OUMAR TOURE
A N A L Y S E C R I T I Q U E D ' U N E E C H E L L E D ' A T T I T U D E D E S E N S E I G N A N T ( E ) S A L ' E G A R D D E L ' U T I L I S A T I O N D E S O B J E C T I F S P E D A G O G I Q U E S E N C L A S S E Mémoi re présentéà l’École des gradués de l ’Université Laval
pour l ’obtention
du grade de Maître es arts (M.A.)
FACULTE DES SCIENCES DE L ’EDUCATION UNIVERSITE LAVAL
QUEBEC
OCTOBRE 1988
LIVRES RARES ] '* £ ’
RESUME
Le but de cette recherche est principalement de questionner la
validité de construit et la validité de contenu de l'échelle d ’attitude des enseignant(e)s à l’égard de l’utilisation des objectifs pédagogi
ques en classe réalisée par Dufresne (1986). Comme la validation d'un
test quelconque se ramène fondamentalement au questionnement des
qualités et prétentions que lui confèrent ses auteurs, nous avons
soumis l'E.A.O.P. de Dufresne (1986) à ce questionnement. Nous avons
eu recours à des experts et à une technique d ’analyse statistique (en l ’occurrence l ’analyse factorielle) pour voir dans quelle mesure les fondements théoriques de la démarche de Dufresne (1986) concordent avec
la réalité vécue. Pour ce, nous avons indiqué aux experts de répartir
les items du questionnaire de la dite échelle entre les cinq facettes
théoriques du construit mesuré. Cette première démarche a indiqué
q u ’il y avait un déséquilibre non seulement dans la répartition des
items entre les facettes mais aussi au niveau des items favorables et
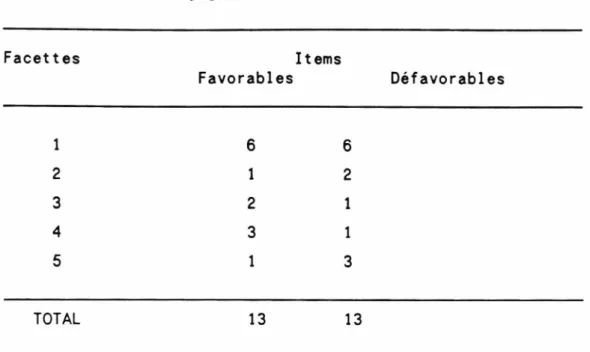
défavorables au sein d ’une même facette. En effet, les experts ont noté
que la facette 1 regroupait 47% des items, que la facette 2 en regrou
pait 17%, que les facettes 4 et 5 en regroupaient 13% et que la
facette 3 en regroupait 10%. Ils ont aussi noté qu’au niveau de la
facette 1 , il y avait 6 items favorables pour 8 items défavorables;
qu’au niveau de la facette 2, il y avait 3 items favorables pour 2
items défavorables; qu’au niveau de la facette 3, il y avait 2 items
favorables pur 1 items défavorable; qu’au niveau de la facette 4, il y
avait 3 items favorables pour 1 item défavorable; qu’au niveau de la
Enfin, l’analyse factorielle des données d ’une enquête réalisée auprès de 387 enseignant(e)s de la région 03, au sujet de l ’utilisation des objectifs pédagogiques révèle un seul facteur principal qui semble
être la facette 1 du construit mesuré. Cela dénote, à notre avis, une
relative faiblesse de la validité de construit et de la validité de
REMERCIEMENTS Je Valiquet dirigé exaltant docteur mémoi re
Mes derniers remerciements mais Laroche pour avoir dactylographié ce
Richard Girard et Claude te recherche et m ’avoir ois pénible mais combien
ais aussi remercier le
e le co-directeur de mon cept ionnelles.
non les moindres vont à Louise
mémoi re.
voudrais ici remercier les docteurs
te pour m ’avoir suggéré l’idée de cet
tout au long de ce processus parf
, stimulant et formateur. Je voudr
Jacques Plante pour avoir accepté d ’êtr dans des circonstances pour le moins ex
TABLE DES MATIERES
Résumé i
Table des matières iii
CHAPITRE 1. 1
1.1 Les objectifs pédagogiques et la réussite scolaire 2
1.2 Les attitudes des enseignants sur la réussite
scolaire des étudiants 6
1.3 Problématique 8
CHAPITRE 2. 13
2.1 Introduction aux études sur la validité 14
2.2 La validité: sa nature et ses mesures 15
2.2.1 La validité de contenu 18
2.2.1.1 Validité apparente 19
2.2 .1.2 Validité logique ou d ’échantillonnage 19
2.2.1.3 La subtilité d'un item 20
2.2.1.4 Validité de substance 20
2.2.1.5 La validité du contenu 20
2.2.1.5.1 La représentativité des
objectifs 21
2.2.1.5.2 Le pairage des items avec
les objectifs 22
2.2.1.5.3 Les aspects de l’item à
examiner par les juges 23
2.2.1.5.4 Le sommaire des résultats 23
2.2.2 Validité reliée au critère 25
2.2.2.1 Validité prédictive 25
2.2.2.3 La validité concurrente 27
2.2.2.4 La validation reliée au critère 27
2.2.2.4.1 Critère 29 2.2.2.4.2 Contamination du critère 30 2.2.2.4.3 Restriction de l’étendue 30 2.2.2.4.4 Fidélité du critère et du prédicteur 31 2.2.3 La validité de construit 31 2.2.3.1 La validation du construit 32
2.2.3.1.1 La méthode des corrélations 33
2.2.3.1.2 La méthode dite de diffé
renciation entre groupes 34
2.2.3.1.3 L ’analyse factorielle 34 2.2.3.1.4 La méthode de la matrice multitrait-multiméthode 34 2.3 Questions de recherche 35 2.4 Limites de la recherche 37 CHAPITRE 3. 39 3.1 Méthodologie 40 3.1.1 Introduction 40 3.1.2 Méthodologie 41 3.1.2.1 Pré-expérimentation 41 3.1.2.2 Expérimentation 41 3.1.2.3 Analyse d ’items 42
3.1.2.4 Analyse des résultats 43
3.1.2.5 Conclusion 43
3.2 Critique de l’E.A.O.P. 44
3.2.1 Critique de la pré-expérimentation 44
3.2.1.1 Les juges: leur sélection et
leurs rôles 44
3.2.1.2 Répartition des items entre les
facettes du construit 45
3.2.1.3 L ’échantillonnage 46
3.2.2 Critique de l’expérimentation 46
3.2.3 Analyse d ’items 47
3.2.3.1 Epuration des données 48
3.2.3.2 Analyse des items du questionnaire 49
CONCLUSION 68
INTRODUCTION
1.1 Les objectifs pédagogiques et la réussite scolaire
1.2 Les attitudes des enseignants et la réussite scolaire
CHAPITRE 1
I ntroduct ion
A notre avis, procéder à une analyse critique d ’un instrument de
mesure, en l’occurence l ’E.A.O.P. de Dufresne (1986), consiste d ’abord à
cerner avec rigueur les nécessités qui ont présidé au cadre de son
élaboration. A cette fin, nous avons consacré le premier chapitre de notre
étude qui comprend trois parties principales toutes reliées à notre
objectif principal, soit l'instrument de mesure en question.
