© Mathieu Gagnon, 2019
Augmentation du champ de vue d'une caméra
temps-de-vol commerciale
Mémoire
Mathieu Gagnon
Maîtrise en physique - avec mémoire
Maître ès sciences (M. Sc.)
Augmentation du champ de vue d’une caméra
temps-de-vol commerciale
Mémoire
Mathieu Gagnon
Sous la direction de :
iii
Résumé
Ce mémoire présente une méthode d’augmentation du champ de vue d’une caméra temps-de-vol commerciale. Cette augmentation étendrait leur utilisation dans certaines applications où la perception de l’environnement sur un large champ de vision est un critère, notamment en robotique mobile. La conception inclut l’ajout d’une lentille de conversion au système optique de la caméra infrarouge ainsi qu’une modification du système d’illumination. Dans le cas d’une Kinect V2, les capacités de reconstruction 3D ont été conservées pour une augmentation d’environ 50% du champ de vue, soit de 70°x60° à 106°x86°. Afin de tenir compte des modifications apportées au système optique, une calibration de la caméra a été effectuée. Le système modifié comporte une bonne précision (<1%) et une bonne exactitude (<1,5%). Ces résultats sont calculés avec 100 acquisitions en considérant un peu moins de 40% des pixels disponibles sur le senseur. Les performances diminuent rapidement en dehors de la zone centrale du senseur. Un compromis a été fait sur les performances du système afin d’augmenter son champ de vue.
iv
Abstract
This dissertation presents a method to increase the field of view of a commercially available time-of-flight camera. This increase could extend the field of application of such cameras, especially in mobile robotics where awareness of the surrounding is an important factor. The design includes a conversion lens added in front of the optical system and a modification to the illumination system. In the specific case of a Kinect v2, capability of 3D reconstruction has been preserved for an augmentation of 50% of the field of view, from 70°x60° to 106°x86°. To take into consideration the optical modifications, a calibration of the camera has been made. The modified system is characterised by a good precision (<1%) and a good accuracy (<1,5%). These results are calculated on slightly under 40% of the available pixels using 100 acquisitions. Performances decrease at a great rate outside of the central pixel zone. A trade-off has been made on the system performances in order to increase the original field of view.
v
Table des matières
Résumé ... iii
Abstract ... iv
Table des matières ... v
Liste des tableaux... vii
Liste des figures ... viii
Remerciements ... xi
Introduction ... 1
1. Théorie ... 4
1.1. Méthodes de mesure de profondeur ... 4
1.1.1. Triangulation ... 4
1.1.2. Temps-de-vol ... 7
1.1.3. Cas spécifique de la Kinect v2 de Microsoft ... 12
1.2. Sources d’erreurs associées aux caméras ToF ... 16
1.2.1. Ratio signal sur bruit ... 16
1.2.2. Multiples réflexions ... 18
1.2.3. Réflexions internes ... 19
1.2.4. Dimension du pixel ... 20
1.2.5. Erreur circulaire ... 20
1.2.6. Erreur de phase sur le pixel ... 21
1.2.7. Erreur sur la reconstruction 3D ... 22
1.2.8. Température ... 22
1.3. Outils utilisés ... 23
1.3.1. CloudCompare ... 23
1.3.2. Algorithme ICP ... 25
1.3.3. Calibration photogrammétrique ... 27
1.4. Méthodes d’évaluation des capteurs 3D dans la littérature ... 33
1.4.1. Distance absolue ... 33
1.4.2. Test sur mur plan ... 34
1.4.3. Reconstruction d’objets ou de scènes ... 35
1.4.4. Autres quantifications ... 36
2. Capteurs ToF commerciaux ... 39
3. Conception du système ... 41
vi
3.2. Augmentation du champ d’illumination ... 44
3.2.1. Tests de collimation ... 46
3.3. Augmentation du champ de vue ... 47
3.4. Assemblage du système ... 48
3.5. Méthode de reconstruction 3D ... 49
3.5.1. Récupérer l’information de sortie de la Kinect ... 50
3.5.2. Calculer la distance radiale à la Kinect pour chaque pixel ... 50
3.5.3. Utiliser la calibration pour reprojeter chaque pixel dans un nuage de points ... 51
4. Résultats expérimentaux ... 54
4.1. Résolution du système ... 54
4.2. Fonction de transfert optique (MTF) ... 56
4.3. Caractérisation du champ d’illumination ... 57
4.4. Observation d’une scène 3D ... 60
4.5. Analyse des erreurs du système ... 63
4.5.1. Mesure de distance absolue et erreur circulaire ... 63
4.5.2. Écart-type sur tout le champ de vue ... 65
4.5.3. Erreur par rapport à un plan ... 68
Conclusion ... 77
vii
Liste des tableaux
Tableau 2.1 – Caractéristiques de certains LIDARs commerciaux ... 40 Tableau 2.2 – Caractéristiques des principaux Flash LIDARs (caméras ToF) commerciaux ... 40 Tableau 3.1 – Paramètres obtenus par la calibration du nouveau système par Ocam Calib ... 53
viii
Liste des figures
Figure 1.1 – Organigramme des procédures utilisées pour la reconstruction 3D d’une caméra stéréo... 4
Figure 1.2 – Schéma de triangulation ... 5
Figure 1.3 – Patron avec une grille de points ... 6
Figure 1.4 – Schématique d’une détection par lumière structurée ... 7
Figure 1.5 – Système typique comportant les composants principaux d’un système time-of-fligh ... 8
Figure 1.6 – Diagramme I-V d’une SPAD ... 9
Figure 1.7 – Histogramme des différentes mesures de temps par un système de ToF direct ... 10
Figure 1.8 – Schéma d’intégration d’un système typique de PM-iToF ... 11
Figure 1.9 – Représentation d’un système CW-iToF ... 12
Figure 1.10 – Kinect v2 représentée avec ses principaux composants ... 13
Figure 1.11 – Signal de trois fréquences émises successivement par la Kinect v2 ... 14
Figure 1.12 – Différence de phase associée à chacune des trois fréquences de la Kinect v2 ... 15
Figure 1.13 – Schématique représentant les multiples réflexions à un coin ... 18
Figure 1.14 – Visualisation de l’effet de dispersion dans le cas d’une caméra ToF ... 19
Figure 1.15 – Explication de l’erreur circulaire ... 20
Figure 1.16 – Test sur la mesure de distance d’un mur à 1,2m de distance en fonction du temps d’utilisation de l’appareil ... 23
Figure 1.17 – Interface graphique de CloudCompare ... 24
Figure 1.18 – Distance réelle comparativement à la distance du plus proche voisin ... 25
Figure 1.19 – Implémentation du ICP dans le logiciel utilisé CloudCompare. ... 27
Figure 1.20 – Schéma représentant une matrice de pixels non idéaux ... 28
Figure 1.21 – Interface graphique présentée par l’outil de calibration de Bouguet ... 30
Figure 1.22 – Exemple de calibration semi-automatique sur OcamCalib ... 31
Figure 1.23 – Schématique des étapes de calibration d’un système utilisant un modèle épipolaire... 31
Figure 1.24 - Schéma représentant un système catadioptrique ... 32
Figure 1.25 – Erreur absolue sur la distance dans le cas de la Kinect v2... 34
Figure 1.26 – Deux méthodes de représentation de l’écart-type dans le cas d’une Kinect v2 ... 34
Figure 1.27 – Erreur RMS en fonction du nombre d’acquisitions ... 35
Figure 1.28 – Méthode d’évaluation de la reconstruction utilisant un cube... 36
Figure 3.1 – Première étape du démontage ... 41
Figure 3.2 – Visualisation de la Kinect v2 lorsque l’enveloppe extérieure est enlevée ... 42
Figure 3.3 – Vue en éclatée de la Kinect v2 ... 42
Figure 3.4 – Vue de face de la Kinect v2 démontée partiellement ... 43
Figure 3.5 – Support de plastique qui permet de faire le lien entre les diodes et les diffuseurs ... 44
Figure 3.6 – Test de collimation sur une cible à 1,5m ... 46
Figure 3.7 – En a) représentation réelle de la lentille de conversion utilisée. En b) schématique représentant la lentille de conversion de manière simplifiée... 47
Figure 3.8 – Augmentation du champ de vue de 70,6°x60° à 106°x86°par l’ajout de la lentille de conversion 48 Figure 3.9 – Schéma du champ de vue du système. ... 49
Figure 3.10 – En (a), vue éclatée du système. En (b), montage expérimental. ... 49
Figure 3.11 – Mosaïque présentant les 11 différentes captures utilisées pour la calibration ... 52
Figure 3.12 – Résultats de la calibration par OcamCalib ... 52
Figure 4.1 – Focale instantanée (IFL, px/°) en fonction de l’angle de vue (FFOV, °) ... 55
Figure 4.2 – Vue du montage par la Kinect v2 modifiée ... 55
Figure 4.3 – Cible de comparaison de contraste ... 56
Figure 4.4 – Différentes mesures de fonction de transfert optique en fonction du champ de vue en utilisant la cible à ratio de contraste 4 :1 ... 57
Figure 4.5 – Schéma représentant la prise de mesure dans les axes horizontal et vertical ... 58
ix
Figure 4.7 - Intensité mesurée par le radiomètre (W/cm2) en fonction de l’angle vertical (°) ... 59 Figure 4.8 – Scène utilisée pour la reconstruction 3D ... 60 Figure 4.9 – Représentation 3D de la scène après reprojection des points du système modifié ... 61 Figure 4.10 – Représentation 3D de la scène après reprojection des points du système modifié, en comparaison avec un nuage de points provenant de la Kinect originale ... 62 Figure 4.11 – Distribution de l’écart de distance de la figure 4.10 avec la même échelle de couleur. ... 63 Figure 4.12 – Différence entre la valeur mesurée et la valeur de référence (en cm) pour la Kinect de référence (bleu) et la Kinect modifiée (rouge) ... 64 Figure 4.13 - Écart-type sur le senseur de la Kinect de référence (gauche) et sur le système modifié (droite) à une distance de 100cm sur un plan de référence ... 65 Figure 4.14 - Écart-type sur 100 acquisitions (mm) du système modifié en fonction de la position du pixel dans le champ de vue horizontal pour une distance de 0.75m à 3.5m ... 66 Figure 4.15 - Écart-type sur 100 acquisitions (mm) de la Kinect de référence en fonction de la position du pixel dans le champ de vue horizontal pour une distance de 0.75m à 3.5m. ... 66 Figure 4.16 - Écart-type sur 100 acquisitions (mm) du système modifié en fonction de la position du pixel dans le champ de vue vertical pour une distance de 0.75m à 3.5m ... 67 Figure 4.17 - Point obtenu par notre système après calibration (en rouge) versus le point dans la même direction à l’intersection du plan théorique (en bleu) ... 69 Figure 4.18 – Erreur sur la distance ρ (en %) d’un mur plan situé à des distances entre 75cm et 775cm ... 70 Figure 4.19 – Erreur ρ (en %) selon l’axe de vue horizontal de la Kinect, montré en pixel, pour différentes distances entre 0.75m jusqu’à 3m ... 75 Figure 4.20 - Erreur ρ (en %) selon l’axe de vue vertical de la Kinect, montré en pixel, pour différentes distances entre 0.75m jusqu’à 3m ... 76
x
« Parce que tout le monde sait qu’en se tenant par la main on avance deux fois plus vite »
xi
Remerciements
J’aimerais d’abord remercier mon directeur de recherche Simon Thibault de m’avoir accueilli dans son équipe et de m’avoir permis de continuer mon cheminement en recherche. Son support tout au long du projet a été précieux et ses interventions, pertinentes.
