Active One-shot Learning
for Personalized Human Affect Estimation
by
Jacqueline L. Xu
Submitted to the Department of Electrical Engineering and Computer
Science
in partial fulfillment of the requirements for the degree of
Master of Engineering in Electrical Engineering and Computer Science
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
June 2018
@Jacqueline
L. Xu, 2018. All rights reserved.
Signature
Author ....
Certified by
The author ht7reby grants to MT permission 1o
reproduce and to dstribute pvbcty paper aid
$6Q.ctronic copias of this thesis document in whole or in part in any medium now known or
redacted
heafter created... ...
Department of Electrical Engineering and Computer Science
--
7May 25, 2018
Certified by...
Accepted by ..
MASSACHUSETTS INSTITUT OF TECHNOWGYAUG 202018
LIBRARIES
Signature redacte..
Ognjen Rudovic, PhDMarie Curie Research Fellow
Thesis Supervisor
Signature redacted
Rosalind Picard, ScD
Professor of Media Arts and Sciences
Thesis Supervisor
Signature redacted
...
E
Katrina LaCurts, PhD
Chairman, Department Committee on Graduate Theses
Active One-shot Learning
for Personalized Human Affect Estimation
by
Jacqueline L. Xu
Submitted to the Department of Electrical Engineering and Computer Science on May 25, 2018, in partial fulfillment of the
requirements for the degree of
Master of Engineering in Electrical Engineering and Computer Science
Abstract
Building models that can classify human affect leads to the challenge of learning on data that is complex in features and limited in size and labels. How can these models balance being general and personalized, capturing both the commonalities and the individual quirks of people? While previous research has explored the inter-section of deep learning, active learning, and one-shot learning to craft models that are semi-supervised and data-efficient, these methods have not yet been examined in the context of personalized affective computing. This study presents a novel active one-shot learning model for personalized estimation of human affect, in particular, detection of pain from facial expressions. The model demonstrates the ability to learn an active learner that achieves high accuracy, learns to become data efficient, and introduces model personalization to match or outperform fully supervised and population-level models.
Thesis Supervisor: Ognjen Rudovic, PhD Title: Marie Curie Research Fellow Thesis Supervisor: Rosalind Picard, ScD Title: Professor of Media Arts and Sciences
Acknowledgments
First and foremost, I would like to thank Ognjen (Oggi) Rudovic and Prof. Rosalind Picard for their support, mentorship, and advising throughout the development of this research. Their encouragement, passion, and research expertise helped me grow as a researcher in affective computing and machine learning. Additional thanks to Javier Hernandez for his help and patient guidance during the initial stages of my research process. And, thank you to the entire Affective Computing group for being a welcoming family of researchers and inspiring me with everyone's incredible work in making technology that is more understanding of humans, in a compassionate way.
A second round of thanks goes to my dear friends in and outside of the MIT
community. The support and love of these incredible individuals have meant the world to me during my journey through MIT, particularly through this year of great personal growth. I am unbelievably fortunate to have shared this year with people whom I look up to in their kindness, wisdom, and spirit.
Last, and certainly not least, an immense thank you to my family who are the roots of my life. Thank you to Qiuwei Xu, Lixin Hao, Mary Xu, and Darlene Brigance (and her children Alexis and Zane) for being my cheerleaders and home base. Finally, thank you to Wenlan Wang whose spirit always has and always will guide me from the fourth dimension.
Contents
1 Introduction 13
2 Related Work 15
2.1 Affect Estim ation . . . . 15
2.2 Active Learning Framework . . . . 15
2.3 Deep Active Learning . . . . 18
2.4 Personalized Machine Learning . . . . 19
3 Active One-Shot Learning Model 21 3.1 Meta Learning Problem . . . . 21
3.2 Reinforcement Learning Framework . . . . 22
3.3 Training an Active Learner with Deep RL . . . . 22
4 Personalized Affect Estimation Model 25 4.1 D ata Setting . . . . 25
4.2 M odel D esign . . . . 27
5 Experiment Design 29 5.1 Training an Active Learner on Personalized Affect Estimation . . . . 29
5.2 Evaluating the Model Label Request Effectiveness . . . . 30
6 Results 31 6.1 Model Accuracy and Label Requests . . . . 31
6.1.2 Final Model Performance. . . . . 33
6.1.3 Per Patient Results . . . . 34
6.2 Label Request Effectiveness . . . . 34
7 Discussion 37
8 Conclusion 39
A Code Guide 41
List of Figures
2-1 The general active learning framework with pool-based sampling. Im-age from Settles [30]. . . . . 17
4-1 Label distribution for the UNBC-McMaster Shoulder Pain Expression dataset and an example of facial action unit coding for one video frame of a patient. . . . . 26
4-2 Source and target subject distribution of training and validation data. 26
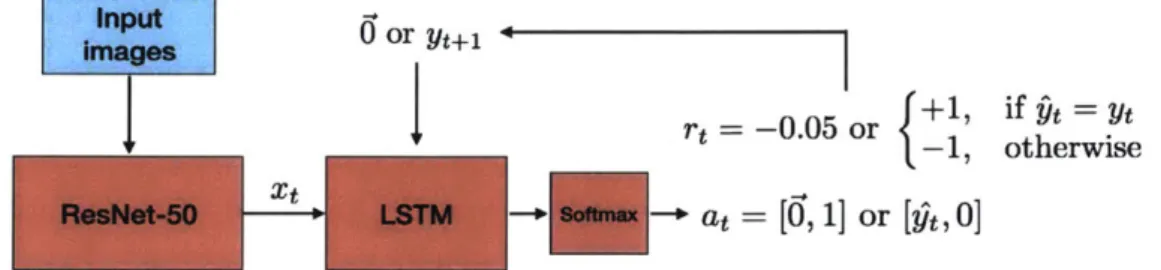
4-3 Model diagram and training paradigm. At each time step within a training episode, a subject's input image is processed by a
ResNet-50 model trained on ImageNet and compressed into a size-ResNet-500 vector
with PCA. This image representation is combined with a zero vector in the first time step. The LSTM output, representing the RL model Q-value, is processed through a linear layer and transformed into a one-hot action vector. Depending on whether the model decides to predict the label or request the true label, a zero vector or the true label is given with the next image representation. Additionally, a reward is assigned and used to update the model via the Bellman loss equation. 28
6-1 Model prediction accuracy and number of label requests during training
of the SAL, PAL, and TAL models for Tva. In Figures 6-la and 6-1c, in the first 40 training steps, the model is trained on Strain through the
SAL model, and in the second 40 training steps, the model switches to
train on Train to personalize the model through the PAL model. The
red line marks this transition point. Figure 6-la shows the performance accuracy of the SAL and PAL models, while Figure 6-1c shows the label requests at each training step for the SAL and PAL models. Figures
6-1b and 6-1d show the accuracy and label requests of the TAL model,
respectively. . . . . 35 6-2 Cumulative fraction of label requests over the course of the SAL, PAL,
and TAL trainings. Figure 6-2a shows the cumulative requests of the
