Tests de type fonction caractéristique en inférence de copules
Texte intégral
Figure
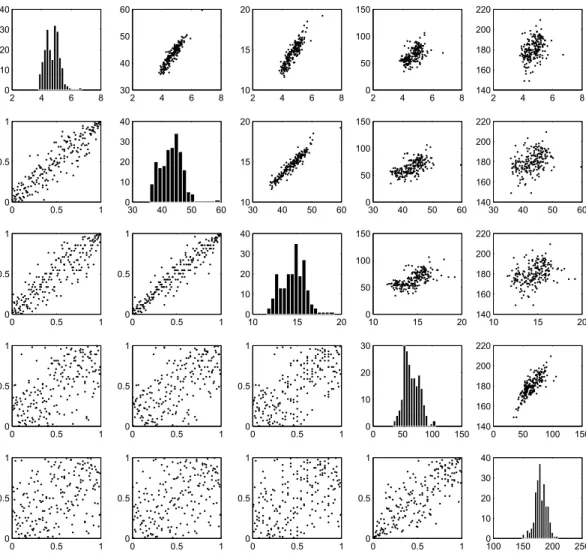

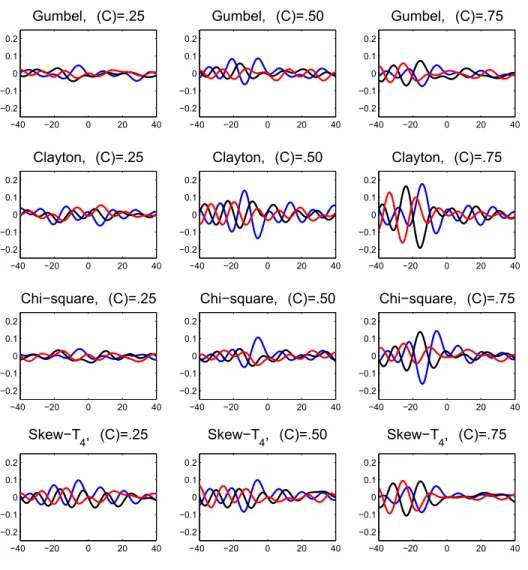
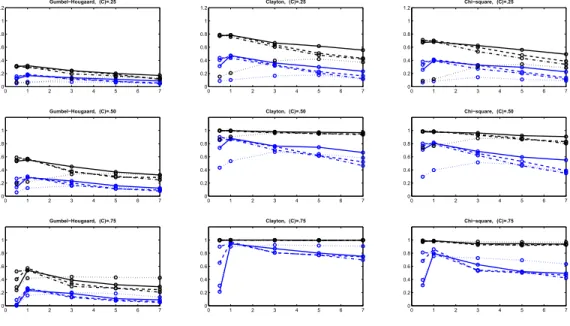
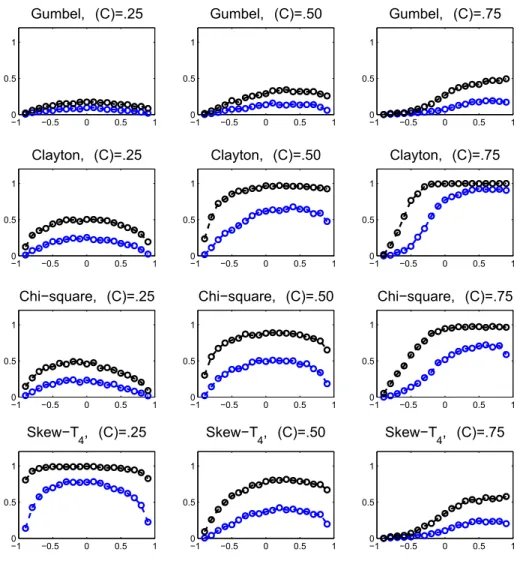



Documents relatifs
On suppose qu'il eectue 10 6 opérations élémentaires suc- cessives, que les erreurs commises pour chacune sont indépendantes, de loi uniforme sur [−1/2 10 −J , 1/2 10 −J ] et
dans le monde de (H 0 ) (les pots de glace ne présentent pas de risque d’intoxication), on peut se tromper en choisissant (H 1 ) et en disant que la glace peut être dangereuse pour
la fonction f admet alors une infinité de
In this case the statistic h(g(T n )) extends the notion of log-likelihood ratio and the test based on this statistic is asymptotically equivalent to first order to robust versions
weighted empirial harateristi funtion (PWECF), introdued reently in Meintanis et
De mani`ere g´en´erale, on d´efinit le niveau (ou seuil) d’un test comme P (rejeter H 0 | H 0 vraie), la probabilit´e de rejeter l’hypoth`ese nulle dans le cas o` u elle est
A multivariate Gamma model using Gaussian copula is proposed and its performances are evaluated for texture classification. The experiments results show that the
We propose multivariate parametric and nonparametric (distribution-free) tests for the hypothesis of elliptical symmetry (with respect to some specified location θθθ) which (based on
