G-équations différentielles stochastiques et
résolution numérique de la G-équation de la chaleur
ﻲﻤﻠﻌﻟا ﺚﺤﺒﻟاو ﱄﺎﻌﻟا ﻢﻴﻠﻌﺘﻟا ةرازو
0B
BADJI MOKHTAR -ANNABA
3B
UNIVERSITY
1B
UNIVERSITE BADJI MOKHTAR
2B
ANNABA
ﺭﺎﺗﺧﻣ ﻲﺟﺎﺑ ﺔﻌﻣﺎﺟ
-
ﺔﺑﺎﻧﻋ
-Faculté des Sciences
Département de Mathématiques
THESE
Présentée en vue de l’obtention du diplôme de
DOCTORAT
EN SCIENCES MATHEMATIQUES
Option
: systèmes dynamiques et calculs stochastiquesPar
OUAOUA Amar
DIRECTEUR DE THESE : BOUTABIA Hacène Prof U.B.M. ANNABA CO-DIRECTEUR DE THESE : SPITERI Pierre Prof U. TOULOUSE
Devant le jury
PRESIDENT 4BBENCHETTAH Azzedine Prof 5BU.B.M. ANNABA
EXAMINATEUR YOUSFATE Abderrahmane Prof 6BU. SIDI BEL ABBES
EXAMINATEUR MAOUNI Messaoud M.C.A 7BU. SKIKDA
Table des matières
1 Généralités sur l’espérance non-linéaire 10
1.1 Espérance non-linéaire . . . 10
1.1.1 Représentation d’une espérance non-linéaire . . . 12
1.1.2 Distribution et indépendance . . . 13
1.1.3 Distribution G normale . . . 16
1.1.4 Théorème de la limite centrale . . . 18
1.2 G-Mouvement Brownien . . . 18
1.2.1 Dé…nitions et propriétés . . . 18
1.2.2 Existence du G mouvement Brownien . . . 22
1.3 Convergence dans Rd . . . 23
2 Solution explicite de la G-équation de la chaleur 28 2.1 Equation di¤érentielle ordinaire liée à la G-équation de la chaleur . . . . 28
2.2 Théorème d’existence et l’unicité de la solution . . . 31
3 Méthodes itératives de relaxation par points et par blocs 41 3.1 Critères d’inversibilité d’une matrice . . . 41
3.2 Dé…nition et propriétés d’une M-matrice . . . 43
3.3 Méthodes itératives classiques . . . 44
4 Rappel sur les algorithmes parallèles 49 4.1 Algorithmes parallèle asynchrones . . . 51
4.2 Algorithmes parallèle synchrones . . . 53
4.3 Rappels sur la notion d’accrétivité . . . 54
4.4 Dé…nitions et théorèmes de convergence . . . 56
4.4.1 Convergence en norme vectorielle : . . . 58
4.4.2 Convergence en norme scalaire : . . . 59
5 Solution numérique de la G-équation de la chaleur 61 5.1 Discrétisation de la G-équation de la chaleur . . . 63
5.2 Linéarisation de la G-équation de la chaleur . . . 64
5.3 Méthodes itératives parallèle de sous-domaines sans recouvrement . . . . 69
5.4 Méthodes itératives parallèle de sous-domaines avec recouvrement . . . . 74
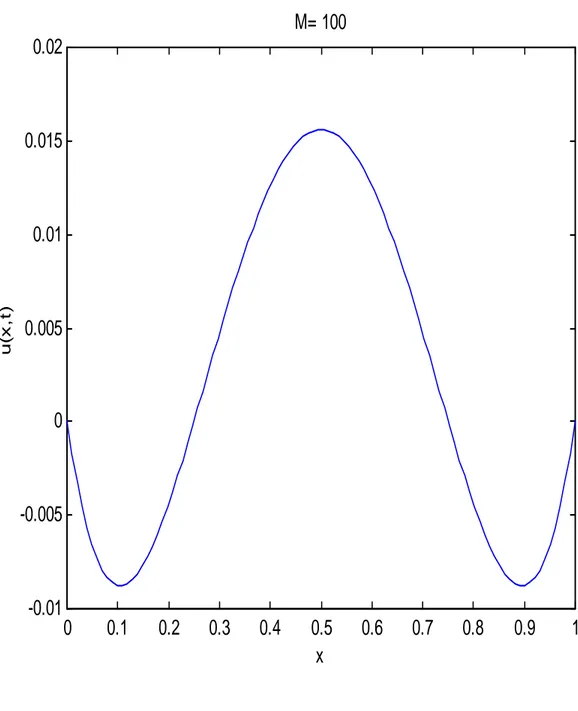
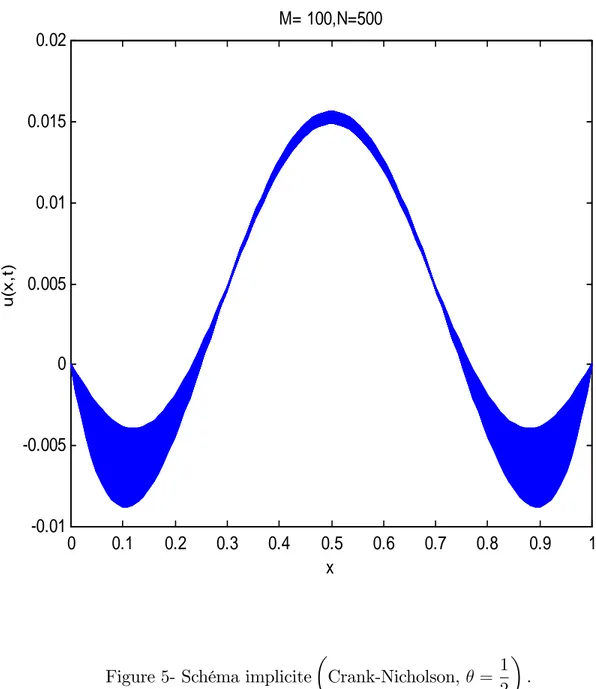
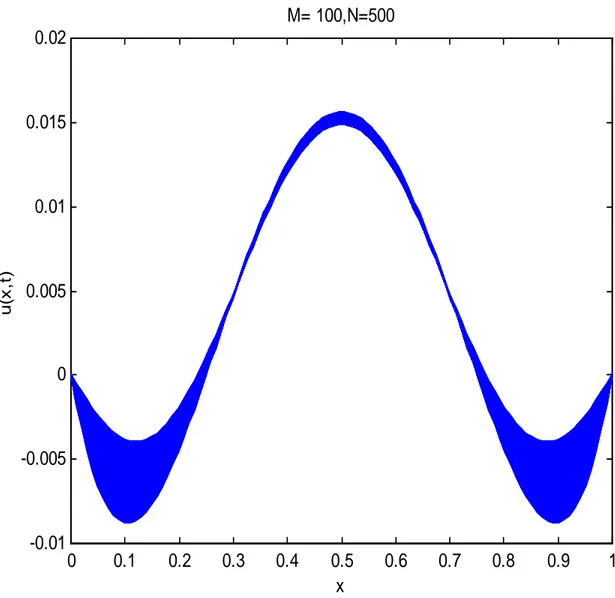
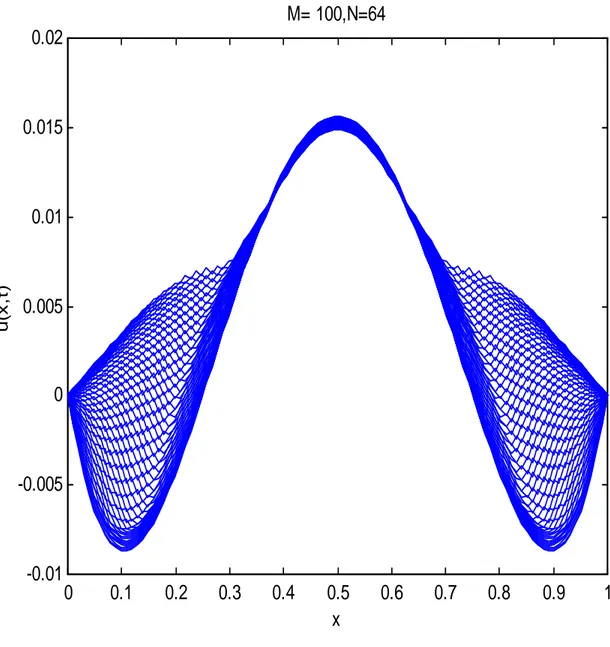
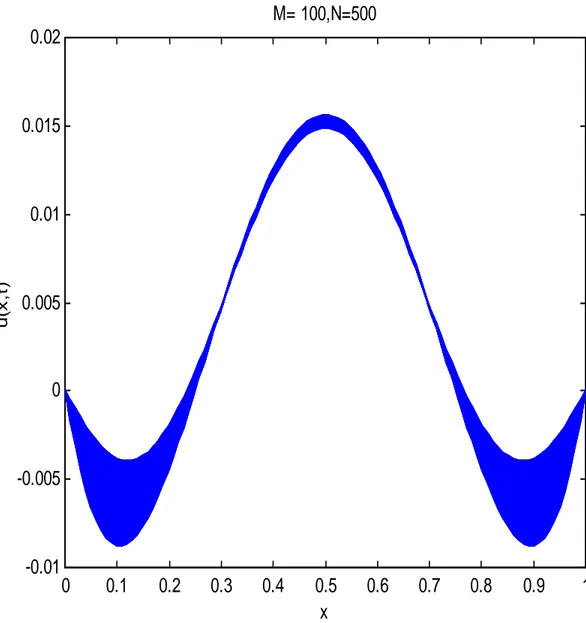
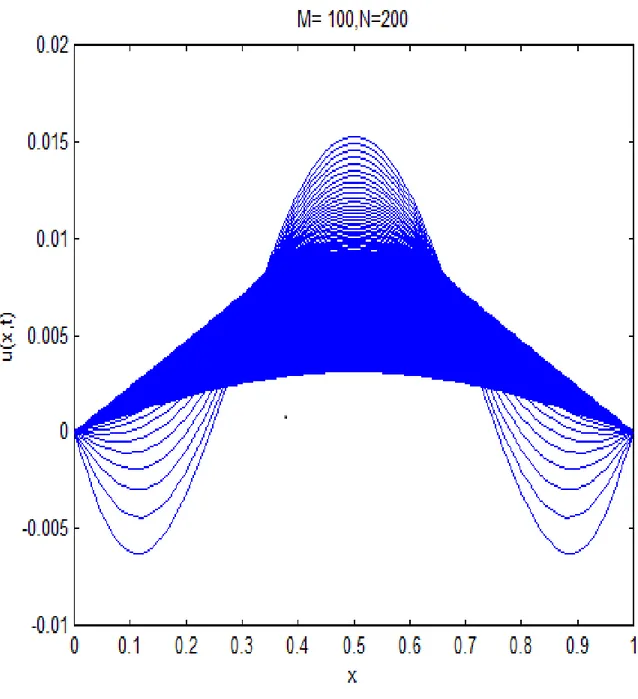
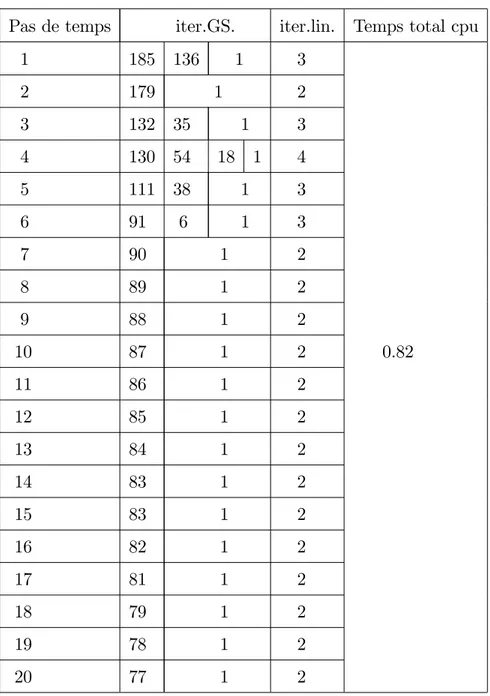
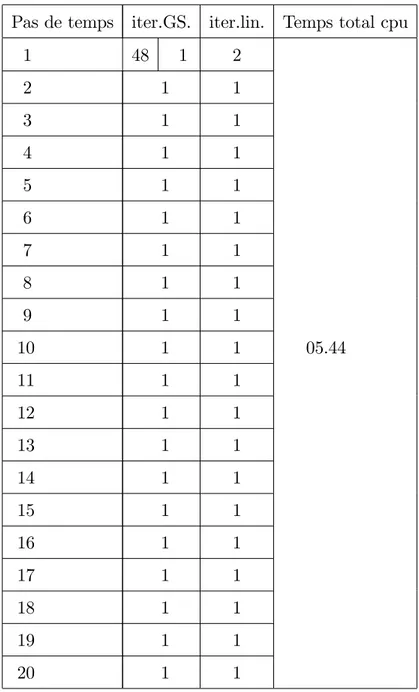
6 Expériences numériques 77 6.1 Expériences numériques séquentielles . . . 77
6.2 Expériences numériques parallèles . . . 96
6.2.1 Résultats des expériences numériques parallèles sur HPC@LR . . 97 6.2.2 Résultats des expériences numériques parallèles sur la Grid5000 . 100
Remerciements
Mes remerciement sont adressés en tout premier lieu à Monsieur le Professeur Hacène BOUTABIA, mon directeur de thèse qui m’a proposé ce sujet de recherche, et qui n’a pas cessé du suivre et de m’encourager à le mener à terme. Je lui exprime également mes sincères gratitudes pour son appui, sa sagesse, ses conseils et surtout pour le temps qu’il a consacré pour me guider à améliorer signi…cativement la qualité de ce travail de recherche. Je tiens également à remercier Monsieur le Professeur Pierre SPITERI pour avoir accepté de me Co-encadrer, de m’avoir constamment guidé, encouragé et conseillé. Je lui exprime non moins mes sincères gratitudes pour sa persévérance pendant mon stage à Toulouse, pour les documents qu’il m’a fournis et qui m’ont aidé à terminer mon travail ainsi que pour sa patience et ses orientations précieuses qui m’ont beaucoup facilité la recherche. Je tiens encore à le remercier et lui être reconnaissant pour le suivi de mon travail et pour m’avoir guidé pour l’implantation des programmes MATLAB.
J’adresse aussi mes vifs remerciements à Monsieur le docteur Ming CHAU, pour les aides, ses encouragement et son soutien et pour m’avoir guidé sur l’implantation des programmes MATLAB et programmes parallèles.
Mes remerciements sont adressés également aux Professeurs BENCHETTAH Azze-dine, YOUSFATE Abderrahmane et au Docteur MAOUNI Messaoud qui m’ont honoré par leur présence parmi les membres de jury et pour le temps qu’ils ont consacré à la lecture de ma thèse.
En…n, je n’oublie pas de remercier le personnel du département informatique et ma-thématiques appliquiées de l’ENSEEIHT de Toulouse, à tous mes proches,à mes amis et à mes collègues doctorants.
Résumé : Dans cette thèse, on résout, par di¤érentes méthodes numériques, la G équation de la chaleur. On montre, d’abord que la solution de la G équation de la chaleur dé…nie sur un domaine borné Rd converge uniformément vers la solution de la G équation
de la chaleur sur Rd lorsque la mesure de tend vers l’in…ni. On montre également que
la solution du problème associé aux méthodes de relaxations parallèles de sous-domaines sans et avec recouvrement convergent vers la solution du problème linéarisé. On présente les résultats des essais numériques séquentiels et parallèles, et en particulier on compare les méthodes parallèles synchrones et asynchrones.
Mots clés : G équation de la chaleur, G mouvement Brownien, relaxations paral-lèles, méthode alternée de Schwartz.
Abstract : In this thesis, we solve, by various numerical methods the G heat equation. Firstly, we prove that the solution of the G heat equation de…ned on a bounded domain
Rd