SAL model in the first 40 training steps and that of the PAL model in
the second 40 steps. This transition is depicted with a red line. Figure
6-2b similarly shows the cumulative label requests for the TAL model. 36
6-3 Percentage of data seen by the model during training on the Strain
in the SAL and PAL models (Figure 6-3a), training on Ttrain in the
SAL and PAL models (Figure 6-3b), and training on Ttrain in the TAL
model (Figure 6-3c). . . . . 36
6-4 Mean accuracy and percent of label request actions on Tat for each patient across the three different model training settings. . . . . 36
List of Tables
6.1 Average model prediction accuracy on the target validation set and
per-centage of label requests made on Tai. The RL models use R,, = -1,
with the first RL model, listed in the second column, calculating ac-curacy by considering requests as incorrect predictions and the subse-quent RL model, listed in the last column, evaluating accuracy based on only the prediction guesses that the model made. . . . . 33 6.2 Average accuracy of the supervised models trained on random data vs.
the data points for which the active one-shot learning model requested lab els. . . . . 34
Chapter 1
Introduction
Emotions in humans are often likened to colors. Each is meaningful in context, difficult to describe, and experienced differently by each person. Still, humans have found ways to identify their own emotions, recognize emotions in others, and share a common language for a wide range of nuanced emotions. Machines, on the other hand, struggle with this difficult task. Of the next major challenges in artificial intelligence (AI), one is to capture the emotional intelligence that humans learn over their lifetimes. Today's voice assistants like Apple's Siri and conversational chatbots like Woebot
[51
cannot yet understand in depth the emotions a person might be expressing in conversation. For Al to better serve humans and for humans to better understand themselves, machines should build understanding of human emotion, or affect, and learn how to best respond to people given their affective state.One of the central challenges of affective computing is to study and characterize aspects of human affect quantitatively
[23].
As the mechanisms of human affect are poorly understood, deep learning models may help us to find promising signals that are most associated with affect, for example, examining features from human facial and physiological data to study subtle human emotions. However, typical deep learn-ing algorithms are extremely data-hungry, requirlearn-ing many data points and human-provided labels to perform supervised training. This training paradigm isn't feasible for many human affective datasets which are often limited in size and costly to la-bel. Furthermore, with affect data, rather than employing a "one-size-fits-all" model,an ideal personalized affect model would be able to provide accurate estimates for individuals, while maintaining a generalized model that can be applied across the population. This personalized machine learning paradigm has been previously ap-plied to affective computing [91, and will be expanded in this work.
To reduce deep learning models' data consumption while maintaining high model performance, many methods have been developed in active learning. Recent work demonstrates the ability of active one-shot learning to train a model to perform clas-sification while balancing accuracy and data consumption
[391.
This thesis builds on the active one-shot learning model and presents a novel personalized active learning model for human affect estimation, particularly applied to pain detection through fa-cial expressions. The personalized active learning model can learn to learn efficiently, while achieving high accuracy on a population and individual level. The work pre-sented in the following thesis does not claim to outperform existing models in affect estimation, but examines how personalization and active learning can bolster current affect estimation models, an intersection of research areas that is just beginning to be explored.Chapter 2
Related Work
2.1
Affect Estimation
One focus of affective computing research has been to create computational models and concrete metrics of affect in humans [23]. Much previous work has applied deep learning to learn supervised models of affect through facial
[11]
and physiological data[20].
These works demonstrate the potential for deep neural networks to process complex data and to detect important features associated with human affect. For an extensive overview of existing efforts in automated affect analysis, see work by Zeng, et. al. [42].A residual issue in applying deep learning to affect estimation is the lack of data
efficiency. As the next section explores, active learning may prove to be a promising solution to creating more data-efficient classification models.
2.2
Active Learning Framework
Often for affect datasets, obtaining large, labeled datasets is time-consuming and costly. In these settings, active learning can be employed to learn more effectively on the data available, without requiring the model to see the label for every data point. Active learning is a semi-supervised machine learning method often applied to settings in which there is a large set of unlabeled data, for which one would like to
learn the true labels, and a small set of labeled data on which the active learning model can train
[30].
In this framework, the model trains on the small set of labeled data to make an informed prediction on the unlabeled data. If the model is uncertain enough about the label of the input data, it can query an oracle which will return the true labels of the data. Otherwise, the model continues receiving new data, for which it repeats the same labeling process. In the active learning setting, it is assumed that requesting labels for data is costly; thus, the model wants to limit the number of times that it requests labels from the oracle. In classification settings, from estimation of facial action unit labels[361
to discovering feature artifacts in electrodermal signals1401,
active learning has been found to train models on a smaller fraction of the training set, while maintaining a similar accuracy as models trained in a fully supervised setting.To create an active learning model, the essential algorithmic decisions include the frequency of model updates and the query strategy dictating when to request a label for a given sample. The model may sample unlabeled data in the following ways:
1. Membership query synthesis: The model generates random, synthetic
sam-ples to explore the entire space of possible samsam-ples.
