Ministère de l’Enseignement Supérieur et de la Recherche Scientifique
Université des Sciences et de la Technologie d’Oran -Mohamed Boudiaf – USTO-MB
Faculté des Sciences Département d’Informatique
Mémoire pour obtenir le diplôme de Magister Présenté par
HOUACINE Abdelkrim
Intitulé
Soutenu le : / / 2011
Devant le jury composé de:
Présidente Mme. BELBACHIR Hafida Professeur (USTO)
Rapporteur Mr. BELKADI Khaled Maître de conférences A (USTO) Examinatrice Melle. NOUREDDINE Myriam Maître de conférences A (USTO) Examinateur Mr. RAHAL Sid Ahmed Maître de conférences A (USTO)
Novembre 2011
Système Immunitaire Artificiel Parallèle
appliqué aux Flow Shop Hybride (FSH)
Remerciements
Merci mon Dieu de m’avoir dressé et éclairé un chemin vers la réussite…
Je remercie tout particulièrement mon encadreur, Mr BELKADI KHALED, responsable du laboratoire
LIMEPS (Laboratoire d’Informatique, Modélisation et Evaluation des Performances des Systèmes), pour m’avoir proposé ce sujet, et à qui je voudrais exprimé ma profonde gratitude, pour sa disponibilité et ses encouragements.
Mes remerciements vont également à Mme H.BELBACHIR responsable de la Post-graduation
«systèmes, réseaux et bases de données » pour m’avoir donné l’occasion de faire partie de la dite option et pour m’avoir fait l’honneur de présider le jury de thèse de magister.
Je remercie vivement tous les membres du jury, qui m’ont fait l’honneur de lire et de juger notre travail : Mr. S.RAHAL maître de conférences à l’USTO
Melle. M .NOUREDDINE maître de conférences à l’USTO
Mes remerciements vont particulièrement à tous mes collègues de la post-graduation «systèmes, réseaux
et bases de données » en particulier, Khaled Ben Ali, Amine Mahmoudi, Houari Benyettou et Kateb
Ameur …
Je remercie aussi, Mr Belkhira Sid Ahmed Hichem, pour donner le courage de réaliser ce travail.
Table des matières
Introduction générale
……… 1Chapitre I : Généralités
1.1 Introduction……….. 31.2 Les systèmes de production ……… 3
1.2.1 La disposition des lignes de production ……… 4
1.2.1.1 La disposition produit ……….……….... 4
1.2.1.2 La disposition Processus ……… 4
1.2.1.3 La disposition cellulaire ……… 4
1.2.1.4 La disposition fixe ……….. 4
1.2.2 Les différents types d’ateliers ……….. 4
1.3 Présentation du problème ……….. 5
1.3.1 Ordonnancement dans les systèmes de production ……….. 5
1.3.2 L’atelier de type Flow Shop Hybride (FSH) ………. 6
1.3.2.1 La configuration du système Flow Shop Hybride ……….. 6
1.3.2.2 Une notation pour le problème FSH ………... 7
1.3.2.3 Les différents types du FSH ……… 9
1.3.2.4 La résolution du problème d’ordonnancement dans le système FSH ………. 10
1.3.2.4.1 Problèmes NP_Difficiles..……….. 10
1.3.2.4.2 Codage de la solution ……… 11
1.3.2.4.3 La complexité du Système FSH ……… 12
1.4 Les méthodes de résolution du problème d’ordonnancement de type FSH ……… 13
1.4.1 Méthodes de résolution exactes ………... 13
1.4.1.1 Branch & Bound ………. 14
1.4.2 Résolution approchée ……… 14
1.4.2.1 Métaheuristiques à solution unique ………. 15
1.4.2.1.1 La descente ……….. 15
1.4.2.1.2 Le Recuit simulé ……….. 15
1.4.2.1.3 La recherche tabou ……….. 16
1.4.2.2 Métaheuristiques à base de population ………. 16
1.4.2.2.1 Colonies de fourmis ……….. 17
1.4.2.2.2 Les algorithmes génétiques ……….. 17
1.4.2.3 Les métaheuristiques avancées ……….. 18
1.4.2.3.1 Les algorithmes mémétiques ………. 19
1.4.2.3.2 La recherche dispersée (Scatter Search) ……… 19
1.4.2.3.3 Algorithme génétique avec gestion de population (GA/PM) ………. 20
1.4.2.3.4 Algorithme mémétique avec gestion de population (MA/PM) ……….. 21
1.4.2.3.5 Métaheuristique électromagnétique ……….. 22
Chapitre II : Les Systèmes Immunitaire Artificiel
2.1 Introduction ……….. 24
2.2 Le système immunitaire Naturel ………... 24
2.2.1 Introduction ……… 24
2.2.2 Composantes de l’immunité ………..……… 25
2.2.2.1 L’immunité naturelle …………..……… 25
2.2.2.2 L’immunité acquise ……..……… 25
2.2.3 Détection des antigènes ……….. 26
2.2.3.1 Le récepteur des lymphocytes B (BCR) ……… 27
2.2.3.2 Le récepteur des lymphocytes T (TCR) ……… 28
2.2.4 Mécanisme de la détection du soi et du non soi ………. 28
2.2.4.1 La sélection positive ……….. 28
2.2.4.2 La sélection négative de lymphocytes B (La délétion clonale) ………. 28
2.2.4.3 La sélection négative de lymphocytes T ……… 28
2.2.5 La théorie de la sélection clonale ……… 29
2.2.6 La théorie des réseaux immunitaires (idiotypique) ……… 31
2.2.7 La théorie du danger ……… 31
2.3 Le système immunitaire artificiel ……… 32
2.3.1 Introduction ……… 32
2.3.2 Représentation des différents mécanismes ………. 33
2.3.2.1 Affinité ……… 33
2.3.2.2 Génération des récepteurs ……… 34
2.3.2.3 La sélection positive ……… 35
2.3.2.4 La sélection négative ……….. 35
2.3.2.5 La sélection clonale ……… 36
2.3.3 Modèle des réseaux immunitaires ……… 38
2.3.4 La théorie du danger ……… 39
2.4 Conclusion ……… 39
Chapitre III :
Développement de l’algorithme immunitaire artificiel pour le problème du FSH 3.1 Introduction ………. 403.2 Le système immunitaire artificiel (AIS) ………. 40
3.2.1 Le principe de la sélection clonale ……….. 40
3.2.2 La maturation d’affinité ……….. 41
3.3 L’approche AIS proposée ……… 42
3.3.1 Algorithme ……….. 42
3.3.2 Le processus de la sélection clonale dans l’algorithme ………... 45
3.3.3 Le processus de la maturation d’affinité dans l’algorithme ……….. 46
3.3.3.1 La mutation ………. 46
3.3.3.2 La génération des récepteurs ……… 47
Chapitre IV :
L’Algorithme immunitaire artificiel Parallèle pour le problème du FSH4.1 Introduction ………. 48
4.2 Les architectures parallèles ………. 48
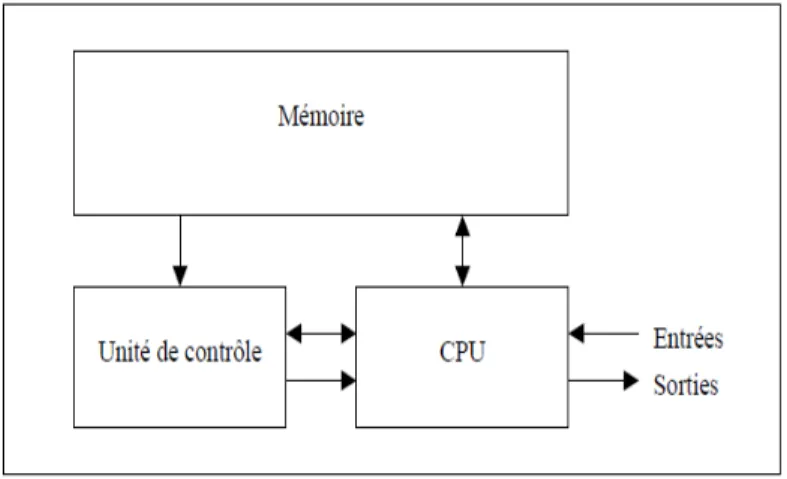
4.2.1 Structure d’un ordinateur séquentiel conventionnel ……… 48
4.2.2 Classification des architectures parallèles ……… 49
4.3 Le parallélisme et les métaheuristiques ……….. 52
4.3.1 Classification des métaheuristiques parallèle ……… 52
4.3.1.1 La première dimension ………. 52
4.3.1.2 La deuxième dimension ……… 53
4.3.1.3 La troisième dimension ………. 53
4.3.2 Stratégies de parallélisme ……… 53
4.3.2.1 Parallélisme de bas niveau ……….. 53
4.3.2.2 Décomposition explicite du domaine ou l’espace de recherche ……… 55
4.3.2.3 Recherches multiples indépendantes ……… 56
4.3.2.4 Recherches multiples coopératives ……….. 56
4.4 Parallélisation de l’Algorithme immunitaire artificiel ……… 57
4.4.1 Les paramètres de migration ……….. 57
4.4.1.1 Nombre de sous populations ……… 57
4.4.1.2 La topologie d’interconnexion ……… 58
IV.4.1.2.1 La topologie grille à deux dimensions ……… 58
IV.4.1.2.2 La topologie Anneau ……….. 58
4.4.1.3 Stratégie de choix pour le remplacement des Anticorps ………. 58
IV.4.1.3.1 La stratégie aléatoire ……… 59
IV.4.1.3.2 La stratégie bon/mauvais ……… 59