converge uniformly to the solution of the G heat equation on Rd when the
measure of tends to in…nity. We also prove that the solutions of the problems associated with the parallel relaxation sub-domains methods without and with overlapping converges to the solution of the linearized problem. We present the results of sequential and parallel numerical experiments, and particularly we compare the synchronous and asynchronous parallel methods.
Keys works : G heat equation, G Brownian motion, Parallel relaxations, Schwarz alternating method.
Introduction : L’équation de Hamilton-Jacobi-Bellman (en abrégé H.J.B) est une équa-tion résultant de la méthode de programmaéqua-tion dynamique initiée par Richard Bellman dans les années 50 pour résoudre des problèmes d’optimisation, c’est-à-dire des problèmes où l’on doit prendre les meilleures décisions possibles, à chaque instant pour un critère de performance donné.
L’équation de la programmation dynamique généralise les travaux antérieurs en méca-nique classique d’Hamilton et Jacobi. Historiquement appliquée en ingénierie puis dans les autres domaines des mathématiques appliquées, l’équation d’HJB est un outil im-portant ainsi que dans des problèmes de prise de décision intervenant en économie et …nance.
Dans [34], [38] Peng introduit une nouvelle notion d’espérance non linéaire ; appelée G espérance, qui peut prendre en compte l’incertitude en considération. La G espé-rance a été développé très récemment et a ouvert la voie à l’introduction de variables aléatoires G normales dans le cadre non linéaire qui n’est pas dé…nie sur un espace de probabilité linéaire donnée [38].
Peng [39] a dé…ni la G-équation de la chaleur qui est une équation non linéaire liée à la distribution G-normale et qui généralise la distribution normale classique. Cette équation, qui est un cas particulier de l’équation de Hamilton-Jacobi-Bellman [10] a une unique solution de viscosité [30] ; [34], [49].
La solution analytique de tel système est généralement di¢ cile à trouver. Dans ce cadre en utilisent les méthodes numériques qui s’avèrent e¢ caces. Ces méthodes conduisent à la résolution de systèmes algébriques de grande tailles surtout si on place dans les do-maines de dimensions très élevés. Compte tenu de la taille des systèmes à résoudre les ordinateurs classiques, à exécution séquentielle, nécessite des temps de calcul élevés. Ac-tuellement, la résolution de systèmes algébriques de très grandes tailles s’e¤ectue par utilisation de méthodes numériques parallèles asynchrones et synchrones sur des ma-chines multiprocesseurs, en particulier les méthodes de sous domaines sont bien adaptées au parallélisme [16] ; parmi les méthodes de sous- domaines on considère généralement,
soit les méthodes de sous-domaines sans recouvrement soit les méthodes de sous-domaines avec recouvrement comme la méthode alternée de Schwarz.
Dans cette thèse nous nous interessons à des algorithmes parallèles asynchrones et synchrones pour résoudre notre problème de résolution de la G-équation de la chaleur. Les premiers travaux dans ce domaine ont été introduites par D. Chazan et W. Miranker dans [9] ; dans le cadre de la résolution de systèmes algébriques linéaires. Par la suite par la suite F. Robert [40] et [41] a étendu l’étude précédente dans le cas de systèmes non linéaires dans une situation où les processeurs communiquent entre eux de manière synchrone. J.C. Miellou dans [24] et [27] a étendu les travaux de F. Robert dans une situation où les processeurs communiquent entre eux de manière asynchrone avec des retards bornés. En 1978, G. Baudet dans [6] a généralisé les itérations chaotiques de D. Chazan et W. Miranker et de J.C. Miellou au cas des itérations asynchrones où les les retards ne sont plus nécessairement bornés. Dans [6] ; [24] ; [12] ; [40] et [9] la convergence de ces méthodes itératives a été étudiées par des techniques de contraction. Les travaux de J.C Miellou et P. Spitèri [25] et L. Girand et P. Spitèri [14] donnent des critères de convergence en norme vectorielle des itérations asynchrones. M. N. El tarazi dans [12] a également établi un résultat de convergence des algorithmes asynchrones par des techniques de contractions en norme scalaire convenable. Bahi dans [2] a donné un résultat de convergence concernant les algorithmes parallèles asynchrones ou synchrones pour des systèmes linéaires de point …xe utilisant des opérateurs non-expansifs relativement à une norme uniforme avec poids.
La thèse est composée de six chapitres
Dans premier chapitre, on rappelle les notions de bases de l’espérance non-linéaire, le G-mouvement Brownien et on montre que la solution de la G-équation de la chaleur dé…nie sur un domaine borné converge vers la solution de la G-équation de la chaleur dé…nie sur Rd; i. e. la mesure du domaine tend vers l’in…ni.
Dans le chapitre 2, on démontre l’existence et l’unicité la solution de la G-équation de la chaleur en 1-dimension
Ensuite, dans le chapitre 3, on donne des dé…nitions et des résultats importants concer-nant la convergence des méthodes de relaxation séquentielles par points et par blocs
Au chapitre 4, on rappelle la formulation des algorithmes parallèles synchrones et asynchrones qui généralisent les algorithmes de relaxation séquentiels présentés au cha-pitre 4.
Au chapitre 5 on présente la résolution numérique de la G-équation de la chaleur par des méthodes parallèles de sous-domaines sans et avec recouvrement.
Au chapitre 6 on présente les résultats des essais numériques par les méthodes sé-quentielles, méthodes parallèles.