2. Stream-based selective sampling: The model selects a random single sample from the distribution of existing unlabeled data points.
3. Pool-based sampling: The model selects a batch of samples (for instance,
based on some similarity metric). (Figure 2-1)
To decide whether to query a sample, there are the following most prominent query strategies for classification settings:
1. Uncertainty sampling: The sample is selected based on the model's
predic-tion confidence for the sample's label. For instance, the model may select the data point for which it is least confident of its label:
XLC = arg max 1 - PO(Ypred X) X
leam a model machine leaming
model
labeled
training set
unlabeled pool
oracle (e.g., human annotator) select quieries
Figure 2-1: The general active learning framework with pool-based sampling. Image from Settles [30].
where x is a given data point, Ypred is the model prediction, and 0 represents
the confidence model parameters.
Alternatively, the model may deem the most uncertain sample as the data point whose first and second most likely labels (Y,p,,ed and Y2,ped, respectively) are
similarly possible, through a strategy called margin sampling:
= arg min Po(yl,,,.edIX) x - PO(Y2,predkI)
A third metric for uncertainty is entropy, which considers the probabilities of all
possible labels yj for a given data point and selects the point with the highest entropy across all labels:
S= arg max -x P0(yi IX) log P0(yiIX)
2. Query-by-committee: The sample is selected based on the level of
disagree-ment in label between a committee of models C = {0(1), 9(2) ...)9 (c)}, all of
which are trained on the same given labeled set of data L. One such metric of disagreement is known as vote entropy:
VE (- ()
x =arg max - L log 1
where V(yi) is the number of votes that a label receives from the models based on their predictions, and IC is the committee size.
An alternate metric of disagreement is the average Kullback-Leibler (KL)
diver-gence:
ICI
XL= arg max I.ZD(PO(c)>|Pc)
where D(P(c)
I
Pc) = Ej Po0 c (yI x) log Pc (yX) and 0(c) represents a particularmodel in the committee, while C represents the committee as a whole.
As evidenced by the active learning literature, there are diverse approaches to designing an active learning algorithm. Many of these considerations depend on the features of the data that the model will train on, and the feasibility of calculating the quantities delineated above.
2.3
Deep Active Learning
To apply active learning to more complex datasets, new models of deep active learning have been developed and applied mainly towards image classification. To adapt deep
neural networks to the active learning framework, modifications to vanilla neural
networks have been tested to evaluate the uncertainty of neural network output labels
[10, 37, 14]. Yet, this query strategy still must be specified by a human. By training an
active learner through active one-shot learning, this query strategy could be learned automatically.
Recent work by Woodward and Finn [39] trains a model to learn to do active learn-ing through the reinforcement learnlearn-ing framework [33]. To train an active learner, the model receives a reward related to its decision to make a prediction or request a label
- positive reward is given for correct predictions, and negative rewards for incorrect
trained to learn how to do active learning for image classification on the Omniglot dataset [17].
This study adapts the active one-shot learning model to learn a personalized model for classification on an affective pain dataset.
2.4
Personalized Machine Learning
While model personalization has been researched in several previous contexts, such as self-reported pain analysis [191 and robot therapy for autism [261, these settings do not make use of active learning to learn more efficiently use fewer data points. Work by Jaques and Taylor, et. al., has applied personalized machine learning to affective computing, predicting wellness metrics and balancing model accuracy on individuals and the population
[9].
This thesis brings together ideas from personalized machine learning, active learning, and affective computing to create a data-efficient personalized active learning model for facial expression estimation.Chapter 3
Active One-Shot Learning Model
3.1
Meta Learning Problem
Moving beyond specializing machine learning models towards specific datasets, recent research has worked towards building models that can adapt to a variety of similar learning environments. This paradigm known as meta learning, or learning to learn, allows models to learn a more general learning framework that can be applied to multiple tasks within a certain space of problems.
Meta learning models are generally able to train on new tasks without requiring as much training data as machine learning models that are trained for single tasks. Thus, these models are often tested on one- or few-shot learning tasks, often classification, in which the model is evaluated on whether it can quickly transfer knowledge from one classification task to another similar task. Several papers have demonstrated the capabilities of meta learning; for instance, Santoro, et. al., [28] was able to achieve one-shot learning on the Omniglot dataset
[171
using a memory-augmented neural network .With meta learning algorithms, the tedious task of defining the machine learning model parameters and hyperparameters is automated and catered towards the task at hand. Even more, meta learning models produce general models that can be applied to various but related data settings. Thus, with meta learning, perhaps a model can be trained to balance generalization and specialization, particularly in affect
datasets. This paper explores how to incorporate personalization into the active one-shot learning model
[391,
a particular type of meta learning model, to address problems in affective computing.3.2
Reinforcement Learning Framework
The core of the training scheme for the active one-shot learning model involves rein-forcement learning (RL)
[331.
Under the RL framework, the learner's main goal is to maximize their expected discounted reward using an action-value function Q(st, at),given the current state st and a proposed action at at that state. The optimal action-value function is represented formally by the Bellman equation:
Q*(st,
at) = Et+[rt + - maxQ*(st+,
at+,)Ist, at] (3.1) at+iwhere E8,t~ indicates an expected value over the distribution of possible next
states st+1, rt is the reward at the current time step t given state st and action at, and -y is a discount factor, which incentivizes the model to seek reward in fewer time steps.
Applying deep learning to RL has opened computers to solve more complex prob-lems, such as playing Atari video games as Mnih, et. al., famously demonstrated [21]. In this pivotal application of deep reinforcement learning, the authors represent the action-value function with a deep neural network, known in this context as a deep
Q-network, as the network approximates the Q-value of a given state and action.
