CyCLaDEs: A Decentralized Cache for Triple Pattern Fragments
Texte intégral
Figure
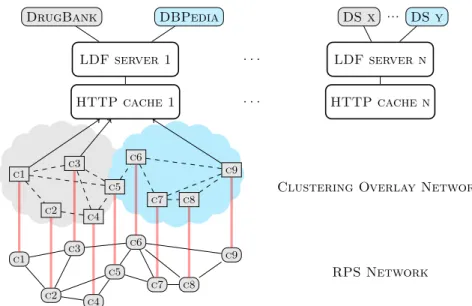
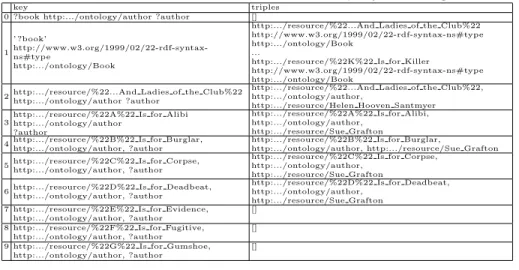
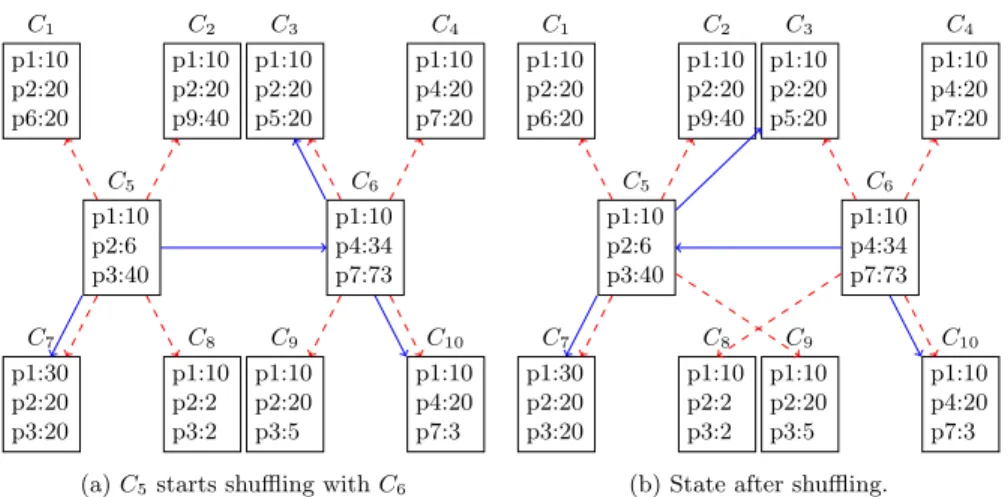
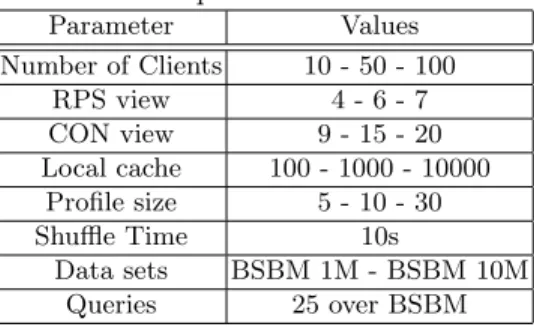
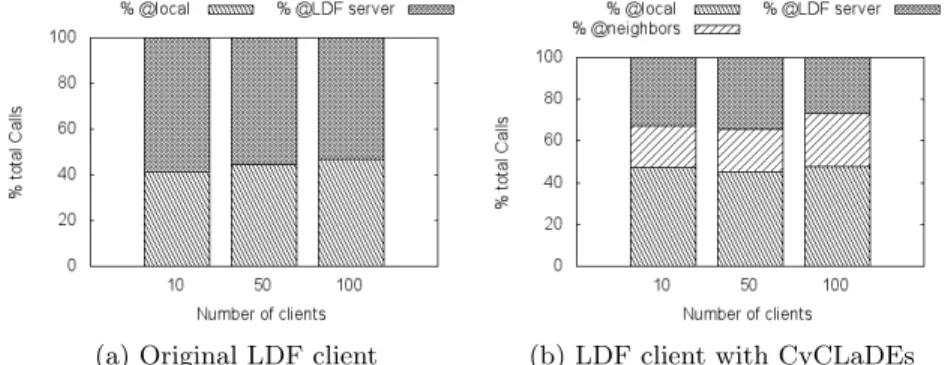
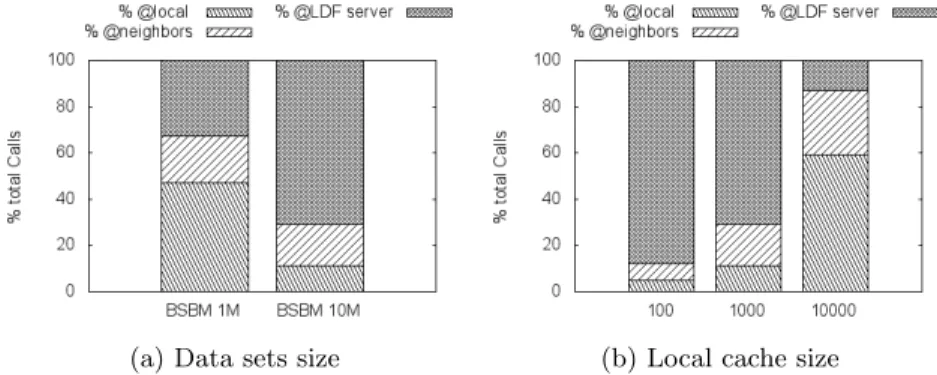
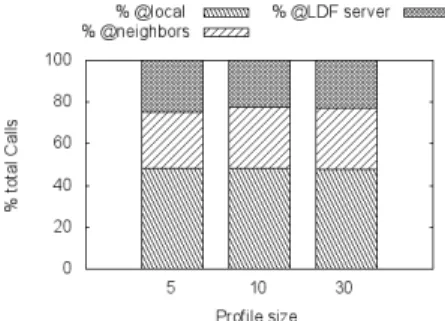
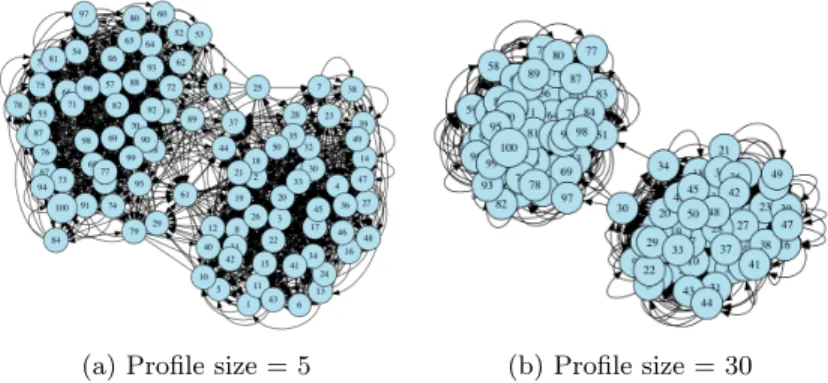
Documents relatifs
Keywords: Environmental information systems, Generic data model, Master data, Time series, Spatial data, Semantics, Schema, Microservices, REST, Web portals, Mobile
Because of its proven good performance, we can now recommend the use of the LRU eviction policy in LISP caches, at least for traces that present an approximate time
If, e.g., the requirement is to have an RRC uniq of at least 11 for all get operations in the network with 5000 nodes and with high churn (Figure 4), a k value of 40 is sufficient..
In fact, in the cache eviction function, the utilization is the ratio of the number of times an eviction is performed in node j (N evictions) over the number of time a content is
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Retrouve les objets dans l’image et
Retrouve les objets dans l’image et
Retrouve les objets dans l’image et
