AVIS
Ce document a été numérisé par la Division de la gestion des documents et des archives de l’Université de Montréal.
L’auteur a autorisé l’Université de Montréal à reproduire et diffuser, en totalité ou en partie, par quelque moyen que ce soit et sur quelque support que ce soit, et exclusivement à des fins non lucratives d’enseignement et de recherche, des copies de ce mémoire ou de cette thèse.
L’auteur et les coauteurs le cas échéant conservent la propriété du droit d’auteur et des droits moraux qui protègent ce document. Ni la thèse ou le mémoire, ni des extraits substantiels de ce document, ne doivent être imprimés ou autrement reproduits sans l’autorisation de l’auteur.
Afin de se conformer à la Loi canadienne sur la protection des renseignements personnels, quelques formulaires secondaires, coordonnées ou signatures intégrées au texte ont pu être enlevés de ce document. Bien que cela ait pu affecter la pagination, il n’y a aucun contenu manquant.
NOTICE
This document was digitized by the Records Management & Archives Division of Université de Montréal.
The author of this thesis or dissertation has granted a nonexclusive license allowing Université de Montréal to reproduce and publish the document, in part or in whole, and in any format, solely for noncommercial educational and research purposes.
The author and co-authors if applicable retain copyright ownership and moral rights in this document. Neither the whole thesis or dissertation, nor substantial extracts from it, may be printed or otherwise reproduced without the author’s permission.
In compliance with the Canadian Privacy Act some supporting forms, contact information or signatures may have been removed from the document. While this may affect the document page count, it does not represent any loss of content from the document.
Simulation de centres de contacts
par Eric Buist
Département d'informatique et de recherche opérationnelle Faculté des arts et des sciences
Thèse présentée à la Faculté des études supérieures en vue de l'obtention du grade de Philosophi~ Doctor (Ph.D.)
en informatique
Janvier, 2009
.. -.-~ .... '-'" ~··t·~~Jr:·~ ~ ... , . , _ ' . 1 . " ~ ,1 . ' : ;~ ',.\ . " . ~ .
,
." ," ' 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1Faculté des études supérieures
Cette thèse intitulée:
Simulation de centres de contacts
présentée par:
Eric Buist
a été évaluée par un jury composé des personnes suivantes: Fabian Bastin, Pierre L'Écuyer, Patrice Marcotte, Benoît Montreuil, Christopher R. Bryant, président-rapporteur directeur de recherche membre du jury examinateur externe
représentant du doyen de la FES
Un centre de contacts est un ensemble de ressources formant une interface entre un
organisme et ses usagers. Plusieurs entreprises disposent d'un tel centre pour offrir des services à leurs clients tandis que des organismes gouvernementaux en possèdent pour les services de renseignements, d'urgence, etc. Les centres de contacts revêtent ainsi une grande importance économique, d'où le besoin de les analyser et d'en optimiser le rendement. Cette analyse consiste à construire un modèle du centre de contacts et à l'utiliser pour évaluer la performance du centre pour plusieurs configurations.
Avec l'accroissement de la complexité de ces centres, la simulation devient progres-sivement le seul outil capable de prendre tous les éléments en compte. Mais les outils disponibles pour la simulation ne sont pas suffisamment performants pour effectuer des analyses et de l'optimisation efficacement. Pour simuler des centres de contacts plus fa-cilement, nous avons alors, dans le cadre de notre projet de maîtrise, développé la biblio-thèque ContactCenters qui permet de construire des simulateurs de centres de contacts
dans le langage de programmation Java. En utilisant cette bibliothèque, nous avons éga-lement construit divers exemples de simulateurs dont un logiciel permettant de simuler, sans programmation Java, la plupart des centres d'appels que nous avons eu à traiter. ContactCenters est déjà plus rapide que tous les outils de simulation commerciaux équi-valents que nous connaissons, mais le logiciel n'est pas encore suffisamment performant pour effectuer de l'optimisation efficacement et son utilisation pose des difficultés aux gestionnaires.
Dans cette thèse, nous proposons des améliorations aux outils existants pour simuler les centres de contacts. En premier lieu, nous explorons des techniques pour augmen-ter l'efficacité en réduisant la variance ou le travail de simulation. Dans le premier cas, pour un temps de calcul identique ou légèrement supérieur, nous obtenons une variance beaucoup plus petite. Dans le second cas, nous obtenons une variance identique ou lé-gèrement plus grande pour un temps de calcul significativement plus petit. Pour cela,
nous étudions des techniques telles que la stratification, les variables de contrôle et les variables aléatoires communes. Nous examinons aussi la possibilité d'utiliser un modèle simplifié de chaîne de Markov en temps continu avec l'uniformisation et la conversion en temps discret. De plus, nous adaptons une technique de scission et de recombinaison à ce modèle pour réutiliser du travail de sirriulation. En second lieu, nous améliorons l'architecture de notre logiciel de simulation pour le rendre plus flexible, extensible et facile à utiliser.
Mots clés: Centres d'appels, réduction de la variance, stratification, variable de contrôle, variables aléatoires communes, chaîne de Markov, uniformisation, scission et recombi-naIson.
A contact center is a set of resources for communication between an organization and its users. Many companies have such a center to provide services to their customers white govemment uses them for information, emergency services, etc. Contact centers clearly have a great economical importance whichjustifies the need to analyze them, and optimize their performance. This anaJysisis performed by building a model of a contact center, and by using the model to evaluate the performance of the center for multiple configurations.
With the increase in complexity of contact centers, simulation is progressively ,be-, coming the only tool capable of taking every de,tail into account. But currently available simulation tools are not fast enough to perform analysis and optimization efficiently. We have thus developed the ContactCenters library during our master's thesis to ease the simulation of contact centers. This library can be used to construct simulators of contact centers in the Java programming language . .using ContactCenters, we have de-veloped sorne example programs, including a generic tool for simulating most common cali centers without programming in Java. ContactCenters is faster than aIl equivalent commercial tools we know of, but it is still not efficient enough for optimization, and its use is often hard for managers.
In this thesis, we propose improvements to existing tools for simulating contact cen-ters. Firstly, we explore techniques for improving efficiency by reducing the variance, or the simulation work. In the first case, for an equal or slightly larger computing time, we obtain an estimator with a significantly smaller variance. In the second case, for an equal or slightly larger variance, we obtain an estimate after a smaller computing time. For this, we explore techniques such as stratification, control variates, and common ran-dom numbers. We also consider the possibility of using a simplified continuous-time Markov chain model with uniformization and discrete-time conversion. Moreover, we adapt a split and merge technique to this model in order to reuse simulation work.
Sec-ondly, we imptove the design of our simulation tool to make it more flexible, extensible, and user-friendly.
Keywords: Call centers, variance reduction, stratification, control variate, common random numbers, Markov chain, unifonniz~tion, split and merge.
RÉSUMÉ v
ABSTRACT. . . vii
TABLE DES MATIÈRES . . . ix
LISTE DES TABLEAUX. . . .. xv
LISTE DES FIGURES
LISTE DES SIGLES
NOTATION . . .
REMERCIEMENTS
CHAPITRE 1: INTRODUCTION
1.1 Problèmes posés par les centres de contacts 1.2 Outils d'analyse . . . 1.2.1 Modélisation 1.2.2 Formules analytiques . . . 1.2.3 Simulation . . . 1.3 Éléments de ContactCenters 1.4 Plan de la thèse . . . . xix . xxiii . xxv . xxix 1 1 3 3 5 7 9 Il
CHAPITRE 2 : CONCEPTS ET NOTATION MATHÉMATIQUE DE BASE 15
2.1 Les centres de contacts . . . . 2.2 Mesures de performance considérées . 2.3 Ordre asymptotique . . . .
15 19
CHAPITRE 3 : COMBINAISON DE LA STRATIFICATION ET DES VA-RIABLES DE CONTRÔLE . . . . . 27 3.1 Variance sur une fonction de plusieurs moyennes
3.2 Variables de contrôle linéaires 3.3 Stratification...
3.4 Combinaison de la stratification et d'une variable de contrôle 3.4.1
3.4.2 3.4.3 3.4.4 3.4.5
Coefficient global pour toutes les strates Coefficient local pour chaque strate . .