3.3
Training an Active Learner with Deep RL
Active one-shot learning
1391
aims to train models that learn to perform active learn-ing, while capturing the data-efficiency of one-shot learning models. These models are trained through deep reinforcement learning and bypass the need to define ex-plicit uncertainty metrics in selecting data to query, by having the model imex-plicitly learn when to request labels for given data and when to make a prediction. As themodels update only after a batch of data is processed, these active learning models use pool-based sampling. The active one-shot learning model [391 represents
Q
with an LSTM, based on previous work in one-shot learning with memory augmentation[28].
Under the reinforcement learning model of active learning, at a given time step t, the active learner may choose an action at of either requesting the true label yt* of the input data point, or providing its prediction yt for the point. If it decides to request the true label, the model receives slightly negative reward (-0.05 in the original paper
[39]) to reflect that obtaining labels for data is costly, but that the model is better off
requesting a true label rather than making a wildly incorrect guess, in the long term. If the model decides to make a prediction, the model receives positive reward (+1) if the prediction is correct; otherwise, it receives negative reward (-1) for an incorrect prediction.
The model trains on this learning task, using the Bellman loss equation, which encourages the model to improve its estimate of the expected reward at the current step:
L(O) := Z[Qe(st, at) - (rt + y max Qe (st+1, at+1))]2 (3.2)
t at +1
where
E
represents the parameters of the action-value function. Over its training, the model improves on the two tasks of learning to label the input data correctly and learning when it is best to request a label. As shown in [39], this deep active learner succeeds at performing one-shot classification on the Omniglot dataset [171.Chapter 4
Personalized Affect Estimation Model
4.1
Data Setting
The experiments later described focus on images from the UNBC-McMaster Shoulder Pain Expression Archive Database
118],
which were generated from videos of the facial expressions of patients with various shoulder issues as they performed arm range-of-motion tests. The dataset consists of 48,398 image frames, generated from 200 video sequences of 25 patients. Because one of the patients displayed only neutral facial expressions, they were removed from the dataset. Each frame is labeled with a pain level from a 16-point pain scale, based on coded facial action unit values (Fig. 4-1b) and the Prkachin and Solomon Pain Intensity (PSPI) scale. Fig. 4-la shows the distribution of pain intensity labels of the dataset, as examined by Kaltwang, et. al. [12]. For this setting, the pain labels are simplified by merging all classes of positive pain (pain levels 1-15) into one class and maintaining one class for neutral expressions(pain level 0).
The images are preprocessed through a ResNet with 50 layers [7], previously trained on ImageNet [15]. Taking the features from the last activation layer, the fea-tures are then transformed into size-500 image representation vectors using PCA. In our experiments, the ResNet is not fine-tuned towards the UNBC-McMaster dataset, though doing so would likely lead to even better model performance.
40,029 bass 1 . . ... (no pain) Class 2 3,000- (pain) 22,000 Z 1,000 -0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Pain intensity (a) (b)
Figure 4-1: Label distribution for the UNBC-McMaster Shoulder Pain Expression dataset and an example of facial action unit coding for one video frame of a patient.
{s
1, ... , s12} and 12 target subjects T = {ti,... , t1 2}. For each subject in S and T,two disjoint sets of the subject's image data are sampled as training and validation sets. Thus, four disjoint data subsets are formed: source training Strain, source vali-dation Sva, target training Ttrain and target validation Tai datasets (Fig. 4-2). These four sets are drawn randomly over the 10 experiment iterations.
Source subjects
Target subjects
U..e
U..
S1, train Si, val Sn,-train Qn, val t1, train tIaI. tnrain t, val
Strain SvlTtrain Ta
Figure 4-2: Source and target subject distribution of training and validation data.
The experiments described in later sections explores training a model that balances generalization and personalization, applied to the UNBC-McMaster shoulder pain dataset. Thus, after the model trains on various training sets (Strain or Ttrain), it is tested on data from Tval.
4.2
Model Design
The task for an active learning model is to identify the presence of pain in the image representation with which it is presented. Over the training arch, the model aims to learn when to make a prediction and when to request the true label from the oracle, based on a reinforcement learning formulation of the active learning task.
In each training episode, one subject is sampled from either the source or target sets, for instance si ~ Strain for training on the source set. For that subject, 40 image representations are sampled, balanced to have 20 data points with pain expressions and 20 without pain expressions. Each training batch consists of 50 episodes, with each episode sampling a new random subject, with replacement. After each batch, the training model is updated. Similar to the training setting of [39], at each time step of a training episode, the model reads in one observation ot, which includes an image representation xt, and decides either to predict the label of the sample or to request the true label, which is output as a one-hot action vector from the model. The model architecture features an LSTM followed by a dense layer and a softmax function whose output represents that of the action-value function Q(ot, at).
Based on the model's action selection and the true label for the input image representation, a reward is assigned as follows:
{
Req, if requesting true label ytrt = Rcor, if predicting and it = yt
Rinc, if predicting and
yt
# ytIf the true label is requested for xt, then yt is fed to the model at the next time step with xt+1 to generate ot+1. Otherwise, if the model makes a prediction, a zero vector is given instead of yt. The model aims to maximize its expected reward over the episode through the Bellman loss function (Eq. 3.2).
Input ot
images 0 or ytI
j+1,
if =ytrt = -0.05 or -1 =eri ResNet-50 LSTM -+s x at = [0, 1] or 0]
Figure 4-3: Model diagram and training paradigm. At each time step within a training episode, a subject's input image is processed by a ResNet-50 model trained on ImageNet and compressed into a size-500 vector with PCA. This image representation is combined with a zero vector in the first time step. The LSTM output, representing the RL model Q-value, is processed through a linear layer and transformed into a one-hot action vector. Depending on whether the model decides to predict the label or request the true label, a zero vector or the true label is given with the next image representation. Additionally, a reward is assigned and used to update the model via the Bellman loss equation.