Dans un premier temps, nous avons procédé à une définition des
objectifs pédagogiques selon diverses perspectives et selon plusieurs
auteurs. Nous en avons esquissé les principaux avantages et inconvé
nients dans le cadre d ’un apprentissage scolaire. De ces diverses
définitions, nous avons retenu celle de Mager (1962) en raison de sa
concision et de son "opérâtionnalité" mais aussi et surtout parce que
c ’est elle qui a servi d ’ossature à l ’élaboration de l’échelle d ’attitude que nous questionnons dans notre étude.
Dans une deuxième temps, nous nous sommes penchés sur certaines
caractéristiques des enseignants, particulièrement leurs attitudes qui,
semble-t-il, ont une influence déterminante sur la réussite scolaire des
étudiants. Bref, nous avons postulé, tout comme de nombreux auteurs que
les attitudes des enseignants à l ’égard de l ’utilisation des objectifs
Autrement dit, la réussite scolaire des étudiants, que l’utilisation des
objectifs pédagogiques est censée faciliter, est déterminée dans une
certaine mesure par les attitudes des enseignants à l’égard de ces
objectifs.
Enfin, après avoir défini et clarifié les notions d'objectifs
pédagogiques, d ’attitude des enseignants et leurs relations possibles et probables sur la réussite scolaire des étudiants, nous avons en même
temps esquissé grossièrement le cadre de notre problématique. Nous avons
donc conclu ce premier chapitre en limitant notre problématique à une
critique rigoureuse et systématique mais aussi constructive d ’une échelle
d ’attitude censée mesurer les attitudes des enseignants à l ’égard de
l’utilisation des objectifs pédagogiques en classe.
1.1 Les objectifs pédagogiques et la réussite scolaire
La réussite scolaire a toujours été, est et demeure une des
préoccupations majeures des enseignants, des étudiants, des parents, des
chercheurs, bref de toute la société. De nombreuses études en éducation,
en sociologie et en psychologie lui sont consacrées notamment pour la
comprendre, l ’expliquer ou la provoquer (Bloom, 1956; Bobbitt, 1924;
Tyler, 1951). Plusieurs auteurs dont Bloom (1956), Rothkopf et Kaplan
(1972) estiment que la connaissance des objectifs pédagogiques a un impact positif sur les apprentissages scolaires, donc sur la réussite scolaire.
Le concept d ’objectif est intimement lié à celui de l ’éducation et
comme le souligne Peters (1966): l’un est essentiel à l'autre. En effet,
on éduque généralement vers l’atteinte d ’objectifs qu’ils soient généraux
ou spécifiques; il serait d ’ailleurs absurde d ’éduquer sans but, sans
objectif. Selon De Landsheere (1966), depuis toujours, les philosophes et les politiques ont assigné des objectifs à l’éducation. Donc, au-delà des querelles sur les finalités de l’éducation, on s ’entend généralement à lui reconnaître des objectifs qu’ils soient implicites ou explicites.
Les objectifs ne sont donc pas une nouveauté dans le monde de
l’éducation. Tout indique cependant qu’ils ne furent conceptualisés et
formalisés q u ’au début du XXe siècle. Bobbitt (1918) fut, semble-t-il, le
premier à les rationaliser et à vouloir les utiliser dans un cadre de
formation et d ’éducation. En effet, il posa d ’abord comme but général de
l’éducation la préparation à la vie adulte. Il proposa alors que soient
analysées les différentes activités sociales, civiques, religieuses,
sanitaires, etc. La production des étudiants, en particulier les erreurs
qu’ils commettent seraient aussi à analyser afin de savoir sur quel point
l’enseignement doit insister. Mais cette méthode systématique de formuler
des objectifs ne parait pas avoir toujours connu les succès que l’on en
escomptait. Ainsi, elle a connu diverses fortunes jusqu’au milieu des
années ’50 où la quête d ’une plus grande démocratie sociale et l’explosion
scientifique ont amené les théoriciens et les praticiens de l’éducation à
se pencher davantage sur les buts de l ’éducation (Tyler, 1951; Bloom,
1956).
Sans faire l ’unanimité tant au niveau de la définition q u ’à celui de
1 ’opérâtionnalisation des objectifs pédagogiques, les différents auteurs
sont arrivés tout de même à jeter les balises d ’une plus grande
systématisation des buts et des objectifs de l ’éducation. En effet, il
existe toute une kyrielle de définitions et d ’opérationnalisations tant la
controverse est grande dès qu’il s ’agit d ’objectifs. Pour essayer d ’y
voir un peu plus clair, ressassons les écrits de quelques auteurs qui se sont intéressés aux objectifs pédagogiques.
Girard (1974) définit un objectif comme une communication d ’inten
tion décrivant ce qui est attendu de la part de celui ou ceux à qui
s ’adresse cet objectif. Cette définition, plutôt générale, ne nous
satisfait pas lorsqu’on parle d ’objectifs pédagogiques car elle est muette
sur les moyens à prendre pour la réalisation dudit objectif et sur la
Pour Hameline (1980), un objectif est une intention pédagogique et
en ce sens, il aurait pu être remplacé par les mots: but ou dessein. Son
utilisation courante et généralisée tient davantage du "standing" du mot que de la précision qu’il est censé apporter car comme tous les mots, il a
comme fonction fondamentale d'entretenir l'ambiguïté autant que de la
dissiper (Jakobson, 1963).
Des auteurs tels que Gagné et Briggs (1974) définissent un objectif comme une action qui doit être entreprise pour déterminer les "capacités"
à apprendre. Il s ’agit là d ’une entreprise difficile car un objectif,
pour être compris de tous, doit être défini en termes clairs et précis.
