A Computational Model of Moral Learning for
Autonomous Vehicles
by
Richard Kim
B.A. Economics
University of California, Los Angeles, 2006
Submitted to the Program in Media Arts and Sciences, School of
Architecture and Planning
in partial fulfillment of the requirements for the degree of
Master of Science in Media Arts and Sciences
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
June 2018
@
Massachusetts Institute of Technology 2018. All rights reserved.
Signature redacted
A u th o r . ...
.. ...
... ...
Program in Media Arts and Sciences, School of Architecture and
Planning
May 25, 2018
Signature redacted
/
Iyad Rahwan
Associate Professor of Media Arts and Sciences
Signatu
Thesis Supervisor
re redacted"
Tod Machover
Academic Head
Program in Media Arts and Sciences
Certified by ...
A ptdh
~s
OFRTECAR
A Computational Model of Moral Learning for Autonomous
Vehicles
by
Richard Kim
Submitted to the Program in Media Arts and Sciences, School of Architecture and Planning
on May 25, 2018, in partial fulfillment of the requirements for the degree of
Master of Science in Media Arts and Sciences
Abstract
We face a future of delegating many important decision making tasks to artificial in-telligence (AI) systems as we anticipate widespread adoption of autonomous systems such as autonomous vehicles (AV). However, recent string of fatal accidents involv-ing AV reminds us that delegatinvolv-ing certain decisions makinvolv-ing tasks have deep ethical complications. As a result, building ethical AI agent that makes decisions in line with human moral values has surfaced as a key challenge for Al researchers. While recent advances in deep learning in many domains of human intelligence suggests that deep learning models will also pave the way for moral learning and ethical decision making, training a deep learning model usually encompasses use of large quantities of human-labeled training data. In contrast to deep learning models, research in hu-man cognition of moral learning theorizes that the huhu-man mind is capable of learning moral values from a few, limited observations of moral judgments of other individuals and apply those values to make ethical decisions in a new and unique moral dilemma. How can we leverage the insights that we have about human moral learning to design AI agents that can rapidly infer moral values of human it interacts with? In this
work, I explore three cognitive mechanisms - abstraction, society-individual
dynam-ics, and response time analysis - to demonstrate how these mechanisms contribute to
rapid inference of moral values from limited number of observed data. I propose two Bayesian cognitive models to express these mechanisms using hierarchical Bayesian modeling framework and use large-scale ethical judgments from Moral Machine to empirically demonstrate the contributions of these mechanisms to rapid inference of individual preferences and biases in ethical decision making.
Thesis Supervisor: Iyad Rahwan
The following people served as readers for this thesis:
Signature redacted
Professor Alex 'Sandy' Pentland ...
Professor of Media Arts and Sciences
MIT Media Lab
Massachusetts Institute of Technology
Signature redacted
Joshua B. Tenenbaum ...
...
Pro essor of Computational Cognitive Science
Department of Brain and Cognitive Sciences
Massachusetts Institute of Technology
Acknowledgments
I would like to extend my deepest gratitude and appreciation to my advisor
Profes-sor Iyad Rahwan. ProfesProfes-sor Rahwan gave me the chance to be at MIT Media Lab, exposed me to many intellectually challenging problems, and provided me opportu-nities to collaborate with amazingly talented individuals who I otherwise could not have met. He showed me what it is to be a true inter-disciplinary scholar who can integrate ideas from various academic disciplines including psychology, economics, and computer science; moreover, do so in a way that is respectful towards scholars of those fields while challenging their established dogmas.
I also thank my readers, Professor Alex 'Sandy' Pentland and Professor Joshua B. Tenenbaum, for their contributions to my thesis by providing me with valuable comments. I feel honored and privileged to have my work read and approved by these two distinguished scholars.
