A Parallel General Game Player
Texte intégral
Figure
Documents relatifs
We study two search algorithms: Monte-Carlo Tree Search For Paraphrase Generation (MCPG) and Pareto Tree Search (PTS) that we use to explore the huge sets of candidates generated
The baseline game tree search algorithms that we use to establish PP ’s value are Monte Carlo Tree Search ( MCTS ) Solver [34] which was recently used to solve the game of havannah
We propose an alternative Monte Carlo Tree Search algorithm: Sequential Halving applied to Trees (SHOT).. It has multiple advantages over UCT: it spends less time in the tree, it
In this thesis, we propose to apply bandit models and Monte Carlo Tree Search to explore the search space of possible rules using an exploration- exploitation trade-off, on
In this thesis, we propose to apply bandit models and Monte Carlo Tree Search to explore the search space of possible rules using an exploration- exploitation trade-off, on
Other algorithms memorize the search tree in memory and expand it with a best first strategy: Proof Number Search [2], PN 2 [4], Depth-first Proof Number Search (Df-pn) [17],
Monte-Carlo Tree Search (MCTS) is a best-rst search method based on random sampling by Monte-Carlo simulations of the state space of a domain [12, 17]. In game play, this means
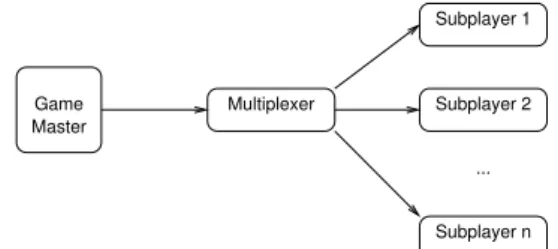
As the Tree parallelization of Monte-Carlo Tree Search works well when playouts are slow, it is of interest for General Game Play- ing programs, as the interpretation of