Quant à Bloom et coll. (1956), ils définissent les objectifs
pédagogiques comme des formulations explicites des modifications
escomptées chez les élèves au cours d ’un processus éducatif. Pour Mager
(1962), un objectif pédagogique est un énoncé traduisant de façon
opérationnelle, c ’est-à-dire observable, communicable et mesurable, les
comportements visés à la fin d ’une séquence d ’enseignement. Mager (1969)
va encore plus loin dans l ’élaboration et le raffinement des objectifs
pédagogiques. En effet, il précise qu’un objectif est une intention
communiquée par une déclaration qui décrit la modification que l ’on désire provoquer chez l ’étudiant, déclaration précisant en quoi l ’étudiant aura
été transformé une fois qu’il aura suivi avec succès tel ou tel
enseignement.
Pour comprendre et analyser les objectifs pédagogiques, il faudrait
en saisir leur niveau abstrait (niveau auquel se situe les buts généraux
vers lesquels tendent les programmes, les écoles, etc.) et leur niveau concret (niveau où les objectifs sont définis en termes de comportement)
et distinguer les principales responsabilités impliquées. Goodlad (1969)
5
- les décisions sociales prises par le pouvoir public - les décision institutionnelles prises par les autorités
pédagogiques dans la ligne des décisions sociales
- les décisions d ’enseignement principalement prises par les enseignants.
Les objectifs sont décrits en termes ou généraux ou opérationnels.
Un objectif général est une communication d ’intention décrivant de façon
globale ce qui est attendu de la part de celui à qui s ’adresse l ’objectif
(Girard, 1974). Donc, par définition, un objectif général est nécessai
rement vague et inadéquat en ce qui concerne la construction d ’une
séquence d ’enseignement mais il est nécessaire à l’élaboration des
objectifs spécifiques. Un objectif spécifique est une communication
d ’intention décrivant le comportement attendu de celui à qui s ’adresse
l ’objectif à la suite d ’une intervention pédagogique (Girard, 1974). Au
niveau des objectifs spécifiques, on parle d ’objectifs intermédiaires et
d ’objectifs terminaux. L ’objectif qui est atteint à la fin d ’une unité
d ’enseignement ou d ’une séquence d ’apprentissage est appelé objectif
terminal (Girard, 1974). L ’objectif qui est préalable à cet objectif
terminal dans la séquence d ’apprentissage est appelé intermédiaire
(Girard, 1974).
Les psycho-éducateurs et les enseignants sont très divisés quant à
l ’utilisation des objectifs pédagogiques dans l ’enseignement. Quand bien
même plusieurs psycho-éducateurs (Bloom, 1956; Bobbitt, 1924; Tyler, 1951)
ont montré l’urgence de préciser les objectifs pédagogiques, ce n ’est
qu’après la publication du livre de Mager (1961) sur la formulation des
objectifs que le monde de l’éducation a commencé sérieusement à
s ’intéresser aux objectifs pédagogiques (Popham et Baker, 1965; Eisner,
1967; Dufresne, 1986).
Les tenants des objectifs pédagogiques mettent de l ’avant les
pédagogiques, sur les apprentissages prévus et non prévus, et sur la
cohérence générale des séquences d'apprentissage. Dans une étude sur la
spécificité des objectifs pédagogiques et le rendement scolaire, Rothkopf et Kaplan (1972) ont démontré que des objectifs explicites entraînent un meilleur rendement académique que des objectifs vagues aussi bien au niveau des apprentissages prévus qu’au niveau des apprentissages non
prévus. Mieux, ces auteurs ont trouvé que les apprentissages prévus et
non prévus déclinent avec la densité de la formulation des objectifs;
autrement dit, plus un objectif pédagogique est formulé simplement,
meilleures sont les chances q u ’il soit atteint par ceux auxquels il
s ’applique.
Pour les adversaires de l’utilisation des objectifs (Ebel, 1967;
Eisner, 1967; Jackson et Belford, 1965; Kliebard, 1968), les études
démontrant les avantages des objectifs pédagogiques sont loin d ’être
concluantes. Ils reprochent notamment aux objectifs pédagogiques leur
caractère "mécaniste", le peu de place qu’ils font à la spontanéité et à
la créativité, et leurs effets négatifs sur les apprentissages non prévus.
Sans préjuger du bien-fondé des raisons invoquées par les suppor-
teurs ou les adversaires des objectifs pédagogiques, nous considérons
quant à nous que les objectifs pédagogiques sont importants dans
l ’enseignement en ce sens q u ’ils indiquent dans quelles directions
doivent se faire les apprentissages. Par contre, les objectifs pédago
giques comme panacée à un rendement académique efficace sont tout
simplement un leurre. D ’autres facteurs en conjonction avec les
objectifs pédagogiques influencent probablement davantage les processus
d ’apprentissage. En effet, le moyen pédagogique (en l’occurrence les
objectifs pédagogiques), importe moins quand on sait l’impact considérable
qu’ont les valeurs et les attitudes des enseignants sur la qualité des
apprentissages des étudiants (Chambers, 1973; O ’Rourke, 1980; Kremer,
7
1.2 Les attitudes des enseignants sur la réussite scolaire des étudiants
Si plusieurs auteurs (Coleman, 1966; England and Dave, 1963; Wolf,
1966) estiment que les caractéristiques personnelles de l ’étudiant
(intellectuelles et affectives) et son environnement familial et social
sont les déterminants essentiels de la réussite scolaire, il n'en demeure pas moins que les caractéristiques du professeur, notamment ses attitudes,
influencent les processus d ’apprentissage de l’étudiant. En effet,
l’apprentissage est la résultante des diverses dimensions (affective,
cognitive, psycho-motrice) de l’étudiant, de celles du professeur, et de
leurs interactions dans un environnement donné (St-Pierre, 1986). On
pourrait donc aisément postuler que les caractéristiques personnelles du
professeur affectent son enseignement et par-delà celui-ci les étudiants
avec lesquels il interréagit. Mais comme le constatent Getzels et Jackson
(1966), on ne sait toujours pas avec précision le rôle et l’importance de cette dimension sur la réussite scolaire; ils concluent ce qui suit:
"En dépit de l’importance critique du problème et des
efforts d ’une cinquantaine d ’années de recherche, on sait
peu de choses sur la nature et la mesure de la personnalité de l ’enseignant ou sur la relation entre la personnalité de
l’enseignant et l ’efficacité de son enseignement. Le fait
désolant est que la plupart des recherches n ’ont pas
produit de résultats significatifs".
