LEARNING TO RANK MUSIC TRACKS USING TRIPLET LOSS
Texte intégral
Figure
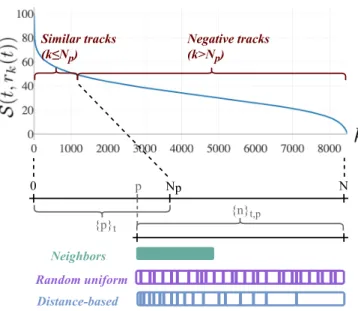
Documents relatifs
The entity label is submitted as a search query to a general search engine and the top ranked documents are used to add context to the ranking process.. The ranking model identifies
Bounded cohomology, classifying spaces, flat bundles, Lie groups, subgroup distortion, stable commutator length, word metrics.. The authors are grateful to the ETH Z¨ urich, the MSRI
Comparison with Respect to Sets of Relevance Aspects For an expert seeking parameter E, let x be the number of comparisons of relevance aspects in E that determine a more relevant
A preliminary analysis of the data recorded in the experiment stressed out the necessity to distinguish the different types of passages: normal driving without any
Le signal obtenu présente une composante de moment d'ordre zéro dont on peut rendre compte par un faible couplage spin-orbite entre l'état fondamental 32Tu et l'état excité 3 /T n
Recently, Balcan et al (2006; 2008) introduced a theory of learning with so-called (ǫ, γ, τ )-good similarity functions that gives intuitive, sufficient condi- tions for a
Among others, we plan to add the following functionalities: (a) the judgment of learning could be refined by allowing the student to highlight parts of texts that were considered
While hob-svm allows us to incorporate high-order information via the pair- wise joint feature vector, it suffers from the deficiency of using a surrogate loss function..
