Analyse des données 2 : consolidation et application à l’analyse du marché du travail et du secteur informel au Việt Nam
84
0
0
Texte intégral
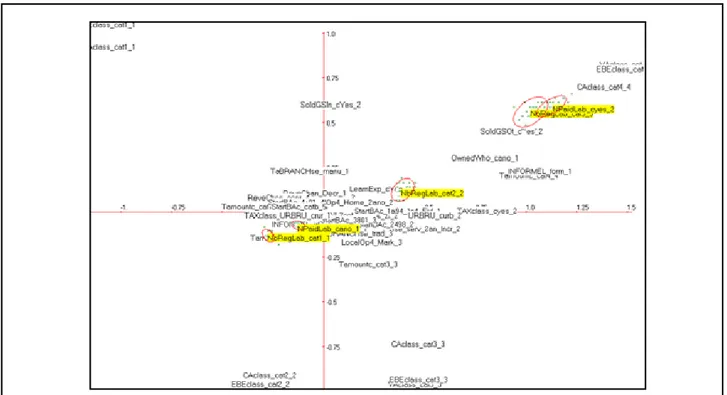
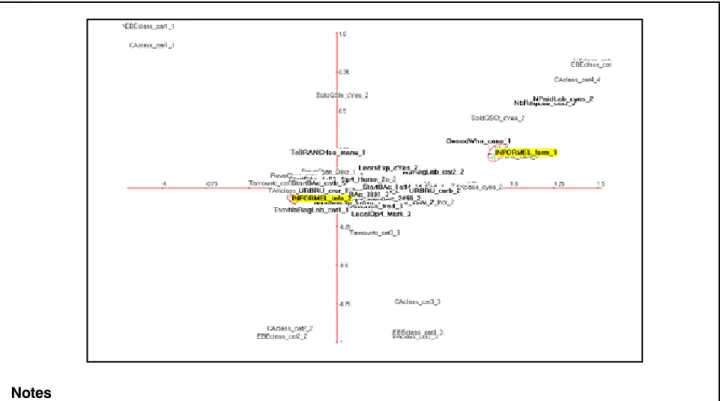
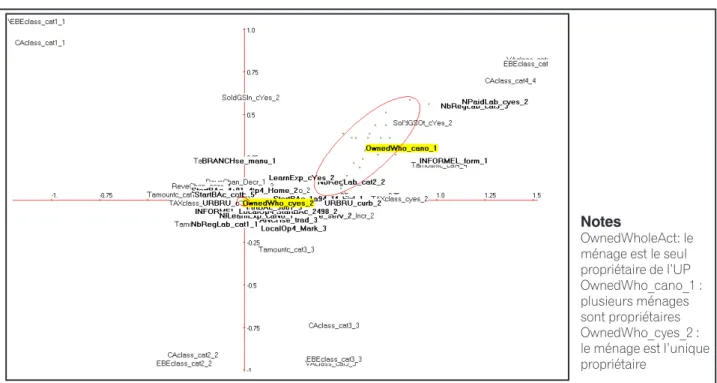
Figure



+7



Documents relatifs