Software Transactional Memory: Worst Case Execution Time Analysis
Texte intégral
Figure

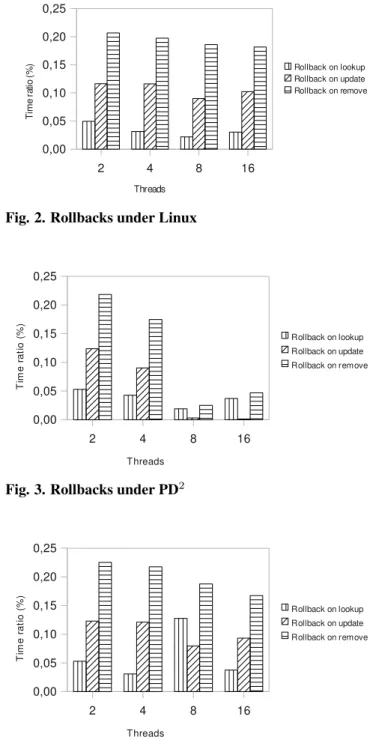
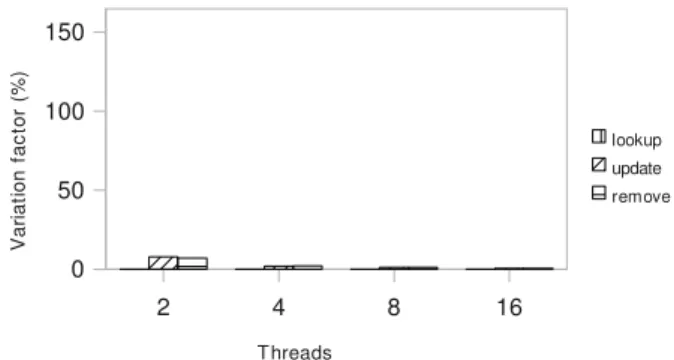
Documents relatifs
A Candida albicans CRISPR system permits genetic engineering of essential genes and gene families.. The MIT Faculty has made this article
/ La version de cette publication peut être l’une des suivantes : la version prépublication de l’auteur, la version acceptée du manuscrit ou la version de l’éditeur. Access
The mean soil volumetric water content value (of the considered period) at each depth is also reported in Table 2. Clearly, the multiplying factor depends on the soil water
A youthful society needs a vigorous and extensive education sector, such as ours bas had since the 19608. But an older society prefers that its taxes be chan- neled into
Pour une fois il semblait fier de moi, mais en même temps tellement étonné que je me vexai un peu, après tout je pouvais réussir aussi bien que lui dans mon travail.. Je commençais
marine strain notably rely on specific desaturation processes of sn-1 bound acyl chains of the
We perform a preliminary study of the vehicular cloud based on two main ideas: (i) vehicles as mobile caches are more widespread and require lower costs compared to small cells;
