HAL Id: hal-01607379
https://hal.archives-ouvertes.fr/hal-01607379
Submitted on 5 Jun 2020HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Distributed under a Creative Commons Attribution - ShareAlike| 4.0 International License
Réalisation d’une application web permettant la
visualisation des données agronomiques de la base
ASTER-ix
Steven Wilmouth
To cite this version:
Steven Wilmouth. Réalisation d’une application web permettant la visualisation des données agronomiques de la base ASTER-ix. [Stage] France. Institut Universitaire de Technologie Nancy Charlemagne (IUT Nancy Charlemagne), FRA.; France. Université de Lorraine (UL), FRA. 2017, 45 p. �hal-01607379�
IUT Nancy Charlemagne Université de Lorraine 2 ter boulevard Charlemagne BP 55227
54052 Nancy Cedex Département informatique
Réalisation d’une application web permettant
la visualisation des données agronomiques
de la base ASTER-ix
Rapport de stage de DUT Informatique
Entreprise : AgroSystèmes Territoires et Ressources (ASTER) de l’Institut National de la Recherche Agronomique (INRA) Mirecourt
WILMOUTH Steven
Tuteur : Jean-Marie TROMMENSCHLAGER Année universitaire : 2016-2017
IUT Nancy Charlemagne Université de Lorraine 2 ter boulevard Charlemagne BP 55227
54052 Nancy Cedex Département informatique
Réalisation d’une application web permettant
la visualisation des données agronomiques
de la base ASTER-ix
Rapport de stage de DUT Informatique
Entreprise : AgroSystèmes Territoires et Ressources (ASTER) de l’Institut National de la Recherche Agronomique (INRA) Mirecourt
WILMOUTH Steven
Tuteur : Jean-Marie TROMMENSCHLAGER Année universitaire : 2016-2017
Remerciements
Je tiens à remercier toute l’équipe pédagogique du département informatique de l’IUT Nancy-Charlemagne pour mes deux années de formation en DUT Informatique.
Je remercie également toute l’équipe de l’unité ASTER Mirecourt de l’INRA pour leur accueil au sein de l’établissement.
Je remercie particulièrement Jean-Marie TROMMENSCHLAGER qui m’a permis de réaliser ce stage en entreprise, qui m’a aussi beaucoup conseillé sur le projet et aidé avec la base de données. Et je remercie Jean-François MARI, parrain pendant le stage qui a pu me conseiller l'utilisation de certains outils.
Table des matières
Introduction ... 7
I – Présentation de l’entreprise ... 8
I – 1. Institut National de la Recherche Agronomique ... 8
I – 2. L’unité AgroSystèmes Territoires Ressources ... 8
II – Le projet ... 9
II – 1. Découverte du projet ... 9
II – 2. Les phases du projet ... 9
III – Les bases de données et Système d’Informations Géographiques (SIG) de l’installation expérimentale ... 11
III – 1. ASTER-ix ... 11
III – 2. SIG ... 12
IV – Travail réalisé ... 13
IV – 1. Recherche de technologies et d’outils ... 13
IV – 1. A. Langages et technologies ... 13
IV – 1. B. Les outils ... 17
IV – 2. Développement de l’application ... 18
IV – 2. A. Développement de l’API... 18
IV – 2. A. 1. Patron de conception ... 18
IV – 2. A. 2. Interactions entre base de données et API ... 18
IV – 2. B. Développement de l’application côté client ... 19
IV – 2 B. 1. Mise en place de la base de l’application JavaScript ... 19
IV – 2 B. 2. Affichage des données d’une parcelle ... 21
IV – 2 B. 2. a. Affichage des interventions ... 21
IV – 2 B. 2. b. Affichage des successions et filiations ... 22
IV – 2 B. 3. Affichage de données issus d’autres shapefiles... 27
IV – 2 B. 3. a. Affichage des points d’observation d’adventices ... 27
IV – 2 B. 3. b. Affichage des zones de fertilité ... 28
IV – 2 B. 3. c. Affichage de la cartes du sol ... 29
IV – 3. Diagrammes ... 31
IV – 3. A. Diagramme d’application... 31
IV – 3. B. Diagramme de classe des contrôleurs ... 33
IV – 3. C. Diagramme de classe des modèles ... 34
IV – Entretiens et réunions ... 35
IV – 1. Entretiens ... 35
IV – 2. Réunions intégrant les utilisateurs ... 35
Perspectives d’évolutions ... 36
Conclusion ... 37
Table des sigles ... 38
Table des illustrations ... 39
Table des tableaux ... 40
Glossaire ... 41
Bibliographique ... 42
Annexe ... 43
7
Introduction
Dans le cadre de mon Diplôme Universitaire et Technologie (DUT) Informatique, j’ai été amené à effectuer un stage conventionné en entreprise d’une durée de 10 semaines. J’ai orienté mes recherches vers des entreprises qui ont déjà travaillées avec l’Institut Universitaire et Technologique Nancy-Charlemagne où je suis ma formation. Après avoir envoyé plusieurs curriculum vitae et lettres de motivation à ces entreprises et n’ayant pas eu de réponse ou alors très tardive, j’ai décidé de démarcher des entreprises autour de mon domicile et aux alentours de mon logement étudiant, n’ayant toujours aucune réponse, je me suis concentré sur les offres de stages disponible sur le service en ligne de mon établissement, deux de mes candidatures ont été retenues, après avoir passé un entretien pour ces deux stages et ayant eux des réponses favorables, je me suis tourné vers le stage qui correspondait le plus à mes projets futurs c’est pourquoi j’ai accepté le stage proposé par l’unité de recherche ASTER – MIRECOURT.
L’objectif de ce stage est de mettre en place une application web permettant la visualisation de données issues d’une base de données de manières graphique, ergonomique et compréhensible pour d’éventuelles réunions mais principalement pour des visites sur l’installation expérimentale. Cette application web est un outil permettant de répondre aux questions posées lors de ces visites, mais sert également d’appui aux intervenants.
En premier lieu, nous allons décrire l’institut, le projet dans lequel s’inscrit mon stage, ensuite nous aborderons les détails techniques et les travaux réalisés tout au long de ces 10 semaines ainsi que les éventuelles améliorations et ajouts futurs.
8
I – Présentation de l’entreprise
I – 1. Institut National de la Recherche Agronomique
L’institut National de la Recherche Agronomique (INRA) est un institut public, fondé en 1946. L’INRA avait pour mission de rattraper le retard de l’agriculture française en associant science et technologie afin d’améliorer les techniques agricoles et d’élevages en France. Sous double tutelle des ministères en charge de la recherche et de l’agriculture, son objectif est d’apporter à travers différents travaux les connaissances nécessaires pour répondre aux besoins nutritionnel de l’être humain mais aussi de développer une agriculture respectueuse de l’environnement et compétitive.