Coefficient dépendant de la variable de stratification continue Comparaison des trois meilleures techniques
Implantation de la combinaison 3.5 Applications aux centres de contacts
28 30 32 36 38 40 41 44 46 48 3.5.1 Modèle considéré. . . 48
3.5.2 Test de variables de contrôle 50
3.5.3 Comparaison avec l'estimation indirecte. 53
3.5.4 Mesures de dispersion des arrivées comme variable de contrôle 54 3.5.5 Application de la combinaison avec la stratification . . . . . 58
CHAPITRE 4 : VARIABLES ALÉATOIRES COMMUNES . . . . . 71 4.1 Technique de base. . . '.
4.2 Estimation d'une dérivée
4.3 Application aux centres de contacts
4.4 Preuves de convergence pour un modèle de centre de contacts 4.4.1 Lemmes de base . . . .
4.4.2 Différence du nombre de contacts avec un temps d'attente
infé-ri~ur à
Sa . . . .
4.4.3 Différence du nombre d'abandons 4.4.4 Différence du temps d'attente moyen
72 73 74 80 82 84 88 90
CHAPITRE 5 : AUGMENTATION DE LA VITESSE DE SIMULATION À
U AIDE D'UNE CHAÎNE DE MARKOV EN TEMPS CONTINU
ET DE UUNIFORMISATION . . . .. 93 5.1 Simulation de chaînes de Markov en temps continu en général 96
5.1.1 Chaîne de Markov en temps continu sur horizon fini 5.1.2 Fonctions de coûts
5.1.3 Uniformisation ..
5.1.4 Conversion en temps discret pour la simulation 5.1.5 Calcul de lE[C 1 9N(T)l 5.1.6 Génération de
9
N(T) 96 98 99 100 102 1035.1.7 Variance dans un modèle simple 105
5.1.8 Variation des paramètres dans le temps 112
5.2 Application aux centres de contacts 114
5.2.1 Construction de la CMTC 116
5.2.2 Simulation avec la recherche indexée 119
5.2.3 Réduction des transitions fictives. . . 127
5.2.4 Problèmes posés par la variation des paramètres dans le temps 131 5.3 Calcul des statistiques avec le modèle de chaîne de Markov. 135
5.3.1 Estimation du niveau de service . . . 135
5.3.2 Estimation du temps d'attente moyen 139
5.3.3 Estimation du temps d'excès moyen . 139
5.3.4 Estimation d'autres mesures de performance 142
5.3.5 Mesures de performance pour les contacts arrivés et servis
pen-dant des périodes différentes 143
5.4 Expérimentations numériques 5.4.1 Exemples testés . . . .
147 147 5.4.2 Comparaison de CSIM,!, CSIM,2 et de la simulation par
5.4.3 5.4.4 5.4.5
Comparaison des temps d'exécution . . . . Impact de la taille et de la complexité du modèle Test avec un taux de transition adaptatif . . . . .
5.5 Étude de la synchronisation des variables aléatoires communes pour le 151 154 155
simulateur simplifié . . . 157
5.5.1 Exemple numérique 158
5.5.2 Impact du changement du nombre de transitions sur la
synchro-nisation . . . . . 160 5.5.3 Impact sur la synchronisation du changement de la borne sur le
. nombre d'agents . . . 162
5.5.4 Restauration de la synchronisation. 168
5.5.5 Impact sur la synchronisation d'un taux de transition adaptatif 169
CHAPITRE 6 : SCISSION ET RECOMBINAISON POUR L'ÉVALUATION
DE LA PERFORMANCE EN FONCTION DE PARAMÈ-TRES DU MODÈLE. . . 175 6.1 Méthode générale de· scission et de recombinaison.
6.1.1 Hypothèses sur le modèle . . . 6.1.2 Simulation de trajectoires multiples 6.1.3 Algorithme de scission . . . .
6.1.4 Prise en charge de la recombinaison de copies . 6.2 Application à un centre de contacts . . . .
177 178 179 180 183 184
6.2.1 Variation d'un seul paramètre continu 185
6.2.2 Variation d'un seul paramètre agissant sur le nombre d'agents 187 6.2.3 Problèmes posés par les recombinaisons . . . .. 189 6.2.4 Variation de plusieurs paramètres agissant sur le nombre d'agents 190 6.2.5 Estimation de sous-gradients .
6.2.6 Gestion de périodes multiples
195 197
6.3 Exemples numériques . . . . 6.3.1 Test avec un type de contact et un groupe d'agents
Simulation avec plusieurs groupes d'agents . . . .
202 202 207 6.3.2
6.3.3 Impact d'un taux de transition adaptatif sur les recombinaisons. 210
CHAPITRE 7 : AMÉLIORATION DU LOGICIEL DE SIMULATION . . 213
7.1 Vue d'ensemble de l'architecture de ContactCenters . . . 215 7.2 Grandes lignes de l'architecture du simulateur générique 216 7.3 Fonctionnalités principales du simulateur générique . . . 220 7.4 Impact de la représentation des groupes d'agents avec des compteurs. 224
7.5 Prédiction des temps d'attente 228
7.5.1 Estimateurs comparés 229
7.5.2 Comparaison des estimateurs sur un modèle simple. 230 7.5.3 Comparaison des estimateurs sur un modèle avec plusieurs types
de contacts . . . 233
7.6 Extensibilité du simulateur générique 7.6.1 Réflexion . . . . 7.6.2 Fournisseurs de services
7.6.3 Autres mécanismes envisageables 7.7 Simplification de l'entrée des données .. 7.8 Amélioration de la clarté des messages d'erreur
CONCLUSION . . BIBLIOGRAPHIE 235 237 238 240 240 242 247 253
3.1 Possibilités pour bs,j(Cs,j - es,j) . . . .. 38 3.11 Facteur retranché à la variance par les différents modes de
combi-naison de la stratification et des variables de contrôle . . . .. 46 3.111 Paramètres de l'exemple avec un type de contact et un groupe
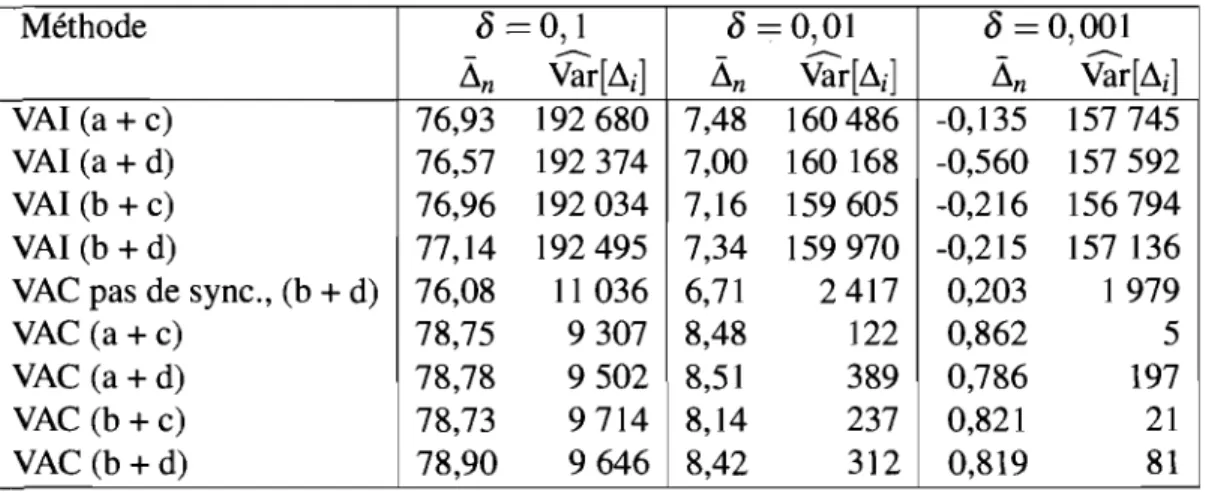
d'agents. . . .. 49 3.1V Résultats de l'application de variables de contrôle sur l'exemple
de centre de contacts avec B aléatoire . . . .. 52 3.V "Résultats de l'application de variables de contrôle sur l'exemple