Chapitre 1
Généralités sur l’espérance
non-linéaire
Une espérance sous-linéaire peut être exprimée comme un supremum des espérances linéaires. Elle est souvent appliquée à des situations où les modèles de probabilités sont incertains et elle s’avère être un outil de base pour mesurer les pertes de risque en …-nance. Dans ce chapitre on donne les notations de bases, les préliminaires de la théorie d’espérance non-linéaire et le G-mouvement Brownien connexe. Plus de détails peuvent être trouvés dans Peng [33]
1.1
Espérance non-linéaire
Soient un ensemble donnée et H un espace linéaire de fonctions à valeurs réelles dé…nies sur . On suppose que H satisfait les conditions suivantes : c 2 H pour chaque constante c et jXj 2 H pour tout X 2 H. L’espace H peut être considéré comme l’espace des variables aléatoires.
Dé…nition 1.1.1 Une espérance sous-linéaire E sur H est une fonctionnelle E : H ! R véri…ant les propriétés suivantes :
(i) Monotonie : E [X] E [Y ] si X Y
(ii) Préservation des constantes : E [c] = c pour c 2 R
(iii) Sous-additivité : Pour tout X; Y 2 H, E [X] E [Y ] E [X Y ] (iv) Homogénéité positive : E [ X] = E [X] ; pour tout 0:
Le triplet ( ; H, E) est appelé espace d’espérance sous-linéaire. Si seulement (i) et (ii) sont satisfaites, E est appellé espérance non linéaire et le triplet ( ; H, E) est appelé espace d’espérance non linéaire.
Remarque 1.1.1 Si l’inégalité (iii) est une égalité, alors E est une espérance linéaire classique.
Remarque 1.1.2 En fait (iii) et (iv) impliquent la propriété suivante de convexité :
E [ X + (1 ) Y ] E [X] + (1 ) E [Y ] pour 2 [0; 1]
Notons que la propriété (iv) est équivalente à la propriété suivante :
E [ X] = +E [X] + E [ X] ; pour tout 2 R:
Dans ce qui suit, on suppose que H satisfait la condition suivante: si X1;...; Xn 2 H
alors (X1; :::; Xn)2 H pour tout 2 Cl;Lip(Rn) ;où Cl;Lip(Rn)désigne l’espace linéaire
de fonctions localement Lipchitzienne de Rn
dans R satisfaisant :
j (x) (y)j C (1 +jxjm+jyjm)jx yj ; 8 x; y 2 Rn
pour C 0et m 2 N dépend de .
Dans ce cas X = (X1; :::; Xn)2 Hn est appelé un vecteur aléatoire à n-dimension.
Remarque 1.1.3 Il est clair que si X 2 H alors jXj ; Xn
2 H. Plus généralement, ' (X) (Y )2 H pour tout X; Y 2 H et pour tout '; 2 Cl;Lip(Rn). En particulier, si
X 2 H alors E [jXjn] <1 pour chaque n 2 N:
Ici, on utilise Cl;Lip(Rn) seulement pour la commodité des techniques. En fait,
l’exi-gence essentielle est que H contient toutes les constantes et, en outre, X 2 H implique jXj 2 H. En général, Cl;Lip(Rn) peut être remplacé par l’un des espaces de fonctions
dé…nies sur Rn suivant :
L1(Rn) :Espace de fonctions bornées Borel-mesurables,
Cunif (Rn) : Espace de fonctions bornées et uniformément continues,
Cb:lip(Rn) :Espace de fonctions continues, Lipchitziennes et bornées,
Lip(Rn) :
Espace de fonctions Lipchitziennes sur Rn:
1.1.1
Représentation d’une espérance non-linéaire
Une espérance sous-linéaire peut être exprimée comme un supremum des espérances linéaires. Elle est souvent appliquée à des situations où les modèles de probabilité sont incertains.
Théorème 1.1.1 Soit E une fonctionnelle dé…nie sur un espace linéaire H satisfai-sant la sous-additivité et l’homogénéité positive. Alors il existe une famille de fonctions linéaires fE : 2 g dé…nies sur H telle que
E [X] = sup
2
E [X] pour X 2 H
et, pour tout X 2 H, il existe X 2 de telle sorte que E [X] = E X[X] :
En outre, si E est une espérance sous-linéaire, alors E est une espérance linéaire.
Remarque 1.1.4 Il est important d’observer que l’espérance linéaire dé…nie ci-dessus E est seulement supposée additive. Mais on peut appliquer le théorème bien connu de Daniell-Stone pour prouver qu’il existe une unique mesure de probabilité additive P
sur ( ; (H)) telle que
E [X] = Z
XdP ; X 2 H
L’incertitude du modèle de probabilité correspondant est décrite par le sous-ensemble fP , 2 g, et l’incertitude correspondante de distributions pour un vecteur aléatoire X à n dimensions dans H est décrite par fFX ( ; A) = P (X 2 A) : A 2 B (Rn)g :
1.1.2
Distribution et indépendance
On donne maintenant la notion de distributions de variables aléatoires selon une espérance non linéaire. Soit X = (X1; :::; Xn) un vecteur aléatoires à n dimensions dé…ni
sur un espace d’espérance non linéaire ( ; H; E) : On dé…nit une fonction sur Cl;Lip(Rn)
par :
FX ['] = E [' (X)] : ' 2 Cl;Lip(Rn) :
Le triplet (Rn; C
l;Lip(Rn) ; FX) forme un espace d’espérance non linéaire. FX est
appelé la distribution de X sous E. On peut prouver qu’il existe une famille de mesures de probabilité FX(:) 2 dé…nie sur (R n; B (Rn)) telle que FX['] = sup 2 Z Rn
' (x) FX(dx), pour chaque ' 2 Cl;Lip(Rn) :
Ainsi FX['] caractérise l’incertitude de la distribution de X: ( voir [33] ; [34]) :
Dé…nition 1.1.2 Soient X1 et X2 deux vecteurs aléatoires à n dimension sur deux
espaces d’espérances non linéaires ( 1; H1; E1) et ( 2; H2; E2) respectivement ; X1
et X2 sont identiquement distribués ( on notera X1 X2) ou X1 d
= X2 si pour toute
fonction test ' 2 Cl;Lip(Rn) ; on a :
Il est clair que X1 d
= X2 si et seulement si leurs distributions coïncident.
Remarque 1.1.5 Si la distribution FX de X 2 H n’est pas une espérance linéaire, alors
X a une distribution incertaine. La distribution de X a les quatre paramètres typiques suivants :
= E [X] ; = E [ X] ; 2 = E X2 ; 2 = E X2 :
Les intervalles ; et [ 2; 2] caractérisent la moyenne incertaine et la variance
incertaine de X respectivement.
Remarque 1.1.6 On notera que X1 d
= X2 implique que les sous-ensembles
d’incerti-tudes de distributions de X1 et X2 sont les mêmes :
fFX1( 1; :) : 1 2 g = fFX2( 2; :) : 2 2 2g
La simple propriété suivante est très utile dans la théorie d’espérance sous-linéaire.
Proposition 1.1.1 Soient X et Y 2 H telle que E [Y ] = E [ Y ] (i.e., Y n’a pas une moyenne incertaine): Alors, on a :
E [X + Y ] = E [X] + E [Y ]
En particulier, si E [Y ] = E [ Y ] = 0; alors E [X + Y ] = E [X] :
La notion d’indépendance qui suit joue un rôle important dans la théorie d’espérance sous-linéaire.
Dé…nition 1.1.3 Dans un espace d’espérance non-linéaire ( ; H; E), le vecteur aléa-toire Y 2 Hn
est dit indépendant d’un autre vecteur aléatoire X 2 Hm
sous E [:] si pour tout ' 2 Cl;Lip(Rn+m) on a :
E [' (X; Y )] = E [E [' (x; Y )]x=X] :
Remarque 1.1.7 Dans un espace d’espérance sous-linéaire ( ; H; E) ; Y est indépen-dant de X signi…e que l’incertitude de distribution fFY ( ; :) : 2 g de Y ne change pas
après la réalisation de X = x. En d’autre terme "l’espérance conditionnelle non-linéaire" de Y par rapport à X est E [' (x; Y )]x=X. Dans le cas de l’espérance linéaire, cette notion
d’indépendance n’est que le cas classique.
Remarque 1.1.8 Il est important de noter que dans une espérance sous-linéaire la condition "Y est indépendante de X" ne signi…e pas automatiquement que "X est indé-pendante de Y ":
Exemple 1.1.1 On considère le cas X, Y 2 H sont identiquement distribuées et E [Y ] = E [ Y ] = 0 mais 2
= E [X2] > 2 =
E [ X2] :
On suppose également que E [jXj] = E [X++ X ] > 0. Ainsi E [X+] = 12E [jXj + X] = 12E [jXj] > 0: Dans le cas où Y est indépendante de X; on a :
E XY2 = E X+ 2 X 2 = 2 2 E X+ > 0
Mais si X est indépendante de Y; on a E [XY2] = 0:
Remarque 1.1.9 La situation "Y est indépendante de X" apparaît souvent lorsque Y survient après X; donc une espérance très robuste devrait prendre l’information de X en compte.
Dé…nition 1.1.4 Une séquence de vecteurs aléatoires à n dimensions f ig1i=1 dé…nis sur un espace d’espérance non linéaire ( ; H; E) est dite convergente en distribution ( ou convergence en loi) sous E si pour chaque ' 2 Cb:Lip(Rn) ; la suite fE [' ( i)]g1i=1
Proposition 1.1.2 Soit f ig1i=1une séquence de variable aléatoire converge en loi dans le sens ci-dessus. Alors l’application F [:] : Cb:Lip(Rn)! R dé…nie par
F ['] = lim
i!1E [' ( i)] pour ' 2 Cb:Lip(R
n)
est une espérance non linéaire sur (Rn:C
b:Lip(Rn)) :
1.1.3
Distribution
G normale
Une notion fondamentalement importante dans la théorie d’espérance sous-linéaire est que la variable X soit N (0; [ 2; 2])
distribuée sous E
Dé…nition 1.1.5 (Distribution G normale)Dans un espace d’espérance sous-linéaire ( ; H; E), une variable aléatoire X 2 H est dite N (0; [ 2; 2]) distribuée (on notera
X N (0; [ 2; 2])
), si pour tout Y 2 H indépendante de X telle que X = Y , on a :d
aX + bY =d pa2+ b2X; 8a; b 0:
Remarque 1.1.10 D’après la dé…nition ci-dessus, on ap2E [X] = E [X + Y ] = 2E [X] etp2E [ X] = E [ X Y ] = 2E [ X] : Il résulte que
E [X] = E [ X] = 0;
autrement dit une variable aléatoire X N (0; [ 2; 2]) distribuée n’a aucune moyenne incertaine.