Un directeur de recherche seul ne pourrait toutefois égaler l’ensemble de son équipe que je remercie ardemment autant pour l’incroyable regroupement d’étudiants qui m’ont aidé dans cette expérience de recherche que par la qualité de ses membres professionnels.
Un merci particulier à Anne-Sophie Poulin-Girard qui a été d’une aide indéniable tout au long de sa présence dans le projet. Sa connaissance du domaine a été un atout majeur à ma compréhension et sa bonne humeur redonne toujours le sourire même lorsque ça ne fonctionne pas au laboratoire. Merci également à Denis Ouellet pour des discussions toujours enrichissantes.
Merci aux techniciens, Hughes Auger, dont la présence au laboratoire a été d’une aide indispensable ainsi que Patrick Larochelle, dont l’expertise en impression 3D a été cruciale pour mener à bien ce projet.
Merci également à Michael Smith pour sa contribution en tant que stagiaire au projet, notamment pour son aide sur le montage du système ainsi que pour plusieurs mesures expérimentales.
Je souhaite aussi remercier l’Institut du Véhicule Innovant pour le financement de ce projet ainsi que mon point de contact Marc-Antoine Legault et son équipe pour les nombreuses discussions ayant mené à l’élaboration du projet.
Finalement, je tiens à remercier ma famille et mes amis qui ont su m’apporter un support authentique tout au long de ma maîtrise.
1
Introduction
Les capteurs permettant une reconstruction 3D ont attiré beaucoup d’attention au cours des dernières années, tant pour la nouveauté de certaines technologies que pour le développement de domaines connexes. La rapide expansion de la recherche sur les véhicules autonomes ou semi-autonomes, notamment par le biais de l’industrie automobile, a permis de mettre en évidence le besoin d’obtenir des dispositifs fiables de reconstruction 3D. Notons en guise d’exemple Waymo, la nouvelle version du véhicule autonome de Google, ou bien le projet de Volvo, bien qu’un grand nombre de manufacturiers automobiles se soit également lancé dans la course [1], [2]. La plupart utilise une combinaison de capteurs pour visualiser leur environnement le plus adéquatement possible, comptant parmi lesquels radars, caméras, ultrasons et LIDARs (« Light Detection and Ranging »). Afin d’obtenir des informations tridimensionnelles, la méthode la plus répandue est très certainement l’utilisation de technologies utilisant le principe du temps-de-vol puisque ces capteurs sont généralement précis et polyvalents. Ils permettent notamment d’obtenir une meilleure exactitude de mesure à grande distance que les radars conventionnels.
Deux grandes catégories de capteurs à temps-de-vol peuvent être différenciées, toutes deux basées sur un principe actif d’émission d’un signal lumineux et de la réception de ce dernier après un certain délai mesurable. La première catégorie est composée de dispositifs munis d’un système mécanique permettant un balayage, généralement en rotation, au cours duquel un nombre important de mesures est acquis en synchronisme. Chaque mesure de distance est ensuite associée à la disposition du système mécanique pour mettre une reconstruction en trois dimensions; cette méthodologie en fait généralement des capteurs dispendieux. Le Velodyne « Puck » VLP-16 est l’un des LIDARs typiques utilisés dans le domaine automobile et compte 16 lasers tournant sur 360° et espacés de 2° verticalement, permettant un angle de vue de ±15° verticalement [3]. La seconde catégorie basée sur le temps-de-vol fonctionne sans mouvement mécanique et procède plutôt à une acquisition simultanée des points d’une scène avec un imageur composé d’une matrice de pixels. La possibilité de commercialisation et de production de ce type de capteur est directement associée à l’évolution des senseurs CMOS (« Complementary Metal Oxide Semiconductor ») durant les deux dernières décennies qui a permis une miniaturisation ainsi qu’une réduction de coût. Ceux-ci sont généralement appelés « Flash LIDARs » ou « Time-of-flight camera » dans la littérature en raison de l’acquisition simultanée et imageante de la scène. De leur terme français caméras temps-de-vol, ces caméras possèdent généralement une distance d’utilisation beaucoup plus faible que les LIDARs en raison de la nécessité de diffuser la lumière sur tout le champ de vue au lieu d’une acquisition point par point. Bien que certains capteurs commerciaux dépassent ces valeurs, leurs champs de vue horizontal et vertical sont typiquement plus petits que 75°x65°, respectivement.
2
Les différentes résolutions et autres spécifications sont très variables. Un résumé non-exhaustif sera présenté en section 2 du présent document.
Le domaine automobile privilégie les capteurs de type LIDAR en raison de leur longue portée, excellente précision et large champ de vue horizontal. De ce fait, les capteurs commerciaux conçus pour une application à grande vitesse ont souvent un champ de vue vertical insuffisant (<30°) en plus d’avoir de faibles résolutions angulaires dans cet axe; alors limités par le nombre de sources laser utilisées. Pour des applications à faible vitesse, ce type de caractéristiques peut être problématique puisque le sol ou certains objets en hauteur pourraient ne pas être détectés dû au champ de vue vertical restreint.
Les caméras temps-de-vol sont quant à elles plus propices à des applications à faible vitesse sur des véhicules hors route ou industriels. Ces capteurs sont aussi peu dispendieux, souvent d’un ordre de magnitude moindre que les LIDARs, et ce, pour des performances acceptables dans plusieurs domaines d’application; cela en fait notamment d’excellents candidats pour la robotique. Elles profitent d’avantages notamment en simplicité de calculs par rapport aux caméras stéréos et en robustesse lorsque soumises à différentes conditions lumineuses puisqu’elles utilisent leur propre illumination. Elles ne nécessitent également pas la reconnaissance d’un patron diffusé spatialement afin d’obtenir des informations de distance, éliminant donc certaines problématiques associées aux méthodes de triangulation actives.