de centre de contacts avec B = 1 . . . 53 3.VI Variance avec les mesures de dispersion des arrivées, pour B = 1 57 3.VII Variance avec les mesures de dispersion des arrivées, pour B '"'-'gamma 57 3.VIII Termes de la décomposition de la variance de
G(so)
pourdiffé-rentes méthodes d'estimation et diffédiffé-rentes valeurs de m . . . .. 67
3.IX Termes des décompositions (3.22) et (3.23) pour chaque strate dans le cas der
G(so)
avecm
= 20 strates . . . .. 693.x Termes de la décomposition de la variance de L pour différentes méthodes d'estimation et différentes valeurs de m . . . .. 70
4.1 Impact d'un changement du temps de service moyen sur le nombre
G(so)
de contacts ayant attendu moins desa,
avec variables aléa-toires communes et n = 10 000. . . .. 774.11 Impact d'un changement du temps de service moyen sur le nombre
G(so)
de contacts ayant attendu moins desa,
avec variables4.111 Impact d'un changement du temps de service moyen sur le nombre moyen d'abandons, avec variables aléatoires communes pour n =
10000. . . .. 79 4.IV Impact d'un changement du temps de service moyen sur le temps
d'attente moyen, avec variables aléatoires communes et n = 10 000 79 4.V Impact d'un changement du temps de service moyen sur le nombre
G(so) de contacts ayant attendu moins de sa, avec variables aléa-toires communes, n = 10 000, 100 strates et variable de contrôle 81
5.1 Types d'événements possibles et effet habituel sur l'état . . . 118 5.11 Sous-intervalles de [0,1) associés à des événements dans le cas où
K =/ = 1 . . . 120 5.111 Impact de H.l sur le taux d'occupation et le taux d'abandon, pour
un modèle simple . . . .. 134 5.IV Comparaison de JED[Wn ~ s 1 Dn] calculée avec la méthode Erlang et
de JED[Wn ~
si
Dn,N(T)] calculée avec la méthode binomiale . . . 138 5.V Comparaison des différentes méthodes pour estimer lE[Wn 1 Wn>
s,9
N(T)] . . . • . . . . . 1425.VI Comparaison des approximations pour JED[WI
+
Wl ~ s 1 dl, dl, nI, nl]1465.VII Paramètres du routage pour l'exemple 5 . . . . . 149 5.VIII Estimés des mesures de performance principales pour les exemples
testés, avec 1 000 réplications indépendantes . . . 150 5.IX Comparaison de la variance obtenue avec les différentes méthodes
de simulation . . . 150 5.x Temps d'exécution pour les différents exemples testés 153 5.x1 Temps d'exécution en fonction du taux d'arrivée . . . 156 5.x1l Temps d'exécution en fonction du nombre de types de contacts. 156
5.XIII Temps d'exécution (en secondes) en fonction de la capacité de la file d'attente et du nombre de sous-ensembles de S . . . . . 157 5.xIV Impact d'un changement du nombre d'agents sur le nombre moyen
de contacts ayant attendu moins de vingt secondes . . . 160 5.XV Impact d'un changement du nombre d'agents sur le nombre moyen
d'abandons . . . .. 161 5.xVI Désynchronisations possibles si q passe à ij quand N1 passe à N1 163
5.XVII Probabilité des différents événements pour l'exemple 1 a avec 25 000 contacts en moyenne pendant un horizon T = 46 800 . . . . . 165
6.1 Performance de la méthode de scission et de recombinaison pour un exemple avec un type de contact et un groupe d'agents . . . . 204 6.11 Variation du nombre moyen d'arrivées dans le temps pour l'exemple
la . . . '. . . 206 6.111 Performance de la méthode de scission et de recombinaison pour
un exemple avec un type de contact, un groupe d'agents et un taux d'arrivée variant dans le temps . . . 207 6.1V Nombre moyen d'arrivées, pendant l'intervalle [0,
Tl,
pour les exemples4 et 5 . . . 207 6.V Performance de la méthode de scission et de recombinaison lors
d'une estimation de sous-gradient
. . .
209 6.VI Effet du partitionnement de S sur les recombinaisons 2107.1 Paramètres du centre de contacts utilisé pour examiner l'impact de
l'implantation des groupes d'agents
...
2267.11 Comparaison des deux modèles de groupes d'agents 227
7.111 Comparaison des estimateurs de temps d'attente sur l'exemple de la section 3.5.1, sans abandon
. . .
2327.IV Comparaison des estimateurs de temps d'attente sur l'exemple de la section 3.5.1, avec abandons . . . 233 7. V Paramètres pour l'exemple avec trois types de contacts et trois
groups d'agents. . . .. 234 7.VI Comparaison des estimateurs de temps d'attente sur un exemple
1.1 Modèle de file d'attente représentant un centre de contacts usuel 5
2.1 Vue schématique des différentes quantités reliées à un groupe d'agents 17 2.2 Partitionnement de 1 'horizon du modèle en périodes. . . .
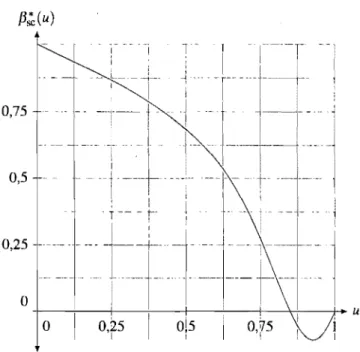
3.1 Fonction f3s~(u) pour le nombre d'appels attendant moins de so,
approximée par des splines cubiques lissées sur 1 000 points
...
3.2 Fonction (J'2(u) pour le nombre d'appels attendant moins de so,approximée par des splines cubiques lissées sur 1 000 points
...
3.3 Fonction J.1(u) pour le nombre d'appels attendant moins de so,ap-proximée par des splines cubiques lissées sur 1 000 points
....
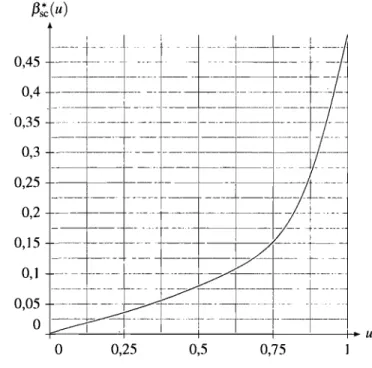
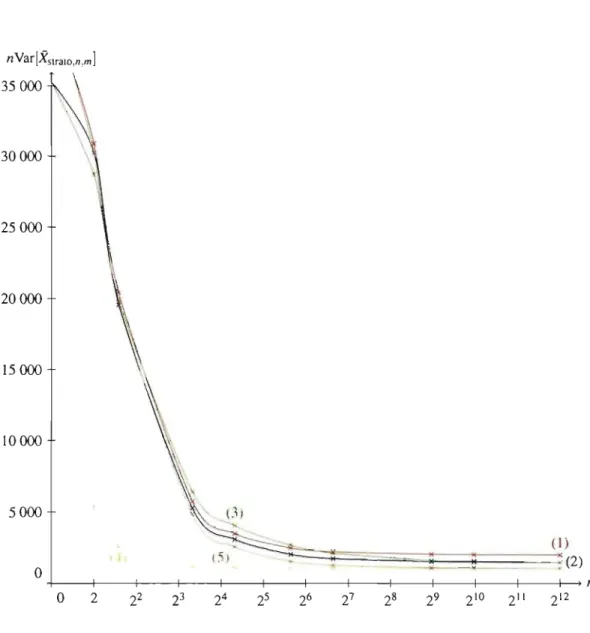
3.4 Fonction f3s~(u) pour le nombre d'abandons, approximée par dessplines cubiques lissées sur 1 000 points . . . . 3.5 Variance de G(so) en fonction du nombre de strates avec allocation
proportionnelle . . . .
5.1 5.2
Variance des estimateurs CS1M 1 , et CSIM 2 ' , en fonction de p
Comparaison de ÀT avec E;;'=1lP'2[N(T)
2:
n] . . . .