Corollaire 1.1.1 Lorsque X et eX sont N (0; [ 2; 2]) distribuées, alors X = ed X: En particulier X =d X
Corollaire 1.1.2 Dans le cas où 2 = 2 0
, N (0; [ 2; 2]) est juste la distribution
Remarque 1.1.11 Si X est indépendante de Y et X = Y;d tel que aX + bY =d p
a2+ b2X; 8a; b 0;alors X est également indépendante de Y et on a : X =d Y:
De même a ( X) + b ( Y )=d pa2+ b2( X) ; 8a; b 0:Ainsi
X N 0; 2; 2 si et seulement si X N 0; 2; 2 :
Dans [33] Peng montre que la loi G normale N (0; [ 2; 2]) est caractérisée par
l’équation parabolique aux dérivées partielles suivante, dé…nie sur [0; 1) R :
@tu G @xx2 u = 0
avec la condition de Cauchy u jt=0= ';où G est appelée fonction génératrice de l’équation,
qui est une fonction sous-linéaire réelle paramétrée par 2 et 2 et dé…nie par:
G ( ) = 1 2E X 2 = 1 2 2 + 2 ; 2 R:
où, on note + = max
f0; g et = ( )+: L’équation précédente est appelée la G équation de la chaleur de la distribution sous-linéaire N (0; [ 2; 2]) :
Remarque 1.1.12 On utilise la notion de solutions de viscosité de la G équation de la chaleur. Cette notion ont été introduite par Crandall et Lions [10].
Proposition 1.1.3 [33] Soit X une variable aléatoire N (0; [ 2; 2]) distribuée.
Pour tout ' 2 Cl;Lip(R) ; on dé…nit la fonction u (t; x) = E ' x +
p
tX ; (t; x) 2 [0;1) R: Alors on a :
1)
u (t + s; x) = E u t; x +psX ; s 0:
2 [0; T ] et pour tout x; y 2 R;
ju (t; x) u (t; y)j C 1 +jxjk+jyjk jx yj
et
ju (t; x) u (t + s; x)j C 1 +jxjk jsj12
En outre, u est l’unique solution de viscosité de la G-équation de la chaleur.
1.1.4
Théorème de la limite centrale
Théorème 1.1.2 [34] (Théorème de la limite centrale) Soit fXig1i=1 une suite de H
identiquement distribuée. On suppose également que, Xn+1est indépendante de (X1; :::; Xn)
pour tout n = 1; 2; :::et que
E [X1] = E [ X1] = 0; E X12 = 2
; E X12 = 2
pour 0 < < <1 …xés. Alors la suite fSn=png1n=1 où Sn = X1+ ::: + Xn; converge
en loi vers une distribution qui est N (0; [ 2; 2]) distribuée.
1.2
G-Mouvement Brownien
Le but de cette section est d’introduire la notion du G Mouvement Brownien liée à la distribution G normale dans un espace d’espérance sous linéaire.
1.2.1
Dé…nitions et propriétés
Dans cette sous section on dé…nit le G Mouvement Brownien unidimensionnel et d dimensionnel, d > 1 ; on donne ainsi quelques propriétés qui sont importantes en calcul stochastique.
Dé…nition 1.2.1 Dans un espace d’espérance sous-linéaire ( ; H,E), un processus (Bt)t 0 est appelé G-mouvement Brownien si les propriétés suivantes sont satisfaites :
(i) B0 = 0
(ii) Pour tout t; s 0 l’accroissement Bt+s Bsest N (0; [ 2s; 2s])-distribué et est
indépendant de (Bt1; :::; Btn) pour tout n2 N et pour toute suite 0 t1 ::: tn t.
Remarque 1.2.1 (ii)Signi…e que
E Bt1; :::; Btn 1; Bt+s Bs = E ' Bt1; :::; Btn 1 (1.1)
où ' (x1; :::; xn 1) = E [ (x1; :::; xn 1;psB1)] :
Dans cas particulier E [ (Bt)] = E
p tB1 ;8t > 0 et E Bt2n+1 = tn+ 1 2E B2n+1 1 pour tout n 1:
Remarque 1.2.2 La lettre G indique que le processus B est caractérisé par sa fonction génératrice" G" dé…nie par
G( ) = 1 2E B
2
1 ; 2 R
Comme le mouvement Brownien classique, le G-mouvement Brownien possède la pro-priété d’échelle ( voir [35]), a savoir, pour tout > 0; le processus 12B
t
t 0 est
également un G mouvement Brownien. Pour tout t0 > 0; le processus (Bt+t0 Bt0)t 0
est aussi un G mouvement Brownien.
Dé…nition 1.2.2 Soit ( ; H; E) un espace d’espérance non linéaire. (Xt)t 0est appelé
processus stochastique à d dimensions si pour tout t > 0; Xt est un vecteur aléatoire à
valeur dans Hd:
Soit S (d) (resp. S+(d))l’ensemble des matrices (resp. dé…nies positives) carrés
symé-triques d’ordre d: Soit G : S (d) ! R dé…nie par G(A) = 12E [(AX; X)] 1
2jAj E [X
2] :
(a) A B ) G(A) G(B) (b) G( A) = +G(A) + G( A) (c) G(A + B) G(A) + G(B):
D’après le théorème (1:1:1) ; qu’il existe un sous ensemble S+(d) fermé, borné
et convexe tel que
G(A) = 1
2sup2 tr( A); A2 S (d) On pose P=fA A : A 2 g ; où A est la transposé de A:
Dé…nition 1.2.3 (Distribution G normale ) Dans un espace d’espérance sous li-néaire ( ; H; E), un vecteur aléatoire à d dimensions X = (X1; :::; Xd)est dit G normalement
distribué et noté par X N (0; ) si pour tout ' 2 Cl;Lip Rd , la fonction u dé…nie par
u (t; x) = Eh' x +ptX i; t 0; x 2 Rd est l’unique solution de viscosité de la G-équation de la chaleur suivante
8 < : @u @t = G (D 2u) ; (t; x) 2 (0; T ) Rd ujt=0= ' (x) où D2u = @2 xixju
i;j est la matrice Hessienne.
Remarque 1.2.3 La G-équation de la chaleur dans le cas unidimensionnel qui corres-pond à d = 1 et = [ 2; 2] R; devient : 8 < : @u @t = G (@ 2 xxu) ujt=0= ' 2 Cl;Lip(R) (1.2) où G( ) = 12( + 2 2) :
Dans le cas où
= diag [ 1; 2; :::; d] : i 2 2i; 2i ; i = 1; 2; :::; d :
la G équation de la chaleur prend la forme : 8 > < > : @u @t = d P i=1 Gi @x2ixiu ujt=0= ' 2 Cl;Lip Rd (1.3)
où Gi( ) = 12( + 2i 2i)et 0 i i sont des constantes données.
On donne maintenant la dé…nition du G mouvement Brownien d dimensionnel.
Dé…nition 1.2.4(G-mouvement Brownien d-dimensionnel ) Un processus (Bt)t 0
à d-dimension dé…ni sur un espace d’espérance sous-linéaire ( ; H,E) est appelé G-mouvement Brownien de dimension d si les propriétés suivantes sont satisfaites :
(i) B0 = 0
(ii) Pour tout t; s 0; l’accroissement Bt+s Bs est N (0; s ) distribué et est
indépendante de (Bt1; :::; Btn) pour tout n2 N et pour toute suite 0 t1 ::: tm t.
Le théorème suivant est dû à Peng [38]
Théorème 1.2.1 Soit eB = Bet
t 0 un processus dé…ni sur un espace d’espérance
sous-linéaire ( ; H,E) tel que : (i) eB0 = 0
(ii) Pour tout t; s 0 les variables aléatoires eBt+s Bet et eBs sont identiquement
distribuées et indépendantes de Bet1; :::; eBtn ; pour tout n 2 N et pour tout suite
0 t1 ::: tm t. (iii) EhBet i = Eh Bet i = 0et limt#0E Bet 3 t 1 = 0:Alors eBest un G [ ; ] mouvement Brownien avec 2 = EhBe12i et 2 = Eh Be12i:
1.2.2
Existence du
G mouvement Brownien
On note par = Cd
0 (R+) l’espace des fonctions ! : R+ ! Rd continues nulles en 0;
muni de la distance !1; !2 = 1 X 2 i i=1 max t2[0;i] ! 1 t ! 2 t ^ 1
Pour tout T 0 …xé, on note T =f!:^T : ! 2 g et on considère le processus
canonique Bt(!) = !t; t2 [0; +1) si ! 2 :
Soit l’espace des variables suivant :
Lip ( T) = ' (Bt1^T; :::; Btn^T) : t1; :::; tn 2 [0; 1) ; ' 2 Cl;Lip R
d
;
Il est clair que Lip ( t) Lip ( T) ; pour tout t T: On pose :
Lip ( ) = 1[
n=1Lip ( n) :
Il es clair que Cl;Lip Rd ; Lip ( T) et Lip ( ) sont des espaces vectoriels. En outre,
notons que; si X; Y 2 Lip ( T)alors X:Y 2 Lip ( T) pour tout '; 2 Cl;Lip Rd :
En particulier, pour tout t 2 [0; +1), Bt 2 Lip ( ) :
Peng [34] a construit une espérance sous-linéaire sur ( ; Lip ( )) de telle sorte que le processus canonique (Bt)t 0soit un G mouvement Brownien de la manière suivante : soit
f ig1i=1 une suite de vecteurs aléatoires à d dimensions sur un espace d’espérance
sous-linéaire ; eH,eE telle que i est G normalement distribuée et i+1est indépendante de
i; :::; i+1 pour i = 1; 2; :::
Ensuite il a introduit une espérance sous linéaire E dé…nie sur Lip ( ) ; via la procé-dure suivante : Pour tout X 2 Lip ( ) de la forme
pour ' 2 Cl;Lip Rd et pour 0 = t0 < t1 < ::: < tm <1; on pose : E ' Bt1 Bt0; :::; Btn Btn 1 = eE h ' pt1 t0 1; :::; p tn tn 1 n i :
Remarque 1.2.4 Pour tout m = 1; 2; :::; on a :
E [jBtjm] = 1 p 2 t +1Z 1 jxjmexp x 2 2t dx et E [ jBtjm] = mE [jBtjm] :
Proposition 1.2.1 [38] Soit (Bt) un G-mouvement Brownien unidimensionnel tel que
B1 d
= N (0; [ 2; 2]) :On a alors pour tout m 2 N
E [jBtjm] = 8 < : 2 (m 1)!! mtm2=p2 si m est impair (m 1)!! mtm2 si m est paire.
1.3
Convergence dans
R
dOn donne un résultat important qui permet de considérer le problème dans un do-maine borné , et lorsque la mesure de tend vers l’in…ni la solution de cette dernière converge vers la solution du problème initial. Ce résultat généralise celui donné par P. Jaillet, D. Lamberton et B. Lapeyre dans [18].