La méthode de localisation et de cartographie simultanée (SLAM, pour « Simultaneous Localisation and Mapping ») est généralement utilisée afin de modéliser l’environnement dans le but de diriger un véhicule autonome de manière sécuritaire. De nombreux articles se sont intéressés à cette méthode au début des années 2000 lorsqu’une approche plus algorithmique a été développée. Depuis, un grand nombre de groupes de recherche l’utilisent en applications de robotique mobile [4]. L’une des premières applications d’une caméra temps-de-vol utilisée à cette fin a été présentée en 2004. Un capteur SR-2 de MESA Imaging Inc. était alors utilisé en tant qu’alternatives aux caméras 2D, caméras stéréos et autres méthodes à balayage laser [5]. La fréquence élevée des caméras temps-de-vol en fait des choix intéressants pour ces techniques, mais deux facteurs rendent difficile leur application : (1) la qualité variable des mesures sur différents objets et (2) le champ de vue relativement limité de ces capteurs. Le premier aspect constitue une problématique inhérente aux systèmes fonctionnant sur le principe du temps-de-vol et dépend grandement de la qualité de l’instrument. Le second aspect est une problématique associée à l’utilisation d’une matrice de pixels sur un système statique, au lieu d’un laser pivotant sur 360° comme les LIDARs par exemple. Malgré leur forte utilisation dans le domaine, très peu de caméras temps-de-vol disponibles offrent un grand champ de vue, à l’exception du « Pico Monstar » de PMDtec disposant de 100°x85° pour un senseur comportant 352°x287°.
3
Dans le présent mémoire, une méthode est proposée afin d’augmenter le champ de vue d’une caméra temps-de-vol commerciale, tout en conservant ses capacités de reconstruction 3D. Afin de démontrer l’applicabilité de la méthode, la caméra Kinect One pour Xbox One, ou caméra Kinect v2, a été utilisée. Cette caméra temps-de-vol a été choisie principalement en raison de son champ de vue d’origine déjà élevé parmi ses compétiteurs et de sa résolution spatiale élevée pour ce type de capteur (512x424 pixels), deux caractéristiques propices à une éventuelle augmentation de son champ de vue. Ses bonnes performances de mesure, son faible coût et son utilisation répandue en robotique sont d’autres facteurs ayant été considérés. La méthode implique d’abord l’ajout d’une lentille de conversion à la caméra infrarouge pour augmenter le champ de vue. Par la suite, le système d’illumination doit être modifié pour émettre un signal sur le champ de vue augmenté. Pour obtenir une reconstruction 3D, le système doit également être calibré et un certain post-traitement des données doit être fait à partir des données de sortie de la Kinect v2.
La première section vise à introduire la théorie nécessaire à la compréhension du présent document. Après une courte introduction sur les méthodes de reconstruction 3D par triangulation et temps-de-vol, le cas spécifique de la Kinect v2 est abordé. Les différentes erreurs associées aux caméras temps-de-vol sont ensuite décrites et des méthodes de mesures sont détaillées. Les différents outils de manipulation 3D et de calibration photogrammétrique y sont également détaillés.
La seconde section présente une brève revue des capteurs commerciaux fonctionnant sur le principe du temps-de-vol. Certaines de leurs spécificités sont détaillées et une distinction est faite entre les LIDARs et les caméras temps-de-vol.
La troisième section décrit les étapes nécessaires à la modification du système, en commençant par le démontage du système d’origine. La conception du système est par la suite décrite tant pour les composants utiles à l’élargissement du champ de vue que du champ d’illumination. S’en suit une présentation du montage expérimental ainsi qu’une description des étapes nécessaires à l’obtention d’une reconstruction 3D à partir du système modifié.
La quatrième section présente la caractérisation du système modifié, tant sur ses paramètres optiques de résolution et de MTF que sur son nouveau profil d’illumination. La reconstruction d’une scène 3D sur un grand-angle est ensuite démontrée. Puis, l’exactitude et la précision du capteur sont évaluées dans l’ensemble du champ de vue. Finalement, une revue du document dans son ensemble est réalisée et certaines perspectives de continuité sont présentées.
4
1. Théorie
1.1. Méthodes de mesure de profondeur
Les caméras conventionnelles permettent d’imager une scène en utilisant un objectif convergent afin de focaliser les faisceaux sur un senseur. Cette opération transforme la scène tridimensionnelle en une image bidimensionnelle sur le senseur, engendrant une perte d’information sur les distances. Diverses approches sont utilisées pour récupérer l’information de profondeur. Cette section vise à présenter les différentes méthodes de mesure de profondeur; c’est-à-dire les différentes méthodes utilisées pour évaluer la scène dans un référentiel x,y,z et en permettre la reconstruction. Les méthodes de triangulation, passives et actives ainsi que les méthodes par temps-de-vol (ToF, pour Time-of-Flight) seront présentées. Des méthodes par interférométrie existent également, mais sont coûteuses et ont une distance de mesure limitée; ces méthodes ne seront pas discutées dans le présent document. À partir de la section 1.1.2, l’étude sera portée uniquement sur les capteurs de type ToF.
1.1.1. Triangulation
Méthodes passives
La méthode passive est basée sur l’utilisation de deux prises de vue différentes afin d’obtenir une vue tridimensionnelle d’une scène. La stéréoscopie par déplacement est une alternative utilisant une seule caméra installée sur un robot et capturant plusieurs images pour retrouver une scène 3D [6]. Les images n’étant pas prises simultanément, cette méthode fonctionne pour une scène statique temporellement.
L’alternative la plus populaire est l’utilisation d’une paire de caméras stéréoscopique. Dans ce cas, deux caméras séparées d’une distance connue permettent en effet de reconstruire la scène 3D par triangulation. La triangulation requiert toutefois une calibration intrinsèque des paramètres des deux caméras pour corriger, notamment, les paramètres de distorsion des lentilles. Les étapes nécessaires pour la reconstruction sont présentées à la figure 1.1.
5
Une fois les objets localisés dans les deux images, chaque pixel est reprojeté par le biais d’un modèle et de sa calibration. La triangulation permet alors d’obtenir l’information de distance pour la reconstruction 3D. Évidemment, dans le cas réel les deux projections sont rarement coïncidentes en raison des erreurs de calibration et de correspondance, il s’agit plutôt d’obtenir le meilleur estimé qui minimise l’erreur de reprojection.
L’étape de correspondance des pixels est l’étape de calcul dans laquelle un objet dans le monde réel doit être identifié sur les deux images. Différentes méthodes sont utilisées à cette fin, par exemple le « smoothness », les bordures, etc. Le point X de la figure 1.2 représente le point minimisant cette erreur et est donc le point utilisé pour la reconstruction.
La méthode passive de reconstruction 3D est sujette aux conditions de lumière ambiante et surtout est soumise aux restrictions du problème de correspondance. Les algorithmes de correspondance fonctionnent généralement sur un voisinage proche des pixels or, il faut des textures différentes ou des couleurs différentes pour identifier un pixel par rapport à son voisinage. Dans le cas d’un milieu homogène, ce type de dispositif de reconstruction ne permet pas une détection 3D complète.
Figure 1.2 – Schéma de triangulation utilisant la valeur x̂ minimisant l’erreur de reprojection [7]
S’il y a une occlusion sur l’une des trajectoires, l’information tridimensionnelle en ce point ne pourra pas être déterminée, créant des zones indéterminées dans la reconstruction 3D. Ce problème se pose puisque les deux caméras n’ont pas exactement le même point de vue.
Méthodes actives
Pour réduire les difficultés associées au problème de correspondance des pixels, la méthode de triangulation active a été développée. Celle-ci utilise le même principe fondamental de triangulation en utilisant deux points de vue pour calculer la distance de chacun des points de la scène. L’organigramme est similaire à celui de la
6
Figure 1.1, toutefois, au lieu de fonctionner par deux images 2D, une seule image est prise. Une projection, souvent dans un spectre infrarouge ou visible, permet alors de trianguler puisque la géométrie de la projection et de la caméra sont connues. Le patron lumineux est ce qui est qualifié d’élément actif puisque le système n’est pas soumis exclusivement à la luminosité ambiante. La figure 1.3 présente un patron de ce type, similaire à celui utilisé par la Kinect pour Xbox 360.
La source lumineuse doit avoir un patron spécifique pour obtenir les informations de distance, ce patron peut prendre différentes formes comme une grille, une projection de points, des franges. Les méthodes diffèrent largement en fonction du mode choisi, par exemple dans le cas d’une projection de franges de lumière blanche ou d’échelle de gris [8], il s’agit du contour dessiné par la lumière vu sous un autre angle qui est utilisé pour la triangulation; comparativement à une projection de points qui utilise un encodage spécifique pour reconnaître les regroupements de points sur un point bien précis de l’image et ainsi trianguler [9] [10]. Des méthodes projetant par exemple un arc-en-ciel de lumière, littéralement, peuvent être utilisées, tel que décrit dans [11], [12] et montré à la figure 1.4. Pour plus d’informations, une liste exhaustive des méthodes utilisant des approches de lumière structurée est présentée dans un tutoriel de Jason Geng disponible sur l’OSA [13].
Bien que les approches soient différentes, elles procèdent généralement de la même manière : un patron significatif est projeté permettant d’associer son angle de sortie réel avec sa position sur l’image 2D captée. Cela élimine en grande partie le problème de correspondance des paires de caméras stéréoscopique puisque le patron projeté est connu, en plus d’éliminer la présence de zone homogène sans caractéristique reconnaissable pour la correspondance. Dans tous les cas, une calibration précise du système doit être faite pour la triangulation.
Figure 1.3 – Patron avec une grille de points. Chacune des sections dans la grille correspond à une séquence de points unique et identifiable permettant de connaitre ses coordonnées 2D. Ce patron est un exemple de pseudo-random binary array (PRBA). [13].