This thesis could not have come to its fruition without the amazing work of my colleagues, Edmond Awad and Sohan Dsouza, two colleagues of Scalable Cooperation who designed and built Moral Machine. As this work is highly reliant on data from Moral Machine, it is no exaggeration to state that my work would not have been possible without preceding work of Edmond Awad and Sohan Dsouza. I also owe
deep gratitude to three individuals - Max Kleiman-Weiner, Andres Abeliuk, and
Niccolo Pescetelli. This work was inspired by the original work of Max Kleinman-Weiner. Andres Abeliuk and Niccolo Pescetelli also shared invaluable expertise as I struggled through several versions of the models proposed in this work. This work also could not have come to its fruition without contributions from these three talented individuals.
My time at Media Lab has been fun and memorable thanks to my colleagues in
Scalable Cooperation: Bjarke Felbo, Morgan Frank, Matt Groh, Ziv Epstein, May Allazzani, Jordan Hoffman, Judy Shen, Abhimanyu Dubey, Esteban Moro, Manuel Cebrian, and Amna Carreiro. I will always cherish the friendships that I made here. Finally, I want to express special gratitude to my family members who have shown
unconditional support and love. I thank my parents, Yong E. Kim and Hae K. Koo, for financial and moral support the last couple years as I took temporary break in my career to pursue an academic degree at MIT. Jiyeon Lee, my wife, for unconditional love she showed me through the toughest periods while pursuing the degree. I could not have asked for a better partner than Jiyeon through this tumultuous journey. Lastly, my son, Sunyul, who turned six this year. I had to sacrifice countless evenings and weekends to research, and despite my absence, he grew up to be such a delightful and joyful child. I owe him him my apology and my gratitude.
Contents
1 Introduction 13
1.1 Background . . . . 13
1.2 Summary of Contributions . . . . 18
1.3 O utline . . . . 18
2 Hierarchical Bayesian Models and Approximate Bayesian Inference 21 2.1 Hierarchical Bayesian Models . . . . 22
2.1.1 Example: Beta-Binomial Model . . . . 23
2.2 Approximate Bayesian Inference . . . . 27
2.2.1 Markov Chain Monte Carlo . . . . 27
2.2.2 Variational Inference . . . . 28
3 Moral Machine Data 31 3.1 Background . . . . 31
3.2 Description of Moral Machine Scenarios . . . . 32
3.3 Data Description . . . . 35
3.4 C onclusion . . . . 36
4 A Computational Model of Moral Learning 37 4.1 Background . . . . 38
4.2 Hierarchical Moral Principle Model . . . . 40
4.2.1 Feature Abstraction . . . . 41
4.2.3 Social Norm and Individual Preference . . . . 43 4.2.4 Examples . . . . 45 4.3 Evaluation . . . . 47 4.3.1 Benchmark Models . . . . 47 4.3.2 Tests . . . . 48 4.4 Conclusion . . . . 50
5 Response Time Analysis of Value-based Moral Decisions 53 5.1 Background . . . . 54
5.2 Factor Drift-Diffusion Model . . . . 55
5.3 Results and Discussion . . . . 58
5.3.1 Factor Weights . . . . 58
5.3.2 Uncertainty in Moral Dilemma . . . . 59
5.4 Conclusion . . . . 61
6 Discussion and Future Work 65 6.1 Contributions . . . . 66
6.2 Future Works . . . . 68
List of Figures
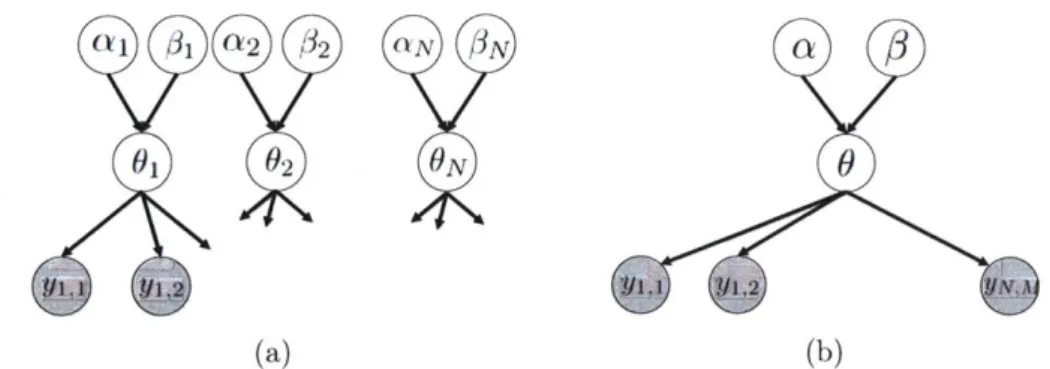
2-1 (a) Unpooled model (b) Pooled model . . . . 24