Cependant, un exemple édifiant de l ’attitude des enseignants sur la
réussite scolaire nous est fourni par l’étude de Joan Baker-Lunn (1966). Elle démontre que dans des écoles à classes hétérogènes, les enseignants qui croient aux vertus de l’homogénéité obtiennent de meilleurs résultats
en arithmétique avec leurs étudiants que ceux qui sont convaincus de
l ’avantage de l ’hétérogénéité avec les leurs.
C ’est dire toute l ’importance que revêt la connaissance des attitu
littérature ne regorge pas d ’études sur les attitudes des enseignants à l’égard des objectifs pédagogiques. Retenons toutefois celles de Popham et Baker (1957), d'Osgood, Succi et Tannenbaum (1957), de Schulze (1972), de Camplese, O ’Bruba et Haie (1979), de Hebbler (1977), de Thompson (1977),
de Dufresne (1986) et de Noël (1987).
1.3 Problémat ique
Parmi les diverses échelles d ’attitude à l’égard des objectifs
pédagogiques que nous avons relevées dans la recension des écrits,
l’échelle élaborée par Dufresne en 1986 nous apparaît être une sérieuse tentative de mesure des attitudes des enseignants face aux objectifs.
Contrairement à l ’I.O.P.L. de Popham et Baker (1967) qui mesurait en
partie le degré de connaissance et l ’utilisation des objectifs que
l’attitude face aux objectifs, l’E.A.O.P. de Dufresne (1986) se proposait
de mesurer effectivement le construit en question. De plus, elle a
l’avantage de ne mesurer que l’attitude des enseignants face aux objectifs
pédagogiques et en cela elle est plus concise et plus précise que le SATO
de Schulz (1972). Finalement, elle ne réduit pas l ’attitude des ensei
gnants face aux objectifs à une question de connaissance des objectifs
comme l ’Attitude Survey de Thompson (1972) et l ’I.O.P.L. de Popham et
Baker (1967).
Les nombreuses qualités de l’E.A.O.P. de Dufresne et les corrections qu’elle a apportées aux diverses échelles d ’attitude élaborées avant elles
nous amènent à la scruter minutieusement et à nous interroger sur le sens
de certaines de ses conclusions. En effet, Dufresne (1986) constate que
le nombre d ’années d ’expérience comme enseignant a une incidence sur
l’attitude face aux objectifs pédagogiques. Ainsi les enseignants
possédant le moins d ’années d ’expérience seraient-ils plus favorables aux objectifs que les enseignants possédant beaucoup plus d ’années d ’expé
rience; l’attitude de ces derniers serait expliquée par une certaine
résistance au changement. Un autre résultat intéressant de l ’étude de
entre les enseignants extrêmement favorables et les enseignants très favorables à l ’utilisation des objectifs pédagogiques en classe puisque la distribution est fortement assymétrique d ’un côté.
Ouvrant la voie à de nombreuses avenues de recherche, l’E.A.O.P. de Dufresne (1986) a permis à l’équipe de Girard et Valiquette (1986) d ’explorer les liens qui pourraient exister entre certains traits de
personnalité (RPF) et cette échelle d ’attitude. Cette recherche
s'imposait dans la mesure où il est important de connaître les traits de
personnalité en liaison étroite avec l’attitude face aux objectifs
pédagogiques au cas où l ’on déciderait de modifier cette attitude.
Noël (1986) a postulé l ’hypothèse q u ’il existe une relation entre
certaines échelles du Personality Research Form et l ’attitude des
enseignants à l ’égard des objectifs pédagogiques. En effet elle a noté
une corrélation significative entre d ’une part le besoin d ’ordre, le
besoin de dominance, le besoin de défense, le besoin de reconnaissance
sociale, et d ’autre part l ’attitude à l’égard des objectifs pédagogiques.
Certains traits de personnalité comme "autonomie", "accomplis
sement", "changement", "compréhension théorique", "impulsivité" et
"structure cognitive" n ’ont pas de corrélation significative avec
l ’E.A.O.P., contrairement aux hypothèses formulées dans l ’étude de Noël
(1986). Il est surprenant que le besoin de compréhension théorique et
celui de structure cognitive qui font évidemment appel à beaucoup de
cohérence, d ’intégration, d ’abstraction et de logique n ’aient pas une
corrélation significative avec l ’attitude à l ’égard des objectifs
pédagogiques. Cela pourrait dénoter, de l ’avis de Noël (1986), un manque
d ’intégration dans le processus mental des enseignants, des objectifs
pédagogiques. Autrement dit, les enseignants n ’auraient pas assimilé les
objectifs pédagogiques au niveau conceptuel, ce qui rend difficile voire
impossible l’utilisation de ces objectifs dans le cadre de leur
L'E.A.O.P. de Dufresne (1986), en raison des interrogations q u ’elle suscite, nous amène à questionner le sens de certaines de ses conclusions
et à formuler certaines critiques qui constituent l’ossature de notre
problémat ique:
a) Nous pensons que rien dans la démarche de Dufresne (1986) tant au
niveau de la conception que de la confection de l’E.A.O.P. ne permet
d ’affirmer q u ’une résistance aux changements expliquerait l’attitude
des enseignants ayant beaucoup d ’années d ’expérience face aux
objectifs pédagogiques;
b) nous pensons aussi qu’une des qualités fondamentales d ’une échelle
d ’attitude, c ’est justement de discriminer avec netteté; ce qui n ’est pas le cas de l ’E.A.O.P.;
c) nous pensons aussi que l’attitude des enseignants à l’égard des
objectifs pédagogiques est liée à leur connaissance réelle ou
supposée de ces objectifs, et à leur utilisation des dits objectifs. Malheureusement, l’étude de Dufresne (1986) ne fait pas mention de cet aspect que nous jugeons essentiel;
d) nous pensons enfin que le domaine ou la discipline a une incidence
sur l ’attitude des enseignants tant il est vrai que certains domaines ou certaines disciplines se prêtent plus facilement que d ’autres à la formulation et à 1 ’opérâtionnalisation des objectifs pédagogiques.
Dans l ’élaboration de l ’E.A.O.P., l’auteur n ’a pas cru utile
d ’investiguer cet aspect des objectifs qui pourrait éventuellement influencer l’attitude des enseignants.