Chapter 5
Experiment Design
5.1
Training an Active Learner on Personalized
Af-fect Estimation
Based on the performance of the model on the source validation set Svai, the model was set to train for 40 training batches, or training steps, with each batch consisting of 50 episodes. During training, epsilon greedy action selection is used with E = 0.05,
with discount factor -y = 0.5, and an Adam optimizer with learning rate ir = 0.001.
Using the deep Q-network framework [211, an LSTM with 200 units is used to model the action-value function. To train the active one shot learning model, rewards are assigned as follows: Req = -0.05, Rcor = 1, and R,,c = -1. Additional values for Ric were tested, Ric = -5 and - 10, but brought about worse accuracy; thus, those
results are not discussed in this paper.
The experiments examine three training scenarios to train a generalizable, yet personalized model. Each model's final performance on Ta was analyzed to see how well the model can generalize to new subjects it has never been trained on, or how well it personalizes to these subjects after being trained on a subset of the target subjects' data. In the first model, the model is trained on Strain until convergence, pausing the training before the model starts to overfit the training set; we will refer to this model as the source active learning (SAL) model. The second model trains
on Strain, pausing the training at the same point as in the SAL model, then further
training the model on Ttrain; we will refer to this model as the personalized active
learning (PAL) model. Finally, the third model trains on Ttrain until convergence; we
will refer to this model as the target active learning (TAL) model.
The SAL model is trained on only the source training Strain set for 40 training batches, then evaluated on the target validation set Tai. The SAL model thus tests
the model's ability to generalize to new target subjects it has not trained on pre-viously. The PAL model is trained on Strain for 40 training batches, then further
trained on Ttrain for 40 training batches, after which it is evaluated on Tai. The PAL
model evaluates the model's ability to personalize to the target subjects while being evaluated on an unseen subset of the target subjects' data. Finally, the TAL model is trained on Ttrain for 40 training batches and evaluated on Tai as a control to see
the model's performance when trained on only the target training set and to observe if there exists any benefit to training on a broader population of subjects in the SAL model.
5.2
Evaluating the Model Label Request
Effective-ness
To examine the effectiveness of the requested data from the active learner over its training, the data for which the model requests labels is saved. After a supervised model can be trained on the requested data points and compared to a separate su-pervised model trained on the same number of random data points. Comparing the accuracy of these supervised models on a test dataset can validate whether the data points that the active learning model requests are meaningful data points that would help a supervised model to train to a high accuracy on the classification task.
Chapter 6
Results
A question of interest in training the SAL, PAL, and TAL models is whether these
models can create active learners with similar accuracy as supervised models, while demanding less training data for and showing higher confidence on the target valida-tion set Tai. Addivalida-tionally of interest is to compare the effects of personalizing the model on T,ain in the PAL model, versus not personalizing the model at all in the
SAL model and not creating a generalized model in the TAL model.
6.1
Model Accuracy and Label Requests
The experiments expose the overall trend that adding personalization to the active one shot learning model, through the PAL model, leads to better performance and lower demand for data on Tai. These findings are highlighted through analysis of the PAL model performance over time in Fig. 6-1, the final performance statistics of the model in Table 6.1, and averaged performance for each individual subject in Fig. 6-4. Unless specified otherwise, the accuracies reported do not include actions in which the active learner requested labels.
6.1.1
Model Performance Over Training
To show the effect of adding personalization to the active one-shot learning model, the accuracy and number of label requests from the model on Tvai were monitored over time. In Figures 6-1a and 6-1c, we observe the accuracy and number of requests from the active one-shot learning model when trained on only Strain during the first 40 training steps (the SAL model, effectively) and then switched to train on Ttrain for the second 40 training steps (the PAL model, effectively). The shift in training sets is indicated by a red vertical line.
Through Figure 6-la, it is apparent that as soon as the PAL model introduces training data from Train, its prediction accuracy spikes to a higher convergence point, near to that of the TAL model (Figure 6-1b). This result suggests that the model benefits from exposure to some data in Ttrain to achieve personalization. An additional observation is that the model's label requests on Tai quickly decrease to zero after about 10 steps into the PAL training (Figure 6-1c), similar as in TAL training (Figure
6-1d).
Additional investigation was performed to capture the cumulative percentage of label requests made by the three active learning models over the training steps. In the transition between the SAL to PAL models (Figure 6-2a), the cumulative percentage of requests quickly drops upon adding personalization to the active learner model training. Meanwhile, the TAL model cumulative percentage of requests (Figure 6-2b) decreases steadily in a manner that mirrors that of the raw number of requests at each time step (Figure 6-1d).
Thus, not only does the PAL model increase the active learner's accuracy on the target validation set, but it also dramatically reduces the number of label requests required by the model.
With the active one-shot learning training paradigm, there exists the concern that, over the training steps, each performing some number of experiment batches, the model will see all of the data. The data consumption of the active one-shot learning model during training, in source and target training settings, shows that the
model eventually sees 80% or more of the training dataset (Figure 6-3). While the model does not necessarily see 100% of the dataset, the UNBC-McMaster shoulder pain dataset is still a relatively small dataset. The experiments previously described may benefit from larger datasets to validate the results presented in this study.
6.1.2
Final Model Performance
In Table 6.1, the SAL, PAL, and TAL models are compared across the supervised and active learning settings, averaged over 10 trials. Compared to the supervised model which effectively requests all labels for the dataset, the active learning models lead to a trained model with similar or better prediction accuracy, but requiring dramatically fewer data points. While the TAL model performs best on points from Tai, the PAL model achieves both greater accuracy and fewer label requests. The SAL model lags behind in both model prediction accuracy and label requests.