4.4.1.4 La fréquence de migration ……….. 59
4.4.2 Présentation de l’Algorithme immunitaire artificiel Parallèle avec migration ……… 59
4.5 Conclusion ……….. 60
Chapitre V :
Implémentation et mise en oeuvre
V.1 Introduction ………. 61V.2 L’algorithme immunitaire artificiel séquentiel ………. 61
V.2.1 Paramètres de tests ……….. 61
V.2.2 Problèmes de tests ……….. 61
V.2.3 Analyse ………. 62
V.3 L’algorithme immunitaire artificiel Parallèle ……… 69
V.3.1 Paramètres de tests ………. 69
V.3.1.1 Influence de la stratégie du choix de remplacement ………. 70
V.3.1.2 Influence du nombre de sous populations ………. 71
V.3.1.3 Influence de la fréquence de migration ………. 73
V.3.1.4 Comparaison entre l’algorithme parallèle et l’algorithme séquentiel ………. 75
V.4 Conclusion ………. 76
Conclusion générale
……….. 77Liste des figures
Chapitre I : Généralités
Figure 1.1: Organisation en Flow Shop ………. 6
Figure 1.2: Le schéma d’un atelier de type FSH ……….. .……… 6
Figure 1.3 : Positionnement du problème du FSH parmi les autres organisations ……… 7
Figure 1.4 : Schéma d’un FSH avec stocks intermédiaire………. 8
Figure 1.5 : FSH avec stock inter étages pour chaque machine……… 9
Figure 1.6 :FSH avec stock inter étages et un stock pour chaque machine en entrée……… 9
Figure 1.7:FSH avec un stock unique en entrée et des stocks inter étage propre à chaque machine……… 9
Figure 1.8 : FSH avec un stock unique en entrée et unique entre les étages……… 9
Figure 1.9 : FSH avec un stock en entrée propre à chaque machine et pas de stock inter 10 Figure 1.10 : FSH avec un stock unique en entrée et pas de stock inter 10 Figure 1.11 : Diagramme de Gantt………. 12
Chapitre II : Les Systèmes Immunitaire Artificiel Figure2.1 : Structure de base d'une Lymphocyte T ………... 26
Figure2.2 : Structure de base d'une immunoglobuline ……….. 27
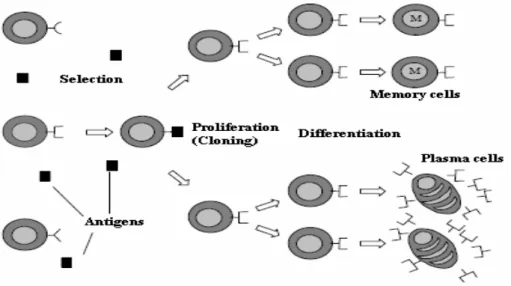
Figure 2.3: Une simple idée du processus de la sélection clonale………. 30
Figure 2.4: Le processus de la sélection clonale et la sélection négative ………. 30
Figure 2.5: Sélection de segment dans des librairies pour former un anticorps……… 34
Figure 2.6: Algorithme de la sélection clonale……….………. 37
Figure 2.7: Représentation schématique de l’évolution de l’algorithme de la sélection clonale ……….……….. 38
Chapitre III : Développement de l’algorithme immunitaire artificiel pour le problème du FSH Figure 3.1: Principe de la sélection clonale………. 41
Figure 3.2 : Structure d’un FSH4:FH2 (P2, P3) ||Cmax ...………..…… 42
Figure 3.3: Organigramme de l’Algorithme ………...….. 43
Figure 3.4: Le processus de la mutation large ………. 46
Figure 3.5: Le processus de la mutation simple……….. 46
Chapitre IV : L’Algorithme immunitaire artificiel Parallèle pour le problème du FSH Figure 4.1: Architecture d’un ordinateur séquentiel conventionnel ……… 49
Figure 4.2: Structure SIMD ………... 50
Figure 4.3: Structure MIMD ………. 51
Figure 4.4: Schéma de l’organisation d’une machine à mémoire partagée……… 51
Figure 4.5: Schéma de l’organisation d’une machine à mémoires distribuées………. 51
Figure 4.6: Parallélisme Bas Niveau ………... 54
Figure 4.7: Configuration en Maitre-Esclave………. 54
Figure 4.8: Décomposition de l’espace de recherche ………. 55
Figure 4.9: Décomposition de l’espace de recherche – l’Algorithme Maître ……… 56
Figure 4.10: Topologie Anneau………... 58
Figure 4.11: Algorithme exécuter par le maître pour PAIS_MIG……… 59
Figure 4.12: Algorithme exécuter aux niveaux des esclaves PAIS_MIG ……….. 60
Chapitre V : Implémentation et mise en œuvre Figure 5.1: Structure d’un FSH4:FH2 (P3, P2) ||Cmax ………. 61
Figure 5.2: Structure d’un FSH4:FH3 (P4, P2, P3) ||Cmax ……….. 62
Figure 5.3: Graphe de variation de la moyenne du Cmax Avec l’augmentation du Tauxde mutation. FSH4 :FH2(P3,P2)………. 62
Figure 5.4 :Graphe de variation de la moyenne du Cmax Avec l’augmentation du Taux de mutation FSH4:FH3(P4,P2,P3) ……… 63
Figure 5.5 : Graphe de variation de la moyenne du temps CPU Avec l’augmentation du Taux de mutation. FSH4 :FH2(P3,P2)………. 63
Figure 5.6 : Graphe de variation de la moyenne du temps CPU Avec l’augmentation du Taux de
mutation.FSH4 :FH3(P4,P2,P3)………. 64
Figure 5.7 : Graphe de variation de la moyenne du Cmax Avec l’augmentation du Taux de remplacement
FSH4 :FH2(P3,P2)……….……. 65
Figure 5. 8 : Graphe de variation de la moyenne du Cmax Avec l’augmentation du Taux de remplacement.
FSH4 :FH3(P4,P2,P3)……….… 65
Figure 5.9 : Graphe de variation de la moyenne du temps CPU Avec l’augmentation du Taux de remplacement.
FSH4:FH2 (P3, P2)……… 66
Figure 5.10 : Graphe de variation de la moyenne du temps CPU Avec l’augmentation du Taux de remplacement.
FSH4 :FH3(P4,P2,P3)………..…… 66
Figure 5.11 : Graphe de variation de la moyenne du Cmax Avec l’augmentation de la fréquence de génération
pour le remplacement.FSH4 :FH2(P3,P2)………..………. 67 Figure 5.12 : Graphe de variation de la moyenne du Cmax Avec l’augmentation de la fréquence de génération
pour le remplacement.FSH4 :FH3(P4,P2,P3)………..……… 68
Figure 5.13 : Graphe de variation de la moyenne du temps CPU Avec l’augmentation de la fréquence de
génération pour le remplacement. FSH4 :FH2(P3,P2) ………... 68
Figure 5.14 : Graphe de variation de la moyenne du temps CPU Avec l’augmentation de la fréquence de
génération pour le remplacement. FSH4 : FH3(P4,P2,P3)………... 69
Figure 5.15 : Variation de la moyenne du Cmax pour différentes stratégies du choix……….. 70
Figure 5.16 : Variation de la moyenne du Cmax avec l’augmentation du nombre de sous populations- N=5 ……… 71
Figure 5.17:Variation de la moyenne du Cmax avec l’augmentation du nombre de sous populations N=10………… 71
Figure 5.18 : Variation de la moyenne du Cmax avec l’augmentation du nombre de sous populations- N=15…….. 72
Figure 5.19 : Variation de la moyenne du Cmax avec l’augmentation du nombre de sous populations- N=20 …….. 72 Figure 5.20 : Variation de la moyenne du Cmax avec l’augmentation de la fréquence de migration - N=5 ………... 73
Figure 5.21 : Variation de la moyenne du Cmax avec l’augmentation de la fréquence de migration - N=10 ………. 73
Figure 5.22 : Variation de la moyenne du Cmax avec l’augmentation de la fréquence de migration - N=15 ………. 74
Figure 5.23 : Variation de la moyenne du Cmax avec l’augmentation de la fréquence de migration - N=20 ………. 74
Liste des tableaux
Chapitre I : Généralités
Tableau 1.1 : Ordonnancement et affectation des Jobs sur les machines des différents étages….………… 11
Tableau 1.2 : Combinatoire de temps de calcul estimé pour le FH2 (P3, P2)….………... 13
Chapitre II : Les Systèmes Immunitaire Artificiel
Sigles et Abréviations
AIS : Le système immunitaire artificiel. FSH : Flow Shop Hybride.