En raison des postulats ci-dessus mentionnés, la présente étude
tentera de s ’intéresser aux facteurs qui influencent "la validité" de
l ’E.A.O.P. de Dufresne (1986). Elle se veut une modeste contribution à la
qualité d ’une échelle d ’attitude qui devrait beaucoup intéresser les
questions sus-mentionnés, elle se résume à une critique systématique autant des méthodes et procédés utilisés dans l’élaboration de l’E.A.O.P.
que de l’inférence qui en est faite. Il ne s ’agit pas de refaire une
étude empirique de l ’E.A.O.P. mais plutôt de détecter tout ce qui, un tant soit peu, pourrait réduire "la validité" de l’E.A.O.P. et d ’y remédier.
Bref, notre étude se ramène à une critique objective et constructive de l ’étude de Dufresne (1986) qui, comme plusieurs autres études sur les attitudes, est sujette aux écueils de la validité de l ’instrument de mesure.
CHAPITRE 2
Int roduct ion
2.1 Introduction aux études sur la validité
2.2 La validité: sa nature et ses mesures
2.2.1 La validité de contenu
2.2.2 La validité de prédiction
2.2.3 La validité concurrente
2.2.4 La validité de construit
13
CHAPITRE 2
Int roduct ion
Après avoir situé le cadre de notre étude dans le chapitre
précédent, il nous paraît opportun d ’élaborer sur la sempiternelle
question au sujet de tout instrument de mesure, à savoir "Est-ce q u ’il
est valide?" Donc, avant d ’aborder l ’objet essentiel de notre étude,
soit l ’analyse critique de l’échelle d ’attitude des enseignants à
l ’égard de l ’utilisation des objectifs pédagogiques en classe (Dufresne,
1986), et de répondre à la question ci-dessus posée, il est de propos de
rappeler certaines assertions au sujet de la validité d ’un instrument de
mesure. Nous avons parlé de de la validité de façon générale et des
différentes sortes de validité de façon plus spécifique. A cet effet,
nous avons défini la validité de contenu, la validité de critère et la validité de construit mais aussi tous les concepts et notions qui leur
sont rattachés ou avec lesquels elles sont confondues. Il s ’agissait,
pour nous, d ’élucider toutes ces notions avant d ’aborder les techniques
et méthodes couramment utilisées pour tester la validité appropriée d ’un instrument de mesure.
Après avoir épilogué longuement sur les notions de validité et
insisté sur l ’impérieuse nécessité pour un quelconque instrument de
mesure d ’être valide, nous avons montré que les différentes sortes de validité ne s ’excluaient pas mutuellement et qu’elles sont même dans une
considérer que le summum des validités est la validité de construit et qu’elle est la seule qui vaille la peine d ’être testée car elle inclut
nécessairement toutes les autres sortes de validité. Nous avons
privilégié, quant à nous, la validité de contenu et la validité de
construit pour tester l ’E.A.O.P. (Dufresne, 1986) quant à ses prétentions et implications.
Enfin, après avoir dressé certains postulats inhérents à un
instrument de mesure valide, nous avons établi nos hypothèses de
recherche qui disent essentiellement ceci:
l’E.A.O.P. (Dufresne, 1986) a une faible validité de contenu; l ’E.A.O.P. (Dufresne, 1986) a une faible validité de construit.
2.1 Introduction aux études sur la validité
S ’il y a un domaine de recherche en sciences sociales où les études
n ’abondent pas, c ’est bien celui de la "validité". Pourtant rares sont
les recherches en sciences sociales dont une partie ou la totalité des
conclusions ne suscite sinon la controverse du moins la retenue. Le
problème c ’est q u ’en sciences sociales, les instruments de mesure (tests
d ’intelligence, échelles d ’attitude, etc.) sont d ’une qualité telle
q u ’ils donnent lieu à de constantes interrogations. Des raisons
multiples et diverses expliquent cet état des choses; de ces raisons,
retenons surtout celle invoquée par Shye (1978).
"Les chercheurs en sciences sociales et en psychologie,
dans leur effort d ’atteindre la rigueur des sciences
physiques, recourent, souvent de façon prématurée, aux
méthodes quantitatives dans leurs études négligeant du même coup une autre dimension essentielle à toute science
expérimentale, c ’est-à-dire la formulation d ’une base
solide à partir de laquelle l ’on mène des recherches.
Ainsi donc, des méthodes statistiques élaborées sont
souvent utilisées pour analyser des données dont la base
15
études empiriques sont donc habituellement impossibles à
reprendre et, il y a peu d ’accumulation de connaissances
en vue de la formulation de lois scientifiques".
En effet, en sciences sociales, les concepts qui servent habituel
lement à la définition et à la formulation des lois scientifiques sont
plus ou moins clairs, plus ou moins précis et de ce fait résistent moins
aux procédures usuelles de l’analyse scientifique. Comme le constate
Kelly (1967):
"Nos construits théoriques ne sont pas aussi clairement
définis que ceux en sciences physiques; nos théories ne
sont pas aussi rigoureuses et il n ’y a pas de consensus
aussi grand quant aux opérations à effectuer pour mesurer
les variables en question. Cette ambiguité explique que
deux tests censés mesurer le même trait peuvent ne pas
être correlés entre eux ou encore que deux tests destinés
à mesurer des caractéristiques différentes soient
tellement en interrelation qu’il est permis de conclure
qu’à toutes fins utiles ils mesurent tous deux la même
caractéristique sous des vocables différents".
Cette avalanche de limites auxquelles doivent s ’astreindre les
chercheurs en sciences sociales a conduit ceux-ci à s ’interroger
sérieusement sur le bien-fondé de résultats obtenus à partir
d ’instruments aussi imparfaits.
2.2 La validité: sa nature et ses mesures
Habituellement l’on se sert des tests pour faire des inférences sur
le comportement de sujets testés et au-delà sur celui des populations
étudiées. Ainsi les tests d ’aptitudes servent, outre à sélectionner les
gens, à faire des inférences sur leur comportement. Il en est de même
des questionnaires de personnalité ou d ’attitude. Donc l ’utilisation des
d ’être rigoureuse et responsable. Elle doit notamment obéir à deux critères cardinaux: la fidélité et la validité.