Supervised RL (with requests) RL (excluding requests)
SAL Acc. 0.605 0.049 0.536 0.038 0.618 0.0117 PAL Acc. 0.683 i 0.229 0.9275 0.005 0.9275 0.005 TAL Acc. 0.831 0.291 0.934 0.009 0.934 0.009 SAL Req. 1 0 0.176 0.046 0.176 0.046 PAL Req. 1 0 0.009 0.003 0.009 0.003 TAL Req. 1 0 0.024 0.009 0.024 0.009
Table 6.1: Average model prediction accuracy on the target validation set and per-centage of label requests made on Tva. The RL models use Rc= -1, with the first RL model, listed in the second column, calculating accuracy by considering requests as incorrect predictions and the subsequent RL model, listed in the last column, evaluating accuracy based on only the prediction guesses that the model made.
Overall, these experiments demonstrate that personalizing the model to the target individuals increases accuracy to levels similar to or higher than the supervised model and lowers demand for labels for the target validation set. The PAL model thus helps us to create an active learner that can be personalized to target population data with lower demand for labels and comparable accuracy to a supervised model trained on the same source and target training datasets.
6.1.3
Per Patient Results
The individual subject results averaged over 10 trials, in Fig. 6-4a, show that the PAL and TAL models most often lead to higher accuracy on the Tai set for most individuals. Additionally, in Fig. 6-4b, we see that the number of requests for the
SAL model is highest, while the PAL and TAL models lead to similarly low request
rates. Thus, we confirm that the high accuracies from experimental results shown in Table 6.1 translate to the scope of individual patients.
6.2
Label Request Effectiveness
The accuracies of the two supervised models, one trained on the data requested by the active learning model during its training and the other on the same amount of randomly selected data, tested on a validation set with all patients in Tai (notably, a harder validation set than used in the previous experiments) can be viewed in Table
6.2. The accuracies are averaged over 10 experiment trials.
Random data Requested data
SAL Acc. 0.546 0.021 0.532 0.018
PAL Acc. 0.504 0.178 0.465 0.175
Table 6.2: Average accuracy of the supervised models trained on random data vs. the data points for which the active one-shot learning model requested labels.
The results show little difference in value of the requested data points and random data points, indicating that the data points requested during the training of the active learner might not be interpretable as salient training examples. A potential explana-tion for this outcome is that the UNBC-McMaster shoulder pain dataset may be too small (in number of subjects or number of data points per subject) for the model to generalize to larger validation sets. Alternatively, the feedback on requests that the active one-shot learning model makes may be just as important to the model's train-ing as the feedback on points that the model made a prediction. Further experiments examining the active learning model's request versus prediction decisions should be performed to better interpret the model's behavior during training.
Target validation prediction accuracy 0.9. 0.S 0.7 0.6 0.5-0 10 20 30 40 50 60 70 80 Training step (a)
Requests during target validation
600 500- 400-300 200- 10 0-0 10 20 0.95-0.90 0.85- 0.80-0.75. 0.70-0.65. 0.60-0.55. 500. 400 300 - 200- 10 0-30 40 50 60 70 s0 Training step (c)
Target validation prediction accuracy
0 5 10 15 20 25 30 35 40 Training step
(b)
Requests during target validation
0 5 10 15 20 25 3 35 40 Training step
(d)
Figure 6-1: Model prediction accuracy and number of label requests during training of the SAL, PAL, and TAL models for Tva. In Figures 6-la and 6-1c, in the first 40 training steps, the model is trained on Strain through the SAL model, and in the second 40 training steps, the model switches to train on Ttrain to personalize the model through the PAL model. The red line marks this transition point. Figure 6-1a shows the performance accuracy of the SAL and PAL models, while Figure 6-1c shows the label requests at each training step for the SAL and PAL models. Figures 6-1b and
Cumulative fraction of requests during target validation 0 10 20 30 40 50 60 70 80 Training step (a) 0.35- 0.30- 0.25-020 - 0.15- 0.10-0.05.
Cumulative fraction of requests during target validation
0 5 10 15 20 25 30 35 40 Training step
(b)
Figure 6-2: Cumulative fraction of label requests over the course of the SAL, PAL, and TAL trainings. Figure 6-2a shows the cumulative requests of the SAL model in the first 40 training steps and that of the PAL model in the second 40 steps. This transition is depicted with a red line. Figure 6-2b similarly shows the cumulative label requests for the TAL model.
Percent of source training data seen
0a.
(a)
Percent of target training data seen
0.6
I'o W 41D M 60 X N
(b)
Percent of target training data seen
a
a S Wn IS 20 2s 30 35 a (C)
Figure 6-3: Percentage of data seen by the model during training on the Strain in the
SAL and PAL models (Figure 6-3a), training on Ttrain in the SAL and PAL models
(Figure 6-3b), and training on Tain in the TAL model (Figure 6-3c).
t~..4
( 4 a ) (a) (b)Figure 6-4: Mean accuracy and percent of label request actions on Tai for each patient across the three different model training settings.
0.30 0.25 0.20-0.15 - 0.10- 0.050.00
-LLL...II
Chapter
7
Discussion
The findings of this study suggest that personalizing an active one-shot learning model on data from the target population can dramatically improve prediction accuracy while decreasing the number of label requests made by the active learning model. This PAL training paradigm can achieve similar, or sometimes better, performance than the TAL model or supervised models trained on Strain and Ttrain. Importantly, the PAL model achieves these high levels of accuracy using the lowest label requests when compared to the other training paradigms.
However, as indicated in Figure 6.2, the points whose labels the active one-shot learning model learns to request do not necessarily seem to be salient points for the model to learn the important features of Tai. By training a supervised model on the data points whose labels were requested by the active one-shot learning model and training a separate supervised model on random data, both models showed poor prediction accuracy on Tvai. One potential reason for this result is that the size of the dataset is too small for the training of the supervised models to yield meaningful results on Tai.