7
Figure 1.4 – Schématique d’une détection par lumière structurée utilisant de multiples longueurs d’onde pour discriminer les angles de projection [13].
Le patron projeté doit être perceptible clairement pour obtenir les informations de distance; nécessitant souvent des caméras avec une grande plage dynamique et impliquant que la lumière ambiante peut grandement nuire à la correspondance du patron puisque tous les points doivent être perceptibles pour reconnaitre une zone donnée. La couleur ainsi que la texture de la zone sont des difficultés supplémentaires à la reconnaissance du patron. Cela fait en sorte que leur application en extérieur est difficile, même pour les dispositifs utilisant une lumière dans le proche infrarouge puisque l’étendue spectrale du soleil vient perturber la mesure.
1.1.2. Temps-de-vol
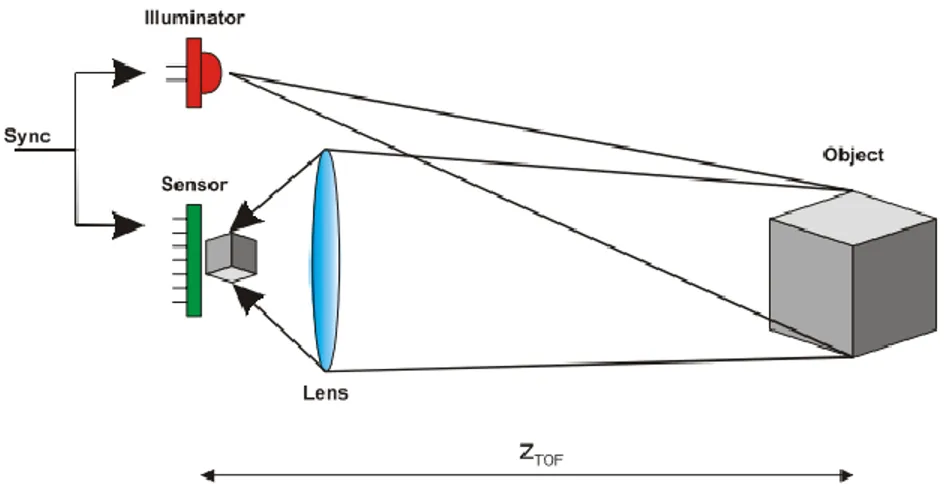
Une autre catégorie de système permettant l’acquisition tridimensionnelle d’une scène sont les systèmes utilisant le principe du temps-de-vol (ToF, pour Time-of-Flight). Ce type de système se compare légèrement aux systèmes de lumière structurée puisqu’un signal doit être émis par une source et reçu par un capteur, le plus souvent un CCD ou CMOS. Le temps parcouru par la lumière lors de l’aller-retour est utilisé afin de calculer la distance selon l’équation de base ci-dessous, où t est le temps, D la distance et c la vitesse de la lumière.
𝐭 =
𝟐𝐃𝐜 (1)
Cette méthode active est implémentée le plus souvent dans un système tel que présenté à la figure 1.5. Contrairement aux systèmes précédents, cette méthode n’a pas besoin d’effectuer une triangulation et, par le fait même, ne doit pas résoudre le problème de correspondance permettant donc un temps de calcul moindre. Puisqu’un système ToF est généralement colinéaire, contrairement aux méthodes stéréos, cela permet d’éviter
8
les artéfacts comme l’effet d’ombrage. Pour cette même raison, un seul capteur optique doit être calibré, à l’instar des systèmes à lumière structurée. On peut voir la différence entre les systèmes ToF et les systèmes à lumière structurée comme étant une solution temporelle au lieu de spatiale. La comparaison est d’autant plus facile à comprendre en utilisant le « rainbow projector », utilisant une différence spatiale des différentes longueurs d’onde. Deux méthodes se sont développées en parallèle, toutes deux basées sur le même principe de base de temps de propagation, mais l’appliquant différemment, soit la méthode directe et la méthode indirecte.
Figure 1.5 – Système typique comportant les composants principaux d’un système time-of-flight, soit la source, le senseur, l’optique et l’horloge. [14]
Méthode par ToF direct
La méthode de ToF direct est possible grâce aux photodiodes à un photon (SPADs, Single-Photon Avalanche Diodes) et à l’utilisation du compte des photons corrélés en temps (TCSPC, Time-Correlated Single-Photon Counting) [15], [16]. Les SPADs sont en fait des semi-conducteurs de jonction p-n utilisés en mode Geiger, soit avec une polarité inversée plus grande que la tension d’avalanche. Cette technologie est de plus en plus utilisée pour les caméras ToF depuis la fin des années 2000.
9
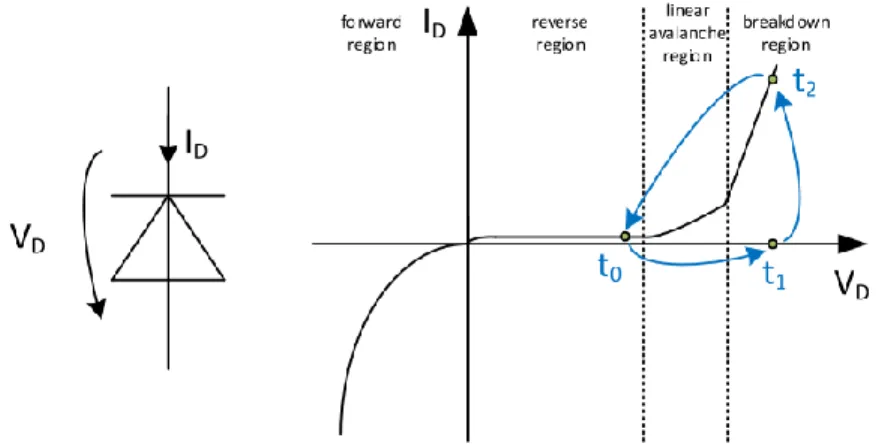
Figure 1.6 – Diagramme I-V d’une SPAD. Le voltage utilisé permet d’opérer la photodiode en mode Geiger, permettant un courant suffisamment élevé pour détecter un seul photon. Entre t0 et t1, le système est activé pour atteindre le « breakdown region ». Un évènement (photon) permet alors la production d’un courant élevé à t2, plus élevé qu’une APD travaillant dans la région linéaire. Pour ne pas endommager le système et pour permettre la mesure suivante, le courant est ramené à t0. [17]
L’effet avalanche permet alors de produire un courant suffisamment élevé, de l’ordre de mA, pour détecter un seul photon. Puisque le « reversed bias » est important dans ce type de photodiode, le temps nécessaire pour la réinitialisation est très court, d’où pourquoi dès 1980 leur utilisation pour des applications rapides a été suggérée [18], [19]. De plus, les SPADs ont été grandement améliorées lorsqu’elles ont été implémentées dans la procédure CMOS dans les années 2000, permettant donc la possibilité d’utiliser ces systèmes pour une détection plus précise et moins coûteuse [20], [21].
Cela fait des SPADs des candidats de choix pour le ToF direct. Toutefois, pour obtenir une résolution de 1mm sur la distance, on doit obtenir une résolution temporelle de 6,6ps, ce qui ne peut être obtenu par une SPAD à température ambiante [22], principalement en raison de bruit associé provoquant de fausses détections. Une méthode de plusieurs acquisitions et de moyennage doit donc être utilisée. La technique du TCSPC [23] a été largement utilisée et est applicable à une caméra ToF [24]. Le principe de la méthode est assez simple : lorsqu’un photon parvient au détecteur, l’avalanche crée un courant mesurable et le temps entre l’évènement et l’initialisation est généralement mesuré par un système TDC (« Time-to-Digital Converter ») [25]. Un grand nombre d’acquisitions est fait pour éliminer les fausses mesures de temps associées au bruit. Un histogramme tel que présenté à la figure 1.7 est produit pour obtenir le temps [17]. La distance est alors obtenue par l’équation 1. L’erreur de mesure dans le cas du ToF direct par l’utilisation d’une SPAD est le cumul entre la largeur d’impulsion, l’erreur du TDC et l’erreur de la SPAD elle-même, résultant du processus aléatoire de génération de paires électron-trou.
10
Figure 1.7 – Histogramme des différentes mesures de temps par un système de ToF direct. L’ordonnée montre le nombre d’occurrences sur un Δt donné. La fonction S(τ) montre l’occurrence de l’évènement. BR(τ) constitue le cumul de la lumière ambiante et du bruit. [17]
Les SPADs sur silicium permettent une utilisation jusque dans le proche infrarouge, sa courbe d’absorption se dégradant rapidement autour de 1.1um, bien qu’il a été démontré dans la littérature qu’une SPAD au silicium peut obtenir une résolution jusqu’à 25ps à 1.55um [26]. Pour une utilisation au-delà de 1.1um, des SPADs InGaAs/InP ou au Germanium sont utilisées la plupart du temps. Une des problématiques est alors le refroidissement nécessaire à des températures autour de -40°C dans le cas du InGaAs/InP.