On dit d ’un instrument de mesure qu’il est fidèle lorsqu’après
plusieurs épreuves appliquées aux mêmes sujets, les scores qu’il génère
demeurent constants. Mais disons tout de suite que de ce point de vue
les mesures psychologiques sont toutes à certain degré peu fidèles. En
effet, comme le soulignent Crocker et Algina (1986), un test d ’aptitude
subi par un groupe d ’adultes et resubi par ce même groupe deux semaines plus tard ne donnerait probablement pas, au niveau individuel, les mêmes
résultats. Les erreurs de mesure, qu’elles soient systématiques ou dues
au hasard, expliquent cet état des choses. Généralement lorsqu’un test a
un coefficient a élevé c ’est-à-dire une consistance interne forte, il est
considéré comme fidèle. Mais cette fidélité ne doit pas masquer les
problèmes d ’inférence souvent rencontrés. En effet, la fidélité est une
qualité essentielle mais non déterminante d ’un instrument de mesure.
Crocker et Algina (1986) notent à ce sujet qu’un jaugeur d ’essence
indiquant toujours 1/4 au-dessus du niveau réel d ’essence d ’une voiture
peut être fidèle c ’est-à-dire indiquer le même résultat après maintes
mesures, mais l ’inférence faite au sujet du volume d ’essence de la
voiture est fausse. Que vaut la fidélité lorsqu’un test est utilisé de
façon inappropriée? La fidélité n ’est donc pas suffisante pour toujours
justifier l ’inférence voulue. La fidélité porte sur la précision avec
laquelle un test mesure une caractéristique déterminée alors que la validité a trait à l ’utilité et à la qualité de la mesure. Le problème de la validité de l ’instrument de mesure est donc ainsi posé et il suscite encore de nombreuses recherches.
Généralement, on dit d ’un instrument de mesure (test d ’aptitude,
test de personnalité, échelle d ’attitude) qu’il est valide lorsqu’il
mesure effectivement ce q u ’il est censé mesurer; ou comme le notent Lord
et Novick (1968), la validité d ’un test se référé beaucoup plus au degré
auquel il mesure ou prédit un critère d ’intérêt quelconque. On peut
les différences de scores obtenus à l ’aide d ’un instrument de mesure
traduisent les différences réelles entre individus par rapport à la
caractéristique q u ’on cherche à mesurer, plutôt que des erreurs
constantes ou erreurs dues au hasard (Selltiz, Wrightmann, Cook, 1977).
Bref, comme le résume Valiquette (1987), la validité régit les relations
entre le construit et les mesures opérationnelles. Lorsqu’on travaille
sur des attributs psychologiques, l ’instrument de mesure parfait n ’existe pas, et on ne peut donc de façon absolue attester de la validité d ’un
instrument de mesure quelconque. Mais il y a lieu de se rappeler que la
validité d ’un instrument de mesure est le substratum même de toute
prétention scientifique dudit instrument. Les données obtenues à l ’aide
de tout instrument de mesure (échelle d ’attitude, test d ’aptitude, test
de personnalité, etc.) peuvent donner lieu à quatre sortes
d ’interprétation (Guion, 1965):
On peut décider d ’inférer les résultats d ’une personne à un test à
toute la classe de situations, le test lui-même n ’étant qu’un
échantillon de cette classe;
on peut aussi utiliser les résultats d ’une personne à un test pour prédire son comportement futur;
on peut aussi estimer le résultat d ’une personne concernant une
caractéristique qui est correlée avec la caractéristique que mesure le test que cette personne a passé;
enfin, on peut essayer de déterminer à quel degré la personne
répondant au test possède une caractéristique particulière.
Ces quatre interprétations donnent lieu à des questions de validité; on parle alors respectivement de validité de contenu, de validité liée au
critère (validité prédictive, validité concurrente) et de validité de
construit. Il s ’agit là de divers aspects de la validité qui ne
inférences voulues, on met l ’accent ou sur la validité du critère
(validité prédictive et validité concurrente) ou sur la validité de
contenu ou sur la validité de construit. Comme le note Wollack (1976),
le choix d ’une méthodologie de validité d ’un test est essentiellement déterminé par la nature de l’inférence recherchée.
2.2.1 La validité de contenu
La validité de contenu a trait au degré de représentativité de l ’échantillon d ’items par rapport à l ’univers d ’items (Bernier, 1984). De façon formelle, la validité de contenu est le degré auquel la variance totale de l’échantillon (le test en question) est reliée à la variance de
toute la population d ’items possibles (Guion, 1969). C ’est le type de
validité auquel est confronté un professeur dans la construction d ’un
test destiné à mesurer le niveau de connaissance des étudiants dans une
matière donnée; en effet le professeur se doit de construire un test dont
les items constitueraient un échantillon représentatif de toute la
matière en question. Il s ’agit là d ’une tâche presque impossible à
réaliser. C ’est d ’ailleurs une des raisons pour lesquelles les auteurs
n ’accordent pas la même importance à la validité de contenu en dépit des recommandations de l ’American Psychological Association (1954, 1974) de
l ’Equal Employment Opportunity Commission (1970). Ainsi pour des auteurs
tels que Messik (1981) et Tenopyr (1977), la validité de contenu n ’est
pas une qualité essentielle de la valité d ’un test; elle constitue sinon un type d ’évidence de la validité de construit du moins un prérequis à la
validité de construit d ’un test. Par contre, des auteurs tels que Yalow
et Popham (1983) pensent que la validité de contenu est un important
moyen de juger dans quelle mesure un test mesure ce qu’il est supposé mesurer.
Mais il faut surtout convenir, comme la plupart des auteurs
(Crombach, 1971; Guion, 1967), que la validité de contenu est d ’abord et
"Comment par exemple, définirait-on l ’univers des tâches que requiert "taper à la machine" dans une entreprise? En construisant un tel test, on rechercherait la validité de contenu seulement dans le sens d ’essayer de reproduire les plus importantes classes d ’activités telles que taper des
documents financiers, écrire des lettres ou préparer des
manuscrits à partir d ’un brouillon. Si, à la lumière du
jugement de ceux qui connaissent ces types de tâches,
l’échantillon de tâches est raisonnablement représentatif
des responsabilités probables du travail indiqué, alors le
test est considéré avoir une raisonnable validité de
contenu".
La validité de contenu se réfère donc au degré auquel le contenu
des items d ’un test est un échantillon représentatif de l ’univers de
contenus tels que prescrits par une définition théorique du construit
mesuré (American Psychological Association, 1974; Crombach et Meehl,
1955). Donc, la validité de contenu n ’est pas une caractéristique des
items individuels d ’un test mais bien celle d ’une collection d ’items
dépendant du jugement d ’experts (Lennon, 1956). Certains auteurs
distinguent aussi la validité de substance, la validité apparente, la
validité logique ou d ’échantillonnage, la subtilité d ’items, toutes ces
validités se rapportant ou se confondant avec la validité de contenu.