19 61 61 63 63
68
109 1105.3 Exemple de partition de l'intervalle [0,1) dans un cas où K
=
1=
1 122 5.4 Exemple d'index de recherche pour un modèle à deux types decontacts et deux groupes d'agents . . . .. 124 5.5 Exemple de partition de l'intervalle [Wb WH!) associé à une
arri-vée de type k . . . .. 125 5.6 Exemple de partition de l'intervalle [Vi, Vi+l) associé à une fin de
service d'un agent du groupe i . . . .. 127 5.7 Exemple de partitionnement de S en deux dimensions, avec trois
5.8 Répartition des types d'événements pour deux taux de transition maximaux différents . . . . . 163 5.9 Progression du nombre Zn de contacts dans le système en fonction
du numéro n de transition, pour trois taux de transition différents. ] 67 5.10 Progression du nombre
Z(t)
de contacts dans le système enfonc-tion du temps discret normalisé t =
Tn/N(T),
pour trois taux de transition différents . . . . . 167 5.11 Nombre Zn de contacts dans le système en fonction du numéron de transition, pour différents nombre d'agents NI, avec borne supérièure
NI
= 100 et R = 2 sous-ensembles de S . . . . . 171 5.12 Nombre Zn de contacts dans le système en fonction du numéron de transition, pour différents nombre d'agents NI, avec borne supérieure
NI
=
100 et R=
3 sous-ensembles de S . . . .. 1736.1 Exemple de simulation avec des trajectoires parallèles 181 6.2 Diagramme illustrant un exemple du processus de scission 183 6.3 Exemple d'application de la scission lors de l'arrivée d'un contact 193 6.4 Exemple d'arbre de scission dans un cas bidimensionnel . . . . . 194 6.5 Exemple d'arbre de scission, dans le cas où seul un sous-gradient
est estimé . . . .. 198
7.1 Diagramme UML décrivant les relations existant entre les contacts, les processus d'arrivées et les composeurs d'appels sortants . . . 216 7.2 Diagramme UML décrivant l'architecture du routeur de
Contact-7.3 7.4
Centers . . . . Utilisation du simulateur générique
Diagramme UML décrivant la structure du simulateur générique 7.5 Exemple de message affiché par d'anciennes versions du
simula-teur générique lorsqu'un élément inconnu était rencontré
217 217 219
7.6 Exemple de message affiché par la version actuelle du simulateur générique lorsqu'un élément inconnu est rencontré . . . 244 7.7 Exemple de message d'erreur affiché par d'anciennes versions du
simulateur lorsqu'un paramètre négatif imprévu était trouvé .. . 244 7.8 Exemple de message d'erreur affiché par la version actuelle du
CMTC Chaîne de Markov en temps continu, voir section 5.1
CMTD Chaîne de Markov en temps discret, voir section 5.1
FTE Full lime equivalent ou équivalent à temps plein, quotient du temps total de bran-chement des agents et de la durée moyenne d'un quart de travail
i.i.d. Indépendant et identiquement distribué, caractérise un ensemble de variables aléa-toires conjointement indépendantes dont la loi de probabilité de chaque élément est la même.
RPC Right party connect, communication sortante réussie, c'est-à-dire que le contact a été établi et la bonne personne a été rejointe
SSJ Stochastic Simulation in Java, bibliothèque utilisée par ContactCenters pour effec-tuer la simulation
VAC Variables aléatoires communes, voir section 4.1 VAl Variables aléatoires indépendantes, voir section 4.1 VC Variable de contrôle, voir section 3.2
XML eXtensible Markup Language, méta-langage permettant de représenter des don-nées complexes et hiérarchiques sous la forme d'un fichier textuel
j
xxiv
"
La plupart des symboles récapitulés ici sont définis dans le chapitre 2 de ce docu-ment.
A(t1,t2) Nombre d'arrivées pendant l'intervalle [t1,t2]
g1(S,t1,t2),g2(S,t1,t2) Niveau de service, c'est-à-dire fraction des contacts qui ont
at-tendu moins de s secondes pendant l'intervalle [t1,t2].
i Indice d'un groupe d'agents
1 Nombre de groupes d'agents
k Indice d'un type de contact
K Nombre de types de contacts
L(t1,t2) Nombre de contacts arrivés pendant l'intervalle [t1 ,t2] et ayant abandonné par
la suite
LB(S,t1,t2) Nombre de contacts arrivés pendant l'intervalle [t1,t2] et ayant abandonné
par la suite après uri temps d'attente supérieur à s
4J(S,t1,t2) Nombre de contacts arrivés pendant l'intervalle [t1,t2] et ayant abandonné
par la suite après un temps d'attente inférieur ou égal à s
.e(t1,t2) Proportion des contacts arrivés pendant l'intervalle [t1,t2] et ayant abandonné
par la suite
n Taille d'un échantillon de nombres aléatoires
Ni(t) Nombre total d'agents dans un groupe i au temps t NB,i(t) Nombre d'agents occupés dans un groupe i au temps t
NF,i(t) Nombre d'agents libres pour servir un contact dans un groupe i au temps t
NG,i(t) Nombre d'agents fantômes du groupe i, c'est-à-dire nombre d'agents devant
NI,i(t) Nombre d'agents inoccupés dans un groupe i, pouvant ou non servir des contacts au temps t
0(tl,t2) Taux d'occupation des agents du groupe i pendant l'intervalle de temps [tl, t21
P Indice d'une période, entre 0 et P
+
1P Nombre de périodes principales
qi,j Taux de transition de l'état i vers l'état j pour une CMTC
q Taux de transition utilisé pour une CMTC uniformisée
Qk Nombre de contacts de type k en attente
Q(t) Taille de la file d'attente au temps t
S Ensemble dénombrable représentant un espace d'états
Sk,i Nombre de contacts de type k en service auprès d'agents du groupe i
S(tl,t2) Nombre de contacts arrivés pendant l'intervalle [tl ,t21 et servis à un temps t ;::: tl
SB(S,tl,t2) Nombre de contacts arrivés pendant l'intervalle [tl,t21 et servis à un temps
t ;::: tl après un temps d'attente supérieur à s
Sa(S,tl,t2) Nombre de contacts arrivés pendant l'intervalle [tl,t21 et servis à un temps
t ;::: tl après un temps d'attente inférieur ou égal à s
t Utilisé pour représenter un temps
tp Temps de fin de la période p
T Temps de départ du dernier contact
e
Représente un paramètre d'un modèleU Variable aléatoire suivant la loi uniforme sur l'intervalle
[0,
1) Y Représente un ensemble de valeurs pour un paramètre d'un modèleW(tl,t2) Temps d'attente moyen des contacts arrivés pendant l'intervalle [tl,t21
W(tl,t2) Somme des temps d'attente pour tous les contacts arrivés pendant l'intervalle
Wdtl, t2) Somme des temps d'attente pour tous les contacts arrivés pendant l'intervalle [tl ,t2l et ayant abandonné par la suite
WS(tl,t2) Somme des temps d'attente pour tous les contacts arrivés pendant l'intervalle [t] ,t2l et servis par la suite
{X
(t), t
~ O} Processus stochastique en temps continuJe remercie tout d'abord Pierre L'Écuyer pour m'avoir proposé ce projet et m'avoir soutenu en tant que directeur de recherche tout au long de sa réalisation. Je le remercie pour ses nombreuses suggestions qui ont contribué à orienter ma recherche et améliorer la bibliothèque ContactCenters, sa documentation et cette thèse.
Je remercie Bell Canada et le Conseil de Recherche en Sciences Naturelles et en Gé-nie (CRSNG) pour avoir contribué au financement de ce projet par le biais d'une bourse d'études à incidence industrielle et d'un projet de recherche sur les centres d'appels dans lequel s'inscrit cette thèse.
Je remercie Athanassios Avramidis, Mehmet Tolga Ce~ik, Wyean Chan, Naoufel Thabet, Raphaël Bean, Mohamed Nassim et Vincent Béchard pour avoir utilisé la bi-bliothèque pendant son développement et proposé diverses améliorations.
Je remercie également mes parents, Pauline et Réal, pour avoir pris soin de mon éducation sans laquelle cette thèse n'aurait pas pu être écrite. Je les remercie également, ainsi que mon frère David et ma sœur Eve, pour m'avoir soutenu et encouragé à mener ce projet jusqu'au bout malgré les embûches rencontrées.
li
1:
1
INTRODUCTION
Un centre de contacts est un ensemble de ressources telles qùe des lignes
télépho-niques, des commutateurs, des routeurs, des employés et des ordinateurs servant d'in-terface de communication entre un organisme et ses usagers. Un contact consiste en
une requête de communication entre un usager et un organisme. La communication peut être effectuée via le téléphone, la télécopie, le courrier électronique, etc. Un centre de contacts ne traitant que des appels téléphoniques est appelé un centre d'appels.