D’autres variantes de systèmes utilisant le ToF direct n’utilisent pas de SPADs, mais plutôt un système APD [27] qui n’a pas été décrit dans la présente section. Plus d’information sur le ToF direct et sa précision peut être obtenue dans [17]. Les SPADs peuvent également être utilisées pour faire du ToF indirect tel qu’il sera présenté à la section suivante, dans ce cas la méthode pour trouver le délai sera différente. Les deux méthodes, ToF direct et indirect, ont d’ailleurs été implémentées dans le même système utilisant une SPAD [15].
Méthode par ToF indirect
L’approche par ToF indirect est une technologie plus mature que la méthode par ToF direct et possède les mêmes avantages. Depuis leur apparition sur semi-conducteur vers la fin des années 90, la précision des senseurs s’est grandement améliorée, principalement en raison de la démodulation faite dans le domaine du courant au lieu du voltage tel que fait précédemment. Également, l’amélioration des techniques de mesure a permis d’accroître la précision de ces systèmes. Plusieurs implémentations de ces systèmes sont disponibles commercialement (voir la section 2).
Le ToF indirect se subdivise en deux catégories, soit le PM-iToF (« Pulsed Modulation indirect-ToF ») et le CW-iToF (« Continuous Wave modulation indirect-ToF »). Dans les deux cas, il est clair que la vitesse du détecteur et sa sensibilité sont deux paramètres cruciaux pour la précision de l’appareil [28], [29]. La méthode pulsée utilise un principe très similaire au ToF direct, à la différence qu’au lieu de mesurer le temps statistique moyen
11
pris par plusieurs photons indépendamment, on mesure le temps utilisé par un pulse complet pour effectuer l’aller-retour en utilisant une méthode avec plusieurs temps d’intégration, voir figure 1.8. Cette méthode nécessite une électronique très rapide, mais moins sensible que dans le cas du ToF direct; permettant donc l’implémentation sur des photodiodes plus standards que les SPADs nécessaires au ToF direct. Par ailleurs, un avantage du PM comparativement au CW est que l’intensité peut être beaucoup plus élevée sur une courte période pour respecter les conditions de sécurité oculaire autour de la longueur d’onde utilisée, le plus souvent autour de 850nm. En PM-iToF, le signal est donc beaucoup plus important que la lumière ambiante pour la durée d’intégration. Cette barrière de sécurité laser limite en quelque sorte directement la qualité maximale de la précision sur la mesure de distance, limitée par le bruit quantique [30], [31].
Figure 1.8 – Schéma d’intégration d’un système typique de PM-iToF. Un pulse d’une largeur Tp est envoyé et un minimum de trois courts temps d’intégration (Tsw1, Tsw2 et Tsw3) sont utilisés pour discriminer à la fois la lumière ambiante, la lumière réfléchie et finalement TToF. [17]
La plupart des implémentations utilisent toutefois le CW-iToF, principalement pour la raison que, puisque le signal est envoyé en continu, ni le senseur ni le système d’illumination doit être ultrarapide contrairement aux systèmes PM-iToF; résultant donc dans des systèmes à faible coût [28]. Le principe de base est d’envoyer un signal continu, le plus souvent un signal sinusoïdal, et de mesurer la différence de phase entre le signal envoyé et le signal reçu afin de déterminer la distance. Il est aisé de comparer les deux signaux puisque l’effet photoélectrique décrit que le courant sera proportionnel au nombre de photons. On sait par ailleurs que le nombre de photons est proportionnel à la puissance optique. La périodicité du signal induit toutefois une ambiguïté sur la distance puisque la différence de phase mesurée ne pourra excéder 2π, introduisant donc une plage d’utilisation z (en m) pour une fréquence décrite par l’équation 2, où c est la vitesse de la lumière dans le milieu (m/s) et f est la fréquence (Hz). La figure 1.12 permet de visualiser l’impact de la périodicité de phase.
𝟎 ≤ 𝐳 ≤
𝐜12
La distance maximale est donc déterminée par la fréquence de modulation la plus faible; celle-ci sera par exemple de 15m pour une fréquence minimale de 10Mhz et de 1,9m pour une fréquence de 80Mhz. L’utilisation de la plus faible fréquence nuit toutefois à la résolution en distance du système puisque la fréquence est inversement proportionnelle à l’écart-type de la mesure sur chaque pixel [32]. Pour combiner les deux effets et obtenir de meilleures précisions et de plus grandes distances, plusieurs fréquences peuvent être combinées [33]. Par ailleurs, la combinaison de plusieurs fréquences permet d’augmenter la distance maximale en combinant trois valeurs de phase différentes pour retrouver un point de rencontre commun [33].
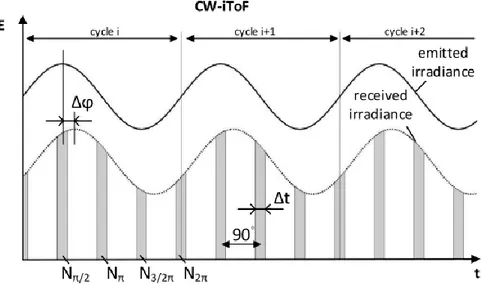
Figure 1.9 – Représentation d’un système CW-iToF. En ligne continue, un signal sinusoïdal envoyé par des DELs et en pointillé ce même signal réfléchi sur un pixel. Dans le cas présent, des échantillons sont effectués à chaque différence de pi/2 sur une intégration de ΔT sur plusieurs cycles. [17].
Afin de pouvoir comparer la différence de phase, il faut d’abord convertir le signal lumineux en signal électrique analysable. La démodulation peut être faite par les mêmes méthodes utilisées dans le domaine des radiofréquences, soit les méthodes hétérodyne et homodyne et par corrélation. La méthode la plus utilisée dans les systèmes ToF par son implémentation simple est la méthode par échantillonnage. Cette méthode est décrite à la figure 1.9. L’avantage de cette méthode est que les intégrateurs de courte durée sont en courant; permettant donc des systèmes robustes au bruit [28].
1.1.3. Cas spécifique de la Kinect v2 de Microsoft
La Kinect v2, ou Kinect pour Xbox One [34], est une caméra ToF utilisant le principe du CW-iToF décrit précédemment. Il a été choisi de présenter plus en détail son fonctionnement dans la présente section, puisqu’il
13
s’agit du système ayant été modifié au cours du projet. Les principaux composants de la Kinect v2 sont représentés à la figure 1.10.
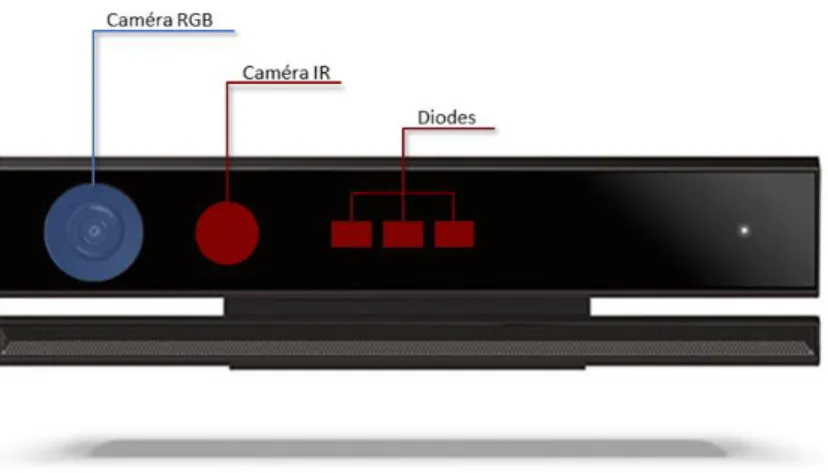
Figure 1.10 – Kinect v2 représentée avec ses principaux composants : caméra RBG, caméra NIR ainsi que trois diodes laser et leur diffuseur.
Les diodes IR émettent des signaux modulés à trois fréquences différentes de 16Mhz, 80Mhz et 120Mhz. Ces trois fréquences sont alternées successivement. Le signal a été mesuré par Giancola et al. [35] et est présenté à la figure 1.11. La longueur d’onde utilisée est de 860nm et des filtres sont situés avant la caméra pour éliminer une grande partie du signal ambiant [36], [37]. Ces trois fréquences donnent une distance maximale théorique associée à la fréquence de 16Mhz de 9,375m. Toutefois, en utilisant la méthode de calcul alternative [33], on pourrait atteindre une distance de 18,75m tel qu’appliqué par [38]. Dans le cas présent, la limite de 18,75m est déterminée puisqu’il s’agit de la distance à partir de laquelle le set de valeur associé par chaque mesure aura une ambigüité, tel que présenté à la figure 1.12. Avec la suite de développement (« SDK 2.0 ») fourni par Microsoft, la distance maximum est fixée à 8 mètres.