Additionally, because the experiment results shown in Figure 6.2 are reported on a validation set using all points from Tai from all patients versus a random sample of 40 data points from Tvai, as performed in the experiment results in Table 6.2, it may be possible that the model is successful at fitting to the patients in the size-40 validation set, but not generalizing to the entire Tai. Because testing the supervised
models on the full Tai dataset is a harder task, future work should test the supervised models on the same size-40 validation set as used in the other model experiments. More investigation should be conducted to explore applying this model to larger or more complex datasets and generating a more representative validation set for the experiments previously described.
Another potential direction is to fine-tune the personalized active learning model end-to-end, from the image preprocessing to the training of the active learning through deep reinforcement learning. With end-to-end training, the model could optimize at all modules of the training process, rather than solely the core components of the classification model.
Overall, the personalized active learning model achieves impressive results in pre-diction accuracy and efficiency of label requests; yet, with further validation and experimentation, this model could prove to be even more powerful.
Chapter 8
Conclusion
This work contributes a novel active one-shot learning learning model that learns to build a personalized active learner that balances learning general and personal-ized information for human affect data. As demonstrated on the UNBC-McMaster shoulder pain dataset, this meta learning model learns how to actively learn and how to decrease the model's need for labels, while achieving accuracies near to that of a supervised model. By personalizing the model on a subset of the target population, the model achieves even higher accuracy and lower requests on held out data from the target population.
Ideally, the social bots of the future will contain personalized active learning mod-els that can interact with people while processing the context and data signals from the humans in the interaction in an automatic and data-efficient manner. As hu-mans are creatures of emotion, our technology should be able to understand the rich palette of affective states that humans express and perhaps, in turn, help us better understand ourselves.
Appendix A
Code Guide
A.1
Main functions
Function Description
get-episode Samples one episode of data with one patient. get-model-performance Analyzes model output and performance metrics.
make-data arrays Creates train and validation datasets for later sampling.
rundatabatch Collects a batch of data and runs the batch through the model. run-supervised-test Trains a supervised model and saves the model performance.
save-requested-data Saves data points whose labels were requested by the training model. Table A.l: Main experiment functions and their description
Bibliography
[1] Philip Bachman, Alessandro Sordoni, and Adam Trischler. Learning algorithms
for active learning. 2017.
[21
Maya Cakmak, Crystal Chao, and Andrea L Thomaz. Designing interactions for robot active learners. IEEE Transactions on Autonomous Mental Development,2(2):108-118, 2010.
[3] Crystal Chao, Maya Cakmak, and Andrea L Thomaz. Transparent active
learn-ing for robots. In Human-Robot Interaction (HRI), 2010 5th ACM/IEEE
Inter-national Conference on, pages 317-324. IEEE, 2010.
[4]
Melanie Ducoffe and Frederic Precioso. Qbdc: Query by dropout committee for training deep supervised architecture. arXiv prepint arXiv:1511.06412, 2015.[5] Kathleen Kara Fitzpatrick, Alison Darcy, and Molly Vierhile. Delivering
cogni-tive behavior therapy to young adults with symptoms of depression and anxiety using a fully automated conversational agent (woebot): a randomized controlled trial. JMIR mental health, 4(2), 2017.
[6] Yarin Gal, Riashat Islam, and Zoubin Ghahramani. Deep bayesian active learn-ing with image data. arXiv preprint arXiv:1703.02910, 2017.
[7] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual
learn-ing for image recognition. In Proceedlearn-ings of the IEEE conference on computer
vision and pattern recognition, pages 770-778, 2016.
[8] Tianxu He, Shukui Zhang, Jie Xin, Pengpeng Zhao, Jian Wu, Xuefeng Xian,
Chunhua Li, and Zhiming Cui. An active learning approach with uncertainty, representativeness, and diversity. The Scientific World Journal, 2014, 2014.
[9] Natasha Jaques, Sara Taylor, Ehimwenma Nosakhare, Akane Sano, and Rosalind
Picard. Multi-task learning for predicting health, stress, and happiness. In NIPS
Workshop on Machine Learning for Healthcare, 2016.
[10] Christoph Kdding, Erik Rodner, Alexander Freytag, and Joachim Denzler.
Ac-tive and continuous exploration with deep neural networks and expected model output changes. arXiv preprint arXiv:1612.06129, 2016.
[111 Samira Ebrahimi Kahou, Xavier Bouthillier, Pascal Lamblin, Caglar Gulcehre,
Vincent Michalski, Kishore Konda, S~bastien Jean, Pierre Froumenty, Yann Dauphin, Nicolas Boulanger-Lewandowski, et al. Emonets: Multimodal deep learning approaches for emotion recognition in video. Journal on Multimodal
User Interfaces, 10(2):99-111, 2016.
[121 Sebastian Kaltwang, Ognjen Rudovic, and Maja Pantic. Continuous pain inten-sity estimation from facial expressions. In International Symposium on Visual
Computing, pages 368-377. Springer, 2012.
[13]
Ashish Kapoor, Kristen Grauman, Raquel Urtasun, and Trevor Darrell. Active learning with gaussian processes for object categorization. In Computer Vision,2007. ICCV 2007. IEEE 11th International Conference on, pages 1-8. IEEE,
2007.
[14]
Ksenia Konyushkova, Raphael Sznitman, and Pascal Fua. Learning active learn-ing from data. In Advances in Neural Information Processlearn-ing Systems, pages 4228-4238, 2017.[151
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural informationprocessing systems, pages 1097-1105, 2012.
[16] Johannes Kulick, Marc Toussaint, Tobias Lang, and Manuel Lopes. Active
learn-ing for teachlearn-ing a robot grounded relational symbols. In IJCAI, pages 1451-1457,
2013.
[171 Brenden M Lake, Ruslan Salakhutdinov, and Joshua B Tenenbaum.