2.2.1.1 Validité apparente
Elle a trait au degré auquel un répondant considère que le contenu
du test est pertinent c ’est-à-dire que le test mesure ce qu’il prétend
mesurer (Wiggins, 1973). Plusieurs auteurs pensent qu’une telle qualité
est désirable pour un test surtout dans le domaine de l ’emploi (American
Psychological Association, 1974; Dick et Hagerty, 1971; Mosier, 1947;
Crombach, 1970). La validité apparente d ’un item est donc le degré
auquel cet item paraît pertinent à une échelle comportementale implicite
2.2.1.2 Validité logique ou d'échantillonnage
20
La validité logique ou d ’échantillonnage est déterminée de façon
systématique; elle nécessite une définition claire du domaine mesuré, la
détermination d ’objectifs spécifiques et le choix d'items les plus
logiques en fonction d ’une division cohérente de la matière ou du domaine visé (Bernier, 1984).
2.2.1.3 La subtilité d ’un item
Un item est dit subtil dans la mesure où le répondant ne sait pas
quelle caractéristique spécifique cet item mesure (Jackson, 1971). Un
exemple d ’item subtil est donné par Holden et Jackson (1981):
"J’aimerais faire le travail de boucher"
Cet item, sans son contexte précis, peut être obscur; mais si l ’on
sait la définition théorique du sadisme, le lien substantiel devient
apparent et évident.
2.2.1.4 Validité de substance
Elle se réfère à la propriété individuelle d ’un item et non à la
collection d ’items. Lorsque des items possèdent une validité substan
tielle, ils sont théoriquement liés à la dimension sous-jacente perti
nente. La validité de substance est une condition nécessaire mais non
suffisante de la validité de contenu. En effet, lorsqu’un test est
composé de nombreuses répétitions d ’un même item, il pourrait toujours
avoir une validité de substance mais le contenu d ’un seul item est
difficilement une représentation adéquate d ’un univers de situations
qu’implique la définition d ’un construit psychologique. Ainsi, pour
Jackson et Holden (1981), la validité de substance est attestée par des
2 1
Elle est nécessaire dans toutes les situations où les utilisateurs
d ’un test désireraient faire une inférence (à partir des scores d ’un
sujet à un test particulier) à un plus large domaine d ’items similaires à
ceux du test en question. L ’objet d ’une validation de contenu est
d ’attester que les items représentent adéquatement le domaine de
performance ou le construit envisagé. La procédure usuelle en l ’occur
rence est d ’avoir une équipe d ’experts indépendants qui jugent de la
représentativité de l ’échantillon d ’items construits. Cette procédure a
généralement lieu après q u ’une forme initiale de l ’instrument de mesure
aura été développée. Selon Crocker et Algina (1986), elle nécessite les
étapes suivantes:
une définition du domaine de performance ou du construit,
la sélection d ’experts qualifiés dans le domaine de performance ou du construit,
l’établissement d ’une structure adéquate permettant de relier les
items au construit ou au domaine de performance,
la collecte des données relative au pairage items-facettes
Comme le note Messick (1981), la validation du contenu implique une stratégie rationnelle où le domaine d ’intérêt est identifié souvent par
des objectifs pédagogiques ou des caractéristiques d ’une tâche. La
validation de contenu est surtout utilisée dans les cas de tests de
performance; c ’est d ’ailleurs la raison pour laquelle le domaine de
performance est souvent défini en termes d ’objectifs pédagogiques. Les
divers aspects des facettes du domaine d ’intérêt sont spécifiées et les
items sont construits de façon à couvrir ces facettes. La façon dont les
items sont construits et répartis entre les facettes détermine dans une
large mesure leur représentativité et au-delà leur homogénéité ce qui
n ’est pas sans affecter le test. C ’est d ’ailleurs la raison pour
laquelle l’on doit observer certaines étapes dans la construction des
items et leur pairage avec les facettes.
2 2 2.2.1.5.1 La représentativité des objectifs
D ’ordinaire, on s ’assure que tous les objectifs définis d ’un domaine
de performance ou d ’un construit sont d ’égale importance (Crocker et
Algina, 1986), c ’est-à-dire que les items les couvrant sont en nombre
égal. Mais ce n ’est pas toujours l’avis des spécialistes. Certains
auteurs comme Katz (1958) suggèrent d ’évaluer les objectifs et de les
ranger par ordre d ’importance avant de pairer les items avec les
objectifs; c ’est dans cet ordre d ’idées que Klein et Kosecoff (1975) ont
proposé de noter l ’importance de chacun des objectifs sur la base d ’une
échelle de cinq points; de plus ils ont suggéré que les experts qui
examinent les items pour les pairer avec les objectifs soient différents
de ceux qui participent au processus d ’évaluation des objectifs comme tel.
Les instructions aux experts, devant ranger les objectifs selon leur
importance, doivent être claires et précises. Par exemple, un expert
pourrait juger de l ’importance d ’un objectif pédagogique à partir du
temps qui lui est imparti alors qu’un autre la définirait en relation
avec les apprentissages futurs. Donc, il appartient au concepteur du test de fournir des définitions communes afin d ’éviter que chacun y aille avec des définitions idiosyncratiques.
2.2.1.5.2 Le pairage des items avec les objectifs
On pourrait demander à des experts de procéder systématiquement en
pairant chaque item avec un objectif défini (Crocker et Algina (1985).
Katz (1958) et Ebel (1956) suggèrent que chaque expert lise l ’item et
identifie la réponse correcte (juste) comme le ferait un candidat. Klein
et Kosecoff (1975) font des suggestions pour améliorer la tâche des
experts. Ils proposent notamment:
- que chaque item soit écrit sur une fiche spéciale
23
- que les résultats soient enregistrés sous une forme standard.
Pour plusieurs auteurs, la décision de pairer les items aux
objectifs est de nature dichotomique: ou bien un item sied à un objectif,
ou bien il ne sied pas à cet objectif. Toutefois, Hambleton (1980) a
décrit une procédure polychotomique avec une échelle en 5 points où un
pointage de 1 signifie que l'item est faiblement congruent avec l'objec
tif et le pointage de 5 signifie que l ’item est parfaitement congruent
avec l’objectif. La moyenne ou la médiane des points de chaque item est
alors prise pour indiquer le degré auquel l’item est congruent avec
1 ’objectif.