Soit
Tk = inffs 2 [0; T ] : jBsj > kg et uk(t; x) = E (' (x + Bt^Tk))
où ' 2 Cl;Lip Rd satisfait :
dépendant de '. Soit BR = x2 Rd: jxj R :
Lemme 1.3.1 Pour tout R > 0, on a :
lim
k!1(t; x)2[0; T ] Bsup Rju (t; x) uk(t; x)j = 0:
Preuve : On a
ju (t; x) uk(t; x)j E j' (x + Bt) ' (x + Bt^Tk)j 1fTk<T g
En utilisant les propriétés de ', on obtient
j' (x + Bt) ' (x + Bt^Tk)j CjBt Bt^Tkj (1 + jx + Btj m +jx + Bt^Tkjm) C (jBtj + jBt^Tkj) (1 + jx + Btj m +jx + Bt^Tkjm)
de sorte que d’après l’inégalité de Holder et en utilisant les propriétés suivantes
(a + b)p 2p(ap + bp) et (a + b + c)p 3p(ap+ bp+ cp)
pour tout a; b; c 0 et pour tout p 1:
ju (t; x) uk(t; x)j CE 1 2 36 jBtj2+jB t^Tkj 2 1 + (jxj + jBtj)2m+ (jxj + jBt^Tkj) 2m E12 1 fTk<T g
D’après les mêmes arguments on a : E jBtj 2 +jBt^Tkj2 1 + (jxj + jBtj) 2m + (jxj + jBt^Tkj)2m E12 4 jB tj 4 +jBt^Tkj4 :E12 9 1 + (jxj + jB tj) 4m + (jxj + jBt^Tkj)4m 6 2 sup s2[0;T ] b E jBsj4 !1 2 :E12 1 + 24m jxj4m+jBtj4m + 24m jxj4m+jB t^Tkj 4m 6 2 sup s2[0;T ]E jB sj 4 !1 2 : 1 + 24m+1 R4m+ sup s2[0;T ]E jB tj 4m !!1 2 ; de sorte que ju (t; x) uk(t; x)j 6C 0 @6 2 sup s2[0;T ]E jB sj4 !1 2 1 A 1 2 0 @ 1 + 24m+1 R4m+ sup s2[0;T ]E jB tj4m !!1 2 1 A 1 2 E12 1 fTk<T g Comme Bi
s suit une loi N (0; [ 2s; 2s]) pour tout i = 1; 2; :::; d; alors on a d’après
Peng dans [38] E Bsi 4 = p12 2 i 4 s p12 2 i 4 T et E Bsi 4m = 4 (mp 1)! 2 i 4ms2m 4 (m 1)! p 2 i 4mT4m: Il résulte que ju (t; x) uk(t; x)j C:E 1 2 1 fTk<T g
où C < +1 est une constante dépendant uniquement de T; m, d et i:
Pour compléter la preuve, on a besoin de démontrer que
lim
k!1(t; x)2[0; T ] Bsup RE 1fTk<T g = 0
variable aléatoire X, on a :
E (X) = sup
p2P
Ep(X)
où Ep est l’espérance linéaire sous P (pour les détailles voir Peng [36] ; [39]) :
Comme fTk < Tg = ( sup s2[0; T ]jB sj > k ) d [ i=1 ( sup s2[0; T ] Bsi > pk d ) ; alors E 1fTk<T g d X i=1 b E 0 @1( sup s2[0; T ]jB i sj>pkd ) 1 A D’après l’inégalité de Markov on a pour toute probabilité P 2 P
P 0 @1( sup s2[0; T ]jB i sj>pkd ) 1 A Ep sup s2[0; T ]jB i sj ! k p d p dE sup s2[0; T ]jB i sj ! k de sorte que E 0 @1( sup s2[0; T ]jB i sj>pkd ) 1 A p dE sup s2[0; T ]jB i sj ! k :
Soit " > 0; alors il existe s" 2 [0; T ] tel que
sup s2[0; T ] Bsi Bsi" + " et on a E sup s2[0; T ] Bsi ! E Bsi" + " i p s"+ " i p T + " d’où E sup s2[0; T ] Bsi ! i p T ;
et par suite E 1fTk<T g p dT k n X i=1 i
Chapitre 2
Solution explicite de la G-équation
de la chaleur
Dans ce chapitre, En utilisant les travaux de H. Mingshang [28],on rappelle que la G-équation de la chaleur en dimension 1 admet une solution explicite unique. Pour cela en associe à la G-équation de la chaleur une équation di¤érentielle ordinaire.
2.1
Equation di¤érentielle ordinaire liée à la G-équation
de la chaleur
On considère la G-équation de la chaleur suivante : 8 > < > : @u @t 1 2 @2u @x2 + 2 @2u @x2 = 0; u (0; x) = x2n+1; (2.1) où 2 [0; 1], (t; x) 2 [0; 1[ R:
Dans ce chapitre, qui reprend les travaux de H. Mingshang [28] ; on donne la rela-tion entre la solurela-tion de la G équarela-tion de la chaleur (2:1) et la solurela-tion de l’équarela-tion
di¤érentielle ordinaire suivante 8 < : y00 + 2 y00 + xy0 (2n + 1) y = 0; lim t!0+ t n+12y px t = x 2n+1: (2.2)
Dans le cas = 0;l’équation (2:1) est l’équation de Barenblatt (cf. [4] ; [5] et [19]) :
Remarque 2.1.1 Pour 2 ]0; 1] l’équation (2:1) est une équation aux dérivées par-tielles parabolique et G est une fonction convexe ; alors elle admet une solution unique de classe C1;2 (cf. [21] et [48]).
Dans ce qui suit, on note par PW la mesure de probabilité de Wiener sur et
EW l’espérance linéaire correspand de PW:
Le processus canonique fBt: t 0g est le
mouvement Brownien standard sous PW.
Rappelons que la mesure de Wiener est l’unique mesure de probabilités telle que pour tout 0 < t1 < t2 < ::: < tn et pour tout B1; B2; :::; Bn
PW(Bt1 2 B1; Bt2 2 B2; :::; Btn 2 Bn) = Z B1 ::: Z Bn pt1(0; x1) pt2 t1(x1; x2) :::ptn tn 1(xn 1; xn) dx1dx2:::dxn où pt(x; y) = 1 p 2 te (x y)2 2t
Proposition 2.1.1 Pour tout 2 [0; 1[ …xé, on a :
i) E [ (Bt)] sup v 1EW [ (vBt)] ; pour tout 2 Cl;Lip(R) ; :
ii) E Bt2n+1 > 0; pour tout entier n 1:
Preuve : On désigne par u (t; x) := E [ (x + Bt)] et uv(t; x) := EW [ (x + vBt)]
respectivement les solutions de viscosités de l’équation (2:1) et de l’équation uv t(t; x) 1
2v
2uv
D’après le théorème de comparaison pour l’équation aux dérivées partielles parabo-lique (cf. [10]), on obtient (i).
Il résulte, d’après (1:1) ; que
E B12n+1 = E B12 + B1 B1 2 2n+1 = Eh B1 2 i ; où (x)=E x + B1 2 2n+1 : D’après (i) ; on a (x) sup v 1 EW x + vB1 2 2n+1 n X i=0 C2i2n+1x2(n i)EWhB2i1 2 i +n (2n + 1) 2 1 2 x 2n 1:
Par conséquent, on obtient
E B12n+1 = E h B1 2 i EW h B1 2 i n (2n + 1) 2 1 2 EW B 1 2 2n 1
Comme < 1, on obtient E B12n+1 > 0 pour tout entier n 1:
Remarque 2.1.2[34]
Pour toute fonction convexe 2 Cl;Lip(R) (resp. concave) ;
E [ (Bt)] = EW[ (Bt)] resp. E [ (Bt)] = EW[ ( Bt)]
Pour toute fonction paire 2 Cl;Lip(R) ;
Notons que pour toute fonction convexe (resp. concave) ;
u (t; x) := EW [ (x + Bt)] resp. EW [ (x + Bt)]
la solution de l’équation (2:1) :
Remarque 2.1.3 Pour = 1; l’équation (2:1) devient l’équation de la chaleur et la solution est donnée par :
u (t; x) := EW (x + Bt)2n+1 :
On suppose que 2 [0; 1[ et on dé…nit pour tout entier n 0;
gn(x) = n X i=0 (2n + 1)! (2 (n i)!!) (2i + 1)!x 2i+1; et hn(x) = n X i=0 (n + i)! (n i)! (2 (n i)!!) (2i)! C 2n+1 0 + ::: + C 2n+1 n i x 2i: (2.3)
2.2
Théorème d’existence et l’unicité de la solution
Théorème 2.1.1 Pour tout entier n 1; (i) On pose, pour tout 2 ]0; 1[,
Pn (x) = 8 > > > < > > > : gn(x) + (2n)!!kn hn(x) exp x 2 2 gn(x) 1 R x exp t22 dt ; x cn 2n+1g n x +(2n)!!dn " hn x exp x 2 2 2 gn(x) x R 1 exp t22 dt # ; x < cn (2.4) où cn, kn et dn sont des constantes, telles que :
8 > > > > > > > > > > > > > > > > > > < > > > > > > > > > > > > > > > > > > : hn 1 cn + gn 1 cn exp c 2 n 2 2 cn R 1 exp t22 dt = 2n " hn 1(cn) gn 1(cn) exp c2 n 2 1 R cn exp t22 dt # kn = (2n)!!gn 1(cn) hn 1(cn) exp c22n gn 1(cn) 1R cn exp t22 dt dn= gn 1(cn) gn 1(cn) knexp 1 2 2 2 c 2 n cn<0: (2.5) Alors un(t; x) := tn+ 1 2P
n pxt est l’unique solution de l’équation (2:1) :
(ii) On pose, pour = 0;
Pn(x) = 8 > < > : gn(x) + (2n)!!kn hn(x) exp x 2 2 gn(x) 1R x exp t22 dt ; x cn x2n+1; x < c n (2.6) où cn et kn sont des constantes, telles que
8 > > > > > < > > > > > : (2n 1)! = c2n n " hn 1(cn) gn 1(cn) exp c 2 n 2 1 R cn exp t2 2 dt # kn= (2n 1)!!2n gn 1(cn) c2nn exp c2 n 2 cn < 0: (2.7) Alors un(t; x) := tn+ 1 2Pn px
t est l’unique solution de l’équation (2:1) :
Avant de prouver ce théorème, on aura besoin des lemmes suivants :
Lemme 2.1.1 Soit 2 ]0; 1] une constante …xé. Alors on a :
(i) Si u est la solution de l’équation (2:1) ; alors P (x) := u (1; x) 2 C2 est la solution
de (2:2) :
(ii) Si P 2 C2 est la solution de (2:2), alors u (t; x) = tn+12P px
t est la solution de
Preuve : (i)Notons que B1 est G-normalement distribuée, d’où pour t > 0; u (t; x) = E x +ptB1 2n+1 = tn+12E " x p t + B1 2n+1# = tn+12u 1;px t ; On déduit que, u (t; x) = tn+12P px t pour t > 0:
Comme u (0; x) = x2n+1; on obtient, lim
t!0+ t
n+12P px
t = x
2n+1; d’où d’après la
re-marque 2:1:1, P 2 C2:
Il est facile de véri…er que, pour tout t > 0;
@u @t = t n 12 n + 1 2 P x p t x 2ptP 0 x p t ; @2u @x2 = t n 12P00 x p t : (2.8)
En substituant (2:8) dans (2:1), on obtient le résultat. La preuve pour (ii) est similaire à celle de (i).
