Children's comprehension of video effects : understanding meaning, mood & message
Texte intégral
Figure
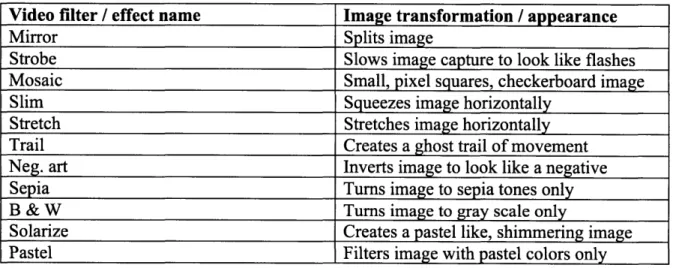
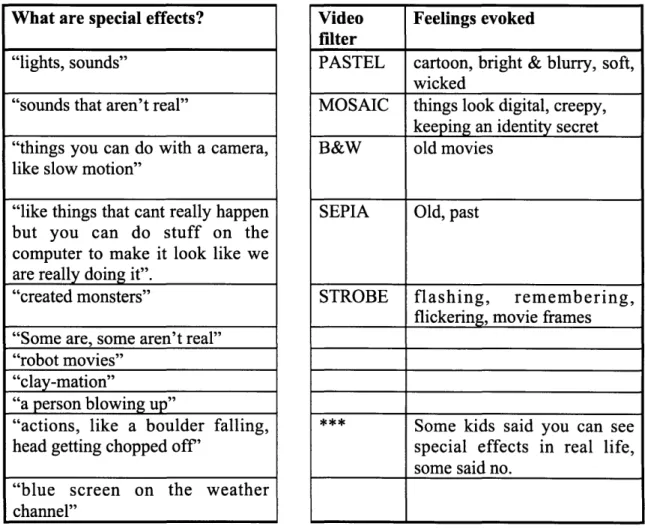
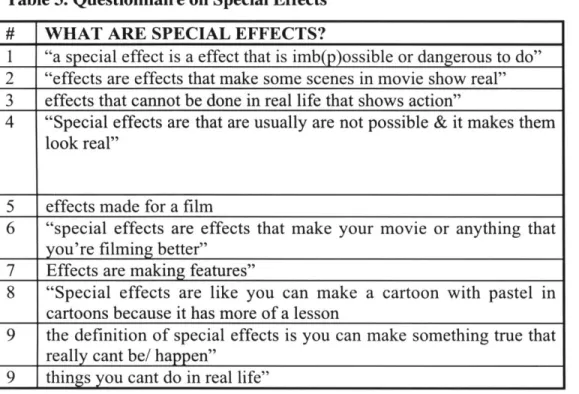



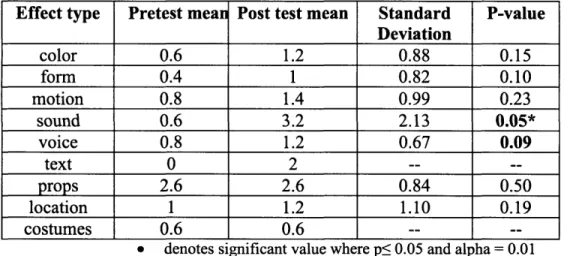
Documents relatifs
L’IETF ne prend pas position sur la validité et la portée de tout droit de propriété intellectuelle ou autres droits qui pourraient être revendiqués au titre de la mise en œuvre
Paper presented at the Bristol Ideas in Mobile Learning 2014 Symposium, Bristol.. "This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives
In this paper we propose an on-line Bayesian temporal model for the simultaneous estimation of gaze direction and of visual focus of attention from observed head poses (loca- tion
To spot these salient events, we used two auditory saliency models: the Discrete Energy Separation Algorithm and the Energy model.. We found that the impact of sound on
This is the step I call enrichment of the structured information: the interesting thing is that I can add this grammatical information to the TEI encoding: it will be really helpful
The first experiment showed that closer proximity of an important element of a video game user interface, namely the score, with the most watched area of the game screen did not
Noting that, here, we deal with a dissipative system together with noisy measurement, we choose the second alternative in this paper. Throughout the following paragraphs, we
They divided the body into 4 segments (head, abdomen, arms and legs). Then for each group, a model of the k nearest neighbors is trained. It takes as input two types.. The first