2-2 (a) Partially pooled (i.e. hierarchical) model (b) The hierarchical model in plate notation. Plate N indicates that there are N variables 02 representing N experiments indexed by i. Plate N x M indicates that there are M observed variables for each of N experiments. . . . . 26
3-1 An example of Moral Machine scenario . . . . 33
3-2 Twenty Characters of Moral Machine . . . . 33
3-3 Non-demographic Factors in Moral Machine . . . . 34
3-4 Distribution of responses by language of instruction. . . . . 34
3-5 Distribution of responses by country of residence . . . . 35
3-6 An example of vector representation of a choice in a Moral Machine scenario . . . . 36
4-1 An example of a binary matrix A that decomposes the characters in Moral Machine into abstract features. Black squares indicate the pres-ence of abstract features in the characters. . . . . 41
4-2 Vector representation of abstract features of a scenario choice. .... 42
4-3 Example of Covariance Matrix . . . . 44
4-4 Graphical representation of hierarchical moral principles model . . . . 44
4-5 Posterior distribution of the model parameters . . . . 46
4-6 Benchmark 1: Character-based Logistic Regression . . . . 47
4-7 Benchmark 2: Feature-based Logistic Regression . . . . 48
4-9 Evaluation results . . . .4
5-1 Graphical illustration of the drift diffusion process. a is the decision
boundary of response Y = 1. Parameter 3 indicates a priori decision
biases as a ratio of a to determine the starting position a#. Lastly, the dashed line before the initial step of the drift process is the nondecision
tim e r . . . . 56
5-2 Graphical model representation of factor analysis drift diffusion. Plate
represents T independent trials. Node Xt represents tuple (yt, rt) that
denotes the decision yt E {0, 1} and response time rt E R+ of trial t. . 57
5-3 Histogram of response time distributions . . . . 58
5-4 Comparison of inferred weights w of FDDM (a) and logistic regression
(b ) . . . . 59
5-5 Comparison of standard deviations of the inferred net utility values
from FDDM and logistic regression. Values along the x-axis are the standard deviations of net utilities derived from FDDM. Values in the y-axis are the standard deviations of net utilities inferred from logistic regression. Points that lie above the 450 diagonal line indicate scenarios that have higher standard deviation from logistic regression. Of the
6500 points, 80.2% lie above the diagonal line. . . . . 62
5-6 (a) Scatter plot of expected utility value E[ut] and standard deviation
o0
Ut. Color of the data point represents response time. Plot is divided
into four quadrants by dividing the data by the median values of two axes. (b) Toy representation of distributions of the net utility values
in each quadrant. . . . . 63
5-7 Comparison of response times in four quadrants. Blue bars indicate
the mean response times and narrow red bars show 95% bootstrap
(n=10000) confidence intervals. . . . . 63
Chapter 1
Introduction
1.1
Background
Advances in artificial intelligence (AI) and sensor technologies have made widespread adoption of autonomous systems such as autonomous vehicles (AV) closer to a reality. Thanks to autonomous systems, we will delegate important decision making tasks to AI agents, which holds many beneficial promises. For instance, it is estimated that approximately 90% of traffic fatalities can be reduced through the widespread adoption of AV's [271.