I – 2. L’unité AgroSystèmes Territoires Ressources
L’unité AgroSystèmes Territoires Ressources (ASTER) est une unité de recherche située au cœur du plateau lorrain dans la plaine des Vosges (88), l’unité est dotée d’une installation expérimentale comprenant une exploitation agricole de polyculture-élevage laitier de 240 hectares.
L’unité de recherche est composée de 30 agents titulaires, elle contribue à plusieurs réseaux interdisciplinaires de recherches et elle maintient des partenariats avec des organismes de gestion de ressources naturelles et de développement agricole.
Les travaux de l’unité sont centrés sur 3 volets qui sont les suivants :
Modéliser les changements d’usage des terres dans les territoires.
Analyser et accompagner les transformations des systèmes sociotechniques.
Concevoir et faire évoluer vers d’avantages d’autonomie des systèmes agricoles dans des territoires de polyculture-élevage laitier.
9
II – Le projet
II – 1. Découverte du projet
Le projet avait été présenté pendant l’entretien de recrutement, puis m’a été représenté le premier jour de stage, ainsi les contraintes et les fonctionnalités attendues ont été expliquées plus en détails.
L’objectif du stage est de réaliser une application web multicritères et dynamique servant d’appui aux différents intervenants lors de visites de l’installation expérimentale ainsi qu’aux éventuelles réunions où l’application est nécessaire. L’application web se doit d’être ergonomique, intuitive et d’une prise en main rapide. Elle permet de mobiliser différentes données issues d’une base de données pour rendre leur lecture plus simple et rapide.
Le projet est soumis à différentes contraintes telles que l’utilisation du langage JavaScript, l’utilisation de la bibliothèque D3JS pour construire les différents graphiques et être multiplateformes.
II – 2. Les phases du projet
Le projet est organisé en trois parties détaillées ci-dessous :
Recherche de technologies pouvant répondre aux besoins et aux différentes contraintes du projet. Exploration de la base de données et extraction de jeux de données pour en comprendre l’architecture et ensuite utiliser la base de données avec l’application web.
Développement de l’application web avec les technologies et outils choisis tout en respectant les contraintes énumérées.
Les deux dernières phases sont complémentaires en raison du lien qui les lient entres elles pour la procédure de développement.
10
Illustration 1 : Chronogramme par semaines du stage.
Dé ve lo p p em e n t d u n s ys tè m e d e p lu gin s Ja va Sc rip t Dé co u ve rt e d u p ro je t e t ac q u is it io n d e r e ss o u rc es C o n ce p tio n d u n e m a q u et te H T M L p o u r l aff ic h a ge d e d o n n é e s C ré a tio n d u n t ria n gle d es t e xt u re s (SV G ) C ré a tio n d e g ra p h iq u e a ve c D 3 JS C ré a tio n d e t a b le au d e d o n n ée s R e ch er ch e d u n s e rv eu r lo ca l SI G Fa ct o ris at io n , aj o u ts d e c o m m e n ta ir e s, co rr e ct io n s d e b u gs A ff ic h ag e d e s fi lia tio n s d e s p ar ce lle s R é u n io n s e t e n tr e tie n s A vr il Se m ai n e 15 Se ma in e 16 Se m ai n e 17 Se ma in e 18 M ai Se ma in e 19 Se ma in e 20 Se ma in e 21 Se ma in e 22 Ju in Se ma in e 23 Se ma in e 24 R e ch er ch e d e b ib lio th è q u e s Ja va Sc rip t Dé ve lo p p em e n t A P I e n P H P Dé ve lo p p em e n t d e l in te rf ac e e t af fic h ag e d e s re ss o u rc e s A ff ic h ag e d e s d o n n ée s d e s p o in ts d e fe tilis a tio n : Re ch e rc he s : D éve lo p pe m en t ap pl ic at io n w eb : D éve lo p pe m en t b ib lio th è qu e Ja va Sc ri pt
11
III – Les bases de données et Système d’Informations Géographiques
(SIG) de l’installation expérimentale
III – 1.
ASTER-ixLa mise en place d’une expérimentation-système en 2004 sur l’installation expérimentale de l’unité de recherche ASTER – Mirecourt a conduit à la collecte de données multiples très diversifiées. La base de données contient deux grandes parties de données, les données agronomiques et les données de recherches.
Les données agronomiques ou agricoles regroupent par exemple les interventions (itinéraires techniques) à l’échelle de la parcelle, ces itinéraires techniques (ITK) sont distingués en sous parties :
Les opérations utilisant des intrants ; les semis, la fertilisation et les traitements phytosanitaires, les récoltes…
Les opérations culturales : le travail du sol, le labour, les travaux de fenaison… Les données de recherche sont liées à un protocole expérimental, elles traitent des relevés de biodiversité, utilisés dans l’évaluation globale des systèmes. Les données de recherche contiennent également les relevés et observations sur les cultures, les maladies et les rendements des produits récoltés. Ces observations sont effectuées à l’échelle de la parcelle mais plus généralement à l’échelle de zones géo-référencées :
Les zones de fertilités sont des zones intra-parcellaires de 900 m² où sont effectuées un grand nombre de mesures.
Les points d’observation des adventices. Une adventice est une plante « indésirable » qui pousse dans une zone où elle n’a pas été semées, ce terme adventice correspond aux expressions « mauvaises herbes » ou « herbes folles » dans le langage courant. Dans le domaine agricole, les adventices sont nuisibles aux cultures car elles sont indésirables au moment des récoltes et sont concurrents des cultures semées. Sur les parcelles cultivées de l’installation expérimentale des points d’observations de ces adventices sont géo-référencées. Ils permettent un suivi et l’analyse des populations d’adventices sur le temps long.
12
ASTER-ix (Application pour la Saisie et le Traitement des Évènements Recensés sur l'Installation eXpérimentale) est le nom donné à la base de données qui contient l’ensemble des informations collectées sur l’installation expérimentale. Cette base de données nous permet d’accéder rapidement aux données sur le sujet que nous souhaitons traiter dans l’application, tel que les itinéraires technique ou les récoltes. L’accès aux données s’effectue en manipulant les tables de la base de données ou à travers des requêtes.
ASTER-ix à plusieurs objectifs finalisés :
Réaliser les évaluations des systèmes de productions agricoles expérimentées.
