Reproducible and Accurate Matrix Multiplication for GPU Accelerators
Texte intégral
Figure
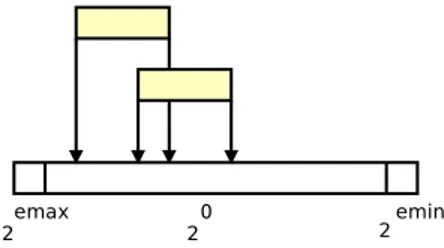
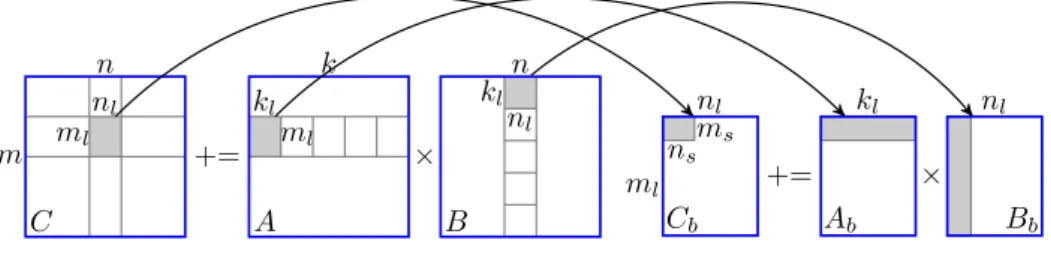
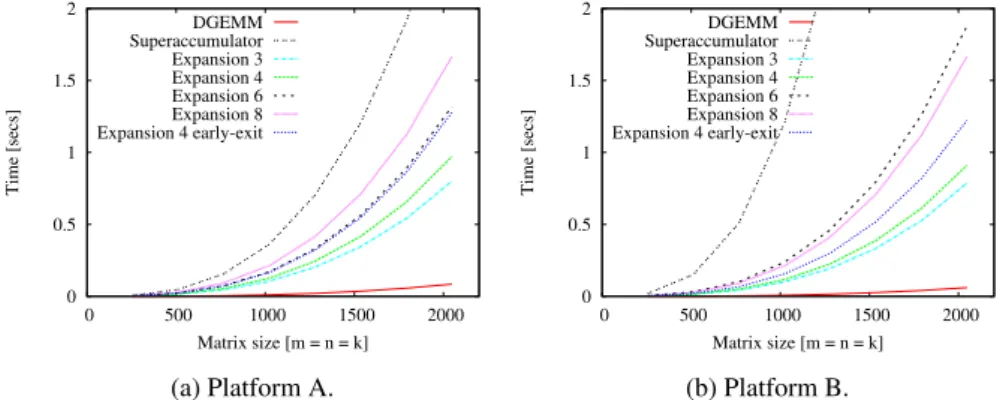
Documents relatifs
Motivated by applications to congested optimal transport problems, we prove higher integrability results for the gradient of solutions to some anisotropic elliptic equations,
Dans le quatrième chapitre, nous avons étudié les propriétés structurales, électroniques, optiques des composés binaires ZnO, ZnS, CdO ,CdS, et CdTe en utilisant la méthode
Les résultats calculés pour les propriétés thermiques à température ambiante pour les deux composés intermétalliques (CeMn 2 Si 2 et NdMn 2 Si 2 )
The practical running time in these applications is dominated by the multiplication of matrices with large integer entries, and it is vital to have a highly efficient implementation
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Nos préoccupations sur la science et l’homme sont les raisons principales qui nous poussé à choisir cet axe de travail scientifique et faire découvrir des
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