De tels centres doivent traiter un grand nombre de requêtes de divers types, néces-sitent une infrastructure technologique importante et emploient plusieurs préposés, aussi appelés agents, d'où un coût de gestion élevé. D'un autre côté, la qualité du service
offert affecte l'image de marque de l'organisme possédant un centre de contacts. Cer-tains centres de contacts qui effectuent de la vente à distance peuvent même devenir une source de revenus pour une entreprise. L'importance économique des centres de contacts a déjà clairement été démontrée [25]. Les gestionnaires doivent donc établir un équilibre entre la réduction du coût et la qualité du service en effectuant des analyses de sensibilité et de l'optimisation.
Ce chapitre présente les genres de problèmes peuvent poser les centres de contacts. Nous y traitons également des types d'outils disponibles pour leur analyse pour ensuite nous concentrer sur notre solution, ContactCenters, que nous avons améliorée dans le
cadre de ce projet. Nous présentons ensuite les objectifs de notre projet de recherche et le plan du reste de cette thèse.
1.1 Problèmes posés par les centres de contacts
Pour réduire les coûts et améliorer la qualité de service, les gestionnaires doivent considérer divers scénarios pour effectuer des analyses de sensibilité. Ils sont également
amenés à résoudre des problèmes d'optimisation, la plupart du temps sans disposer d' ou-tils adéquats. De plus, ils doivent faire de la planification à court, moyen et long termes du comportement de centres de contacts. Ces problèmes sont présentés dans [l, 7, 34, 71] et examinés plus en profondeur dans les références données par ces articles. Dans cette thèse, nous développons des outils pour aider à effectuer l'analyse de sensibilité et l'op-timisation.
L'analyse de sensibilité consiste à évaluer la performance d'un système sous diverses conditions et utiliser les résultats obtenus pour étudier l'effet de ces conditions sur la performance. Une telle analyse permet par exemple d'évaluer l'impact d'une diminution des durées de service sur la proportion des contacts répondus après un temps d'attente inférieur à un certain seuil, appelée niveau de service. L'analyse de sensibilité permet
aussi d'évaluer la pertinence de changements opérationnels dans un centre de contacts, notamment la mise en place d'une nouvelle politique de routage des contacts, la forma-tion d'agents pour servir de nouveaux types de contacts, l'acheminement d'une porforma-tion des contacts vers un centre géré par un fournisseur tiers, la construction d'un centre de contacts virtuel en mettant en réseau deux ou plusieurs centres réels, etc.
Outre le niveau de service, la performance du système est souvent évaluée en me-surant le pourcentage d'abandons des contacts, leur temps d'attente moyen et le taux d'occupation des agents. Les contacts sont habituellement partitionnés en plusieurs types tandis que les agents sont divisés en plusieurs groupes. Il est courant d'observer, en plus de la performance globale, celle pour chaque type de contact et groupe d'agents.
Parfois, les agents ne servent pas tous les contacts avec le même rendement. Si un agent préfère les contacts d'un certain type k] mais peut aussi servir ceux d'autres types moins efficacement, il est souhaitable que cet agent reçoive des contacts de type k] la plupart du temps. Dans un tel contexte, les gestionnaires s'intéressent à la qualité de l'af-fectation des contacts aux agents, c'est-à-dire à la proportion des contacts d'un certain type servis par des agents d'un certain groupe.
les gestionnaires recherchent le scénario optimal. Par exemple, un problème courant consiste à trouver le nombre minimal d'agents dans chaque groupe pour atteindre un ni-veau de service donné. L'optimisation demande ainsi d'évaluer la performance du centre de contacts plusieurs fois avec des paramètres différents. Elle vise en premier lieu le nombre d'agents par intervalle de temps et par groupe (aussi appelé staffing en anglais [4]), la construction d'horaires pour les agents [6], mais elle s'étend également au ni-veau du routage [56] et de la composition automatique d'appels destinés par exemple à la vente de produits, le rappel de clients, etc.
L'optimisation peut aussi se concentrer sur les recours, c'est-à-dire les décisions prises par les gestionnaires pendant la journée si la performance du système diffère de celle prévue ou désirée. Ces décisions peuvent inclure l'appel de nouveaux agents en ré-serve, la fin prématurée du quart de travail pour certains agents en service, la redirection d'une fraction des contacts vers un fournisseur tiers, etc. L'optimisation de ces recours est une importante avenue de recherche et nécessite beaucoup de simulation.
1.2 Outils d'analyse
1.2.1 Modélisation
Examinons maintenant les outils disponibles pour analyser les centres de contacts. Avant d'entreprendre toute analyse, les gestionnaires doivent construire un modèle ma-thématique approximant le centre de contacts considéré. Ce modèle peut ensuite être utilisé pour prédire le comportement du système lorsque ses paramètres sont Illodifiés. Le modèle le plus courant, sur lequel nous nous concentrons dans cette thèse, est un réseau de files d'attente semblables à celle de la figure 1.1. Dans ce modèle, les contacts sont partitionnés en K types. Les contacts des KI premiers types sont dits entrants, c'est-à-dire qu'ils correspondent à des requêtes initiées par des usagers communiquant avec le centre. Les contacts des autres types sont dits sortants, c'est-à-dire que les requêtes leur correspondant sont initiées par des agents du centre ou un système de composition
automatique.
Les agents servant les contacts sont séparés en 1 groupes. Le groupe d'un agent détermine l'ensemble des types de c~)Otacts qu'il peut servir si bien que tous les agents ne peuvent pas servir n'importe quel contact. Un tel centre est alors dit multi-skill en anglais. Nous reviendrons sur ces notions dans la première section du chapitre suivant.
Déterminer les bonnes partitions pour les contacts et les agents est un problème de modélisation. En général, chaque contact et chaque agent possède ses propres attributs qui le rend unique si bien que former des types de contacts et des groupes d'agents exige habituellement de négliger certaines caractéristiques. Ainsi, plus il y a de types de contacts ou de groupes d'agents, plus le modèle est réaliste, mais plus il est difficile d'obtenir les données nécessaires pour en fixer les paramètres et d'interpréter les résultats obtenus. En revanche, s'il y a trop peu de types de contacts ou de groupes d'agents, le modèle devient trop irréaliste et ne permet pas de mener à bien l'analyse désirée.
Ces partitions établies, il faut modéliser le routage, c'est-à-dire les règles déterminant vers quels agents sont acheminés les contacts qui arrivent et quels contacts en attente servent les agents devenus libres. De plus, les gestionnaires doivent estimer des lois de probabilité pour les durées de service des contacts, modéliser les abandons, déterminer le processus d'arrivée des contacts, etc. Ils doivent également garder à resprit que tous les paramètres sont susceptibles de varier dans le temps. L'estimation de lois est traitée dans bon nombre de livres de simulation, comme [53, 58].
Mais tout cela nécessite des données qui sont difficiles à obtenir si les systèmes en place dans les centres de contacts ne les collectent ou ne les conservent pas. En parti-culier, il arrive que seules des données agrégées par demi-heures ou même pour toute la journée soient disponibles. De plus, modéliser les abandons est difficile, car nous ne pouvons pas observer le temps de patience des contacts qui n'ont pas abandonné. Ce problème est abordé et traité dans [34, 35]. Pour des exemples de modélisations; voir
[11,25].
Abandons
0···8
Groupes d'agents
Types de contacts
Figure 1.1 - Modèle de file d'attente représentant un centre de contacts usuel
. du centre de contacts réel. Les résultats obtenus sont comparés avec les données réelles afin de valider le modèle et le corriger si nécessaire. Ce problème de modélisation et de validation est couvert par tous les ouvrages de base en simulation, comme [53].
1.2.2 Formules analytiques
II existe plusieurs façons différentes d'exécuter un modèle de centre de contacts. Avec les premiers centres ne traitant qu'un seul type d'appel téléphonique, des fQrmules analytiques fondées sur la théorie des' files d'attente étaient utilisées pour effectuer l' ana-lyse sous des hypothèses simplificatrices fortes. Par exemple, le modèle Erlang C, cou-ramment utilisé, considère que les arrivées suivent un processus de Poisson, que les temps de service sont indépendants et suivent la loi exponentielle et qu'aucun abandon n'est autorisé, ce qui est plutôt irréaliste. Sous ces hypothèses, il est possible de dériver une formule donnant la probabilité à long terme que tous les agents sont occupés, ce qui correspond à la probabilité à long terme qu'un appel ait à attendre. À partir de cette probabilité, il est possible de déterminer d'autres mesures de performance telles que le
temps d'attente moyen et le niveau de service.