PAIS_MIG : L’algorithme immunitaire artificiel parallèle avec migration. Th : Les lymphocytes T helper.
Tc : Les lymphocytes T cytotoxiques. NK : Natural Killer.
CPA : Les Cellules Présentatrices d'Antigène CMH : Complexe Majeur d'Histocompatibilité BCR : Le récepteur des lymphocytes B
Ig : Les immunoglobulines. Ac : Anticorps
TCR : Le récepteur des lymphocytes T
La fonction ordonnancement vise à organiser l’utilisation des ressources technologiques et humaines présentes dans les ateliers ou les services de l’entreprise pour satisfaire soit directement les demandes des clients, soit les demandes issues d’un plan de production préparé par la fonction de planification de l’entreprise.
Compte tenu de l’évolution des marchés et de leurs exigences, cette fonction doit organiser l’exécution simultanée de multiples travaux sur des délais de réalisation de plus en plus courts, à l’aide de ressources plus ou moins polyvalentes disponibles en quantités limitées. Ceci constitue un problème complexe à résoudre. En cela, apporter des solutions efficaces et performantes aux problèmes d’ordonnancement constitue sûrement un enjeu économique important.
Les problèmes d’ordonnancement industriel ne peuvent généralement être résolus en un temps polynomial par des algorithmes exacts de nature séquentielle ou parallèle et font ainsi partie de la classe des problèmes dits NP-Difficiles. Les métaheuristiques représentent alors des alternatives intéressantes pour la résolution de ce type de problème. Même si ces heuristiques ne garantissent pas l’optimalité, elles assurent généralement une bonne qualité de solutions dans un temps de calcul raisonnable. Plusieurs travaux réalisés au cours des dernières années ont démontré l’utilité et l’efficacité des métaheuristiques pour la résolution de ces problèmes d’optimisation combinatoire.
Le système immunitaire artificiel (AIS) est une nouvelle technique utilisée pour résoudre les problèmes de l’optimisation combinatoire. Les AIS sont des systèmes computationels qui explorent, dérivent et appliquent les différents mécanismes inspirés du système immunitaire biologique naturel dans le but de résoudre les problèmes dans différents domaines.
Le but du travail que nous présenterons dans cette thèse de magister est d’une part, la proposition d’un algorithme basé sur la théorie des systèmes immunitaire artificiel (AIS) pour résoudre le problème d’ordonnancement dans un système de production de type Flow Shop Hybride (FSH) et d’autre part, de paralléliser cet algorithme pour avoir plus d’efficacité et de performance.
Le but de paralléliser cette méthode est d’améliorer la qualité des solutions obtenues, Les solutions sont les meilleurs ordonnancement des différents travaux dans un FSH qui optimisent (minimisent) le Cmax (le temps d’achèvement des travaux).
Cette thèse de magister est organisée en cinq chapitres :
Dans le premier Chapitre nous allons présenter les notions liées aux systèmes de production, en suite nous allons présenter le problème d’ordonnancement dans un système de production de type Flow Shop Hybride (FSH) et en fin les différentes méthodes de résolution utilisées pour le résoudre.
Dans le deuxième chapitre, nous présenterons les systèmes immunitaires artificiels en détaillant les différents concepts et mécanismes inspirés du système immunitaire naturel pour la résolution des problèmes en général et les problèmes d’optimisation en particulier.
Dans le troisième chapitre, nous présenterons l’algorithme immunitaire artificiel adopté pour résoudre le problème d’ordonnancement dans un système de production de type Flow Shop Hybride.
Dans le quatrième chapitre, nous présenterons les différentes architectures parallèles et les différentes stratégies de parallélisation des métaheuristiques et en fin nous détaillerons la stratégie de parallélisation que nous avons choisi pour cet algorithme.
Le cinquième chapitre est consacré à l’implémentation et à la mise en œuvre des deux versions séquentielle et parallèle de l’algorithme adopté en présentant les résultats expérimentaux obtenus.
Chapitre I
Généralités
1.1 Introduction
Depuis les dernières décennies, les systèmes de production ont connu un développement prodigieux, où la gestion de production et l’ordonnancement des tâches sont devenus les éléments qui posent plus de problèmes très importants. Comme l’augmentation de la production et la diminution des coûts sont devenus l’objectif majeur dans toutes les entreprises, les chercheurs ont tenté à trouver et à développer de nouvelles stratégies et méthodes pour la résolution de tels problèmes ; beaucoup plus meilleures que les anciennes.
La gestion de production a pour but de fournir des outils permettant le contrôle et la planification de processus de production. Toutes les études montrent que ces fonctions doivent coopérer pour permettre l’automatisation de la production et que certaines sous fonctions telles que la gestion des stocks sont bien maîtrisées mais ce n’est pas le cas pour d’autres comme la planification et l’ordonnancement en particulier, qui sont encore assez mal résolus malgré les nombreux efforts faits actuellement.
Les problèmes d’ordonnancement se rencontrent très souvent notamment dans l’optimisation de la gestion des systèmes de production. La plupart des problèmes d’ordonnancement sont NP-difficiles. Il s’ensuit que ces problèmes sont impossibles à résoudre de manière exacte ; les chercheurs se sont orientés vers l’utilisation de méthodes approchées appelées « heuristiques ». Contrairement à une méthode exacte qui vise à l’obtention d’une solution optimale, l’objectif d’une heuristique est de trouver une « bonne solution en un temps raisonnable ».
Dans ce chapitre on va présenter les différentes notions liées aux systèmes de production et ensuite on va présenter le problème d’ordonnancement dans un système de production de type Flow Shop Hybride (FSH) et en fin on va voir les différentes méthodes de résolution utilisées pour le résoudre.
1.2 Les systèmes de production
L’ordonnancement dans un système de production consiste à assigner les différents travaux (Jobs) qui ont besoin d’être traités aux différentes ressources, Ces ressources sont principalement les machines qui développent les travaux mais peut inclure aussi la main-d'oeuvre exigée pour opérer les machines.
Donc, la planification industrielle fait référence à la planification des travaux sur les machines afin qu'ils puissent être traités de la manière la plus optimale.
Le processus de planification (ordonnancement) peut être fait d’une manière efficace en identifiant les caractéristiques fondamentales du processus de production :
• La disposition des lignes de production
1.2.1 La disposition des lignes de production [BON 08]
C’est l'organisation des ressources dans l'unité de la production et il y a 4 dispositions fondamentales: 1.2.1.1 La disposition produit
Dans ce type de disposition, chaque produit a sa propre ligne de production. Ce qui est traduit par avoir un ensemble de ressources consacrées uniquement pour le traitement d’un type de produit particulier, les ressources sont arrangées d’une manière à maximiser le taux de production pour ce type de produit. Généralement, dans ce type de disposition les machines exigées sont arrangées dans une ligne suivant l'ordre de la séquence du traitement .Cette disposition est utilisée pour la production des produits en grande quantité et permet de minimiser le temps de placement des produits.
1.2.1.2 La disposition Processus
Appelé aussi une Disposition Fonctionnelle parce que dans cette disposition les machines utilisées pour le même traitement sont regroupées. Le but de cette disposition est de maximiser l'utilisation des machines. Contrairement à la Disposition Produit, les machines sont partagées entre les produits qui les ont besoin.
1.2.1.3 La disposition cellulaire
Quand les produits qui ont besoin d'un traitement semblable sont groupés et toutes les machines utilisées pour traiter ce groupe sont arrangées dans une cellule. La disposition est appelée une disposition cellulaire. La différence entre la Disposition Processus et la Disposition Cellulaire est que les machines dans la cellule ne sont pas identiques mais constituent toutes les machines qui sont exigées pour traiter un groupe des produits.
1.2.1.4 La disposition fixe
C'est un type unique de disposition où le travail reste immobile à une place et les machines sont déplacées à l'emplacement du travail. Cette disposition est utilisée pour certains types de produits, surtout ceux qui sont trop lourd pour être déplacés dans l'unité de production.