Due to the possibility of dramatically reducing traffic fatalities, AV has garnered great excitement in the media and attracted large commercial and academic research investments. However, recent string of fatal accidents involving AV [84, 85] has re-minded the public that there are ethical and legal complications to yielding control of vehicles to Al agents. These complications has catapulted the issue of AL ethics (or machine ethics) into the forefront of Al research and has made it imperative for engineers, AI researchers, and policy makers to examine approaches to incorporate society's ethical standards into the AI's decision making processes.
For example, suppose an AV experiences a brake malfunction and as a result of the defect it faces a unfortunate choice of either killing an elderly man in his seventies inside the vehicle by swerving and crashing into a wall or killing an eight year old pedestrian girl by staying on its course. In this rare, but not an improbable,
scenario, whom should the AI agent sacrifice? How can Al researchers and engineers instill society's ethical values in the mechanistic decision making process such that the decision is deemed acceptable, or at least preferable to the alternative, by the
public at large?
Interestingly, the idea of codifying ethical behaviors in an artificially intelligent system is not a new concept. In his work "I, Robot," published in 1950, the author Isaac Asimov introduced Three Laws of Robotics that governed robot's behaviors:
* A robot may not injure a human being or, through inaction, allow a human being to come to harm.
* A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.
* A robot must protect its own existence as long as such protection does not conflict with the First or Second Laws.
Today, Asimov's Three Laws is considered a thought provoking introduction to the notion of AI ethics, but codifying these laws into a computer program to create a truly ethical AI agent is not considered a viable approach [2, 86].
Recently, machine learning, a branch of computer science that uses statistical techniques to learn from data, has become front and center of AI research. Within the field of machine learning, deep learning, a class of models that uses artificial neural network architectures inspired by biological system of intelligence, have demonstrated impressive feats in various domains of human intelligence including computer vision
[761, machine translation [89], speech generation [60], and many others. In fact, in
a domain as abstract as human emotion, deep learning models have shown close to human-level proficiency in detecting human emotions in natural language text [231. Most of these achievements were once considered beyond the reaches of machine intelligence just a couple of decades ago.
The remarkable achievements by deep learning models may lead one to conclude that they will also pave the way for research in learning ethical values and ethical
decision making by machines. However, Al researchers face several challenges in applying deep learning models in the domain of ethics. Most notably, training a
deep learning model often requires extremely large quantities of human-labeled data
-usually much larger than other machine learning models. Although researchers in deep learning models have made recent advances that enable their models to be trained with smaller number of examples [83, 72], this constraint remains a key challenge in deep learning research.
In contrast to the state-of-the-art deep learning models, human mind is capable of learning from a much smaller number of noisy and sparse examples [49]. Commonly referred as "poverty of stimulus," this remarkable capacity of the human mind was first noted in language acquisition of children. Linguists and developmental psychol-ogist observed that children demonstrate ability to rapidly learn morphological rules and hierarchical phrase structure of a language from limited observations [14] and that their ability to generate sentences and understanding meanings of new words cannot be merely explained by experience alone [521. Evidence from studies in hu-man learning suggests that the ability to learn from limited experience and to apply the lessons across new instances cuts across many domains of human intelligence [79] including learning moral values from a limited observations of ethical decisions and their outcomes [54, 88, 45].
Leveraging this insight about the human mind, how can we build an AI agent such that it has the capacity to learn moral values and societal preferences from limited interactions with people and observations of their actions? In this thesis, I explore three mechanisms that guide moral learning in humans and express them as a Bayesian model of cognition using hierarchical Bayesian modeling framework. My goal is to demonstrate how we can engineer ethical Al agents that can rapidly learn moral values and overcome "poverty of stimulus" [14].
First, children do not learn to make ethical decisions by weighing the trade-offs of values associated with specific characters and consequences involved in an instance
of moral dilemmas. Rather, they learn generalizations of moral values from a few
many novel instances of dilemmas that involve different set of characters and different degrees of harm. For example, suppose a child is reprimanded by his parents for tormenting a stray cat. From this experience, a typical child will learn not only to value the specific cat involved but will also learn not to cause harm to innocent animals in general. He may further generalize the lesson to a principle of respecting all living creatures. As a result, his parents should not expect their child to harm another species of animal such as a bird, which results in a separate lesson about respecting birds. The capacity for abstraction enables a child to take moral values learned from a single instance of moral dilemma and generalize them across infinitely unique instances of moral dilemmas.