14
Figure 1.11 – Signal de trois fréquences émises successivement par la Kinect v2. Les mesures montrent trois fréquences différentes de 80MHz, 16MHz et 120MHz (de haut en bas). On remarque également la présence d’harmoniques supérieures. [35]
La méthode d’acquisition de la Kinect utilise le principe du pixel différentiel composé de la section A et de la section B. Lorsque l’horloge est active, le senseur capte sur la section A, et lorsque l’horloge est inactive le senseur capte sur la section B. Le résultat composé de (A-B) fournit alors l’information de phase, (A+B) fournit une image par la lumière ambiante et √∑(𝐴 − 𝐵)2 fournit une image active, c’est-à-dire la scène illuminée
uniquement de l’illumination du dispositif [36]. Le SDK 2.0 permet uniquement d’obtenir l’image active ainsi que l’image de distance, il est donc possible que le circuit intégré de la Kinect v2 sorte uniquement le signal (A-B) qui est d’intérêt lors d’une mesure de distance.
15
Figure 1.12 – Différence de phase associée à chacune des trois fréquences en fonction de la distance mesurée. Jusqu’à la ligne pointillée à 18,75m, la combinaison des trois mesures de phase est unique et permet donc de lever l’ambigüité sur la distance.
Le senseur est constitué de 512x424 pixels de 10um de « pixel pitch » [37]. Plus logiquement, on estime plutôt à 10,1um la distance réelle de centre-à-centre, pour une taille effective du pixel de 10um et une distance entre les pixels de 0,1um. Le terme « pixel pitch » est parfois utilisé de manière erronée dans la littérature. L’opération de calcul de distance est effectuée pour chacun des pixels indépendamment, il fournit donc une mesure de distance par pixel.
Le fonctionnement du pilote logiciel de la Kinect v2 a été analysé pour montrer que, à chaque acquisition d’une image de distance, 10 mesures sont faites au total [39]. Trois déphasages différents sont utilisés pour chacune des fréquences (0, 2π/3 et 4π/3); cette méthode permet de réduire au maximum l’effet de la présence des harmoniques supérieurs dans le signal [40]. L’utilisation de la 10e mesure n’est pas clairement définie. Le SDK 2.0 pour la Kinect v2 fournit directement la distance z pour un pixel donné. Davantage d’informations sur la reconstruction 3D de la Kinect vont être présentées ultérieurement.
Lors de la procédure d’acquisition, l’ouverture de la caméra reste constante à f/1.07. Pour chacune des mesures (i.e. pour chaque déphasage différent) deux temps d’intégration utilisés, soit 100us et 1000us. La mesure retenue pour le calcul de distance est celle de la plus longue période d’intégration n’étant pas saturée, et ce,
16
pour chaque pixel individuellement. Cette méthode permet d’obtenir une mesure plus précise sans saturer le pixel.
1.2.
Sources d’erreurs associées aux caméras ToF
Les principales sources d’erreurs présentes dans les caméras ToF seront discutées dans cette section. Il est important à cette étape de distinguer les termes utilisés dans le présent document. La précision sera l’équivalent du terme anglais « precision » et représente la résolution temporelle, soit l’écart-type du signal lors de plusieurs acquisitions. L’exactitude est l’équivalent du terme anglais « accuracy » et est déterminée par l’écart entre la valeur réelle et la valeur mesurée par une référence. La distinction est importante puisqu’un capteur très précis pourrait être totalement inexact. Dans le cas d’une caméra ToF, la précision dépend davantage du signal lumineux perçu par le senseur. L’exactitude sera quant à elle affectée principalement par l’erreur circulaire et par la qualité de la calibration photogrammétrique, mais également par les autres sources d’erreurs.
Cette sous-section décrit en premier lieu les erreurs aléatoires, composées des erreurs sur l’amplitude, des multiples réflexions, des réflexions internes et des erreurs sur la dimension du pixel. Ensuite, les erreurs systématiques et pouvant être compensées par calibration sont présentées : erreur circulaire, erreur de phase sur le pixel, erreur sur la reconstruction 3D et erreur associée à la température.
1.2.1. Ratio signal sur bruit
Dans une caméra ToF, la précision du capteur est directement associée avec la quantité de lumière reçue par le senseur. Lorsque l’amplitude reçue est plus faible, le bruit sur la mesure de distance sera plus important et vice-versa jusqu’à la saturation du pixel qui causera alors une mesure de distance invalide. En fait, l’écart-type d’une caméra ToF est inversement proportionnel à l’amplitude du signal sur le pixel [41], selon l’équation 3.
𝛔
𝐝∝
𝟏𝐀𝐩𝐢𝐱𝐞𝐥 (3)
Les sources de bruit présentes pour une caméra ToF sont les mêmes que pour un capteur CCD ou CMOS conventionnel. Il s’agit du cumul de trois catégories de bruit : (1) bruit quantique, (2) bruit de conversion et (3) bruit numérique. La deuxième catégorie inclut tous les bruits altérant la conversion du signal optique en signal analogique dans le CCD en influençant le nombre de paires électron-trou. Notamment, le bruit thermique, le bruit kTC, le bruit de scintillation et le bruit introduit par le « dark current » en sont inclus; toutes ces contributions augmentent en fonction de la température. Le bruit numérique est le bruit associé au passage du signal analogique en signal numérique. Finalement, le bruit quantique (« shot noise ») est le bruit le plus important
17
dans les caméras ToF et constitue la limite théorique puisqu’il s’agit de la source de bruit ne pouvant être éliminée; seul un moyennage permet d’en limiter les effets. La limite théorique de la résolution d’une caméra ToF limitée uniquement par le bruit quantique est donc déterminée par l’équation 4 dans le cas d’un calcul utilisant 4 points d’échantillonnage [28].
𝐫𝐞𝐬
𝐭𝐡é𝐨=
𝐜 𝟐𝐟𝐦𝐨𝐝√𝟖√𝐦𝐬+𝐦𝐚
𝟐𝐀 (4)
Où ms et ma représentent respectivement le nombre de photoélectrons produit par la moyenne du signal et de la luminosité ambiante, fmod la fréquence utilisée. A est l’amplitude du signal analogique, dépendant donc du contraste de démodulation du pixel, mais également du signal optique de retour. Cette équation montre également que la précision dépend de la luminosité ambiante. Pour cette raison, en plus d’éviter la saturation des pixels, les capteurs ToF fonctionnent généralement avec un filtre spectral NIR autour du spectre fourni par l’illumination. Également, les capteurs comme la Kinect ou ceux de PMDtec limitent électroniquement l’impact de la luminosité ambiante en utilisant des pixels différentiels, voir « Cas spécifique de la Kinect v2 ». Les pixels ayant une amplitude trop faible peuvent également subir un effet de discrétisation [31]. Un effet de moyennage sur un tel signal produira des pixels flottants.
Puisque cette erreur dépend de l’amplitude, tout ce qui vient affecter l’amplitude peut affecter la précision du capteur. Notamment, un objet à plus grande distance sera moins illuminé qu’un objet proche et la réflectivité de la surface influencera également la mesure. Une surface à angle perd de l’intensité selon sec(𝜃).L’intensité distribuée est inversement proportionnelle à l’inverse du carré de la distance (équation 5).
𝐈(𝐫) ∝
𝟏𝐫𝟐 (5)
De manière générale, il s’agit donc d’une erreur aléatoire; toutefois, certains comportements constants peuvent être identifiés pour un système donné. Le système d’illumination peut être non uniforme dans le champ de vue, engendrant une précision sur la distance non uniforme dans le champ de vue. Également, l’optique permettant de rediriger les rayons n’envoie généralement pas la lumière uniformément sur le senseur et introduit donc une perte d’intensité, souvent en bordure du senseur.
Certaines méthodes peuvent être utilisées afin de limiter les mesures erronées par les erreurs associées à l’amplitude. Notamment, les pixels saturés lors de la prise de mesure peuvent être simplement filtrés. De même, lorsque le signal est très faible et que l’erreur est donc plus importante, il est possible de fixer un seuil éliminant ces données invalides [42],[43]. Cette méthode peut néanmoins exclure plusieurs pixels du champ de vue. Certaines procédures plus complexes peuvent être utilisées afin de modifier le temps d’intégration pour diverses
18
zones du senseur. Une méthode commune demeure le moyennage qui permet d’obtenir une valeur plus précise [41], [44].
1.2.2. Multiples réflexions
Ce type d’erreur est imprévisible dans la mesure où il dépend de la géométrie de la scène observée. Cette erreur est causée par le fait que l’illumination produite peut être réfléchie plusieurs fois avant d’atteindre le pixel. L’erreur peut également survenir lorsque le signal reçu est une moyenne de deux signaux. La figure 1.13 montre cette situation se produisant au croisement entre deux murs. Certains objets concaves peuvent même produire soit des discontinuités lorsque le signal n’est pas réfléchi vers le capteur ou des pixels flottants lorsque le signal est réfléchi sur des surfaces spéculaires
Figure 1.13 – Schématique représentant les multiples réflexions à un coin. Les réflexions ayant un temps de parcours plus long produisent une déformation sur la mesure de distance telle que présentée dans la portion de droite. [45]
La correction de multiples réflexions est difficile puisqu’elle dépend de la scène et qu’un simple moyennage ne permet pas d’éliminer cet effet. Il est important de préciser que deux formes de cette erreur peuvent survenir : les réflexions multiples provenant d’une surface lambertienne et les réflexions spéculaires. La plupart du temps, les méthodes reposent sur l’utilisation de plusieurs fréquences afin d’effectuer la correction. Les premières méthodes utilisaient des algorithmes itératifs et n’étaient pas suffisamment efficaces pour permettre leur utilisation en temps réel puisqu’elles pouvaient prendre jusqu’à plusieurs minutes de traitement par acquisition [46]. De nouvelles méthodes, notamment celle présentée par Microsoft permettent d’obtenir des résultats en temps réel et sont basées sur l’algorithme SRA (« Sparse Reflection Analysis ») qui détermine les réflexions spéculaires avec plusieurs réflexions et les réflexions diffuses [47].