1.2.2 Les différents types d’ateliers
Il existe cinq grandes familles essentielles de problèmes d’ateliers [VIG 97] :
1. Problèmes à "1 Machine" : pour lesquels chaque travail (job) n’est constitué que d’une opération à réaliser.
2. Problèmes à "Machines Parallèles" : pour lesquels chaque travail n’est constitué que d’une opération qui peut être réalisée par une ou plusieurs machines (selon les contraintes prises en compte),
3. Problèmes d’"Open-Shop" : pour lesquels la gamme de fabrication n’est pas fixée (les opérations peuvent s’exécuter en parallèle) et différente pour chaque travail.
4. Problèmes de "Job-Shop" : pour lesquels la gamme de fabrication est linéaire (une opération de la gamme ne peut être commencée que lorsque l’opération qui la précède dans la gamme est terminée) mais différente pour chaque travail.
5. Problèmes de "Flow Shop" : où la gamme de fabrication est linéaire et identique pour chaque travail.
1.3 Présentation du problème
1.3.1 Ordonnancement dans les systèmes de production
L’ordonnancement consiste à organiser dans le temps la réalisation des taches compte tenu des contraintes pour atteindre les objectifs déterminés au préalable.
Le but d’un ordonnancement c’est généralement d’optimiser une dimension particulière du problème telle que : le coût, les revenus, le temps ou l’efficacité. Donc, un ordonnancement doit être développé afin qu'un résultat optimum soit obtenu qui prend en considération les limites imposées par les contraintes.
Dans un système de production, les taches sont les étapes du processus de transformation de la matière première en un produit fini. Un produit dans une phase de production est appelé un travail. Les ressources pourraient être les machines sur lesquelles les travaux sont traités, la main d’œuvre pour opérer les machines. Chacune des ressources a certaines contraintes.
Par exemple, les machines et la main d’œuvre ont des contraintes du temps : ils ne peuvent pas travailler sans arrêt mais ils ont besoins du temps pour reposer, nourriture, entretien, etc.
Un autre type de contrainte est que seulement un travail peut être traité par une machine et un homme à tout moment donné. En outre, les contraintes monétaires limitent le nombre des machines,
main-d'oeuvre, heures de travail, etc. donc on a beaucoup de contraintes à respecter pour un ordonnancement optimal.
Maximiser la productivité dans un système de production est l'objectif fondamental d'un ordonnancement optimal. Un ordonnancement optimal peut dire plusieurs choses en fonction de la définition de la productivité. Dans une installation industrielle, la productivité peut être mesurée par le nombre des travaux traités par unité de temps avec ou sans prendre en compte la disponibilité des produits dans les délais pour les clients, utilisation des ressources et par d’autres façons. En fonction de la façon choisie pour mesurer la productivité un ordonnancement peut avoir un ou plusieurs objectifs à atteindre. Parmi les objectifs on trouve Cmax (le temps total d’achèvement des travaux), décalage, retard et autres.
Après le processus de l'optimisation un ordonnancement complet fournit essentiellement le début et la fin de chaque travail sur chaque machine et peut inclure aussi des informations diverses concernant les heures de fonctionnement des machines, le temps d’entretient , temps pour le repos et l’allocation des ouvriers aux machines …etc.
1.3.2 L’atelier de type Flow Shop Hybride (FSH)
Une topologie du système de production telle qu’a été présentée précédemment (Flow Shop, job Shop, …etc.) offre l’avantage de fournir instantanément une image des entreprises. Néanmoins, il est très rare que l’organisation d’une entreprise puisse nous permettre de la classer uniquement dans une des classes de cette topologie. On découvre beaucoup plus souvent des organisations mixtes soit en parallèle soit en série de type Masse Atelier [VIG 97].
1.3.2.1 La configuration du système Flow Shop Hybride
Dans un problème de type Flow Shop on ne considère que le problème d’ordonnancement des taches (Gamme linéaire). Le problème d’affectation (qui découle de la présence des machines parallèles à chaque étage) n’existe pas puisqu’il n’y a qu’une seule ressource (machine) par étage Figure 1.1:
Un FSH est un Flow Shop mais avec des machines parallèles à chaque étage (le nombre des machines peut être différent dans chaque étage). Un FSH est constitué d’un ensemble de m étages, Chaque étage j (j=1,…, m) est composé de M (j) machines parallèles. N jobs visitent les m étages dans le même ordre (étage1, etage2, étage3,…, étage m) et les dates de fin sont connues pour chaque Job
Figure 1.2 :
Etage 1 Etage 2 Etage m Figure 1.1 : Organisation en Flow Shop
Figure 1.2 : Le schéma d’un atelier de type FSH Station d’entrée Station de sortie . . . . . . . . . . . .
1er étage 2èmeétage mème étage
L’atelier de type Flow Shop Hybride a les caractéristiques suivantes :
a) A chaque étage un Job est traité par une seule machine et toutes les machines peuvent exécuter les mêmes opérations, mais pas avec la même performance (la performance d’une machine peut être liée à la compétence de l’agent qui l’utilise).
b) A tout moment, une machine ne peut traiter qu’un seul job, entre chaque étage les Jobs peuvent
attendre ou non dans des stocks limités ou illimités.
c) Le FSH est un problème générique qui peut modéliser les opérations de production, le stock et le transport entre étages [VIG97].
La résolution du problème FSH, consiste à rechercher un ordonnancement en entrée (étage1) des Jobs, et leurs affectation aux machines des différents étages dans le but d’optimiser un critère de performance (Cmax, Tmax, Lmax….etc.).
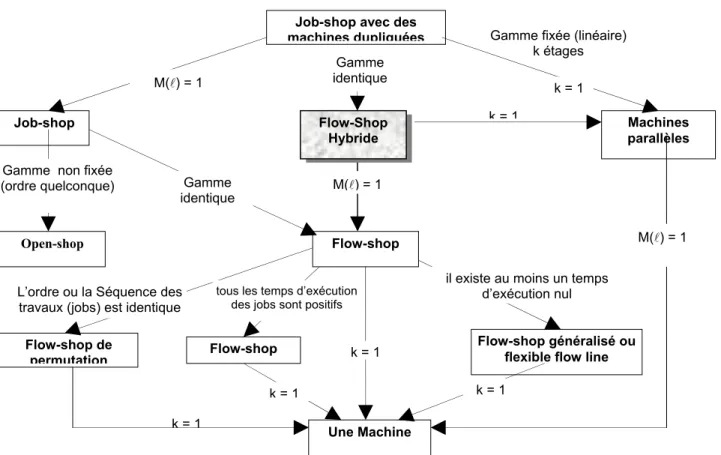
1.3.2.2 Une notation pour le problème FSH
Le système FSH est un système de production désigné par plusieurs champs [VIG 97] :
a) Champ α Composé de 4 paramètres :
[
1
2
]
{
(
3
4
)
}
( )
21 αα
α
α
α
j j= tel que : Job-shop avec desmachines dupliquées Job-shop Machines parallèles Open-shop Flow-shop Flow-shop de permutation Une Machine
Gamme fixée (linéaire) k étages
Flow-shop
k = 1 k = 1
M(l) = 1
Gamme non fixée
(ordre quelconque) Gamme
identique M(l) = 1
M(l) = 1
k = 1
k = 1 k = 1
tous les temps d’exécution des jobs sont positifs
L’ordre ou la Séquence des travaux (jobs) est identique
Gamme identique
Flow-shop généralisé ou flexible flow line il existe au moins un temps
d’exécution nul
k = 1
Flow-Shop Hybride
k désigne le nombre d’étages et M(l) désigne le nombre de machines à l’étage l.
α
|β
|γ
.Figure 1.3 : Positionnement du problème du FSH parmi les autres organisations [VIG 97]
1
α : Désigne le problème FSH
2
α : Désigne le nombre d’étages
Le couple (α3α ) est répété autant de fois qu’il y ‘a d’étages. Dans chaque étage : 4 3
α : désigne le type de machine (φ,P,Q,R) de l’étage j.
4
α : Désigne le nombre de machines dans l’étage j. b) Champ β
Permet de définir les contraintes prises en compte, Ce champ peut être sous la forme :
n
β β
β = 1,..., , ou βi peut être une concaténation de différents paramètres, résumant les contraintes appliquées sur l’étage i du système.
Dans la notation utilisée dans le FSH l’indice supérieur désigne le n° de l’étage. Les indices inférieurs i et j correspondent respectivement au n° du Job (pièce) et au n° de la machine sur laquelle est traitées la pièce [VIG 97].
c) le champ γ
Ce champ correspond au critère à optimiser : Cmax, Lmax,…,etc.
D’après la description des trois champs, le problème FSH sera noté comme suit : Exemple : FH2, (P2, P1) || Cmax (1) FH2, (P2, P1) ||split (l) ||Cmax (2)
(
) (
)
5 3 ) ( 2 1 ) (2
3
= j j= j jP
P
FSH
(3)L’exemple (1) dénote un FSH à 2 étages avec machines parallèles (P) ; 2 machines dans le 1ier étage et 1 machine dans le second. Le critère à optimiser est le Cmax. On note l’absence du champ β : pas de contrainte sur le système.