Poursuivre la gestion agricole et règlementaire de l’installation expérimentale.
Proposer une base de données validée avec un recul temporel de plus de 10 ans à des équipes de recherche extérieures.
La base de données permet d’exécuter des requêtes (SQL) à partir des tables. Sous Microsoft Access les requêtes sont stockées sous forme de vues. Une vue est une table virtuelle stockant les données issues d’une requête d’interrogation de la base de données. Ces vues restent permanentes comme le serait une table ce qui nous permet d’utiliser les données au même titre qu’une table. Les requêtes de construction de ces vues consistent à faire une sélection sur critères si ces derniers sont respectés, les données sont ajoutées dans la vue. Cette base de données est une base de données relationnelle, c’est-à-dire que les tables possèdent une relation entre elles par un ou plusieurs attributs communs. Elles sont également liées par des règles de cardinalités. Ceci permet de garantir l’intégrité référentielle des données.
III – 2. SIG
Le parcellaire et les zones de mesures liées aux divers protocoles de recherches sont géo-référencées. Le logiciel ARCGIS® est utilisé pour effectuer cette tâche. Les fichiers issus d’ARCGIS® sont au format shapefile. Le lien avec le parcellaire de la base de données ASTER-ix est réalisé par un identifiant unique aux deux systèmes, « le nom court » de la parcelle ou le nom de la zone de fertilité.
13
IV – Travail réalisé
IV – 1. Recherche de technologies et d’outils
IV – 1. A. Langages et technologies
Mes recherches sur les technologies web se sont portées sur les éléments connus et étudiés en cours, à savoir les langages JavaScript et PHP.
J’ai exploré un peu plus en détail l’univers de JavaScript, le potentiel de ce langage nous permet de manipuler les pages web rapidement est simplement. Je me suis penché sur un framework développé par Google se nommant AngularJS. Ne connaissant pas ce framework, j’ai exploré rapidement la documentation, au final j’ai décidé de développer l’application en JavaScript sans framework et en utilisant différentes bibliothèques. Le fait de ne pas utiliser de framework m’oblige à comprendre les mécanismes du langage JavaScript mais évite de rendre l’application obsolète si le framework n’est plus maintenu.
Pour les interactions entre mon application JavaScript et la base de données, je me suis mis à la recherche de bibliothèques JavaScript, mais sans succès. Celles trouvées n’étaient plus maintenues ou ne fonctionnaient qu’avec un seul navigateur web (internet explorer). J’ai donc décidé de développer une API en PHP. Cette API a pour but de questionner la base de données et d’en tirer des données utilisables par l’application JavaScript. Pour ce faire j’ai cherché des ORM pouvant se connecter aux bases de données Microsoft Access mais ce fut un échec. Effectivement les bibliothèques proposées sur internet ne correspondaient pas à mes recherches, c’est pourquoi j’ai décidé de développer moi-même un petit ORM pour interagir avec la base de données.
L’application aura donc une API en PHP, il faudra donc utiliser PHP et un serveur http pour pouvoir exécuter des requêtes depuis l’application JavaScript. Travaillant sur une machine Windows mon choix s’est tourné vers l’utilisation de wamp, qui est un outil utilisé et vu pendant mes cours.
Les tableaux 1, 2 et 3 récapitulent les langages, les bibliothèques ainsi que les technologies que j’ai utilisés lors de mon stage.
14
Langages Descriptions
JavaScript un langage de programmation de scripts principalement employé dans les pages web interactives.
HTML 5 est le format de données conçu pour représenter les pages web. C'est un langage de balisage permettant d'écrire de l'hypertexte.
CSS est un langage informatique qui décrit la présentation des documents HTML et XML.
PHP est un langage de programmation libre, utilisé principalement pour construire des pages Web dynamiques via un serveur http.
15
Bibliothèques Description
D3JS est une bibliothèque JavaScript permettant l’affichage de données numériques de manière dynamique.
Leaflet est une bibliothèque JavaScript de cartographie en ligne.
Materialize est un framework développé par Google qui permet la création de page web HTML avec un style déjà établi.
jQuery est une bibliothèque JavaScript développée pour faciliter l’écriture de scripts et contient plusieurs fonctionnalités.
Slim est un micro-framework PHP, permettant la mise en place rapide d’API PHP, ou bien de développer des applications webs.
16
Technologies Descriptions
Apache est un serveur http permettant l’exécution de requêtes respectant le protocole http. C’est le serveur HTTP le plus populaire.
WAMP est un environnement de développement web conçut pour Windows, il embarque un serveur http sous Apache ainsi que le langage PHP.
Microsoft® Access® est une base de données relationnelle éditée par Microsoft.
Composer est un gestionnaire de paquets, il permet d’installer des bibliothèques rapidement et simplement.
17 IV – 1. B. Les outils
Pour pouvoir écrire un programme rapidement avec un rendu visuel des variables, des fonctions et autres éléments, il est nécessaire d’utiliser un IDE à la place d’un éditeur de texte classique. L’IDE nous permettra d’avoir une auto-complétion, c’est-à-dire qu’il nous proposera le nom de nos variables et de nos fonctions. Il nous proposera également des fonctions déjà implémentées par le langage de programmation utilisé, ce qui permet d’être plus rapide lors de la saisie du code. Il permet aussi de colorer les différents éléments d’un langage de programmation, tels que les variables, les fonctions ce qui rend la lecture du code plus simple et permet l’identification des éléments plus rapidement.
La machine sur laquelle je développe, possède un IDE nommé Sublime Text, cet éditeur fait très bien les tâches énumérées ci-dessus. Il est multi-langages de programmation, ce qui nous permet de ne posséder qu’un seul IDE pour tout le projet. Seul bémol pour cet IDE c’est qu’il ne permet pas la navigation entre classes PHP lorsque l’on clique sur le nom de classe ou d’une variable ce qui permettrait de naviguer plus rapidement.
Le tableau 4 détail les outils utilisés lors de ce projet.
Outils Descriptions
Sublime Text est un éditeur de texte générique qui prend en charge de multiples langages et permet donc la colorisation des variables, fonctions et d’autres données du langage.
Git permet la gestion de versions décentralisées, ce qui permet de revenir en arrière rapidement et permet aussi de stocker le projet sur un serveur tiers, ce qui consolide le versioning.
Bitbucket est un service web permettant la gestion de projet et l’hébergement de projet utilisant les logiciels de version Git et Mercurial.