Remarque 2.1.4 Soit u la solution de viscosité de l’équation (2:1) avec 2 [0; 1] ; alors pout tout (t; x) 2 ]0; 1[ R, ( ) := u (t; x) est une fonction continue et décrois-sante (cf [10] et [34]) :
On résout tout d’abord l’équation (2:2) pour 2 ]0; 1] ; et par la suite grâce au lemme 2:1:1, on obtient la solution correspandante de l’équation (2:1) avec = 0:
Pour cela, on donne les lemmes suivants :
Lemme 2.1.2 Soient 6= 0 et > 0: Si ' (:) est une solution de l’ E:D:O : y00 + xy0 y = 0; alors (x) := ' x est une solution de l’équation 2y00
+ xy0 y = 0:
y (x) = 1gn(x) + 2 2 4hn(x) exp x2 2 gn(x) 1 Z x exp t 2 2 dt 3 5 ; où 1 et 2 sont des constantes arbitraires.
Preuve : D’après lemme 2:1:1 pour = 1, on trouve que yn(x) = EW (x + B1) 2n+1 et byn(x) = p 2 EWh (x + B 1) 2n+1i
sont deux solutions linéairement indépendantes de l’équation y00+ xy0 (2n + 1) y = 0:
On véri…er aisément que
yn(x) = gn(x) et byn(x) = hn(x) exp x2 2 gn(x) 1 Z x exp t 2 2 dt; d’où le résultat.
Lemme 2.1.4 Soit x > 0: Alors pour tout entier n 1; on a :
h0n 1(x) + gn 1(x) gn 10 (x) + xgn 1(x) exp x 2 2 1 Z x exp t 2 2 dt hn(x) gn(x) exp x 2 2 : (2.9) Preuve : On dé…nit mn(x) = p 2 EW h (x + B 1) 2n+1i
; alors d’après le lemme pré-cédent, on a : mn(x) = hn(x) exp x2 2 gn(x) 1 Z x exp t 2 2 dt:
La deuxième inégalité de (2:9) découle du fait que mn(x) 0: Comme la fonction
mn(:)est décroissante, alors m
0
n(x) 0; d’où la première inégalité de (2:9).
h0n 1(x) + gn 1(x) g0n 1(x) + xgn 1(x) exp x 2 2 " 1 Z x exp t 2 2 dt et hn(x) gn(x) exp x 2 2 # 1 Z x exp t 2 2 dt:
de plus, on peut montrer que :
1 Z x exp t 2 2 dt h0n 1(x) + gn 1(x) gn 10 (x) + xgn 1(x) exp x 2 2 < min1 k n (p 2 (2k)!(n k)! x2k23kn! ) ; hn(x) gn(x) exp x 2 2 1 Z x exp t 2 2 dt < min1 k n (p 2 (2k + 1)!(2 (n k) 1)!n! 2kx2(k+1)(2n)! (n k 1)! ) :
Lemme 2.1.5 On pose pour tout n 1 et 2 ]0; 1[ une constante …xé,
fn(x) : = hn 1 x + gn 1 x 2 2 x Z 1 exp t 2 2 dt 2nh n 1(x) + 2ngn 1(x) exp x2 2 1 Z x exp t 2 2 dt;
Alors il existe une constante x0 < 0 telle que fn(x0) = 0:
Preuve : On a :
fn0 (x) := 1(gn 10 x +xgn 1 x ) exp x 2 2 x Z 1 exp t 2 2 dt +1(h0n 1 x + gn 1 x ) 2n h0n 1(x) + gn 1(x) + 2n gn 10 (x) + xgn 1(x) exp x2 2 1 Z x exp t 2 2 dt: Comme x < 0; fn0 (x) > 1(g0n 1 x + xgn 1 x ) exp x 2 2 x Z 1 exp t 2 2 dt +1(h0n 1 x + gn 1 x ):
d’après le lemme 2:1:4; on obtient, fn(x) > 0 pour x < 0; ce qui achève la preuve.
Lemme 2.1.6 Pour tout entier n 1; on a :
lim x!1x 2n 2 4hn 1(x) + gn 1(x) exp x2 2 x Z 1 exp t 2 2 dt 3 5 = (2n 1)!:
Preuve : D’après les expressions de hn et gn; on a :
hn 1(x) gn(x) gn 1(x) hn(x) = (2n 1)!x; hn 1(x) g 0 n 1(x) + xhn 1(x) gn 1(x) h 0 n 1(x) gn 1(x) gn 12 (x) = (2n 1)!
x2n 2 4hn 1(x) + gn 1(x) exp x2 2 x Z 1 exp t 2 2 dt 3 5 (2n 1)!x2n+1 gn(x) ; x2n 2 4hn 1(x) + gn 1(x) exp x2 2 x Z 1 exp t 2 2 dt 3 5 (2n 1)!x2n g0n 1(x) + xgn 1(x) :
quand x ! 1, d’où le résultat.
Preuve du théorème 2.1.1 Pour tout 2 ]0; 1[ …xé, on désigne par Pn (:)la solution de l’équation (2:2) :
On suppose qu’il existe une constante cn< 0 telle que :
8 < : d2 dx2Pn (x) 0 pour x cn d2 dx2Pn (x) 0 pour x cn:
d’après les lemmes 2:1:2 et 2:1:3 et le fait que lim
t!0+t n+1 2P n x p t = x 2n+1; la fonction
Pn (:) admet une expression de la forme (2:4) : Comme Pn 2 C2;il résulte de (2:5) que
lim x!c+n Pn (x) = lim t!cn Pn (x) ; lim x!c+n d2 dx2Pn (x) = 0; lim x!cn d2 dx2Pn (x) = 0:
Soit cn < 0; et soient kn et dn les constantes qui apparaissent dans la formule (2:4) :
On remarque que Pn apparaisant dans les équations (2:4) et (2:5) est de classe C2 et
satisfait les conditions précédentes. Pour x cn
1 (2n + 1) (2n)
d2
= gn 1(x) + kn (2n)!! 0 @hn 1(x) exp x2 2 gn 1(x) 1 Z x exp t 2 2 dt 1 A = EW (x + B1)2n 1 EW h (x + B 1) 2n 1i EW ((c n+ B1)) 2n+1 E W (cn+ B1)2n+1 = EWh (x + B1)+ 2n 1 i EWh (x + B 1) 2n 1i EWh (c n+ B1) 2n 1iE Wh (c n+ B1)+ 2n+1 i : Pour tout x cn; on a : EW h (cn+ B1) 2n 1i EW h (x + B1) 2n 1i ; EW h (cn+ B1)+ 2n 1 i EW h (x + B1)+ 2n 1 i ;
qui entraine que
d2
dx2Pn (x) 0pour tout x cn:
Par la même méthode, on obtient
d2 dx2Pn (x) 0pour x cn: D’après le lemme 2:1:1; un(t; x) = tn+12P n x p t
est une solution de (2:1) ; d’où (i). On pose ln(x) = 1 Z x exp t 2 2 dt hn 1(x) gn 1(x) exp x 2 2 ; x < 0:
On peut prouver que
lim x!0+ln(x) = +1; l 0 n(x) = (2n 1)! g2 n 1(x) exp x 2 2 > 0; x < 0: (2.10) D’après la remarque 2:1:4 on a : u (1; 0) = kn( ) = (2n)!! ln(cn( )) # 0 lorsque " 1;
et grâce à (2:10) ; on obtient cn( )" 0 lorsque " 1:
Par conséquent cn( )
# 1 lorsque # 0; et d’après lemme 2:1:6; on obtient (ii) :
Remarque 2.1.5 Pour tout 2 ]0; 1[ …xé, on a :
E Bt2n+1 =un(t; 0)=kntn+
1 2
où kn est dé…nie dans (2:5) ; il est clair que kn est unique.
En particulier
E Bt3 =kt
3 2
8 > > > > > > > > > > > > < > > > > > > > > > > > > : 1 + c exp 2c22 1 R 1 exp t22 dt = 2 1 c exp c22 1 R c exp t22 dt k = 2c exp c22 c1R c exp t22 dt c < 0 (2.11) Pour = 0 on a : E Bt2n+1 =un(t; 0)=kntn+ 1 2
où kn est la constante dé…nie dans (2:7).
En particulier
E Bt3 =kt
3 2
où k est une constante dé…nie par les équations suivantes :
8 > > > > > > > > > > < > > > > > > > > > > : 1 = c2 c3exp c2 2 1 R c exp t22 dt k = 2c3exp c2 2 c < 0: (2.12)
Chapitre 3
Méthodes itératives de relaxation
par points et par blocs
Le but de ce chapitre est d’introduire les méthodes de relaxations classiques. On donne également la dé…nition et des propriétés d’une M matrice et quelques critères d’inversibilité d’une matrice.
3.1
Critères d’inversibilité d’une matrice
Dé…nition 3.1.1 Une matrice A est diagonale dominante si les conditions suivantes sont véri…ées :
jai;ij
X
j6=i
jai;jj ; 8i 2 f1; ..., dim (A)g
Dé…nition 3.1.2 Une matrice A est diagonale dominante stricte si les conditions suivantes sont véri…ées :
jai;ij >
X
j6=i
Dé…nition 3.1.3 Une matrice A est diagonale fortement dominante si A est dia-gonale dominante et s’il existe au moins un indice k pour lequel l’inégalité :
jak;kj >
X
j6=k
jak;jj ; 8i 2 f1; ..., dim (A)g
est véri…ée.
Dé…nition 3.1.4 Une matrice réelle ou complexe A est réductible s’il existe une ma-trice de permutation P, de même dimension, telle que :
P APt = 0 @ B1;1 B1;2 0 B2;2 1 A
où les matrices Bi;i, pour i = 1; 2, sont des matrices carrées. Si une matrice n’est pas
réductible, elle est irréductible.
Lemme 3.1.1( voir [29]) Une condition nécessaire et su¢ sante pour qu’une matrice A soit irréductible est que, pour tout couple d’indices (i; j), i 6= j, il existe au moins un en-semble d’indices i1; i2; :::; ik (ik= j) ; avec k 1; tels que les éléments ai;i1;ai1;i2;...,aik 1;j
soient tous di¤érents de zéro.