L’exemple (2) dénote un FSH à 2 étages avec machines parallèles (P) ; 2 machines dans le 1ier étage et 1 machine dans le second. Le critère à optimiser est le Cmax. Une contrainte de décomposition en sous lots (split) est appliquée au 1ier étage.
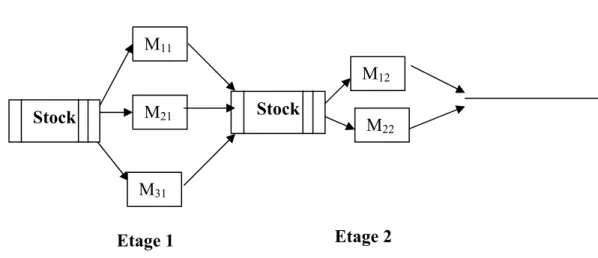
L’exemple (3) dénote la configuration représentée par le schéma suivant avec un stock inter étage (Figure 1.4)
1.3.2.3 Les différents types du FSH
Il existe plusieurs types du FSH suivant la stratégie du stock inter étage [ARI 04]
a) FSH1 : Flow Shop Hybride avec stock inter étages sous forme de file d’attente propre à chaque machine.
b) FSH2 : Flow Shop Hybride dans lequel il existe un stock en entrée propre à chaque machine, mais un stock unique inter étages.
c) FSH3 : Flow Shop Hybride caractérisé par un stock unique en entrée et des stocks inter étages propre à chaque machine.
d) FSH4 : Flow Shop Hybride caractérisé par un stock unique en entrée et unique entre les étages. Figure 1.5 : FSH avec stock inter étages pour chaque machine
Figure 1.6 : FSH avec stock inter étages et un stock pour chaque machine en entrée
Figure 1.7 : FSH avec un stock unique en entrée et des stocks inter étage propre à chaque machine
e) FSH5 : Flow Shop Hybride caractérisé par un stock en entrée propre à chaque machine et pas de stock inter étages.
f) FSH6 : Flow Shop Hybride caractérisé par un stock unique en entrée et pas de stock inter étages.
1.3.2.4 La résolution du problème d’ordonnancement dans le système FSH
Dans un FSH on se contente de résoudre des problèmes de fabrication en série. L’atelier est composé de m étages et chaque étage j regroupe un ensemble de Kj machines, Les gammes sont toutes
identiques.
Le problème d’ordonnancement dans le système FSH consiste à trouver un ordre de passage des différentes taches en entrée du système et une affectation des différentes taches sur les différentes machines de l’étage j+1 suivant leur date de fin de traitement à l’étage j.
1.3.2.4.1 Problèmes NP_Difficiles
Cette classe rassemble des problèmes pour lesquels il n'existe pas d'algorithme qui fournisse la solution optimale en un temps d'exécution polynomial en fonction de la taille des données. Il existe une quantité innombrable de problèmes de ce type dans la littérature. Parmi les plus célèbres, on peut citer le problème du voyageur de commerce, le problème du sac à dos.
En 1988, Gutta a montré que le problème d’ordonnancement dans le système FSH a été classé NP-Complet pour tous les systèmes FSH à 2 étages qui ont un nombre de machines dans un étage qui dépasse 1,
Max (M (1), M (2)>1 [VIG 97].
Du à sa nature (NP-Complet), beaucoup de stratégies exactes, heuristiques et métaheuristiques ont été proposées pour résoudre ce problème. Pour cela un codage des solutions dites admissibles ou réalisables a été utilisé. Ce codage prend en compte une notation rigoureuse pour représenter l’ordre imposé sur les opérations (taches) ainsi que l’affectation de ces opérations sur les différentes machines de chaque étage.
Figure 1.9 : FSH avec un stock en entrée propre à chaque machine et pas de stock inter étages.
1.3.2.4.2 Codage de la solution
Le problème d’ordonnancement du Flow Shop Hybride peut être formalisé comme un problème d’optimisation combinatoire noté : MIN (H(x)) ∀x∈S
S : est l’ensemble des solutions admissibles. x : une solution admissible.
H : le critère à minimiser.
Une solution x admissible est représentée par la concaténation de n+1 vecteurs : X = (σ , V (1), V (2),…, V (n) )
Le premier vecteur σ correspond à l’ordonnancement des travaux (Jobs) en entrée et les n suivants à leur affectation.
- σ = σ1, σ 2,…, σn est une permutation de {1,2,.., n} pour l’ordonnancement des n jobs en entrée du
FSH
- V(i) est un vecteur de longueur m pour l’affectation dans chaque étage du i éme Job (i=1..n) dans l’ordonnancement .
-V(i) j tq 1<= V(i) j<= Mj est la machine de l’étage j (j=1…m) affecté au job i (i=1…n).
Exemple: Soit un FSH:
• à deux étages avec des stocks illimités et quatre jobs en entrée.
• le premier étage est composé de trois machines identiques en parallèle et le deuxième étage de deux machines identiques en parallèle.
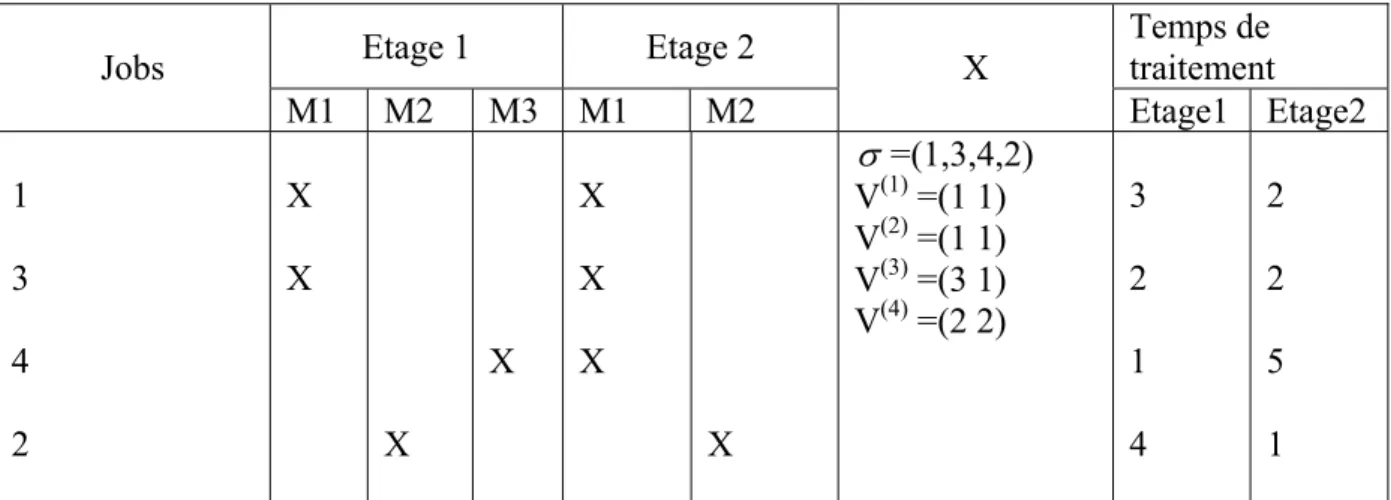
Le tableau 1.1 illustre l’ordonnancement et l’affectation correspondant au vecteur X= ((1342),(1 1),(1 1),(3 1),(2 2))
Etage 1 Etage 2 Temps de traitement
Jobs M1 M2 M3 M1 M2 X Etage1 Etage2 1 3 4 2 X X X X X X X X σ =(1,3,4,2) V(1) =(1 1) V(2) =(1 1) V(3) =(3 1) V(4) =(2 2) 3 2 1 4 2 2 5 1
Le diagramme de Gantt correspondant est le suivant :
Compte tenu de l’affectation des jobs aux machines, les jobs sont traités dans le premier étage selon l’ordre : 1, 2,4 et 3 et dans le 2éme étage selon l’ordre : 4, 2,1 et 3.
1.3.2.4.3 La complexité du Système FSH
La taille du problème représente le nombre de solutions réalisables .Cette valeur est fixée et est dépendante de l’organisation de l’atelier (nombre d’étages + nombre de machines) et du nombre d’opérations à ordonnancer. Cette valeur est donnée comme suit [SAH 02] :
n i M
K
n
S
Card
∏
=
1!
)
(
Ou n est le nombre de Jobs à ordonnancer, M est le nombre d’étages et Kiest le nombre de machines dans l’étage i.
Le Card(S) croit de façon exponentielle avec l’augmentation du nombre des Jobs à ordonnancer. Le problème est ainsi NP-Complet à cause de la taille de l’espace des solutions qui est relativement grand et qui ne peut de ce fait être traité de façon déterministe [SAH 02]. Pour avoir une idée sur la taille du problème d’ordonnancement, prenons la configuration d’un FSH composé de deux étages (FH2) avec 3 machines dans le premier étage et 2 machines dans le second.
