Near-Duplicate Video Detection Based on an Approximate Similarity Self-Join Strategy
Texte intégral
Figure
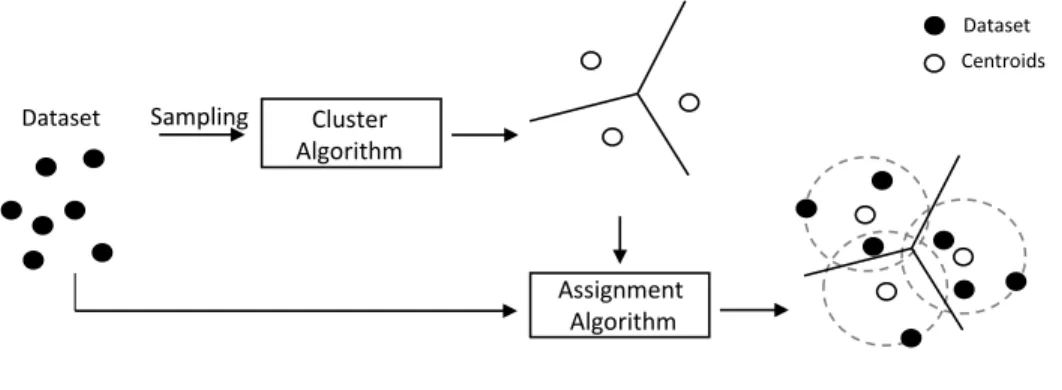

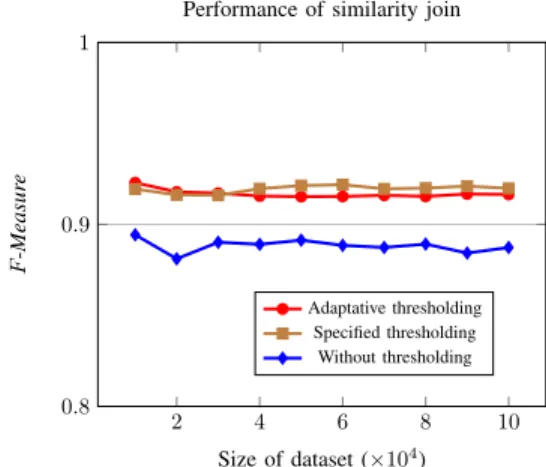
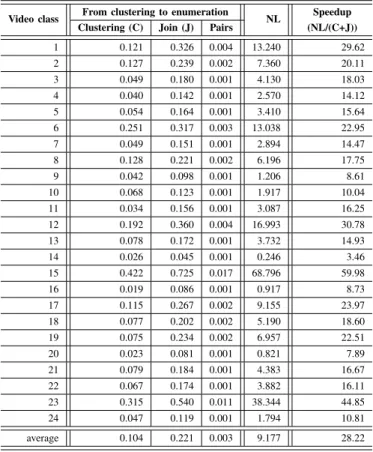
Documents relatifs
Unit´e de recherche INRIA Rennes, Irisa, Campus universitaire de Beaulieu, 35042 RENNES Cedex Unit´e de recherche INRIA Rh ˆone-Alpes, 655, avenue de l’Europe, 38330 MONTBONNOT
Unité de recherche INRIA Rennes : IRISA, Campus universitaire de Beaulieu - 35042 Rennes Cedex (France) Unité de recherche INRIA Rhône-Alpes : 655, avenue de l’Europe - 38334
We benefit from the information already exchanged by OLSR, and identify a number of mechanisms through which a node may detect a conflict between the ad- dress assigned to one of
The group Γ is called fractal (respectively freely fractal) if Γ admits a faithfull (respectively free) fractal action on some A ω.. 2 Rational points of
In this work, we introduce the use of the Campana- Keogh distance, a video compression-based measure, to compare musical items based on their structure.. Through extensive
More specifically, we use the Sorted Neighborhood Method (SNM) to consider only candidate pairs [16] within a window of size 3 (value chosen based on experience). As sorting keys,
After deriving some basic properties of the self-similar profiles in Section 3.1, we split the analysis in three parts and study first even profiles in Section 3.2 after turning
In the second step, short video sub-sequences, represented by video symbols computed from the video database, are stored into a hash index video database, and for a query video