Second, moral values and behavioral norms vary enormously from one society to another. For example, while certain societies view preferential treatment of family and friends with disdain and consider it as an example of corruption, other societies deem such preferential treatment as a moral obligation. Furthermore, although individual preferences and biases may be idiosyncratic due to unique life experiences of the individual, people belonging to the same ethnic or national groups share a similar set of values and behavioral norms. Therefore, one can often infer a great deal of information about a person's behavioral patterns and his values from his ethnic or cultural information.
Finally, when one observes a decision being made by another person facing a moral dilemma, response time (RT), the time she took to arrive at the decision, provides a clue about the inherent difficulty of the dilemma and the latent confidence level of the decision maker. For example, when faced with the dilemma to save the life of a five-year old girl versus that of an adult who is convicted criminal, most people are quick to make their decisions in favor of the little girl. However, when the dilemma is between a five-year girl versus three innocent adults, the trade-offs of the values are not as obvious for many people. As a result, people assess consequences of their decisions more carefully and methodically, which leads to accumulation of response time.
in predicting human decisions in moral dilemma found in Moral Machine, a web
application that collects human judgments in ethical dilemmas involving AV. 1 A
recent study of public sentiment about AV reveals that endowing AI driver with societal preferences and capacity to make ethical decisions is an important step before AV can undergo widespread commercial adoption [12]. In light of this recent finding, the models proposed here, in combination with Moral Machine platform, can serve as a meaningful demonstration of an approach that AI researchers and engineers should adopt and further explore in building ethical Al agents for AV and other autonomous systems.
Moreover, while Moral Machine scenarios are examples of moral dilemmas, they do not provide comprehensive and realistic picture of ethical complications that may
arise in the real-world. Real-world moral dilemmas rarely have binary choices of
actions with binary outcomes. The full extent of the consequences of our choices in dilemmas are never truly known in advance, and they are revealed in sequences, which enable people to adjust and react accordingly. In light of the limitations posed
by Moral Machine data, I note that the goal of this work is not to propose a general
model of ethical decision-making that incorporates all learning mechanisms, behav-ioral norms, and moral values, in a complex and comprehensive measure in which the details can vary greatly depending on the philosophical tradition (e.g. deontology vs consequentialism). Furthermore, it is also not the goal of this thesis to propose a pre-scriptive and normative form of ethical decision making that can be used as a module in a working AV system. Throughout this thesis, I sidestep philosophical discussion about the normative form of ethics. Rather, my focus here is to explore how three
mechanisms - abstraction, society-individual dynamics, and response time - can play
important roles in Bayesian models of moral learning and show how insights from cognitive psychology can be applied to building ethical AI agents for autonomous systems.
1.2
Summary of Contributions
Contributions of this thesis can be summarized as follows:
e Explore the latest Bayesian framework to propose a new computational model
of moral learning in order to analyze and predict human judgments in moral dilemmas in Moral Machine and empirically demonstrate the robustness of the model's capacity to rapidly infer individual preferences in abstract dimensions of moral dilemma.
e Introduce a principled approach to simultaneously inferring the idiosyncratic
preferences of individuals in moral judgments and the group-norm that repre-sents aggregation of those individual preferences.
* Combine sequential sampling model with factor analysis to propose a new Bayesian model of cognition to characterize how the mind weighs the features of moral dilemmas to arrive at a decisions.
* Using reaction time as an additional evidence, I show that the new model that incorporates reaction times yields quicker inference of societal preferences in the outcome of moral dilemmas.