Le problème est noté FH2 (P3, P2) || Cmax, ou Cmax représente le critère à minimiser qui signifie le temps d’achèvement total des travaux.
M2 M1 M3 M2 M1 2 émeEtage 1 er Etage 1 2 3 4 5 6 7 8 9 10 1 3 2 4 4 1 3 2
Le tableau 1.2 expose les cardinalités de l’espace des solutions lorsque le nombre n des pièces varie de 1 à 10. Nombre de pièces Combinatoire Du FSH
Temps de calcul estimé pour l’évaluation de toutes les solutions possibles
n Card(S)=n !6n années Mois Jours Heures Minutes Secondes Millisecondes
1 6 6 2 72 72 3 1,296 1 296 4 31,104 31 104 5 933,120 933 120 6 33,592,320 33 592 320 7 1,410,877,440 23 30 877 440 8 67,722,117,120 18 48 42 117 120 9 3,656,994,324,480 42 7 49 54 324 480 10 219,419,659,468,800 7 0 19 13 54 19 400 000
Tableau 1.2 : Combinatoire de temps de calcul estimé pour le FH2 (P3, P2) et n=1,…,10 [SAH 02]. 1.4 Les méthodes de résolution du problème d’ordonnancement de type FSH
Pour la résolution des problèmes d'optimisation NP-Difficiles, il existe de nombreuses méthodes génériques de résolution. Ces méthodes se classent en deux catégories bien distinctes. D'une part, les méthodes exactes, cherchant à trouver de manière certaine la solution optimale en considérant l'ensemble des solutions possibles.
D'autre part, les méthodes heuristiques, qui se contentent de rechercher une solution de bonne qualité. Dans le cadre de l'optimisation de problèmes NP-Difficiles, les méthodes exactes ne résolvent pas les problèmes en temps polynomial, ce qui limite la taille des problèmes solvables par ce type d'approche. Cette limite est variable selon les problèmes, mais toujours présente. C'est pour la résolution approchée des problèmes de grande taille qu'ont été introduites les méthodes heuristiques. Parfois on utilise également ces méthodes pour des applications temps réel qui ne permettent pas d'utiliser une méthode exacte qui devient alors trop coûteuse en temps de calcul. Les métaheuristiques sont des méthodes génériques de résolution approchée des problèmes d'optimisation. Elles permettent, avec une même méthode, d'envisager une résolution approchée de nombreux problèmes d'optimisation différents, en ayant un minimum d'adaptations à réaliser pour chaque problème.
1.4.1 Méthodes de résolution exactes
Nous nous intéressons maintenant aux différentes méthodes de résolution des problèmes d'optimisation. En premier lieu nous présentons les différentes classes de méthode exactes. L'intérêt des méthodes exactes est d'apporter l'assurance d'obtenir une solution optimale.
Pour cela, elles doivent parcourir l'ensemble de l'espace de recherche, ou au moins avoir l'assurance de n'écarter aucune solution ayant le potentiel d'être meilleure que la solution optimale trouvée par l'algorithme.
Les méthodes de résolution les plus répandues sont certainement celles construisant un arbre de recherche afin d'explorer l'ensemble de l'espace de recherche. Ces méthodes sont appelées Branch & * (('*') pouvant être remplacé par Bound, Cut, Price ou Cut & Price). Elles utilisent des bornes pour éliminer de la recherche des ensembles de solutions ayant une certaine structure. D'autres méthodes sont spécifiques à un problème donné.
1.4.1.1 Branch & Bound
Le Branch & Bound (B&B) est une large classe d'algorithmes d'où sont dérivées le Branch, cut
& Price. Il utilise la stratégie diviser pour régner, en partitionnant l'espace des solutions en sous- problèmes pour les optimiser chacun individuellement.
L'idée de base est de construire un arbre où les solutions se forment de manière incrémentale lorsqu'on s'enfonce dans l'arbre, les solutions intermédiaires étant appelées solutions partielles. A fin de résoudre plus rapidement le problème, il faut définir une borne supérieure et inférieure sur la solution partielle z, et raffiner ces deux bornes par la suite jusqu'à les égaliser :
- Construction d'une borne supérieure : pour trouver une borne supérieure, il suffit de donner une solution réalisable pour le problème traité. Si l'objectif est de minimiser, l’optimum du problème ne pourra qu'être inférieur à la valeur de cette solution en ce point.
- Construction d'une borne inférieure : l'idée est de résoudre le problème que l'on obtient à partir du problème partiel initial en laissant tomber les contraintes sur les variables.
Comme on optimise sur un ensemble réalisable plus large, l'optimum ainsi obtenu ne pourra qu'être inférieur à l'optimum du problème initial. La racine de l'arbre correspond à une solution partielle vide, les feuilles correspondent à des solutions réalisables (une feuille par solution réalisable). Les autres noeuds correspondent à des solutions partielles. D'une manière classique, on fixe une variable de décision à chaque 'étage' de l'arbre. La profondeur de l'arbre, nécessaire pour atteindre les solutions complètes, correspond aux nombres de variables de décision à fixer.
1.4.2 Résolution approchée
Les méthodes de résolution approchée sont généralement utilisées là où les méthodes exactes échouent. En effet, une résolution exacte nécessite de parcourir l'ensemble de l'espace de recherche, ce qui devient irréalisable lorsque l'on veut résoudre de gros problèmes.
Dans ce cas, une exécution partielle de l'algorithme exact permet rarement d'obtenir une solution de bonne qualité. Des méthodes de résolution approchée ont été mises au point afin de procurer rapidement des solutions de bonne qualité mais non optimales. Parmi ces méthodes de résolution approchée, on distingue les deux classes : celles se basant sur une solution unique et celles faisant évoluer une population de solutions, et les métaheuristiques avancées.
1.4.2.1 Métaheuristiques à solution unique
Les Métaheuristiques à solution unique sont basées sur un algorithme de recherche de voisinage qui commence avec une solution initiale, puis l'améliore pas à pas en choisissant une nouvelle solution dans son voisinage. Les plus classiques sont La descente (la recherche locale), le recuit simulé et la
recherche tabou. 1.4.2.1.1 La descente
C’est la méthode de recherche locale la plus élémentaire. Elle peut être décrite comme suit : 1 : choisir une solution s dans S
2 : Déterminer une solution s’ qui minimise f dans le voisinage de s. 3 : Si f (s’) < f (s) alors poser s := s’ et retourner à 2
4 : Sinon STOP (selon critère d’arrêt)
Une variante consiste à parcourir N(s) et à choisir la première solution s’ rencontrée telle que f(s’)< f(s) (pour autant qu’une telle solution existe). Pour éviter d’être bloqué au premier minimum local rencontré, on peut décider d’accepter, sous certaines conditions, de se déplacer d’une solution s vers une solution s’ € N(s) telle que : f (s’) ≥ f(s). C’est ce que font les méthodes que nous décrivons ci-dessous. 1.4.2.1.2 Le Recuit simulé
La méthode du recuit simulé:
- prend ses origines dans la physique statistique, - est le fruit des travaux de Metropolis.
- introduite dans le domaine de l’optimisation combinatoire par Kirkpatrick en 1983.
Cette méthode exploite le principe selon lequel un système physique qui est chauffé à une très haute température et ensuite graduellement refroidi, atteindra en bout de ligne un niveau faible d’énergie correspondant à une structure moléculaire stable et forte. Elle peut être définie comme suit :
1 : Choisir une solution s∈ S ainsi qu’une température initiale T. 2 : Tant qu’aucun critère d’arrêt n’est satisfait faire
3 : Choisir aléatoirement s’ ∈ N(s);
4 : Générer un nombre réel aléatoire r dans [0,1]; 5 : Si r < p (T, s, s’) alors poser s := s’;
6 : Mettre à jour T; 7 : Fin du tant que.
En général, on choisit une température initiale élevée pour une grande liberté de l’exploration de l’espace de recherche. Puis, la température décroît jusqu’à atteindre une valeur proche de 0, ce qui signifie l’arrêt de l’algorithme. On peut considérer une grande augmentation de la température comme un processus de diversification alors que la décroissance de la température correspond à un processus d’intensification. La méthode de recuit simulé est une méthode sans mémoire. On peut facilement l’améliorer en rajoutant une mémoire à long terme qui stocke la meilleure solution rencontrée
1.4.2.1.3 La recherche tabou
La méthode de recherche avec tabous a été introduite par Glover (1986). Elle explore itérativement l’espace des solutions d’un problème en se déplaçant d’une solution courante à une nouvelle solution située dans son voisinage, et elle est décrite ci-dessous :
1 : Choisir une solution s∈ S, poser T:=φ et s*:= s; 2 : Tant qu’aucun critère d’arrêt n’est satisfait faire
3 : Déterminer une solution s’ qui minimise f(s’) dans NT(s) 4 : Si f (s’) < f(s*) alors poser s*:=s’
5 : Poser s:= s’ et mettre à jour T 6 : Fin du tant que
Les paramètres d’un algorithme de recherche tabou sont : - les mémoires à court terme,
- le compteur,
- le nombre d’itérations - et le critère d’arrêt.