Human-level concept learning through probabilistic program induction. Science,
350(6266):1332-1338, 2015.
[18] Patrick Lucey, Jeffrey F Cohn, Kenneth M Prkachin, Patricia E Solomon, and
lain Matthews. Painful data: The unbc-mcmaster shoulder pain expression archive database. In Automatic Face & Gesture Recognition and Workshops
(FG 2011), 2011 IEEE International Conference on, pages 57-64. IEEE, 2011.
[19]
Daniel Lopez Martinez, Ognjen Rudovic, and Rosalind Picard. Personalized automatic estimation of self-reported pain intensity from facial expressions. InComputer Vision and Pattern Recognition Workshops (CVPRW), 2017 IEEE Conference on, pages 2318-2327. IEEE, 2017.
[201 Hector P Martinez, Yoshua Bengio, and Georgios N Yannakakis. Learning deep physiological models of affect. IEEE Computational Intelligence Magazine,
8(2):20-33, 2013.
[21] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
[22] Kelly Peterson, Ricardo Guerrero, Rosalind W Picard, et al. Personalized gaus-sian processes for future prediction of alzheimer's disease progression. arXiv
preprint arXiv:1712.00181, 2017.
[23] Rosalind Wright Picard et al. Affective computing.
[24] Guido Pusiol, Laura Soriano, Michael C Frank, and Li Fei-Fei. Discovering the signatures of joint attention in child-caregiver interaction. In Proceedings of the
Cognitive Science Society, volume 36, 2014.
[251 Piyush Rai, Avishek Saha, Hal Daum6 III, and Suresh Venkatasubramanian.
Domain adaptation meets active learning. In Proceedings of the NAACL HLT
2010 Workshop on Active Learning for Natural Language Processing, pages
27-32. Association for Computational Linguistics, 2010.
[261 Ognjen Rudovic, Jaeryoung Lee, Miles Dai, Bjorn Schuller, and Rosalind Picard.
Personalized machine learning for robot perception of affect and engagement in autism therapy. arXiv preprint arXiv:1802.01186, 2018.
[271 Ognjen Rudovic, Jaeryoung Lee, Lea Mascarell-Maricic, Bj6rn W Schuller, and
Rosalind W Picard. Measuring engagement in robot-assisted autism therapy: A cross-cultural study. Frontiers in Robotics and AI, 4:36, 2017.
[28] Adam Santoro, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, and
Timo-thy Lillicrap. One-shot learning with memory-augmented neural networks. arXiv
preprint arXiv:1605.06065, 2016.
[29]
Jens Schreiter, Duy Nguyen-Tuong, Mona Eberts, Bastian Bischoff, Heiner Mark-ert, and Marc Toussaint. Safe exploration for active learning with gaussian processes. In Joint European Conference on Machine Learning and KnowledgeDiscovery in Databases, pages 133-149. Springer, 2015.
[301 Burr Settles. Active learning literature survey. University of Wisconsin, Madison, 52(55-66):11, 2010.
[311 Burr Settles and Mark Craven. An analysis of active learning strategies for
sequence labeling tasks. In Proceedings of the conference on empirical methods
in natural language processing, pages 1070-1079. Association for Computational
Linguistics, 2008.
[321 Xiaoxiao Shi, Wei Fan, and Jiangtao Ren. Actively transfer domain knowledge.
Machine Learning and Knowledge Discovery in Databases, pages 342-357, 2008.
[331
Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998.[34]
Devis Tuia, E Pasolli, and William J Emery. Using active learning to adapt remote sensing image classifiers. Remote Sensing of Environment, 115(9):2232-2242, 2011.[35] Oriol Vinyals, Charles Blundell, Tim Lillicrap, Daan Wierstra, et al. Matching networks for one shot learning. In Advances in Neural Information Processing
Systems, pages 3630-3638, 2016.
[361 Robert Walecki, Ognjen Rudovic, Maja Pantic, Vladimir Pavlovic, and Jeffrey F
Cohn. A framework for joint estimation and guided annotation of facial action unit intensity. In Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition Workshops, pages 9-17, 2016.
[37] Keze Wang, Dongyu Zhang, Ya Li, Ruimao Zhang, and Liang Lin. Cost-effective
active learning for deep image classification. IEEE Transactions on Circuits and
Systems for Video Technology, 2016.
[381
Xuezhi Wang, Tzu-Kuo Huang, and Jeff Schneider. Active transfer learning under model shift. In International Conference on Machine Learning, pages 1305-1313, 2014.[39]
Mark Woodward and Chelsea Finn. Active one-shot learning. arXiv preprintarXiv:1 702.06559, 2017.
[40]
Victoria Xia, Natasha Jaques, Sara Taylor, Szymon Fedor, and Rosalind Picard. Active learning for electrodermal activity classification. In Signal Processing inMedicine and Biology Symposium (SPMB), 2015 IEEE, pages 1-6. IEEE, 2015.
[411 Min Xiao and Yuhong Guo. Online active learning for cost sensitive domain adaptation. In CoNLL, pages 1-9, 2013.
[421
Zhihong Zeng, Maja Pantic, Glenn I Roisman, and Thomas S Huang. A survey of affect recognition methods: Audio, visual, and spontaneous expressions. IEEEtransactions on pattern analysis and machine intelligence, 31(1):39-58, 2009.
[43] Shusen Zhou, Qingcai Chen, and Xiaolong Wang. Active deep networks for semi-supervised sentiment classification. In Proceedings of the 23rd International
Conference on Computational Linguistics: Posters, pages 1515-1523. Association
![Figure 2-1: The general active learning framework with pool-based sampling. Image from Settles [30].](https://thumb-eu.123doks.com/thumbv2/123doknet/13845975.444408/17.917.242.673.117.360/figure-general-active-learning-framework-sampling-image-settles.webp)