D'un autre côté, le modèle Erlang B suppose que tout appel qui ne peut pas être servi immédiatement est bloqué; aucune attente en file n'est autorisée. La formule d'Erlang B, qui permet d'obtenir la probabilité à long terme qu'un appel soit bloqué, est valide peu importe la loi de probabilité du temps de service. Le modèle Erlang A autorise quant à lui les abandons, mais il suppose que les temps de patience des contacts sont i.i.d. exponentiels.
Ces formules analytiques sont présentées dans bon nombre d'ouvrages sur la théorie des files d'attente, notamment [20] et reprises dans certains articles comme [34, 70]. Elles sont suffisamment simples pour être implantées par les gestionnaires sous forme de macros dans des tableurs comme Microsoft Excel. Il existe aussi des logiciels dédiés à leur calcul, comme par exemple [16].
Dans le cas d'un centre avec plusieurs types de contacts et groupes d'agents, des ap-proximations existent, mais elles imposent des hypothèses additionnelles sur le routage et les abandons. Par exemple, plusieurs approximations imposent qu'à l'arrivée d'un appel, une liste de groupes d'agents dépendant de son type soit visitée et que le pre-mier groupe comportant au moins un agent libre soit sélectionné. En particulier, [50] propose une approximation qui est valide seulement si tout appel ne pouvant être servi immédiatement est bloqué. L'approximation plus générale développée dans [4] permet l'attente en file, mais elle restreint la façon qu'un agent devenant libre choisit un contact en attente.
Ces formules considèrent habituellement que le centre d'appels fonctionne dans des conditions identiques depuis un temps infini. En réalité, les conditions changent réguliè-rement et nous souhaitons estimer la performance sur un horizon fini, par exemple une journée ou un mois. Les principales approximations du niveau de service sur horizon fini sont reprises dans [45], mais elles supposent toujours que les arrivées suivent un processus de Poisson, les temps de service sont exponentiels et aucun abandon n'a lieu. En pratique, ces hypothèses ne sont pas satisfaites. Par exemple, [5] donne un exemple
dans lequel des processus d'arrivées doublement stochastiques reproduisent mieux les arrivées qu'un processus de Poisson ordinaire. De même, [11] présente un cas pour le-quel les durées de service observées s'ajustent beaucoup mieux à une loi lognormale qu'à une loi exponentie]]e. De plus, il est la plupart du temps trop coûteux de former tous les employés pour servir tous les contacts, même si [81] illustre que cela pourrait augmenter la qualité de service en théorie. Ainsi, agréger tous les types de contacts et les groupes d'agents pour utiliser une approximation adaptée à un modèle simple donne souvent des résultats irréalistes.
1.2.3 Simulation
Bien que les centres de contacts sont encore modélisés par un système de files d'at-tente, seule la simulation peut fournir des évaluations précises tenant compte de toute la complexité. Par contre, évaluer la performance pour plusieurs scénarios par simulation demande d'effectuer des milliers, voire des millions de réplications pour aboutir à un résultat précis. Il est alors important, pour y parvenir, de disposer d'outils très rapides.
Pour donner une idée du temps pris par la simulation pendant l'optimisation, prenons par exemple la technique décrite dans [6]. Celle-ci considère le problème de construction d'horaires comme un programme mathématique utilisant comme fonction objectif un coût linéaire par rapport au nombre d'agents sur chaque quart de travail et le niveau de service des contacts pour les contraintes. La technique résout un programme linéaire correspondant à une version simplifiée du programme mathématique sans les contraintes (stochastiques) sur les niveaux de service. Elle utilise ensuite la simulation pour évaluer la réalisabilité de la solution et ajoute des contraintes au programme linéaire simplifié en utilisant des coupes établies par un estimé du sous-gradient du niveau de service par rapport au vecteur d'affectation des agents, lui aussi obtenu par simulation. Ce processus de coupe est répété jusqu'à obtenir une solution réalisable. Si cette méthode est appliquée sur un centre d'appels avec 20 types d'appels, 35 groupes d'agents et 52 périodes, avec seulement 300 réplications (correspondant à des jours dans le modèle) pour le test de
réalisabilité et 20 réplications pour chaque composante de sous-gradient, il faut malgré tout 300
+
20 * 35 * 52 = 36 700 réplications par itération. Avec ces paramètres et notre outil de simulation qui est le plus rapide parmi ceux que nous connaissons, l'optimisation a exigé cinq heures de temps de calcul.Pour améliorer la vitesse de simulation, nous pouvons simplifier le modèle utilisé, optimiser le programme exécutant le modèle ou encore appliquer des techniques de réduction de la variance. La première idée est souvent inacceptable tandis que la se-conde réduit le temps d'exécution jusqu'à un certain point seulement. La troisième idée, par contre, a un grand potentiel pour améliorer l'efficacité, car il existe un très grand nombre de techniques différentes qu'il est possible d'appliquer et de combiner. Ces techniques sont décrites dans la plupart des ouvrages de base en simulation, notamment [10,28,36,53,58]. Par contre, leur application n'est souvent pas directe et demande des adaptations. Plusieurs articles appliquent ou combinent ce genre de techniques, notam-ment [8, 9, 18]. Par contre, aucun de ces articles ne concerne spécifiquenotam-ment les centres de contacts.
Un centre de contacts peut bien entendu être modélisé grâce à un logiciel de simu-lation générique, mais cette tâche nécessite un énorme travail de conception et même de programmation. Il existe heureusement des logiciels spécialisés qui supportent la simula-tion de la plupart des centres de contacts d'aujourd'hui. Arena Contact Center Edisimula-tion de Rockwell [75] et ccProphet de NovaSim [73] sont des exemples de tels logiciels. Toute-fois, de nouveaux cas qui n'étaient pas prévus initialement peuvent survenir à n'importe quel moment et s'avérer difficiles à traiter sans recourir à des mécanismes de bas niveau qui dépendent du logiciel choisi et qui peuvent nécessiter la mise à jour vers une version plus complète (et plus coûteuse) du produit. De telles extensions sont aussi nécessaires pour appliquer des techniques de réduction de la variance. Les logiciels commerciaux sont également formés d'un grand nombre de couches superposées, interconnectées et difficiles à séparer qui peuvent diminuer la performance. Ainsi, faute d'outils adéquats, plusieurs gestionnaires de centres de contacts emploient encore les formules analytiques
même lorsque leurs hypothèses ne sont pas vérifiées.
1.3 Éléments de ContactCenters
De notre côté, nous avons développé la bibliothèque ContactCenters [12, 14, 15] en Java. Ce langage est puissant, largement utilisé et très bien supporté. Nous avons em-ployé la bibliothèque SSJ [55, 59, 64] comme système de simulation en Java pour la génération des nombres aléatoires, la gestion de la liste d'événements et la collecte sta-tistique. Grâce à l'héritage, les classes de ContactCenters peuvent facilement être éten-dues sans les réécrire en entier. Un simulateur peut tirer parti de Java pour accéder à un grand nombre de bibliothèques d'optimisation, d'analyse statistique, ainsi qu'à des outils de construction d'interfaces graphiques. Grâce aux optimisations des récentes machines virtuelles Java, un simulateur écrit en Java s'exécute beaucoup plus rapidement qu'un modèle conçu grâce aux outils commerciaux les plus utilisés et fondés sur un langage complètement interprété et peu répandu.
ContactCenters est formée de composantes indépendantes qui sont reliées entre elles au moment de construire un programme simulant un modèle précis et détaillé de centre de contacts. Un tel programme peut également intégrer des techniques de réduction de la variance. Ces composantes représentent les contacts (appels, télécopies, etc.), les pro-cessus d'arrivées, le composeur d'appels sortants, les groupes d'agents, files d'attente et le routeur. Chaque contact est représenté par une entité, c'est-à-dire un objet, avec son propre ensemble d'attributs prédéfinis que l'utilisateur peut étendre si nécessaire. Les sources de contacts (processus d'arrivées et composeurs d'appels sortants) construisent de tels contacts et les envoient au routeur qui se charge de mettre les contacts en service auprès d'agents ou les insérer dans des files d'attente pour les traiter plus tard. Le routeur annonce aussi les contacts sortants du centre à un système de collecte statistique.