On génère aléatoirement une solution initiale puis on initialise le compteur et les mémoires ; ensuite on choisit une solution dans le voisinage de la solution courante en tenant compte des mémoires, Si la solution choisie est meilleure alors on la conserve, on incrémente le compteur et on met les mémoires à jour, ce processus est répété jusqu’à ce que le critère d’arrêt soit satisfait.
Pour l’intensification elle est assurée par l’acceptation d’une solution améliorante, par le critère d’aspiration et la conservation des solutions élites dans la mémoire à long terme. Tandis que la diversification est donnée par la liste Tabou et la mémoire à long terme peut aussi être un facteur de diversification
1.4.2.2 Métaheuristiques à base de population
Les méthodes d'optimisation à base de population de solutions améliorent, au fur et à mesure des itérations, une population de solutions. L'intérêt de ces méthodes est d'utiliser la population comme facteur de diversité.
1.4.2.2.1 Colonies de fourmis
C’est une méthode évolutive inspirée du comportement des fourmis à la recherche de nourriture. Cet algorithme a été proposé par Dorigo en 1992. Chaque fourmi est un algorithme constructif capable de générer des solutions. Soit D l’ensemble des décisions possibles que peut prendre une fourmi pour compléter une solution partielle. La décision d ∈ D qu’elle choisira dépendra de deux facteurs, à savoir la force gloutonne et la trace.
- La force gloutonne est une valeur ηd qui représente l’intérêt qu’a la fourmi à prendre la décision d et
cette valeur est directement proportionnelle à la qualité de la solution partielle obtenue en prenant la décision d,
-La trace τd représente l’intérêt historique qu’a la fourmi de prendre la décision d. Plus cette quantité est
grande, plus il a été intéressant dans le passé de prendre cette décision. L’algorithme est décrit de la manière suivante :
1 : Initialiser les traces τd à 0 pour toute décision possible d 2 : Tant qu’aucun critère d’arrêt n’est satisfait faire
3 : Construire |A| solutions en tenant compte de la force gloutonne et de la trace 4 : Mettre à jour les traces τd ainsi que la meilleure solution rencontrée;
5: Fin du tant que
Cet algorithme ne donne rien pour la diversification et rien pour l’intensification c’est pour cela que les chercheurs ont tenté de l’améliorer avec l’ajout de nouveaux composants comme une recherche locale par exemple
1.4.2.2.2 Les algorithmes génétiques Les algorithmes génétiques,
- introduits par J. Holland (1975), Sont des méthodes évolutives inspirées des principes de la sélection naturelle :
L’algorithme est décrit de la manière suivante : 1 : Générer aléatoirement une population
2 : Tant que Nombre de générations ≤ Nombre de générations Maximum Faire 3 : Evaluation : Assigner une valeur d’adaptation (fitness value) à chaque individu.
4 : Sélection : Etablir de façon probabiliste les paires d’individus qui vont se reproduire en accordant une meilleure chance aux meilleurs individus.
5 : Reproduction: Appliquer les opérateurs génétiques aux paires sélectionnées où les nouveaux individus produits représentent la nouvelle population.
Les paramètres d’un algorithme génétique sont les suivants : La taille de la population,
La méthode de génération des individus initiaux, La sélection des individus à croiser,
Le mécanisme de croisement,
L’opérateur de mutation et les conditions de remplacement.
On génère aléatoirement une population de solutions appelés aussi individus ou chromosomes ensuite à chaque itération on applique des mécanismes de sélection, de recombinaison et de mutation dans le but d’obtenir une nouvelle population. Les meilleurs individus ont de plus grandes chances d’être sélectionnés pour la reproduction, donc de transmettre leurs caractéristiques aux prochaines générations. Les opérateurs de mutation et de sélection permettent de favoriser la diversification alors que l’opérateur de croisement peut assurer l’intensification de la recherche
Le processus décrit ci-dessus est répété jusqu’à ce qu’un état de convergence (tous les individus sont identiques) soit atteint ou jusqu’à ce qu’une condition d’arrêt définie soit remplie (par exemple un nombre d’itération maximum ou l’atteinte d’une qualité de solution satisfaisante).
Il existe plusieurs travaux portant sur les algorithmes génétiques et de nombreuses variantes portantes, entre autres, sur la représentation de la population, sur les différents opérateurs et sur la définition des critères de terminaison de la méthode.
1.4.2.3 Les métaheuristiques avancées
Les métaheuristiques sont très puissantes pour la résolution d’un grand nombre de problèmes et donnent des meilleurs résultats, mais on peut constater quelques défauts comme
- la limite de trouver un minimum global en un temps fini, - difficultés à adapter des algorithmes à certains problèmes,
- pour certains problèmes elles ne sont pas plus performantes que les méthodes exactes, - certaines ne donnent pas de succès à propos de l’intensification et la diversification.
Pour aller plus loin dans la recherche de solutions, il faut avant tout pouvoir détecter de nouvelles solutions. Les algorithmes à base de populations présentent un intérêt particulier par le parallélisme qui est nécessaire dans la recherche des solutions. En ajoutant de nouveaux composants à ces algorithmes, on peut alors construire des algorithmes hybrides, l'une des faiblesses d'un algorithme génétique -par exemple- la vitesse de convergence trop lente, elle peut être compensé par l'ajout d'une méthode de recherche locale. C'est le cas des algorithmes mémétiques de Moscato [MOS 89]. Il est clair que sans l'aide des recherches locales les méthodes à population n'arrivent pas à fournir des solutions très satisfaisantes. De même, sans la gestion efficace d'une population de solutions, il est difficile pour une recherche locale de parcourir efficacement l'espace des solutions souvent très vaste.
Une autre des caractéristiques importantes est de pouvoir limiter la taille de la population ; c'est le cas du Scatter Search (la recherche dispersée) de Glover et de l’algorithme GA/PM (genetic algorithm with population management - algorithme génétique avec gestion de la population), initialement proposé par Sorensen .
1.4.2.3.1 Les algorithmes mémétiques
Les algorithmes mémétiques ou les algorithmes génétiques hybrides sont des métaheuristiques avancées introduites par MOSCATO en 1989 [MOS 89]. L'idée principale de cette technique est de rendre un algorithme génétique plus efficace par l'ajout d'une recherche locale en plus de la mutation. Une des observations générales provenant de l'implémentation d'un algorithme génétique basique est souvent la faible vitesse de convergence de l'algorithme.
L'idée de Moscato est donc d'ajouter une recherche locale qui peut être une méthode de descente ou une recherche locale plus évoluée (recuit simulé ou recherche tabou par exemple). Cette recherche locale sera appliquée à tout nouvel individu obtenu au cours de la recherche. Il est évident que cette simple modification entraîne de profonds changements dans le comportement de l'algorithme.
Un simple algorithme mémétique est donné ci-dessous :
1 : Initialisation : générer une population initiale P de solutions avec taille = n 2 : Appliquer une recherche locale (RL) sur chaque solution de P
3 : Répéter
4 : Sélectionner deux solution x et x’ avec une technique de sélection 5 : Croiser les deux parents x et x’ pour former des enfants y
6 : Pour chaque enfant y
Améliorer cette solution avec RL 7 : Appliquer une mutation sur y
8 : Choisir une solution à remplacer y’ et la remplacer par y dans la population 10 : Fin pour
11 : Jusqu’à critère d’arrêt
L'intensification dans cet algorithme est produite par l'application de la recherche locale et l'opérateur de mutation assure la diversification de la méthode
1.4.2.3.2 La recherche dispersée (Scatter Search)
L'origine de la méthode ou du moins la première publication que l'on trouve comportant ce nom est due à Glover [GLO 86] . Mais le travail conjoint de Fred Glover, Manuel Laguna et Raphael Mart a permis d'obtenir une méthode plus claire et plus sophistiquée et qui garde un caractère générique indéniable :
1 : Générer une population initiale R0 d’individus et poser i:=0; 2 : Tant qu’aucun critère d’arrêt n’est pas satisfait faire
3 : Créer un ensemble Ci de points candidats en effectuant des combinaisons linéaires des points de Ri; 4 : Transformer Ci en un ensemble Ai de points admissibles (à l’aide d’une procédure de réparation); 5 : Appliquer une Recherche Locale sur chaque point de Ai; soit Di l’ensemble résultant.