18
IV – 2. Développement de l’application
IV – 2. A. Développement de l’API
Le développement de l’API a été relativement simple, la première chose a été d’importer Slim au projet en utilisant Composer, puis d’initialiser Slim, c’est-à-dire de créer l’objet pour qu’il soit ensuite utilisable pour différentes tâches telles que les routes ou bien la gestion des erreurs.
IV – 2. A. 1. Patron de conception
Le patron de conception utilisé pour l’API est dit MVC (Modèle-Vue-Contrôleur). Ce patron permet de structurer son programme et de le rendre plus facilement maintenable par une tierce personne qui n’aurait pas participé au développement. Le principe est de diviser l’application en trois parties qui sont :
Le modèle : Élément permettant la gestion des données (lecture, enregistrement, validation). Le modèle va représenter une seule table de la base de données, il est indépendant du contrôleur et de la vue.
La vue : Élément visible par les utilisateurs de l’application, la vue sert à afficher des données issues du modèle que le contrôleur lui aura transmis.
Le contrôleur : Élément central de l’application, le contrôleur va exécuter les actions passées dans l’adresse url. Il va la plupart du temps utiliser un ou plusieurs modèles ainsi qu’une vue. Dans notre cas, la vue sera l’application en JavaScript.
IV – 2. A. 2. Interactions entre base de données et API
N’ayant pas trouvé de gestionnaire de basse de données Microsoft Access, j’ai décidé de développer moi-même une classe permettant les interactions avec la base. Cette classe utilise l’objet PDO de PHP, qui permet de faire une connexion à la base de données et d’exécuter tous types des requêtes (insertions, mise à jour, suppression, …). Pour éviter de multiples connexions à la base de données, le gestionnaire n’effectue qu’une seule connexion à la base ce qui évite d’en créer une à chaque requête.
Ce gestionnaire est une classe parent des modèles. Ils héritent de celle-ci comme elle permet de définir le nom de la table, la clé primaire mais aussi les relations entre les différentes tables.
19
Les bases de l’API étant faites, je me suis attelé sur le travail de l’application web en JavaScript.
IV – 2. B. Développement de l’application côté client
Le développement de l’application côté client s’est faite en plusieurs étapes ; telles que la recherche de bibliothèques JavaScript pour incorporer et afficher les éléments qui ont été mis à ma disposition comme les fichiers de parcellaires, des sols et d’autres données utiles. Mais aussi une recherche d’un style graphique adapté à l’affichage des données.
L’application embarque différents outils permettant de traiter les fichiers issus des Systèmes d’Informations Géographiques (SIG). Ce dernier est un système d’information conçu pour traiter, analyser, gérer et présenter différents types de données géographique. Une application développée en JavaScript permet l’extraction de données et une interaction avec les fichiers SIG. Les données extraites de ces fichiers serviront à récupérer des éléments dans la base de données pour être afficher sur l’application.
IV – 2 B. 1. Mise en place de la base de l’application JavaScript
Les fichiers utilisés sont au format shapefile. Ce sont des fichiers de formes utilisées pour les systèmes d’informations géographiques. Mes recherches m’ont donc conduit vers la bibliothèque Leaflet qui offre de nombreuses possibilités sur l’affichage des dits fichiers. Elle permet l’affichage de plusieurs couches sur différents plans, elle permet aussi la création de points et de cibler des endroits précis sur le parcellaire.
Leaflet crée des éléments HTML à partir des fichiers shapefiles ce qui nous permet de leurs attribuer des événements comme le clic, le survole et bien d’autres.
Une fois cette bibliothèque trouvée et prise en main, j’ai commencé à développer la base de l’application, je me suis tourné vers Materialize, framework CSS qui permet de créer un style graphique rapidement à l’aide de règles déjà définies.
Après la mise en place de style graphique, le développement JavaScript a réellement commencé.
20
Tout d’abord, un fichier JavaScript central a été créé pour y écrire une fonction d’initialisation mais aussi pour y regrouper les fonctions globales de l’application, comme l’exécution de requêtes vers l’API. Voyant ce fichier s’allonger de plus en plus une fois la base finie, et ayant effectué le commencement de la mise en place de la bibliothèque Leaflet pour les différents fichiers shapefiles, j’ai décidé de développer un système de modules (plugins), qui d’une part facilite la lisibilité des fichiers JavaScript, morcèle le code en divers plugins qui sont chargés à l’initialisation de l’application. Ce système se veut simple et compréhensible, pour ce faire, un simple fichier JavaScript récence les plugins, ce dernier sera utilisé par l’application à l’initialisation pour charger les différents plugins.
Toutefois il est nécessaire de déclarer cinq fonctions qui sont nécessaire à l’application dans les fichiers JavaScript des plugins,
Ces fonctions sont les suivantes :
init : cette fonction permet d’initialiser des données et d’appeler d’autres fonctions à l’initialisation.
name : cette fonction a pour but de nous retourner le nom du plugin. Le nom permet d’identifier la couche affichée et donc de faire différentes actions dessus.
button : cette fonction retourne un booléen pour indiquer si le plugin doit posséder un bouton ou non. Si le plugin possède un bouton il possède donc une image pour l’identifier.
drawLayer : cette fonction dessine à l’aide de la bibliothèque Leaflet la couche correspondante plugin, c’est dans cette fonction que sont définis les évènements sur les formes qui dessinent les parcelles ou les points.
Ces fonctions sont nécessaires au bon fonctionnement de l’application, mais il est possible d’en ajouter d’avantage au plugin. A ce stade le site possède déjà une interface et permet l’affichage du parcellaire. L’illustration 2 représente l’interface graphique de l’application web.
21
Illustration 2 : Interface graphique de l’application web.
Une fois le parcellaire affiché, plusieurs événements ont été greffés à chaque formes tels que le survol de la souris pour afficher le nom de la parcelle, et le clic pour afficher plus de données sur la parcelle.
L’événement du clic sur la parcelle permet l’affichage d’une autre interface qui permet l’affichage des données concernant la parcelle. Toutes les données qui seront affichées dans cette page seront issues de la base de données en utilisant l’API développé précédemment bien qu’il faut écrire les modèles correspondant aux données que nous voulons, le contrôleur pour récupérer les données en fonction des paramètres de l’url et le retour des données au format jSON, sans oublier l’écriture de la route qui nous sert à pointer l’url sur le bon contrôleur et la bonne fonction.