Dé…nition 3.1.5 Une matrice A est diagonale dominante irréductible si A est irréductible et diagonale fortement dominante.
Théorème 3.1.1( voir [29]) Une matrice diagonale dominante irréductible est inver-sible.
Théorème 3.1.2 ( voir [22]) Une matrice à diagonale dominante stricte est inver-sible.
Théorème 3.1.3 Soit A une matrice à diagonale dominante stricte ou à diagonale do-minante irréductible ; si, de plus, ses éléments diagonaux sont strictement positifs, alors :
Re ( i(A)) > 0; 8i 2 f1; 2,...., dim (A)g :
où les nombres i(A) sont les valeurs propres de la matrice A et Re ( i(A)) désigne la
partie réelle des valeurs propres i(A) :
3.2
Dé…nition et propriétés d’une M-matrice
Dé…nition 3.2.1 Une matrice A 2 RM M est dite monotone si A est inversible et
si A 1 0.
Proposition 3.2.1 Une matrice A est monotone si et seulement si Ax 0) x 0:
Dé…nition 3.2.2 Une matrice A 2 RM M est une M-matrice si elle est monotone et si ai;j 0 pour i6= j:
Proposition 3.2.2 Soit une matrice A 2 RM M telle que i) ai;j 0 pour i6= j:
ii) X
1 j M
ai;j > 0 pour i=1,...,M.
Alors A est une M-matrice.
Proposition 3.2.3 Soit une matrice A 2 RM M telle que
i) ai;j 0 pour i6= j;
ii) X
1 j M
ai;j 0 pour i=1,...,M,
iii) A est inversible.
Théorème 3.2.1 Soit A une matrice tel que ai;j 0 pour tout i 6= j. A est une
M-matrice, si et seulement si :
- Les éléments diagonaux ai;i sont strictement positifs
- La matrice de Jacobi J = I D 1A; D diagonale de A; est tel que (J ) < 1:
Théorème 3.2.2 Soit A une matrice strictement ou irréductible diagonale dominante t.q. ai;j 0 dès que i6= j et ai;i > 0. Alors A est une M matrice.
Théorème 3.2.3(Perron-Frobenius, voir [47]) Soit J 0 une matrice irréductible. Alors J possède une valeur propre réelle positive égale à son rayon spectral (J ) ; à (J ) est associé un vecteur propre > 0; (J ) augmente lorsque n’importe quel coe¢ cient de J augmente, (J ) est une valeur propre de multiplicité un de J:
De plus on a la relation suivante
J: v: ; v 2 [ (J) ; 1[
Remarque 3.2.1 La matrice de Jacobi J d’une M matrice A est une matrice non – négative.
Lemme 3.2.1 (voir [6]) Soit A une matrice carrée non-négative ; (A) < 1 si et seulement s’il existe un scalaire positif et un vecteur positif tel que :
A et < 1:
3.3
Méthodes itératives classiques
Les méthodes par points consistent à transformer l’équation AU = F en une équation de point …xe comme suit :
ui = fi X j6=i ai;juj ai;i ;8i
ce qui peut s’écrire matriciellement :
U = BU + c
avec B matrice (d’itération) de même dimension que la matrice A, c vecteur dé…ni par la transformation de point …xe.
Ainsi U0 étant donné, on génère l’itération :
Up+1 = BUp+ c; pour p=0, 1, 2...
Dé…nition 3.3.1 Pour toute matrice carrée A; d’ordre n, on dé…nit (B) par (B) = max
1 i n(j i(B)j) le rayon spectral de la matrice B:
On a le critère général de convergence suivant :
Théorème 3.3.1 On considère l’itération linéaire suivante 8
< :
U0 donné quelconque,
Up+1= BUp+ c; pour p=0, 1, 2... (3.1)
cette itération converge quel que soit U0 si et seulement si (B) < 1:
Dé…nition 3.3.2 On appelle vitesse asymptotique de convergence de l’itération li-néaire (3:1) la quantité dé…nie par E (B) = ln ( (B)) :
Les méthodes classiques de relaxation par points sont dé…nies comme suit ; on consi-dère la décomposition suivante de la matrice A :
où A est une matrice de dimension M; D étant la diagonale, E la partie triangulaire inferieure et C la partie triangulaire supérieure
A = 0 B B B B B B B B B B B B B B B @ : : : : C : : : : D : : : : E : : : : 1 C C C C C C C C C C C C C C C A
La méthode de Jacobi par points : La méthode de Jacobi par points est dé…nie par : up+1i = fi M X j6=i ai;jupj ai;i ;8i , B = J = D 1(E + C) = I D 1A
La méthode de Gauss-Seidel par points : Est dé…nie par :
up+1i = fi i 1 X ai;j j=1 up+1j M X ai;j j=i+1 upj ai;i ;8i , B = L1 = (D E) 1C
La méthode de relaxation par points (SOR : Successive Over-relaxation) : La méthode de relaxation par points est dé…ni par :
8 > > > > > > < > > > > > > : up+ 1 2 i = fi i 1 X ai;j j=1 up+1j M X ai;j j=i+1 upj ai;i up+1i = (1 !) upi + !up+ 1 2 i ; 0 < ! < 2 8i , B = L! = (D !E) 1((1 !) D + !C)
Remarque 3.3.1 Il est à noter que, lorsque le paramètre ! est égal à 1, on retrouve la méthode de Gauss-Seidel par points. Par ailleurs, l’introduction du paramètre ! est destinée à augmenter la vitesse de convergence de l’algorithme, lorsque cela est possible. Pour dé…nir les méthodes de relaxations par blocs on considère un partitionement de la matrice A en blocs, tel que A = (Aij)1 i;j ; et soit un partitionement compatible
des vecteurs F et U de…ni par F = (Fi)1 i et U = (Ui)1 i .
La méthode de relaxation par blocs (SOR) : De manière analogue aux méthodes par points on dé…nit les méthodes de relaxation par blocs, ce qui conduit, dans ce cas, à l’écriture suivante : Ai;i:U p+12 i = Fi X j<i Ai;j:Ujp+1 X j>i Ai;j:Ujp et Uip+1= (1 !) Uip+ !Up+ 1 2 i ; 8i 2 f1; :::; g ; 0<! < 2
pour calculer les composantes Uip+1;il est nécessaire de résoudre un système linéaire du type Ai;iUip+1= Gi:Si l’on utilise une décomposition du type Li:Ribasée sur la
décompo-sition de Gauss de la matrice Ai;i, il su¢ ra d’e¤ectuer une seule fois cette décomposition ;
en e¤et, si l’on stocke les facteurs Li et Ri;il su¢ ra de résoudre Li:RiUip+1= Gi à chaque
itération p:
Remarque 3.3.2 Dans la méthode de relaxation précédente, si ! = 1; on retrouve la méthode de Gauss-Seidel par blocs. La formulation de la méthode de Jacobi par blocs s’écrit comme suit :
Ai;iUip+1= Fi
X
j6=i
Ai;jUjp; 8i 2 f1; :::; g
Théorème 3.3.2 Pour toute matrice A , une condition nécessaire de convergence de la méthode de relaxation par points ou par blocs est que 0 < ! < 2:
Théorème 3.3.3 Soit A une matrice à diagonale strictement dominante ; alors la mé-thode de Jacobi et la mémé-thode de Gauss-Seidel par points convergent.
Théorème 3.3.4 Soit A une matrice à diagonale dominante irréductible ; alors la mé-thode de Jacobi par points et la mémé-thode de Gauss-Seidel par points convergent.
Remarque 3.3.3 Les résultats des théorèmes (3:3:3) et (3:3:4) s’étendent au cas de la méthode de surrelaxation par points pour ! 2 ]0; 1] :
Théorème 3.3.5 Soit une matrice tridiagonale par blocs dont les blocs diagonaux sont inversibles. Si toutes les valeurs propres de A sont réelles, alors les méthodes de Jacobi et de relaxation par blocs, pour 0 < ! < 2, convergent ou divergent simultanément.
Dans le cas de la convergence, il existe une valeur optimale !opt du paramètre !
donnée par : ! = !opt = 2 1 + q 1 ( (J ))2
; (L!) = !opt 1 pour ! = !opt
qui minimise le rayon spectral de la matrice d’itération de relaxation par blocs L! dé…nie
par
L! = (D !E) 1
Chapitre 4
Rappel sur les algorithmes parallèles
Dans ce chapitre nous introduisons les algorithmes parallèles asynchrones pour ré-soudre des systèmes algébriques de grande taille. Un algorithme séquentiel s’exécute sur un ordinateur comportant une seule unité centrale de calcul (où processeur) qui exécute chaque instruction l’une après l’autre. Un algorithme parallèle s’exécute sur une machine comportant plusieurs unités de calcul qui travaillent simultanément sur la même appli-cation. On distingue les algorithmes parallèles synchrones où les processeurs attendent les résultats produits par les autres processeurs pour continuer leur traitement et les algorithmes parallèles asynchrones où les processeurs ne sont pas synchronisés.
On suppose deux processeurs notés P 1 et P 2 collaborent à la recherche du point …xe d’une application F . Les processeurs P 1 et P 2 réactualisent la première et la deuxième composante du vecteur itéré. A…n de mettre en œuvre un schéma itératif de Jacobi parallèle, il est nécessaire de réactualiser les composantes du vecteur itéré suivant un certain ordre et en e¤ectuant certaines synchronisations. Un exemple type déroulement des calculs est donné par la …gure 1 où les rectangles blancs numérotés représente les phases de réactualisation et les rectangles noirs représentent les phases de communication et d’attente, les ‡èches délimitant le commencement et la …n des communications. On constate que la nécessité de respecter un ordre de calcul strict et de synchroniser les processeurs peut engendrer des pertes de temps importantes. Les contraintes d’ordre de
réactualisation et de synchronisation peuvent aller à l’encontre de la recherche de bonnes performances.
Pour illustrer les algorithmes itératifs asynchrones on peut reprende l’exemple simple précédant. Un tupe de déroulement asynchrone des calculs est alors donné par la …gure 2 où les rectangles blancs numérotés représentent les phases de réactualisation et les rectangles noirs les phases de communication. Le numéro d’itération est incrémenté au commencement de chaque nouvelle phase de réactualisation. On note que les rectangles noirs ne contiennent pas de période d’inactivité et que les phases de réactualisation s’enchaînent plus rapidement.