6 : Sélectionner des points dans Ri∪Di pour créer le nouvel ensemble Ri+1 de référence et poser i:=i+1; 7 : Fin du tant que
Cette méthode fait évoluer une population de solutions et s'appuie sur le principe suivant :
- Une population de solutions (assez importante au départ) est générée (en essayant de proposer des solutions diverses les unes des autres)
- et chaque individu est amélioré par l'application d'une recherche locale.
- De cette population on extrait un ensemble de références contenant les meilleures solutions de la population initiale.
- Ensuite ces solutions sont combinées entre elles (et avec les nouvelles solutions générées) - puis améliorées jusqu'à ce qu'il n'y ait plus de nouvelles solutions générées par combinaison. - Ensuite une moitié de la population est régénérée (remplacée par des solutions diverses) - et le processus recommence jusqu'à satisfaction d'un critère d’arrêt.
Un des points importants, c'est la mesure de la diversité des solutions. Cette mesure doit être prise dans l'espace des solutions (et non dans l'espace des objectifs) et elle doit refléter la différence entre deux solutions. La particularité de cette méthode est l'acharnement à épuiser les ressources par combinaison. Ceci se traduit par une sorte d'exploration systématique de tout un voisinage possible et bien sur par un temps d’exécution parfois prohibitif. Par la suite, on remplace une partie de la population et on recommence. On remarque que la combinaison des points de référence assure la diversification et la recherche locale garantit l’intensification.
1.4.2.3.3 Algorithme génétique avec gestion de population (GA/PM)
En 2003 K. Sőrensen a proposé cette métaheuristique qui est appelée GA/PM (Genetic Algorithm with Population Management - Algorithme Génétique avec Gestion de la Population).
Le fonctionnement est assez simple et est basé sur un algorithme génétique.
- Nous supposons que nous savons comparer deux individus entre eux et mesurer leur dissemblance. - Au départ, on génère une population initiale de petite taille
- et on choisit un paramètre ∆ fixant le niveau de dissemblance des solutions entre elles.
- Ensuite, on procède comme dans un algorithme génétique, on choisit deux individus que l'on croise pour obtenir deux enfants.
- Pour chacun tant que le critère de diversité n’est pas satisfait on applique un opérateur de mutation sur ces individus jusqu'à ce qu’il soit satisfait.
- Ensuite sous condition, on les insère dans la population à la place d'un autre individu
A chaque itération le paramètre ∆ gérant la diversité est mis à jour ce qui fait sans doute que cette méthode donne de très bons résultats. Parmi les avantages de cet algorithme il maintient une population de petite taille et bien diversifiée, l'évolution du paramètre de diversité ∆ qui permet à tout moment d'augmenter ou de réduire la diversité des individus dans la population.
L’algorithme GA/PM est donné comme suit : 1: initialiser population P et le seuil de diversité ∆ 2: répéter
3: choisir deux parents P1, P2 dans P 4: croisement sur P1, P2 → enfants C 5: choisir B au hasard de P
6: tant que dP(C) < ∆ 7: muter C
8: fin tant que 9: B ← C
10: mettre à jour le seuil ∆ 11: jusqu'à (critère d'arrêt). Dans cet algorithme
- le facteur d'intensification est donné par le croisement,
- concernant la diversification, c'est la boucle tant que (6 à 8) imposant une diversité. Comme la manipulation du paramètre ∆ peut être interprétée dans les deux sens ;
- Si on diminue ∆, on autorise l'intégration de solutions moins diverses, donc on intensifie la recherche, dans le cas contraire, on force les individus à être de plus en plus éloignés entre eux, donc on diversifie la recherche.
1.4.2.3.4 Algorithme mémétique avec gestion de population (MA/PM)
C’est une évolution des GA/PM, elle est introduite en collaboration avec K. Sőrensen et M. Sevaux, elle ressemble beaucoup à un GA/PM sauf qu’ils ont ajouté une recherche locale pour bien améliorer le comportement de l’algorithme. L’algorithme est donné comme suit :
1: initialiser population P et le seuil de diversité ∆ 2: répéter
3: choisir deux parents P1, P2 dans P 4: croisement sur P1, P2 → enfants C
5:appliquer une recherche locale RL C ← RL(C) 6: choisir une solution B au hasard dans P 7: tant que dP(C) < ∆
8: muter C 9: fin tant que 10: B ← C
11: mettre à jour le seuil ∆ 12: jusqu'à (critère d'arrêt).
Remarque : les étapes de 5 à 10 se font pour chaque enfant C
Ici l’application de la recherche locale est un facteur principal d’intensification de la recherche et l’ajustement du seuil ∆ permet soit de diversifier ou d’intensifier la recherche.
Comme on peut constater les avantages de cet algorithme :
- Permet le contrôle actif de diversité avec la gestion de population.
- Structure de type Algorithme mémétique se qui rend son implémentation plus facile. - Peut s’appliquer à tout Algorithme mémétique (facteur d’extensibilité)
1.4.2.3.5 Métaheuristique électromagnétique
La Métaheuristique Electromagnétique (ME) puise son inspiration dans la loi électromagnétique de Coulomb sur les particules chargées.
Le principe de cette loi est le suivant : "Deux particules exercent sur les autres particules une force d’attraction ou de répulsion dont la valeur est proportionnelle au produit des charges des particules et inversement proportionnelle au carré de la distance qui les sépare" (Loi de Coulomb).
L’idée sous-jacente de la méthode ME est que les particules (les solutions) ayant de "mauvaises propriétés" (ou chargées négativement suivant la loi de Coulomb) exercent une force de répulsion sur les autres particules et les particules ayant de "bonnes propriétés" (ou chargées positivement suivant la loi de Coulomb) exercent une force d’attraction sur les autres particules.
Chaque particule possède donc une certaine charge et une certaine force qui déterminent la direction de son mouvement dans l’espace de recherche.
Une particule i à l’étape k a les caractéristiques suivantes : - sa position courante X i,k
- la meilleure position de son voisinage xbest, k, - sa charge q i,k
- sa force Fki
- f (xj, k) valeur de la fonction à optimiser f aux point xj,k où j est une particule. L’algorithme est donné comme suit :
1 : k := 0
2 : pour chaque particule i faire 3 : xi,0 = Générer Position() 4 : fin pour
5 : tant que k <= MaxIter faire 6 : pour chaque particule i faire
7 : qi,k = Calcul Nouvelle Charge() 8 : Fk,i = Calcul Nouvelle Force() 9 : xi,k+1 = Calcul Nouvelle Position() 10 : xi,k = Mise à Jour()
11 : fin pour 12 : k := k + 1 13 : fin tant
L’intensification dans la ME (Métaheuristique Electromagnétique) est fournie par l’attraction d’une particule par une autre si cette dernière est meilleure qu’elle (régions prometteuses) et est repoussée par une autre si cette dernière est pire qu’elle (nouvelles régions) ce qui signifie la diversification de la recherche.
1.5. Conclusion
Dans ce chapitre nous avons présenté les systèmes de production et les différentes dispositions des lignes de production et types d’ateliers, par la suite nous avons présenté le problème de l’ordonnancement dans un système de production de type Flow Shop Hybride (FSH) qui est un problème NP_difficile dont la résolution nécessite des méthodes beaucoup plus puissantes. En fin nous avons parlé des méthodes de résolution développées pour résoudre ce problème en particulier et les problèmes de l’optimisation combinatoire en générale.
Dans le chapitre suivant on abordera les systèmes immunitaires artificiels et les différentes applications de cette technique pour résoudre les problèmes dans différents domaines et en particulier les problèmes de l’optimisation combinatoire.
![Tableau 1.2 : Combinatoire de temps de calcul estimé pour le FH2 (P3, P2) et n=1,…,10 [SAH 02]](https://thumb-eu.123doks.com/thumbv2/123doknet/7783970.258958/25.892.81.849.191.471/tableau-combinatoire-temps-calcul-estimé-fh-p-sah.webp)
![Figure 2.3 : Une simple idée du processus de la sélection clonale. D’après [BRO 05]](https://thumb-eu.123doks.com/thumbv2/123doknet/7783970.258958/43.892.122.774.108.522/figure-simple-idée-processus-sélection-clonale-bro.webp)
![Figure 2.6 :- Algorithme de la sélection clonale [GHA 06]](https://thumb-eu.123doks.com/thumbv2/123doknet/7783970.258958/50.892.135.691.714.1024/figure-algorithme-de-la-sélection-clonale-gha.webp)
![Figure 2.7 : Représentation schématique de l’évolution de l’algorithme de la sélection clonale [GHA 06]](https://thumb-eu.123doks.com/thumbv2/123doknet/7783970.258958/51.892.174.757.129.380/figure-représentation-schématique-évolution-algorithme-sélection-clonale-gha.webp)