IV – 2 B. 2. Affichage des données d’une parcelle IV – 2 B. 2. a. Affichage des interventions
Les interventions effectuées sur la parcelle sur l’année en cours et deux mille jours en arrières sont les premiers éléments à afficher sur l’interface, la durée de deux mille jours ont été choisie pour ne pas afficher tous l’historique des interventions, donc limiter la liste à afficher. De plus les deux mille jours correspondent à une rotation culturale. L’affichage est très simpliste afin de permettre une prise en main facile. Il comporte la date et le nom de
22
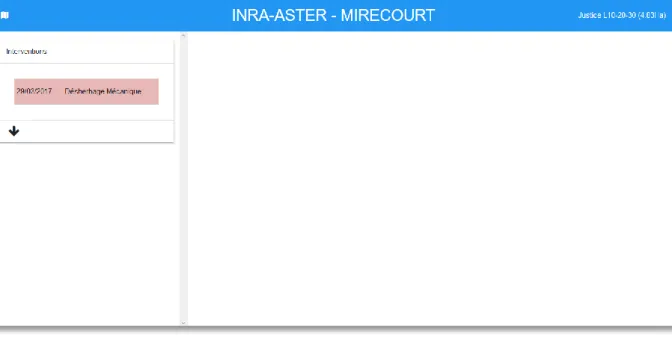
l’intervention ainsi qu’une couleur qui définit le type d’interventions (travail du sol, récolte, fertilisation, …). Pour afficher toutes ces informations de manière claire et facilement lisible, l’utilisation de boîtes déroulantes fournies par le framework Materialize fut très utile. L’illustration 3 représente l’interface d’affiche du détail des données d’une parcelle.
Illustration 3 : Affichage des interventions.
Cet affichage est rendu possible grâce au travail de construction des requêtes en amont. Pour obtenir ce résultat un parcours des données issues de la base a été fait pour construire ces boites déroulantes et y ajouter des tableaux pour séparer la date du nom de l’intervention et les commentaires associés.
IV – 2 B. 2. b. Affichage des successions et filiations
Après avoir conçu l’affichage des interventions, il a été convenu d’afficher les successions et les filiations entre les parcelles car certaines ont été regroupées au cours des années. L’interface intègre également différents boutons qui sont disponible pour l’affichage d’autres données telles que les récoltes, les données du sol ou bien la gestion des prairies.
L’utilisation de la bibliothèque JavaScript D3JS a été nécessaire pour afficher le graphique des successions culturales, cette bibliothèque permet de créer une multitude de graphique du plus simple au plus complexe. Ce graphique représentera les successions de cultures mises en place sur la parcelle choisie de 2004 à l’année courante, il y sera afficher les types de cultures avec une couleur différente pour les différencier, le passage de la souris sur
23
un morceau du graphique déclenchera un évènement de survole et affichera dans une petite boite de dialogue le détail de la culture.
L’affichage de l’année sur l’axe des abscisses permet de changer d’année de référence et donc de réorganiser entièrement le graphique et les données sous-jacentes. Les parcelles qui présentent des filiations n’affichent pas toutes les filiations mais en première intention qu’une seule parmi toutes les filiations. L’illustration 4 illustre l’affichage du graphique des successions culturales de la parcelle.
Illustration 4 : Affichage des successions culturales avec événement de la souris.
Après avoir affiché les successions culturales en fonction d’une des filiations, il fut logique de mettre à disposition une liste permettant de faire des choix sur les filiations à afficher, il a donc fallut modifier légèrement le code de l’API pour prendre en compte le changement de filiation, ce qui fut assez bref car le code déjà en place ne nécessitait pas de grosses modifications. Pour la représentation de la liste nous nous sommes dirigés vers quelque chose de simple et facile de compréhension.
Les filiations sont issues de la base de données via l’API qui est appelé par un script JavaScript. Il ne reste plus qu’à parcourir le résultat envoyé par l’API et de construire la liste. L’illustration 5 est la représentation de l’affichage de la liste des filiations mais est aussi le rendu final de la page d’affichage.
24
Illustration 5: Affichage liste des filiations.
IV – 2 B. 2. c. Affichage des détails du sol
L’affichage détaillé des composantes du sol consiste à afficher les textures et les roches-mères (substratums), il consiste aussi en l’affichage d’un triangle des textures pour la visualisation des zones de fertilité.
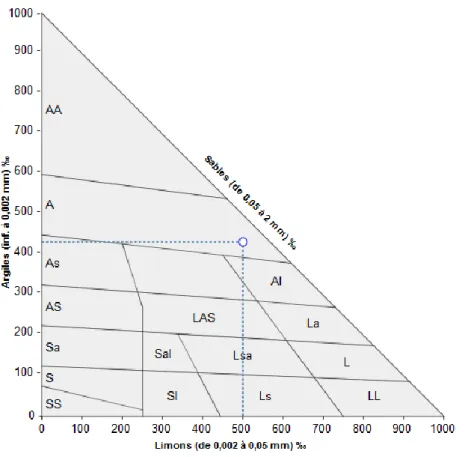
Les données des textures du sol des zones de fertilité sont modélisés sur un triangle des textures GEPPA, élaboré et publié en 1963, le triangle GEPPA se présente sous la forme d’un triangle isocèle rectangle dont les côtés ou axes représentent les teneurs en argiles, limons et sables chaque axe étant gradué de 0 à 100% mais nous pouvons aussi le trouvé graduée de 0 à 1000%. Ce dernier permet de connaître la texture du sol, cette texture correspond à la répartition de trois minéraux dans le sol qui sont : les sables, les limons et les argiles.
25
L’illustration 6 est un exemple de triangle des textures GEPPA, avec la modélisation d’une zone de fertilité issue de l’application :
Illustration 6 : Triangle des textures GEPPA
Ne trouvant aucunes bibliothèques JavaScript sur la création d’un triangle des textures GEPPA, l’idée m’est venue de créer une bibliothèque JavaScript. L’image du triangle est au format SVG, c’est-à-dire une image vectorielle, ce qui est très pratique, car elle garde ses proportionnalités quel que soit l’affichage ce qui évite d’avoir une image déformée ou pixélisée.
Le rendu final de cette image n’est que du code HTML, pour créer le triangle, il m’a fallu étudier le fonctionnement des balises de HTML pour créer les différentes cellules du triangle. A l’aide d’un triangle imprimé sur papier millimétré, j’ai pu constituer un triangle au format SVG en HTML.
26
Une fois ce long travail terminé, je me suis mis à créer une petite bibliothèque qui rend possible une création simple et rapide du triangle en y définissant l’élément parent. C’est-à-dire l’élément qui va contenir le triangle, les dimensions (hauteur, largeur), la couleur des cellules, l’épaisseur des bordures ainsi que la couleur et la couleur du texte. L’ajout de points sur le triangle ce fait très simplement, il suffit d’indiquer les coordonnées x et y du point en paramètre d’une fonction nommée addPoint.
