Focus distance-aware lifetime maximization of video camera-based wireless sensor networks
Texte intégral
Figure
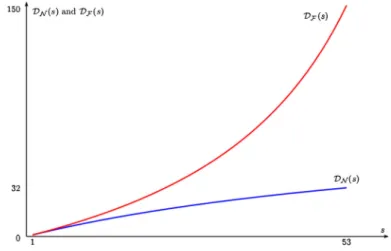
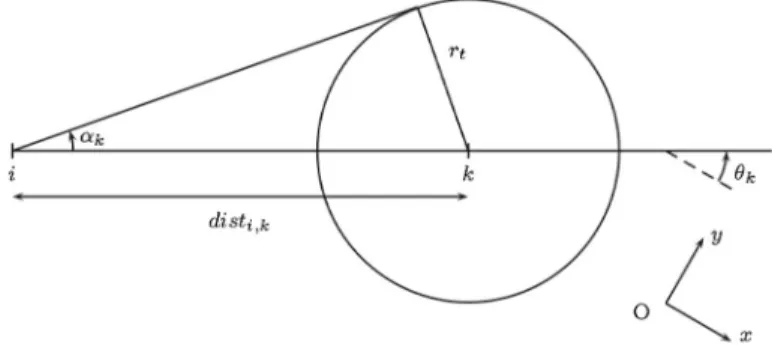
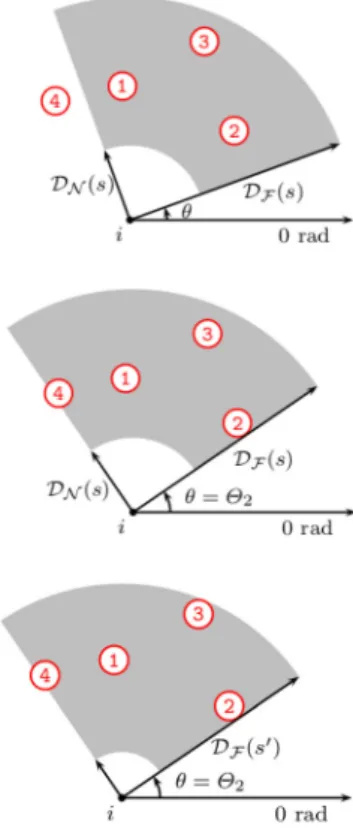
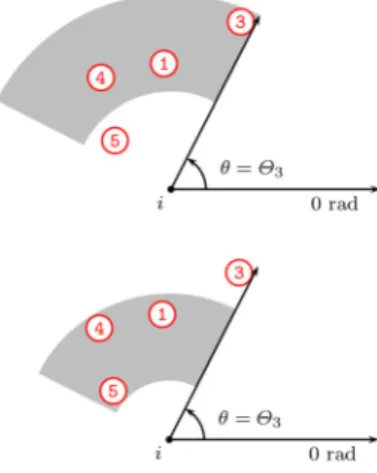
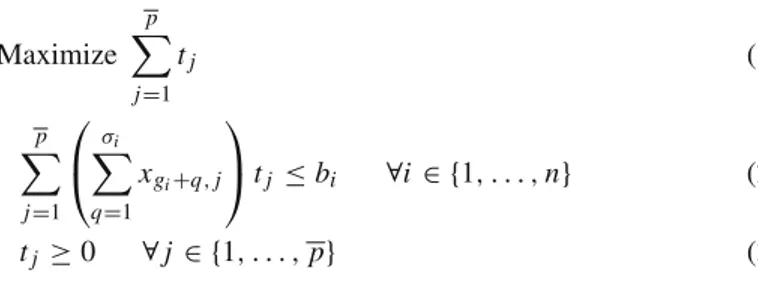

Documents relatifs
Bagherinia, “A new approach for area coverage problem in Wireless Sensor Networks with hybrid particle swarm optimization and differential evolution algorithms,”
The random forest algorithm was used for health assessment, when the industrial device is monitored by a wireless sensor network.. Data in a wireless communication can easily be
The random forest algorithm was used for health assessment, when the industrial device is monitored by a wireless sensor network.. Data in a wireless communication can easily be
Hierarchical QOS-aware Routing in Multi- tier Multimedia Wireless Sensor Networks.. 10th IEEE International Conference on Management of Multimedia and Mobile Networks and
In a general way, network lifetime can be defined as the time span from the deployment of the wireless sensor network until the time where the network becomes inoperative. It is
In this work, we consider the problem of maximizing the lifetime of a wireless sensor network that is required to cover some targets.. The idea is to maximize the number of
More specifically, we present the design and evaluation of GCP (Gossip- based Code Propagation), a distributed software update algorithm for mobile wireless sensor networks.. GCP
Key-words: energy efficiency, node activity scheduling, network lifetime, sleeping node, spatial reuse, coloring algorithm, slot assignment, wireless ad hoc networks, sensor