19
D’autres approches ont été investiguées afin de minimiser ces erreurs, notamment d’utiliser la lumière structurée en bonification au système original ou bien d’augmenter le nombre de fréquences utilisées par le capteur [48]– [50].
1.2.3. Réflexions internes
Ce type d’erreur est similaire à celui des multiples réflexions à la différence qu’il est causé par des réflexions internes dans le capteur, tel que représenté à la figure 1.14. Cela se produit principalement lorsqu’un objet réfléchissant une grande proportion du signal se trouve dans le champ de vue. Un objet proche agit à ce titre en raison de la décroissance en r2 de l’intensité lumineuse pour les objets éloignés. Le fort signal réfléchi par cet objet se réfléchit au sein même du capteur et s’ajoute aux signaux plus faibles sur les pixels avoisinants, produisant alors un biais sur le ToF : le plus long tracé de rayon du ToF peut modifier la phase perçue par le senseur puisque ce dernier capte l’addition des deux signaux.
Figure 1.14 – Visualisation de l’effet de dispersion dans le cas d’une caméra ToF. Dans ce cas, l’objet 1 proche vient affecter la mesure des objets 2 et 3. [51]
Ce type d’erreur (« scattering », en anglais) a été modélisé comme une addition linéaire au signal complexe par [52]. D’autres travaux ont par la suite permis de réduire l’erreur causée par les réflexions internes de 60% dans le cas d’un SR-3000 [53].
20
1.2.4. Dimension du pixel
L’erreur sur la dimension du pixel (« mixed pixel ») est présente dans tous les capteurs ToF utilisant un senseur composé de plusieurs pixels. Elle s’explique simplement par le fait que le pixel a une dimension finie. Par exemple, dans le cas d’un capteur ayant 100 pixels pour 50 degrés de champ de vue, la dimension du pixel à 5m serait alors de 4,36cm. Le signal reçu par un pixel donné sera alors la moyenne du signal dans cette zone, induisant une erreur dans le cas d’une surface comportant des pores ou toute rugosité. Dans le cas où il s’agit d’une bordure d’un quelconque objet, cela peut mener aux pixels flottants (« flying pixels ») caractéristiques des caméras ToF [54].
1.2.5. Erreur circulaire
Ce type d’erreur s’applique aux caméras ToF indirectes utilisant un mode CW et dépend de la distance de mesure, d’où pourquoi elle est souvent qualifiée de « depth distortion » en anglais. Cette erreur a été expliquée assez tôt dans la littérature [28] et est présente en raison d’un signal d’envoi imparfait par rapport à celui attendu. Notamment, lors de l’envoi d’un signal sinusoïdal par la source, il est possible de contenir des ordres supérieurs. Il a été identifié que, dans le cas d’un signal sinusoïdal, il s’agit en fait de la présence d’harmoniques impaires d’ordre supérieur dans le signal d’envoi produisant les erreurs circulaires. Son nom, « circular error » ou « wiggling error » en anglais, provient d’ailleurs du comportement de cette erreur qui tend à osciller en fonction de la distance selon une courbe sinusoïdale. Ce comportement typique a été modélisé théoriquement dans le calcul du dépliement de phase (unwrapping) dans [28] et confirme les mesures expérimentales [55], [56] puisque l’erreur sur la phase se répercute directement sur la distance. La figure 1.15 montre le résultat de la modélisation dans le cas d’un signal sinusoïdal parfait et d’un signal comportant une harmonique.
Figure 1.15 – Première ligne : signal modulé, Deuxième ligne : courbes montrant la phase réelle ainsi que la phase calculée par une caméra ToF, Troisième ligne : erreur simulée sur la phase (y) en fonction de la phase totale du signal (x) en utilisant quatre échantillons. [28]
21
Le comportement de l’erreur est similaire en fonction de l’envoi d’un signal carré qui ne sera pas, en réalité, parfaitement carré et pourra posséder des bordures linéaires ou en exponentielle décroissante. En fait, il est montré par la même modélisation qu’à la figure 1.15 même un signal carré parfait introduira une erreur circulaire.
Ce type d’erreur est systématique pour un système et peut donc être calibré en utilisant un autre capteur comme valeur de comparaison (« ground truth ») [57], [58], [59]. Les résultats peuvent donc être tenus dans une table de valeurs ou bien peuvent être modélisés par B-Spline [57], [59] ou par un polynôme de degrés différents.
Il est à préciser que le temps d’intégration vient modifier l’erreur circulaire et que, dans ce cas, une calibration devrait être effectuée pour chaque temps d’intégration utilisé, ce qui rend un mode automatique compliqué à calibrer. La cause exacte de cette modification n’est pas connue précisément, mais elle ne serait pas reliée à l’intensité lumineuse puisque les courbes demeurent similaires en fonction de la distance, mais ont un écart, tel que montré dans des courbes expérimentales pour le SR-3000, le PMD 19k et le Effector O3D [41]. Dans [28], on remarque également une modification de l’allure de la courbe d’erreur selon leur modélisation. Une hypothèse serait que le temps d’intégration vient directement affecter la démodulation en fréquence utilisant certains points, modifiant alors l’aliasing puisqu’une partie plus ou moins grande du signal est échantillonnée.
1.2.6. Erreur de phase sur le pixel
L’erreur de phase sur le pixel est associée d’une part aux imperfections de la manufacture des pixels puisque chaque pixel n’est pas nécessairement identique [55], [60], [61]. Cela produit toutefois une erreur constante pour chacun des pixels et peut donc être totalement annulé dans le cas où le résultat pour un pixel est une soustraction de deux mesures pour obtenir la différence de phase, tel qu’il est effectué dans les capteurs PMD 19k et Effector OD3 [41].
D’autre part, la position du pixel sur le senseur induit également une erreur puisque les senseurs sont généralement reliés en lignes ou en colonnes et causent donc une différence de phase augmentant graduellement, plus le pixel est distancé du générateur de signal. Également, chacun des pixels a sa propre capacitance; produisant un léger délai supplémentaire sur la phase de référence.
Ce type d’erreur est similaire au FPN (Fixed-Pattern Noise) associé aux caméras 2D standards. De manière similaire aux méthodes développées pour les caméras 2D, une calibration peut être effectuée considérant chacun des pixels individuellement et être inclus dans la calibration de l’erreur circulaire par une fonction
22
considérant la position de chacun des pixels [43]. Ce type d’erreur est toutefois moins important que les autres types d’erreurs systématiques précédemment mentionnés. Dans le cas du SR-3000, il est estimé que moins de 9% de l’erreur combinée entre erreur circulaire, erreur due au temps d’intégration et erreur sur le pixel est associée à cette dernière.
Alors que l’erreur circulaire peut être calibrée utilisant seulement les pixels centraux, ce qui est plus simple à effectuer en laboratoire, chacun des pixels possède ici leur propre erreur sur la distance. La calibration est donc plus difficile puisque la méthode de calibration est difficile à séparer de l’erreur associée à l’amplitude, qui variera en fonction de la cible, de la distance ainsi que du patron d’illumination. En utilisant une cible plane par exemple, chacun des pixels n’est pas exactement à la même distance ni à la même illumination. Une difficulté supplémentaire s’ajoute également puisque l’erreur sur la reconstruction 3D du pixel s’additionne dans le cas du test sur un plan droit par exemple.
1.2.7. Erreur sur la reconstruction 3D
Alors que les précédentes erreurs concernent la capacité du temps-de-vol à déterminer la bonne distance « ρ » du senseur jusqu’à la cible, l’erreur sur la reconstruction concerne la capacité à obtenir la bonne projection de cette distance « ρ ». Cette mesure est importante puisque c’est ultimement cette information qui permettra au capteur d’imager une scène en 3D puisqu’elle fait le lien entre la distance obtenue par l’aller-retour du time-of-flight et la position x,y,z du pixel. Cette erreur est minimisée à l’étape de calibration photogrammétrique de la caméra et se quantifie généralement par l’erreur de reprojection, voir la section « Calibration » pour plus d’informations.
1.2.8. Température
La température a également un effet certain sur la prise de mesure d’une caméra ToF en influençant directement la mesure de distance. La principale raison derrière ce phénomène est associée aux semi-conducteurs et au bruit thermique associé par une augmentation de la température dans le senseur lui-même au cours du temps d’acquisition, tel qu’il a été mesuré pour différents capteurs [60] à la figure 1.16. Une autre raison possible est la performance du système d’illumination qui peut varier en fonction de la température et ainsi s’ajouter à l’erreur thermique du senseur.