Cette bibliothèque est disponible en ligne1 avec l’accord et l’encouragement à partager de Monsieur TROMMENSCHLAGER Jean-Marie.
La bibliothèque terminée, le développement de l’application a donc continué sur l’affichage des données du sol de la parcelle, en plus du triangle des textures à afficher, il y a un tableau d’affichage des zones de fertilité représentées sur le triangle, ce tableau indique le pourcentage de sables, limons et argiles. Sur chacune des lignes de ce tableau, un événement de clic de la souris y est ajouté pour pourvoir visualiser des données supplémentaires telles que le calcaire et le pH. Ces données sont organisées par années d’analyse ce qui permet de les trouver facilement dans la base de données. Les lignes de ce second tableau possèdent elles aussi un événement de clic de la souris, ce qui permet d’afficher tout le détail de l’analyse de la zone de fertilité selon une année choisie.
L’application prévoit l’affichage des données du sol à l’échelle de la parcelle que nous visualisons. Ces données concernent les textures du sol ainsi que les substratums. Elles sont affichées de la même manière que les interventions, c’est-à-dire qu’elles sont affichées dans des boîtes déroulantes. Cet affichage permet de ne pas afficher un amas de données qui pourrait rendre la lecture difficile.
Toutes les données affichées sont issues de la base de données et ont été extraites grâce à l’API, API qui par ailleurs s’occupe aussi de réorganiser les données, de faire du traitement sur celles-ci afin de les rendre plus facilement utilisable sur l’application, mais aussi de modifier les noms des champs extraits pour les rendre plus courts, compréhensibles et simples. Par exemple pour l’affichage des analyses d’une zone de fertilité, l’API s’occupe de réordonner les données par année de la plus ancienne à la plus récente. L’illustration 7 est l’affichage final du rendu des données sur le ou les zones de fertilités et à l’échelle de la parcelle.
1https://bitbucket.org/wilmouth8u/tts/
27
Illustration 7 : Affichage du tableau de détails d’un point de fertilité et des textures à l’échelle de la parcelle.
IV – 2 B. 3. Affichage de données issus d’autres shapefiles
Ce travail d’affichage de données issues des shapefiles telles que les zones des fertilités les points d’observation des adventices et les informations sur le sol de l’ensemble du domaine a été fait en parallèle de l’affichage du parcellaire et des actions qui lui sont attribuées
IV – 2 B. 3. a. Affichage des points d’observation d’adventices Grâce aux fichiers géo-référencé mis à ma disposition, il est tout à fait possible d’afficher une nouvelle couche d’affichage des points d’adventices sur l’application web. Le principe est le même que l’affichage du parcellaire, c’est un module possédant les cinq fonctions essentiels au fonctionnement des modules. Lorsque l’on affiche les points d’adventices, le parcellaire est masqué pour laisse apparaître un parcellaire vierge, c’est-à-dire un parcellaire sans trames ni couleurs, ce qui rend plus facilement visible les zones.
28
Les points d’adventices sont représentés par des cercles de couleur rouge, ce qui les rend identifiables rapidement. Ces points qui sont en réalité des formes indépendantes les unes des autres possèdent un événement de clic de la souris, qui affiche pour le moment les coordonnées x et y ainsi que le nom de ce point qui par la suite nous servira à extraire des informations de la base de données pour cette dernière. L’illustration 8 représente l’affichage des points d’observation des adventices.
Illustration 8 : Affichage des points d’adventices.
IV – 2 B. 3. b. Affichage des zones de fertilité
Les zones de fertilité sont des zones appartenant à une parcelle, ces zones sont géo-référencées donc nous pouvons les afficher de la même manière que les autres couches par le système de module. Les zones sont juste affichées et possèdent un événement de clic de la souris qui nous affiche la parcelle sur laquelle se trouve la zone, la texture et la roche-mère ainsi que la profondeur du sol. Les zones sont elles aussi affichées sur un parcellaire vierge pour les rendre identifiables rapidement. Peu de données y sont affichées car elles seront détaillées dans l’affichage des données relatives aux zones de fertilité, sol, les rendements… L’illustration 9 représente l’affichage des zones de fertilité.
29
Illustration 9 : Affichage des zones de fertilité.
IV – 2 B. 3. c. Affichage de la cartes du sol
L’affichage du sol consiste à afficher les zones des différentes textures et substratums présentent dans le sol du territoire de l’installation expérimentale. Les textures y sont représentées par des couleurs tandis que les substratums y sont représentés par des trames (quadrillage, cercle, croix, ligne horizontale et verticale).
Cette nouvelle couche est affichée grâce au système de module, elle est greffée à l’application par un module qui lui est propre contenant toujours les cinq fonctions essentielles aux modules. Dans ce module on peut y retrouver la requête vers l’API pour récupérer la texture et le substratum de la zone sélectionnée. Ces données extraites de la base seront affichées au clic de la souris sur une zone ciblée. L’illustration 10 est le rendu de l’affichage du sol.
30
Illustration 10 : Affichage de la carte du sol (textures et substratums).
Un affichage détaillé des données de textures du sol est possible grâce au bouton « ? » qui est disponible sous les boutons de zoom. Ce bouton affiche les textures, la surface et le pourcentage sur le territoire de l’exploitation expérimentale, il est possible d’afficher les substratums en cliquant sur la texture ce qui va permettre l’ouverture d’une boite déroulante qui nous affichera les substratums liés à la texture, nous aurons les mêmes données que pour les textures, c’est-à-dire le nom du substratum, la surface par rapport à celle de la texture et le pourcentage par rapport à celui de la texture. L’illustration 11 est le rendu de l’affichage du détail du sol.
31
Illustration 11 : Affichage des détails du sol (textures et substratums).
IV – 3. Diagrammes
IV – 3. A. Diagramme d’application
Sur l’illustration qui suit, nous pouvons voir le serveur BASILIC, c’est un serveur où
la base de données utilisée est déposée. Sur l’application, nous utilisons une copie de cette base de données pour pourvoir l’utiliser sans connexion internet. Les fichiers shapefiles servent au rendu sur l’interface de l’application mais servent aussi à l’application JavaScript qui extrait des données qui seront utilisées pour faire les appels à l’API qui elle va à son tour interroger la base de données.