Le programmeur peut facilement construire un observateur et l'enregistrer auprès de ces composantès pour, par exemple, connaître les contacts qui sont créés, ceux qui sortent
du système, suivre l'état des agents, etc. En fait, tout le couplage entre les composantes du système est effectué à l'aide d'observateurs [33], ce qui donne un maximum de flexi-bilité. Dans ce modèle, chaque objet observable comporte une liste d'observateurs dont le contenu exact n'est connu qu'à l'exécution. Un observateur est un objet implantant une interface spécifique. Lorsque de l'information doit être diffusée, la liste est parcou-rue et une méthode spécifiée par l'interface est appelée pour chaque observateur. De cette façon, les composantes peuvent être testées, améliorées et remplacées indépendamment des autres.
Par contre, écrire un programme Java pour simuler un centre de contacts peut être long et n'est pas à la portée de tous les gestionnaires. Un tel programme doit aussi ré-pondre à un certain nombre de normes pour pouvoir interagir de façon générale avec d'autres programmes tels qu'un optimiseur.Il est alors important de disposer d'un simu-lateur précompilé le plus général possible permettant de traiter les cas les plus courants et d'interagir facilement avec d'autres outils. En utilisant les composantes de Contact-Centers, nous avons construit un tel simulateur qui permet, en utilisant des fichiers de configuration dans le format XML [83], de traiter la plupart des centres d'appels cou-, . rants.
XML est un langage permettant de décrire du contenu hiérarchique sous la forme d'une chaîne de caractères, en employant des éléments auxquels sont associés des attri-buts et qui peuvent contenir du texte ou d'autres éléments. Bien entendu, une application XML particulière spécifie quelles informations sont permises dans les fichiers qui lui sont propres.
Ce simulateur générique précompilé se restreint à un modèle particulier mais assez général de centre d'appels mixte supportant KI types d'appels entrants et Ko types sor-tants, avec 1 groupes d'agents et un horizon séparé en P périodes principales de durée fixe. L'usager peut employer n'importe quelle loi de probabilité de SSJ pour les durées de patience et les durées de service, mais il doit choisir les processus d'arrivées, les politiques de composition d'appels sortants et la politique de routage parmi des listes
de politiques prédéfinies. Il peut par contre paramétrer les différents processus avec des valeurs numériques.
Le simulateur calcule différentes statistiques comme le nombre d'appels produits, servis, bloqués ou ayant abandonné. Ces statistiques sont utilisées entre autres pour es-timer les mesures de performance qui intéressent les gestionnaires, comme le niveau de service, le pourcentage d'abandons, etc. Chaque mesure est estimée pour chaque période séparément ainsi que pour tout l'horizon.
La simulation peut être effectuée de façon stationnaire pour une seule période de du-rée supposément infinie dans le modèle, en utilisant la méthode des moyennes par lots [53] pour obtenir des intervalles de confiance, ou pour tout l'horizon, avec un nombre donné de réplications indépendantes. Dans le cas stationnaire (horizon infini), le simu-lateur est initialisé avec les paramètres pour une période et ces paramètres demeurent fixes tout au long de l'expérience. Dans le cas non stationnaire (horizon fini), les para-mètres peuvent changer d'une période à J'autre. Simuler sur horizon infini ne semble pas naturel pour des centres de contacts, mais il peut s'avérer utile de le faire pour compa-rer les résultats de simulation avec des approximations considérant le système comme stationnaire.
1.4 Plan de la thèse
Dans cette thèse, nous proposons des améliorations aux outils existants pour simuler les centres de contacts. En particulier, nous améliorons J'efficacité à J'aide de techniques de réduction de la variance, nous proposons un modèle simplifié plus rapide à simu-ler mais moins restrictif que ceux employés par les approximations courantes et nous améliorons la flexibilité et la facilité d'utilisation de notre logiciel de simulation.
D'abord, le chapitre suivant explique de façon plus détaillée ce que sont les centres de contacts et introduit la notation mathématique utilisée tout au long de cette thèse. En-suite, nous examinons des techniques réduisant la variance pour un scénario particulier.
Dans cette optique, le chapitre 3, publié en partie dans [61
J,
étudie la combinaison de la stratification sur une variable continue avec une variable de contrôle linéaire et montre que l'interaction entre ces deux techniques soulève des problèmes intéressants. La strati-fication [19] consiste à séparer les réalisations d'une ou plusieurs variables aléatoires en strates et à échantillonner séparément dans chaque strate pour ensuite calculer un esti-mateur combinant les strates. Une variable de contrôle linéaire [37] consiste quant à elle en une variable aléatoire d'espérance nulle multipliée par un coefficient et ajoutée à un estimateur. La combinaison des deux techniques pose des problèmes, car le coefficient optimal de la variable de contrôle dépend de la variable sur laquelle nous stratifions. Il existe également plusieurs façons d'effectuer la combinaison et aucune technique ne surpasse toutes les autres en général. En particulier, nous pourrions croire qu'utiliser un coefficient variant en fonction d'une variable de stratification continue réduit davan-tage la variance qu'un coefficient dépendant uniquement de la strate puisque la première méthode utilise davantage d'informations que la seconde. Mais souvent, utiliser un co-efficient par strate est plus simple à implanter et réduit davantage la variance. Après avoir examiné la synergie entre ces deux techniques, nous évaluons l'effet de certaines variables de contrôle sur un exemple de centre de contacts avant d'appliquer la combi-naison et examiner les résultats.Comme expliqué dans la section 1.1, les gestionnaires sont souvent amenés à simu-ler plusieurs scénarios pour un même modèle. Bien que simusimu-ler chaque scénario plus rapidement réduit le temps total pris par toute l'expérience, il est judicieux d'étudier des techniques tirant parti de la similarité existante entre les configurations. Le cha-pitre 4 examine pour cela l'application des variables aléatoires communes [10] pour estimer la différence de mesures de performance par rapport à un paramètre d'un centre de contacts. Cette technique consiste à utiliser les mêmes nombres aléatoires aux mêmes endroits pour chaque configuration simulée. Dans ce chapitre, publié en partie dans [60], nous comparons différentes méthodes de synchronisation et développons pour certains cas des preuves de convergence de la variance de la différence par rapport à la variation
d'un paramètre continu.
Puisque les techniques précédentes ne sont pas efficaces dans tous les cas, nous avons pensé à simplifier notre modèle. Dans cette optique, le chapitre 5, publié en partie dans [13], développe un modèle de centre de contacts utilisant une chaîne de Markov en temps continu et permettant dans certains cas d'améliorer la vitesse de simulation en utilisant l'uniformisation [40] et la conversion en temps discret [31]. La technique consiste à simuler la chaîne de Markov en temps discret imbriquée et à calculer des espérances conditionnelles à la séquence des états visités et au nombre de transitions effectuées. Si nous appliquons cette idée aux centres de contacts, la chaîne de Markov utilisée possède un état à plusieurs dimensions. Nous traitons ce problème en appliquant la recherche indexée pour générer les transitions dans les modèles avec plusieurs types de contacts et groupes d'agents. L'estimation du niveau de service avec la conversion en temps discret n'est pas triviale étant donné qu'elle fait appel aux temps d'attente de tous les contacts qui ne sont pas générés avec cette méthode. Nous résolvons ce problème en calculant pour chaque contact une probabilité conditionnelle au nombre de transitions passées en attente et au nombre total de transitions. De plus, l'uniformisation fait parfois en sorte que le tau,x de transition utilisé est élevé, provoquant beaucoup de transitions fictives. Pour remédier à cela, nous développons une technique de partitionnement de l'ensemble d'états permettant de bénéficier d'un taux de transition adaptatif sans briser l'uniformisa-tion. Si le taux d'arrivée et le nombre d'agents sont élevés et s'il y a un nombre modéré de types de contacts et de groupes d'agents, la simulation avec ce modèle est plus ra-pide qu'avec un modèle tenant compte de tous les détails et notre chaîne de Markov se fonde sur des hypothèses moins restrictives que les formules d'approximation couram-ment utilisées. Cette technique est ainsi très utile pour les premières étapes d'algorithmes d'optimisation, la simulation par événements discrets étant utilisée à la fin pour raffiner la solution trouvée.
