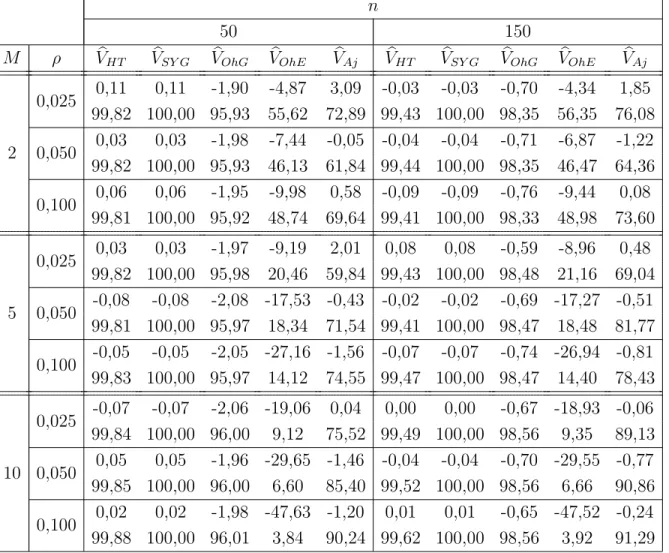
Dans cette présentation, nous considérons un estimateur de la variance simplifié qui a l’avan- tage de ne pas dépendre des probabilités d’inclusion jointes de deuxième phase et
Contexte : En avril 2002 le candidat Jean-Marie Le Pen a surpris tout le monde en battant Lionel Jospin au premier tour des élections présidentielles en France. Une semaine avant
Propriétés : probabilité dans une situation d’équiprobabilité Les n événements élémentaires d’un univers Ω liés à une expérience aléatoire sont dits équiprobables si
— échantillon non exhaustif : pour construire un échantillon de taille n, on procède par n tirages au hasard avec remise (remise de l’individu dans la population après
Lors d’un contrôle, le responsable qualité prélève de façon aléatoire un échantillon de 300 barres de pâte d’amande dans la production et constate que 280 barres sont
![[ ] [ ] [ ] Échantillonnage & Estimation T.S.](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)