L'utilisation spatio-temporelle de l'information visuelle en reconnaissance de mots / par Caroline Blais
Texte intégral
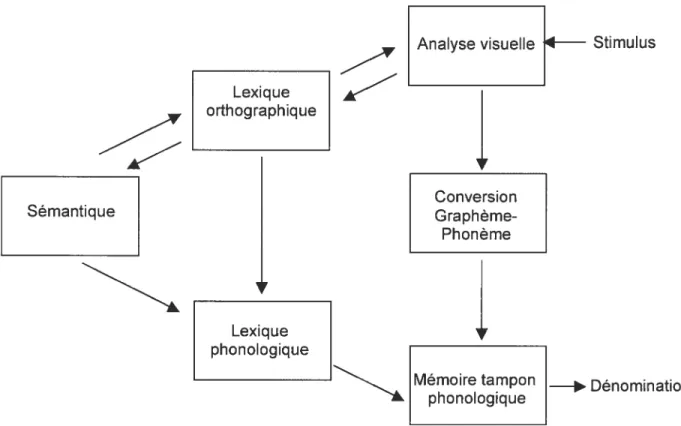
Figure





Documents relatifs
variations temporelles présentées par le signal de parole (comme cela a été établi dans les expériences de type gating), va davantage dans le sens d'un modèle non phonémique
Les limites des tests classiquement utilisés résident dans la capacité des auditeurs à restaurer des séquences de parole altérée ; Ceci est essentiellement dû
QUETZAL CARLOS PARAPLUIE TOUCAN. quetzal carlso paarpluie
quatre orange dix matin Nombre de lettres dans les mots 1. Pour vérifier tes réponses, utilise la grille de correction
Mais qui sont ces enfants dans la cour.. Le chat
Pour vérifier tes réponses, utilise la grille de correction A. Laureen
[r]
По ней можно получить ответы по вопросам здорового питания, отказа от табака, а также информацию о работе центров здоровья.. Теперь решено дополнить ее