L’application JavaScript et les shapefiles « collaborent » entres eux pour afficher les données sur l’interface. C’est pourquoi nous pouvons voir des doubles flèches qui représentent les appels et les retours.
32
Illustration 12 : Diagramme de l’application web.
A ST ER -ix B A SIL IC A P I A p pl ic at io n Ja va Sc ri pt Pa rc el la ir e So l Zo n es d e fe rt ili té s Zo ne s d a dv en ti ces Sh ap ef ile s
33 IV – 3. B. Diagramme de classe des contrôleurs
Les tâches à réaliser pendant le stage étant terminées, voici le rendu final du diagramme de classes des contrôleurs.
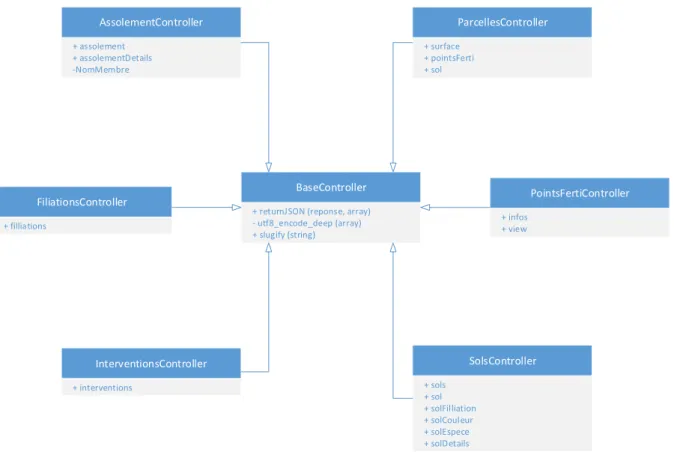
Les contrôleurs héritent tous d’un seul contrôleur nommé BaseController qui permet d’avoir différentes fonctions qui n’ont pas besoin d’être réécrites dans chacun des contrôleurs. Les fonctions sont le retour de l’information au format jSON, une fonction privée pour l’encodage des caractères en UTF-8 et une fonction pour transformer des chaînes de caractères en remplaçant les espaces par des tirets bas, les accents sont également retirés. L’illustration 13 est une représentation de l’héritage des contrôleurs.
Illustration 13 : Diagramme de classes des contrôleurs.
AssolementController + assolement + assolementDetails FiliationsController + filliations InterventionsController + interventions ParcellesController + surface + pointsFerti PointsFertiController + infos + view SolsController + sols + sol BaseController
+ returnJSON (reponse, array) - utf8_encode_deep (array) + slugify (string) -NomMembre + solFilliation + solCouleur + solEspece + solDetails + sol
34 IV – 3. C. Diagramme de classe des modèles
Les modèles sont eux aussi terminés par rapport aux fonctionnalités développées pendant le stage. Les modèles héritent tous de la classe nommée Model tout comme le contrôleur BaseController permet au modèles de bénéficier de fonctions sans les réécrire comme la recherche de n-uplet, la recherche d’un seul n-uplet ou le comptage du nombre de n-uplet mais aussi les relations entre tables. Elle délivre aussi une connexion à la base de données identique à tous les modèles ce qui évite une connexion par modèle et donc qui ferait n-connexions à la base. L’illustration 14 est le rendu final des modèles ainsi qu’une représentation de l’héritage de la classe Model.
Illustration 14 : Diagramme de classes des modèles. Model - connections : array + table : string + primaryKey : string + primaryKeyValue : string + db : PDO + query : PDOStatement + __construct() + find(req: array) + first(req: array) + count(req: string)
+ hasMany(Model, string, array) + belongsTo(Model, string, array) N_Parcelles N_Substratums N_Texture R_Analyse_Sol R_Assol_Final R_Assol_Tout_Couleur R_Assolement_Final R_Commentaire_ITK R_ITK R_Parc_Sol R_Parc_Sol_Substr R_Parc_Sol_Text R_Parcelle_PF R_Parcelles_Filiation R_PF_Parcelle R_Surface_Totale_Assol_ANREC R_T_Texture_PF R_Text_Substr_Sol_CD
35
IV – Entretiens et réunions
IV – 1. Entretiens
Les entretiens journaliers m’ont permis d’avancer sur le projet, mais aussi de faire un point sur les différentes fonctionnalités. Pour ma part je trouve qu’avoir des entrevues régulières permet de faire une mise au point sur le projet et de pouvoir corriger ou améliorer les choses sans attendre la fin du projet. Ce qui pourrait modifier un ou plusieurs éléments sur l’application et donc engendrer un redéveloppement des fonctionnalités pour que tout ce réadapte.
Pendant ces entretiens, j’ai pu proposer et exposer mes idées sur l’agencement de l’affichage des données. J’ai aussi proposé des solutions techniques qui pour certaines ont aboutie à un résultat convenable. Ces entrevues m’ont servis à obtenir des conseils sur l’affichage des données mais aussi à discuter sur les données à utiliser dans les vues pour pouvoir les exploiter avec l’API et l’application web.
Les entretiens sont bénéfiques pour le projet tout comme pour la personne qui développe le projet, ils nous permettent d’avancer et de revenir en arrière rapidement pendant le développement des fonctionnalités et non à la fin du projet.
IV – 2. Réunions intégrant les utilisateurs
Il y eu deux réunions durant le stage, la première servi à présenter l’application aux techniciens qui l’utiliserons sur le terrain pendant les visites de l’installation expérimentale, mais a aussi servi à avoir une première impression quant à l’ergonomie de l’application. Elle a permis de récolter des avis sur les différentes fonctionnalités et par conséquent sur les données à afficher, celles qui leur sont le plus utiles pendant les visites.
Une seconde réunion a permis de montrer l’avancement et les fonctionnalités développées depuis la réunion précédentes. Cette dernière a permis d’obtenir des conseils d’amélioration d’affichage des données et de fonctionnalités à ajouter de manière optionnelle ou permanente à l’application.
Les réunions nous permettent de faire un point avec les techniciens qui utiliseront l’outil en dialoguant sur les points qu’ils trouvent négatifs et à améliorer, tout comme les entretiens réguliers, les réunions donnent une vue d’ensemble du projet, ce qui a pour but d’améliorer l’application web avec les idées de chacun.
36
Perspectives d’évolutions
Les bases du projet étant posées, et les fonctionnalités les plus évoluées développées, il reste donc le développement d’autres fonctionnalités des boutons présents sur le panel d’affichage de la parcelle.
L’utilisation de bibliothèques JavaScript pour la création de tableau ou d’autres éléments sera une idée à exploiter pour rendre le code moins long, plus lisible et plus facilement maintenable.