2.2.1.5.3 Les aspects de l’item à examiner par les juges
On devrait mettre à la disposition des juges une description claire
des caractéristiques de l’item qu’il faut considérer. Les caractéris
tiques pertinentes sont: le sujet, le processus cognitif impliqué ou le
niveau de complexité de la performance requise, le mode de présentation, le mode de réponse requise.
2.2.1.5.4 Le sommaire des résultats
Il faut une façon standard de collecter et de présenter les
résultats. Crocker et Algina (1986) suggèrent la procédure suivante:
- le calcul du pourcentage d ’items qui sont congruents avec les objec
tif s ;
- le calcul du pourcentage d ’items qui sont fortement congruents (c’est-
à-dire ayant des scores élevés) avec les objectifs;
- le calcul de la corrélation entre l ’importance des objectifs et le
nombre d ’items les mesurant (Klein et Kosecoff, 1975);
- le calcul de l ’indice de congruence entre les items et les objectifs
24
- le calcul du pourcentage d ’objectifs non mesurés par aucun item du
test.
Les deux premiers indices nécessitent un large nombre d ’items (peut-
être 100 ou plus) pour une interprétation sensée. Le troisième indice
est affecté par la variance du nombre d ’items mesurant chaque objectif et
l’importance de ces objectifs. De façon spécifique, si tous les
objectifs ont une égale importance autement dit si le même nombre d'items
mesurent chacun des objectifs, cet indice de corrélation serait nul. Le
qtratri-èm« indice, décria p a r Hambleton (1980) et Rovinelli (1977) peut
être utilisé pour voir à quel degré un item donné a une validité de
contenu pour un ensemble d ’objectifs. Dans le cas idéal, un item doit
être relié uniquement à un seul objectif. La collecte de données reflète
cette assomption car on donne un score de 1 chaque fois qu’un item est
congruent avec un objectif, un score de 0 , s ’il y a incertitude, et un
score de -1 si l ’item n ’est pas congruent avec l ’objectif. L ’indice de
congruence d ’un item i à un objectif k pour être donné par la formule:
Jlk “ ___ (Mk“M)
2N-2 où N est le nombre d ’objectifs,
est la note moyenne des juges à l'item i concernant le kième
objectif,
p -est la note moyenne des juges à l’iterm i concernant tous les
object ifs.
La congruence la plus haute possible entre un item et un objectif est de 1 ; cela est possible quand tous les juges pairent un item à un et
seul objectif. Lorsque qu’un item mesure plus qu'un objectif, son indice
de congruence en est inférieur à l ’unité. L'idéal serait que l ’indice de
congruence pour chaque item soit le plus élevé possible pour l ’objectif auquel il s ’applique et le plus faible possible pour les autres objec tifs.
25
Enfin, le pourcentage d ’objectifs non couverts par les items est un indice permettant de savoir à quel degré le domaine en question est
représenté par les items. Son interprétation est délicate lorsque le
nombre d ’objectifs est petit.
Un autre problème avec la validation du contenu, c ’est que même si
tous les items couvraient parfaitement les objectifs, il se pourrait que
les objectifs édictés ne représentent pas adéquatement le domaine auquel
le concepteur du test voudrait faire des inférences. Pour contourner ce
problème, Cronbach (1971) propose de doubler l’expérience de construction
du test. En effet deux équipes indépendantes auxquelles on fournit les
mêmes restrictions et renseignements quant aux contenus de données, aux
méthodes d ’échantillonnage, à la pré-expérimentation et aux critères
d ’interprétation des données doivent développer chacun un test. Ces deux
tests seront administrés aux mêmes sujets. Avec la théorie classique des
tests, on sait que
2
6
6 1 e 2
où Xj et X2 sont les scores aux deux formes parallèles du test, et 6 ej est la variance d ’erreur à la 1ère forme du test et 602 est la variance
d ’erreur à la 2e forme du test. Pour un sujet, si
62 + 6*
e l e 2
z ( x ^ - x ^ ) 2/N
s ’approche de 1 , on dirait que les deux tests sont similaires en termes
de leur variance d ’erreur.
2.2.2 Validité reliée au critère
Comme le note Nunnally (1978), la validité liée au critère est
impliquée lorsque l ’objet d ’un test est d ’estimer une quelconque forme de
comportement extérieur au test lui-même et appelé critère. La
corrélation entre le test et le critère détermine le degré de validité
dudit test. Conséquemment, un test est de peu d ’utilité s'il n ’a pas une
26
critère donné doit reposer sur de bonnes bases théoriques. D'ordinaire
on distingue deux types de validités reliés au critère: la validité
prédictive et la validité concurrente.
2.2.2.1 Validité prédictive
Elle a trait au degré de relation ou d ’association entre les scores
d ’un individu à un test et un critère mesuré. Dans ce type de validité,
on est surtout préoccupé par le comportement futur de l’individu établi à
partir des scores de ce même individu à un test; plus les scores de
l’individu permettent de prédire son comportement futur, plus la validité
prédictive du test est grande. Généralement les tests de rendement
scolaire servent à mesurer l’atteinte d ’objectifs et aussi à prédire les
chances de réussite des étudiants dans un domaine social quelconque. Dans ce type de validité, l ’accent est moins sur le test lui-même que sur
le comportement prédit. En effet, pour un test quelconque, il peut y
avoir plus d ’une validité prédictive; on pourrait dire q u ’il y a autant
de validités prédictives pour un test qu’il y a de critères à prédire
(Ghisel 1i , 1980). Dans le domaine de l'emploi, la validité prédictive
est surtout déterminée par la méthode du suivi (follow-up method). Dans
ce type de méthode, un test est passé par tous les demandeurs d ’emploi,
ce test ne constituant aucunement une base de sélection. Pour les
candidats retenus, on établit un critère de succès et après une certaine
période on essaye de voir la relation entre le critère et le test passé. C ’est le degré de relation entre le critère déterminé et le test passé qui détermine dans quelle mesure ledit test est valide.
Comme l ’observe Guion (1986) "l’énoncé de la validité prédictive
d ’un test n'est pas une évaluation du test per se, mais plutôt une
évaluation du test tel qu’utilisé dans une étude de validation". Beaucoup
de variations dans l ’utilisation d'un test peuvent en influencer la
"validité". Les mêmes principes de contrôle expérimental doivent