23
Figure 1.16 – Test sur la mesure de distance d’un mur à 1,2m de distance en fonction du temps d’utilisation de l’appareil. 10x10 pixels au centre du senseur ont été utilisés. [60]
De manière évidente, la température externe d’utilisation a aussi une influence sur les performances d’un capteur ToF puisque la température d’équilibre atteinte sera alors différente, ainsi que la mesure [58]. Ce type d’erreur est toutefois systématique et peut donc être calibré; le modèle de calibration inclura alors l’impact de l’erreur du senseur ainsi que de celle du système d’illumination, s’il y a lieu.
1.3. Outils utilisés
1.3.1. CloudCompare
« CloudCompare » est un logiciel libre ayant été conçu à l’origine pour la comparaison entre deux nuages de points (NdP) ou entre un NdP et un maillage (« mesh », représentation 3D). Il a par la suite été élaboré avec diverses fonctionnalités pour le traitement des NdP, notamment la manipulation, la segmentation, le filtrage, l’échantillonnage, l’élaboration de statistique et de visualisation. D’autres outils similaires, notamment
24
PointCloud Library (PCL), peuvent faire le même type de manipulation [62]. Pour les besoins du présent mémoire, CloudCompare fournissait suffisamment d’outils pour le traitement. La plupart du temps, Matlab était utilisé pour le traitement des données sauf lorsqu’il s’agissait de comparaison entre deux NdP; ces outils ayant déjà été intégrés dans CloudCompare. La transition entre Matlab et CloudCompare se faisait aisément puisque CloudCompare lit les formats communs de NdP comme le format « ply » ou « pcd ».
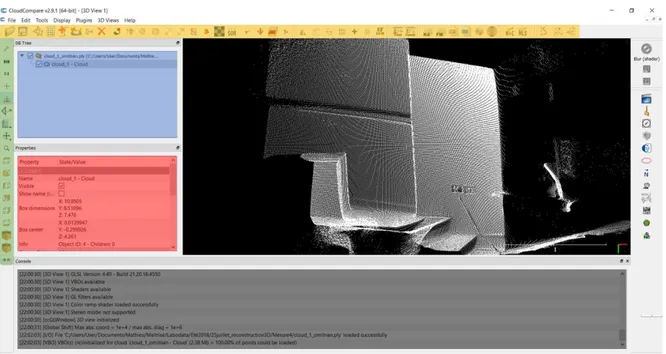
L’interface graphique permet une utilisation simple des principaux outils, tels que présentés à figure 1.17.
Figure 1.17 – Interface graphique de CloudCompare présentant une scène arbitraire en trois dimensions. En bleu, feuille de travail comportant les NdP utilisés; en vert, les différentes méthodes de visualisation; en rouge les caractéristiques du NdP; en gris, l’historique des manipulations et de couleur or les principales applications du logiciel sur le traitement des NdP.
Le site internet en référence fournit beaucoup de documentation sur les aspects du logiciel ainsi que sur les méthodes employées lors des calculs [63]. Deux outils ont été régulièrement utilisés, notamment le filtrage statistique et la comparaison de deux NdP.
Le filtrage statistique (Statistical Outlier Filter, SOF) présent dans CloudCompare est très similaire à celui implémenté dans PCL [64]. L’algorithme calcule la distance du voisinage moyen d’un point à ses k voisins les plus proches, puis rejette les points situés plus loin que la moyenne additionnée de n fois l’écart-type. Ce type d’algorithme est utilisé pour filtrer un nuage de points comportant un bruit important et peut être utilisé pour éliminer les pixels flottants associés aux caméras ToF.
25
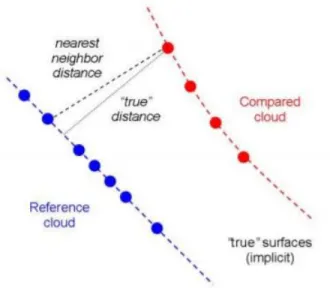
La distance entre deux nuages de points peut être calculée par simple différence au plus proche voisin. Cette approche peut toutefois mener à un calcul inexact puisque la distance réelle, telle que présentée à la figure 1.18, est rarement la distance au plus proche voisin. Différentes approches peuvent être utilisées pour minimiser cette erreur. La première est de comparer directement le nuage avec un maillage de référence; obtenir ce type de modélisation n’est pas toujours aisé. Des méthodes alternatives de modélisation locale existent, mais n’ont pas été utilisées dans le présent document puisque leur utilisation peut changer le résultat dépendamment des nuages analysés et que la méthode peut introduire des erreurs locales. Par souci de comparaison, l’approche du plus proche voisin a été utilisée. Également, dans le cas actuel, l’erreur de modélisation est jugée faible par rapport à l’erreur de positionnement entre le nuage de référence et le nuage analysé. L’algorithme ICP de la section suivante permet de minimiser l’erreur de positionnement et constitue l’une des manières retenues pour l’ajustement.
Figure 1.18 – Distance réelle comparativement à la distance du plus proche voisin. La distance réelle est plutôt la distance entre le point comparé et la surface de référence.
1.3.2. Algorithme ICP
L’algorithme ICP (« Iterative Closest Point ») [65] est fréquemment utilisé dans le domaine 3D pour recaler deux objets similaires, soit l’objet de référence (modèle) et l’objet data (registered). L’objet data sera celui qui sera déplacé par une transformation matricielle afin de minimiser l’écart entre chacun des points des deux objets. Évidemment, les objets prennent la forme de nuages de points (NdP) quelconque, lorsque deux conditions sont respectées : (1) les nuages de points doivent avoir la même forme (représenter une scène équivalente) et (2) ils doivent être déjà préalignés. Plusieurs variantes de cet algorithme sont présentes dans la littérature, mais toutes utilisent ces mêmes bases [66].
26
Le premier point n’est pas une condition en soi puisque l’algorithme est généralement utilisé dans ce but précis, toutefois, il est possible que certaines portions des deux NdP ne soient pas des régions communes. Il ne pourra donc pas y avoir de correspondance entre ces points. Certains algorithmes comme celui présenté dans CloudCompare utilisent une fonction permettant d’ajuster le pourcentage de compatibilité entre les deux NdP.
Le second point est une nécessité de l’algorithme ICP afin de réduire la présence des minimums locaux de l’algorithme itératif; bien que la solution optimale pourrait malgré tout être déterminée. Ce pré-alignement est souvent effectué en robotique mobile par l’application d’une matrice déterminée par la translation du robot (gps, odométrie) et la rotation de celui-ci mesurée mécaniquement. Ces systèmes mécaniques présentent toutefois des erreurs; l’algorithme ICP entre alors comme dernière étape dans les techniques de SLAM pour recaler les NdP successifs de la même scène [67]. Une méthode de préalignement est disponible dans CloudCompare à cette fin.
Les entrées de l’algorithme ICP de base sont : (1) le modèle, (2) le NdP à ajuster ainsi que (3) un paramètre sur l’erreur résiduelle (RMS) ou sur le nombre d’itération maximal. La sortie sera la matrice de transformation permettant de transposer le NdP data sur le modèle. La procédure d’implémentation [66] est généralement décrite en 4 étapes :
1) Associer les points similaires entre les deux NdP
2) Calculer la transformation nécessaire pour minimiser le RMS point à point de tous les points présents 3) Appliquer la transformation au NdP data
4) Recommencer à l’étape 1 jusqu’à l’atteinte du critère RMS ou du maximum d’itération
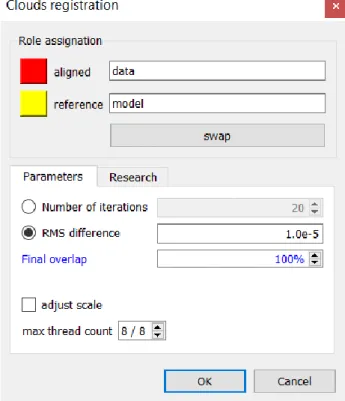
Dans le cas du ICP implémenté dans CloudCompare, le menu est celui représenté à la figure 1.19. Cette variante du ICP permet d’ajuster le facteur d’échelle entre les deux NdP ainsi que le pourcentage de coïncidence entre les deux NdP.

![Figure 1.2 – Schéma de triangulation utilisant la valeur x̂ minimisant l’erreur de reprojection [7]](https://thumb-eu.123doks.com/thumbv2/123doknet/3275563.93967/16.918.304.623.566.792/figure-schéma-triangulation-utilisant-valeur-minimisant-erreur-reprojection.webp)
![Figure 1.4 – Schématique d’une détection par lumière structurée utilisant de multiples longueurs d’onde pour discriminer les angles de projection [13]](https://thumb-eu.123doks.com/thumbv2/123doknet/3275563.93967/18.918.285.628.108.399/schématique-détection-structurée-utilisant-multiples-longueurs-discriminer-projection.webp)