L’utilisation d’un serveur local de cartographie pourrait être mis en place pour l’affichage d’un fond de carte ou de photographies aériennes géo-référencées, car actuellement le fond de carte est chargé par une connexion internet ce qui ne sera plus le cas pendant l’utilisation sur le terrain de l’application web.
37
Conclusion
L’objectif de mon stage était de construire une application web permettant la visualisation d’élément issus d’une base de données pour les rendre facilement accessible, facilement lisible et compréhensible de manière graphique et interactive. Des réunions avec le personnel qui utilisera l’application ont été organisées pour présenter le projet, son avancement mais aussi pour avoir un retour sur les améliorations à apporter, sur les ajouts possibles et envisageables. Plusieurs entrevues par jours avec Monsieur TROMMENSCHLAGER Jean-Marie m’ont permis d’avancer sur le projet, de l’améliorer. J’ai aussi proposé des idées qui ont été validées ou améliorées. Ne connaissant pas le système de base de données utilisé, j’ai dû m’adapter rapidement ce qui fut assez rapide car il est assez similaire à ce que je connaissais déjà.
Cette première expérience professionnelle dans le domaine informatique, m’a fait me préparer au monde du travail avec tous les bons côtés et les moins bons. En effet la mise en œuvre des fonctionnalités demandées inconnues ou encore les difficultés rencontrées avec les outils utilisés sont très formatrices car tous ces aléas m’ont permis d’apprendre d’avantage. J’ai travaillé en autonomie ce qui m’a permis de bien étudier les bibliothèques et outils utilisés pendant le stage. J’ai aussi constaté que le métier de développeur n’est pas qu’un métier où l’on écrit de code à longueur de journée mais que c’est un métier où l’on est en contact et en interaction avec des personnes qui ne sont pas familière avec l’informatique telle que nous la pratiquons.
Ce stage me conforte dans mon idée principale de poursuite d’études dans le développement web mais aussi de continuer à travailler dans le développement web côté client et serveur.
38
Table des sigles
AJAX Asynchronous Javascript And XML API Application Programming Interface ASTER AgroSystème TErritoire Ressources
Framework Cadre d’applications
HTML HyperText Markup Language
HTTP HyperText Transfer Protocol
IDE Integrated Development Environment INRA Institut National de Recherche Agronomique
JS JavaScript
JSON JavaScript Object Notation
MVC Modèle-Vue-Contrôleur
ORM Object-relational mapping
PDO PHP Data Objects
PHP Hypertext Preprocessor
CSS Cascading Style Sheets
39
Table des illustrations
Illustration 1 : Chronogramme par semaines du stage. ... 10
Illustration 2 : Interface graphique de l’application web. ... 21
Illustration 3 : Affichage des interventions. ... 22
Illustration 4 : Affichage des successions culturales avec événement de la souris. ... 23
Illustration 5: Affichage liste des filiations. ... 24
Illustration 6 : Triangle des textures GEPPA ... 25
Illustration 7 : Affichage du tableau de détails d’un point de fertilité et des textures à l’échelle de la parcelle. ... 27
Illustration 8 : Affichage des points d’adventices. ... 28
Illustration 9 : Affichage des zones de fertilité. ... 29
Illustration 10 : Affichage de la carte du sol (textures et substratums). ... 30
Illustration 11 : Affichage des détails du sol (textures et substratums). ... 31
Illustration 12 : Diagramme de l’application web. ... 32
Illustration 13 : Diagramme de classes des contrôleurs. ... 33
40
Table des tableaux
Tableau 1 : Langages utilisés ... 14
Tableau 2 : Bibliothèques utilisées. ... 15
Tableau 3 : Technologies utilisées. ... 16
41
Glossaire
Polyculture-élevage : système de production agricole combinant une ou plusieurs cultures et au moins un élevage.
Assolement : Répartition annuel des cultures sur le territoire d’une exploitation agricole. Les cultures peuvent varier d’une année à l’autre, c’est une succession culturale ou rotation. Substratum : Couche de sol située entre le sous-sol et la roche-mère. Cette couche est formée par l’altération de la roche-mère.
API : Une API (Application Programming Interface) est un ensemble de classes, méthodes ou fonctions servant de façade qui offre des services à d’autres logiciels.
Framework : Un framework est un ensemble d’outils et de règles conçues pour modeler l’architecture d’une application web ou logiciel.
PDO : PDO est une interface qui permet d’accéder à plusieurs types de base de données. Cette interface permet d’exécuter les mêmes instructions quel que soit la base de données utilisée. Expérimentation-système : Concept d’expérimentation généralisé à l’INRA pour concevoir des systèmes agricoles innovants répondant à des critères environnementaux, économiques et sociaux.
Bibliographique
https://fr.wikipedia.org/wiki/Institut_national_de_la_recherche_agronomique http://www.nancy.inra.fr/Le-centre-Les-recherches/Les-unites/Aster https://fr.wikipedia.org/wiki/Microsoft_Access https://d3js.org/#introduction http://leafletjs.com/index.html http://www.inra.fr/Chercheurs-etudiants/Systemes-agricoles/Tous-les-dossiers/experimentation-systemeAnnexe
FICHE RAPPORT DESTINEE A LA BIBLIOTHEQUE
(à insérer à la fin du rapport)
RAPPORT CONFIDENTIEL ET NE DEVANT PAS FIGURER A LA BIBLIOTHEQUE :
Oui non
NOM ET PRENOM DE L'ETUDIANT : WILMOUTH Steven DUT : INFORMATIQUE
S4 S4 bis Année Spéciale/AETP
LICENCE PROFESSIONNELLE
ASRALL CISII
__________________
TITRE DU RAPPORT : Réalisation d’une application web permettant la visualisation des données agronomiques de la base ASTER-ix
Nom de l'Entreprise : Institut National de la Recherche Agronomique - ASTER Adresse : 662 Avenue Louis Buffet, 88500 Mirecourt
Type d'activité (domaines couverts par l'entreprise) : Recherche Agronomique Nom du parrain (enseignant IUT) : Jean-François MARI
Mots-clés (sujets traités) : Web, JavaScript, HTML, CSS, PHP, API, MsAccess
___________________________________________________________________________ Projet de réalisation d’une application web permettant la visualisation de données issues d’une base de données de manière graphique, ergonomique et compréhensible dans le but de présentations sur l’ensemble du domaine en vue de visites, cette application sert notamment d’appui aux intervenants pour illustrer leurs propos ou retrouver des données qu’ils auraient oubliés.