F igure 1 : Algorithme itératif synchrone
4.1
Algorithmes parallèle asynchrones
Les premiers travaux dans ce domaine ont été introduits par D. Chazan et W. Mi-ranker dans [9] ; dans le cadre de la résolution de systèmes algébriques linéaires
Ax = b
où A est une matrice symétrique dé…nie positive, x et b sont des vecteurs de RM:
Ils ont proposé le modèle de résolution suivant :
xp+1i = 8 < : xpi , si i6= s(p) Fi x p r1(p) 1 ; :::; x p r (p) , si i = s(p) (4.1) où A = D E; F (x) = Bx + C; B = C 1E et C = D 1b:
Pour tout p 2 N; on note par xp le vecteur itéré à l’étape p; s (p) 2 f1; :::; g et R =f(r1(p) ; :::; r (p))gp2N est une suite de N véri…ant pour s 2 N :
(a) 0 ri(p) < s 8i 2 f1; :::; g ; 8p 2 N
(b) 8i 2 f1; :::; g l’ensemble fp 2 N; i = s(p)g est in…ni. Ce modèle peut être interprété comme suit :
A chaque relaxation p + 1; seulement la composante s(p) mise à jour, les autres composante restent inchangées ; la condition (a) a¢ rme que les retards ri(p) dus aux
communications entre processeurs est aux di¤érents calculs sont bornés et la condition (b) signi…e qu’aucun composante n’est abandonnée dé…nitivement théoriquement i.e on doit réactualiser chaque composante une in…nité de fois. Chazan et Miranker ont établi le théorème suivant :
Théorème 4.1.1(Voir [9]) La suite fxp
gp2N converge vers x point …xe de l’équation de point …xe x = F (x) si et seulement si (jBj) < 1; où jBj est la matrice dont les éléments sont les valeurs absolues de B; (jBj) le rayon spectrale de la matrice jBj :
Par la suite F. Robert [40] et [41] a étendu ce résultat dans le cas de systèmes non linéaires dans une situation où les processeurs communiquent entre eux de manière synchrone. J.C. Miellou dans [24] et [27] a étendu ces études dans une situation où les processeurs communiquent entre eux de manière asynchrone avec une retard bornés. En 1978, G. Baudet dans [6] à généralisé les itérations chaotiques de D. Chazan et W. Mi-ranker et J.C. Miellou au cas des itérations asynchrones où les retards peuvent être non bornés. Dans [6] ; [9] ; [12] ; [24] et [40] l’étude de la convergence est e¤ectuée par des techniques de contraction. Les travaux de J.C Miellou et P. Spitèri [25] et L. Girand et P. Spitèri [14] donnent des critères de convergence en norme vectorielle des itérations asynchrones. M. N. El tarazi dans [12] a également établi un résultat de convergence des algorithmes asynchrones par des techniques de contractions en norme scalaire convenable. Bahi dans [2] a donné un résultat de convergence concernant les algorithmes parallèles asynchrones ou synchrones pour des systèmes linéaires de points …xe utilisant des opé-rateurs non-expansifs relativement à une norme uniforme avec poids. Le modele général proposé par G. Baudet dans [6] est le suivant :
xp+1i = 8 < : xpi , si i =2 s(p) Fi x 1 (p) 1 ; :::; x (p) , si i2 s(p); 8i 2 f1; :::; g (4.2)
Nous rappelons quelques dé…nitions importantes concernant la stratégie s(p) et la suite de retards R =fr1(p) ; :::; r (p)g.
Dé…nition 4.1.1 Une stratégie S est une suite (s(p))p2N de partie non vides de f1; :::; g satisfaite :
8i 2 f1; :::; g ; fp 2 N j i 2 s(p)g est un ensemble in…ni.
8p 2 N; (p) = 1(p); :::; (p) 2 N telle que i(p) = p ri(p) 8i 2 f1; :::; g ; 8p 2 N; 0 i(p) p; 8i 2 f1; :::; g ; lim p!1 i(p) = +1:
Remarque 4.1.1 La notion de stratégie correspond aux numéros des composantes sur lesquelles on relaxe ; à l’itération p on traitera en parallèle les composantes dont les numéros appartiennent à s (p). La suite de retards rend compte de la disponibilité des données, ce qui permet de modéliser l’absence de synchronisation entre les processeurs ainsi que les retards dus aux temps de latence des communications.
4.2
Algorithmes parallèle synchrones
Lorsque les retards ri(p) ; i = 1; :::; ; sont identiquement nuls, la formulation (4:2)
correspond alors aux algorithmes de relaxation synchrones [41] :
Remarque 4.2.1 L’algorithme (4:2) caractériser une méthode de calcul où les commu-nications entre les processeurs peut être synchrone ou asynchrone. On obtient donc les méthodes parallèle synchrones, lorsque (p) = p;8p 2 N ;
En outre, si : s(p) = f1; :::; g et (p) = p; 8p 2 N, i.e. S = ff1; :::; g; :::; f1; :::; g; :::g alors (4:2) modélise la méthode séquentielle de Jacobi par blocs.
Tandis que si :
s(p) = p:mod( )+1 et (p) = p;8p 2 N, i.e. S = ff1g; f2g; :::; f g; f1g; f2g; :::; f g; :::g alors (4:2) modélise la méthode séquentielle de Gauss - Seidel par blocs.
Si : de plus S = ff1g; f2g; :::; f g; f g; f 1g; :::; f1g; f1g; f2g; :::; f g; f g; :::; f1g; :::g et (p) = p;8p 2 N, alors (4:2) décrit la méthode des directions alternée (ADI).
4.3
Rappels sur la notion d’accrétivité
Pour analyser la convergence des algorithmes asynchrones et synchrones et obtenir ainsi des conditions su¢ santes de convergence liées aux propriétés des opérateurs à in-verser, nous rappelons la notion d’opérateur accrétif [3].
E étant un espace de Banach, soit E son dual topologique ; on note respectivement j:j et j:j les normes dé…nies sur E et E et h ; i la forme bilinéaire qui met en dualité E et E :
Dé…nition 4.3.1 On appelle opérateur de dualité G associé à E l’opérateur E vers E dé…ni par :
8X 2 E ; G (X) = g 2 E j jgj = jXj ; hX; gi = jXj2 :
Remarque 4.3.1 On montre que l’opérateur de dualité est le sous di¤érentiel de la demie-norme au carré.
Soit A un opérateur de D (A) à valeurs dans E:
Dé…nition 4.3.2 A est un opérateur fortement accrétif si :
8 (X; Y ) 2 D (A)2;9 g 2 G (X Y ) et 9 c 2 R+ tels que :
hA (X) A (Y ) ; gi cjX Yj2:
Remarque 4.3.2 Si c est nul l’opérateur A est un opérateur accrétif ; si de plus l’in-égalité est stricte, l’opérateur A est strictement accrétif.
Remarque 4.3.3 Cette notion d’accrétivité généralise au cas des espaces de Banach la notion d’opérateur monotone dans les espaces de Hilbert. En e¤et dans le cas où E est un espace de Hilbert, E étant identi…é à son dual, alors on véri…é aisément que :
g = X Y si X 6= Y
et les notions d’accrétivité et de monotonie coïncident [7] :
Proposition 4.3.1 -Une condition nécessaire et su¢ sante pour qu’une matrice A soit fortement accrétive dans Rn
muni de la norme euclidienne j:j2;est que A soit une matrice
fortement dé…nie positive, i.e. qu’il existe un réel positif c tel que :
hAX; Xi cjXj22; 8X 2 Rn; X 6= 0 :
Proposition 4.3.2 Une condition nécessaire et su¢ sante pour que la matrice A soit fortement accrétive dans Rn muni de la norme l
1; qu’il existe un réel positif c tel que
pour tout i 2 f1; :::; ng : aii c; aii n X j=1;j6=i
jaijj c (diagonale strictement dominante par colonne) :
Proposition 4.3.3 Une condition nécessaire et su¢ sante pour que la matrice A soit fortement accrétive dans Rn muni de la norme l
1, qu’il existe un réel positif c tel que
pour tout i 2 f1; :::; ng : aii c; aii n X j=1;j6=i
jajij c (diagonale strictement dominante par ligne) :
Remarque 4.3.3 -Une condition nécessaire et su¢ sante pour que la matrice A soit accrétive dans Rn
muni de la norme euclidienne j:j2; est que A soit une matrice
-Une condition nécessaire et su¢ sante pour que la matrice A soit accrétive dans Rn
muni de la norme l1; est que :
Les coe¢ cients diagonaux de la matrice A soient non négatifs ; La matrice A soit à dominance diagonale en colonne, i.e. :
aii
n
X
j=1;j6=i
jaijj ; 8i 2 f1; :::; ng
-Une condition nécessaire et su¢ sante pour que la matrice A soit accrétive dans Rn
muni de la norme l1; est que :
Les coe¢ cients diagonaux de la matrice A soient non négatifs ; La matrice A soit à dominance diagonale en ligne, i.e. :
aii
n
X
j=1;j6=i
jajij ; 8i 2 f1; :::; ng
Remarque 4.3.4 A étant une matrice dé…nie positive on peut véri…er par un raison-nement de compacité très simple qu’il existe un nombre c, strictement positif, tel que :
hAX; Xi cjXj22; 8X :
où c correspond à la valeur minimale de J (Y ) = hAY; Y i avec jY j2 = 1:
4.4
Dé…nitions et théorèmes de convergence
Dans cette section, on rappelle quelques dé…nitions et théorèmes de convergence don-nées par J.C.Miellou [24] et [27] :
Notations et dé…nitions : Soit E un espace de Banach et un entier naturel, et soit fEig pour i 2 f1; :::; g, une famille d’espaces de Banach, de normes respectives k:ki:
Nous notons par Je le rayon spectral de la matrice eJ . Nous considérons sur E = Y
i=1
Ei;la norme vectorielle canonique q; qui à V = f:::; Vi; :::g 2
E; fait correspondre q (V) = f:::; kViki; :::g :
Soit F une application, non linéaire en général de D (F ) E;à valeurs dans D (F ) E; telle que :
D (F )6= ? (4.3)
où ? est l’ensemble vide.
Compte tenu de la décomposition de E, on peut considérer celle de F dé…nie par :
F (X) =fF1(X) ; :::; Fi(X) ; :::; F (X)g
Dé…nition 4.4.1 u étant un élément …xé de D (F ) ; si F et eJ véri…ent la condition suivante :
q (F (u) F (V)) J q (uf V) ; 8V 2D (F ) :
nous dirons que eJ est une majorante linéaire en u, pour la norme vectorielle q; de F:
Dé…nition 4.4.2 Nous dirons que F est contractante en u, pour la norme vectorielle q; si :
q (F (u) F (V)) J q (uf V) ; 8V 2D (F )
où eJ est non négative, et J < 1; ee J sera dite alors matrice de contraction de F en u.
Dé…nition 4.4.3 Si F et eJ véri…ent la condition :
![Figure 3. Décomposition du domaine [0; 1] 3 par trois sous-domaines.](https://thumb-eu.123doks.com/thumbv2/123doknet/2026456.3805/76.918.320.664.150.492/figure-decomposition-domaine-domaines.webp)