Lorsque nous simulons plusieurs configurations, en plus d'augmenter l'efficacité pour simuler chaque configuration séparément, nous souhaitons éviter de répéter du
tra-vail inutilement. Dans cette optique, le chapitre 6 généralise une technique de scission et de recombinaison (split and merge en anglais) présentée dans [68], pour l'adapter à
un modèle de centre de contacts. Avec cette technique, des copies du modèle simulé se scindent au moment où des décisions impliquant les paramètres à faire varier sont prises et peuvent fusionner lorsque l'état du système est le même. Par contre, avec un modèle trop complexe, le nombre de points de décision est trop grand ou les tests pour la scis-sion et la recombinaison sont si coüteux que simuler chaque configuration séparément est plus rapide. Nous proposons un modèle de centre de contacts ne présentant pas ces problèmes et sur lequel nous avons appliqué la technique avec succès pour estimer des sous-gradients du niveau de service. Dans ce modèle, chaque point de décision corres-pond à l'arrivée d'un contact et la scission se produit en fonction du routage du nouveau contact.
Enfin, le chapitre 7 présente les grandes lignes de l'architecture de ContactCenters, ses principales fonctionnalités ainsi que les problèmes principaux rencontrés pendant son développement. En particulier, nous examinons plus en profondeur les possibilités du simulateur générique précompiJé. Nous découvrons aussi que le mode de gestion des groupes d'agents affecte dans certains cas les résultats de simulation. Nous comparons différentes heuristiques pour prédire les temps d'attente dans le cas où le modèle com-. porte plusieurs types de contactscom-. Nous examinons aussi comment nous avons augmenté
l'extensibilité du simulateur générique nécessitant peu ou pas de programmation Java en permettant à l'usager de personnaliser les lois de probabilité, les politiques de routage et de composition d'appels sortants et les processus d'arrivées utiJisés. Nous décrivons aussi comment nous avons simplifié l'entrée des paramètres en construisant un schéma XML pour notre format de données et comment nous avons amélioré la clarté des mes-sages d'erreur en tirant parti du mécanisme de propagation des exceptions de Java. Voir la documentation de ContactCenters [14] pour des détails supplémentaires sur l'archi-tecture, les fonctionnalités et l'utilisation du logiciel de simulation.
CONCEPTS ET NOTATION MATHÉMATIQUE DE BASE
Dans ce chapitre, nous présentons les concepts et la notation mathématique de base qui seront utilisés tout au long de cette thèse. La prochaine section décrit de façon plus détaillée ce qu'est un centre de contacts. La section 2.2 décrit de façon mathématique les mesures de performance abordées au chapitre précédent. Enfin, la section 2.3 rappelle la notion d'ordre asymptotique qui sera utilisée à certains moments dans cette thèse.
2.1 Les centres de contacts
Comme indiqué au chapitre précédent, un centre de contacts est habituellement mo-délisé par un réseau de files d'attente semblables à celle de la figure 1.1. Un contact
consiste en une requête de communication entre un usager et un organisme. Les contacts
entrants sont générés par des usagers tentant d'entrer en communication pour obtenir un
service tel qu'une réservation ou du support technique; Les contacts sortants sont initiés
de façon proactive par les employés ou, dans le cas des appels téléphoniques, par un sys-tème spécialisé appelé composeur. Ils permettent par exemple la vente à distance ainsi que le rappel de clients. Les centres capables de traiter les deux types de contacts sont dits mixtes.
Afin de simplifier le traitement, chaque contact est classé selon un type représenté sous la forme d'un entier k entre 1 et K, où K est le nombre total de types de contacts supportés par un système particulier. Un contact est entrant si son type k E {l, ... ,KI},
où KI ~ K est le nombre de types de contacts entrants tandis qu'il est sortant si k E {KI
+
1, ...
,K}.
Le type de contact peut être déterminé en utilisant sa provenance (numéro de téléphone de l'appelant, site Web utilisé, etc.), les choix de l'usager dans des menus, etc. Il peut représenter la raison de la communication, l'importance du client, etc.ap-pelé composeur qui puisent les informations sur les usagers à contacter depuis une liste. La composition de cette liste ainsi que le nombre de contacts à tenter simultanément par le composeur dépend d'une politique de composition. Un contact sortant peut échouer si, par exemple, le numéro de téléphone du client ou son adresse électronique sont in-valides, si l'usager appelé est occupé ou absent, si une boîte vocale est atteinte, etc. Si un composeur est utilisé pour appeler des clients, il se peut aussi qu'au moment où la communication est complètement établie, aucun agent n'est disponible pour la traiter; on appelle cela un mismatch. Les clients victimes d'un tel problème peuvent soit at-tendre en file ou être bloqués. Bien entendu, le temps de patience d'un client ainsi traité sera habituellement très petit. Si la communication réussit, un agent doit vérifier que la bonne personne est contactée avant de pouvoir traiter la communication sortante. Une communication ainsi réussie est appelée right party connect.
Le service d'un contact consiste en un traitement destiné à satisfaire la requête d'un
usager. De nos jours, plusieurs requêtes peuvent être traitées entièrement par des sys-tèmes automatisés, mais parfois, un usager peut manifester le besoin ou le désir de parler à un être humain. Dans ce contexte, le service comprend la phase de traitement automa-tique, le travail d'un employé pendant la communication avec le client et le travail que l'employé doit parfois effectuer après le dialogue.
Chaque employé, aussi appelé agent, fait partie d'un groupe i E
{l, ...
,!}
définis-sant ses compétences. Il possède également certaines particularités qui peuvent affecter son efficacité et son horaire de travail. Un agent peut aussi correspondre à une ressource informatique dans le cas où on voudrait modéliser un système de traitement automatisé. Au temps t de la journée, le groupe i contient Ni(t) membres dont NB,i(t) sont en train de servir des contacts et NI,i(t) sont inoccupés. Il se peut que Ni(t)<
NB,i(t)+
N1,i(t)si NO,i
(t)
agents terminent leur quart de travail (quittent le groupe) après avoir terminéle service en cours. Parmi les agents inoccupés, seuls NF,i(t) ::; NI,i(t) sont connectés et disponibles pour de nouveaux services. Le nombre d'agents Ni(t) est souvent plus petit que le nombre planifié en raison de retards, de pauses prolongées, etc. La figure 2.1
pré-sente une vue schématique de ces différentes quantités. Nous pouvons également définir
N(t), NG(t), NB (t), NI(t)
etNF(t)
comme les équivalents des quantités précédentes pour tous les groupes d'agents du système.Les agents du groupe i ne peuvent servir que des contacts dont le type fait partie d'un ensemble Si {l, ... ,I}. On parle d'un groupe d'agents généralistes si Si {1, ...
,I}
et d'un groupe de spécialistes si ISil est proche de 1. On parle d'un centre de contacts
multi-skills si 1
>
1, K>
1 et Si diffère d'un groupe d'agents à l'autre.Pendant leurs quarts de travail, les agents sont enregistrés auprès d'un routeur chargé d'acheminer les nouveaux contacts vers des agents libres et d'affecter des contacts en attente à des agents devenus libres. Les règles de routage peuvent être très complexes, allant d'une simple liste de groupes d'agents spécifique à chaque type de contacts à une politique dynamique tenant compte de tout l'état du système pour prendre chaque décision. Évidemment, le routeur est une composante centrale dans un centre de contacts. Un usager peut être servi par plusieurs agents avant d'obtenir satisfaction. Par exemple, un utilisateur éprouvant des problèmes techniques avec un logiciel pourrait parler à dif-férents techniciens (simultanément ou séquentiellement) avant d'obtenir une solution. Un retour se produit lorsqu'un usager servi doit recontacter l'organisme pour obtenir un nouveau service ou tenter de nouveau de satisfaire sa requête initiale.
Dans le cas de communications différées comme les courriers électroniques, le ser-vice peut même être préemptif, c'est-à-dire qu'un agent peut interrompre une tâche consistant par exemple à répondre à un message pour se charger d'une tâche plus prio-ritaire comme traiter un appel téléphonique. Ainsi, en raison des retours et du service préemptif, les agents traitent parfois plusieurs usagers simultanément.
1 Nombre planifié