* Demonstrate an approach to replicate "poverty of stimulus" in moral learning of the human mind by combining abstraction, society-individual dynamics, and response time.
e Demonstrate a step toward engineering AV system that can learn to make
ethi-cal decisions on the road from limited interactions and observations of behaviors of human drivers using a novel data from Moral Machine.
1.3
Outline
In Chapter 2, I provide a brief explanation of hierarchical Bayesian modeling frame-work and a discussion on innovations in approximate Bayesian inference
method-ologies. This chapter will provide the methodological foundation for the rest of the thesis. As a prelude to the models introduced in the later chapters, Chapter 3 contains descriptions of Moral Machine including the discussion on the original motivations behind deployment of Moral Machine. I also describe representation of data from Moral Machine relevant to the models that I introduce in later chapters, which will serve as a key step in understanding the features of the model in Chapter 4 and Chapter 5.
In Chapter 4, I present hierarchical moral principles model (HMPM). After briefly discussing the background of hierarchical Bayesian model in moral learning in Section 4.1, I provide detailed description of various elements of this model including abstract features of moral dilemma and representation of individual as a unit of society. In Section 4.3, I report on evaluation of HMPM in predicting human decisions against three benchmark models using data from Moral Machine.
In Chapter 5, I introduce of a Bayesian model that incorporates response time in moral decision making as evidence for model parameter inference. The chapter begins with a brief introduction to drift-diffusion model (DDM) in Section 5.1, which is followed by a section that provides details of factor drift diffusion model (FDDM) that combines DDM with aspects of the hierarchical moral principle model in Chapter 4. Using data from Moral Machine, I show that FDDM is capable of inferring parameter values using response time information.
Finally, in Chapter 6, I conclude the thesis with a brief discussion to summarize the main contributions of this work. In addition, I note the limitations of the approaches presented here and propose interesting future directions to address these limitations.
Chapter 2
Hierarchical Bayesian Models and
Approximate Bayesian Inference
Background knowledge plays an important role in acquisition of new knowledge in the human mind. Structural representation of the background knowledge guides the mind to restrict the hypothesis space to consider, which enables the mind to learn more from sparse observational data. Al researchers commonly refers to this as "inductive bias," and statisticians call it "priors." [79].
Bayesian inference provides a principled approach to express the relationship be-tween background knowledge and updated understanding of the world after new data has been observed. Hierarchical Bayesian modeling framework [28] takes this idea and offers a formalism to express uncertainty and structural representation of background knowledge. Due to its expressiveness of how the mind uses prior information to aid in learning, hierarchical Bayesian inference has been widely explored in cognitive research.
In addition to hierarchical Bayesian modeling framework, many approximate Bayesian inference methodologies have been introduced, notably Markov Chain Monte Carlo and Variation Inference. These innovations have enabled Bayesian modelers to ex-plore large statistical models with complex relationships between variables and have contributed to broader applications of Bayesian statistical models in scientific research including cognitive science [80].
The aim of this chapter is to provide a brief explanation of hierarchical Bayesian modeling framework in Section 2.1 using a simple example and to offer a short sur-vey of the innovations in approximate Bayesian inference methodologies in Section 2.2. While it is not meant to be a thorough survey of these two rich subjects, this chapter will serve as a general foundation for many concepts that will be introduced in subsequent chapters.
2.1
Hierarchical Bayesian Models
At its core, Bayesian inference involves computation of joint probability
distribu-tion P(Y, 0) of observed data Y and latent parameters 6. Uncertainty about latent
variables 0 is expressed as prior distribution P(0), and after observing the data,
up-dated belief about the variables is characterized by posterior distribution following the Bayes' rule:
P(OIY) =
P(0)P(YIO)
(2.1)P(Y)
where P(Y 6) is the probability of the data given the hypothesis 0, also called the
likelihood. Evidence P(Y) is a marginalized probability P(Y) = fe P(Y, 0)dO where
E
is the entire hypothesis space. Because computation of P(Y) is intractable onemust resort to approximate Bayesian inference methodologies, which I discuss in the following section.
In Bayesian inference, computation of posterior distribution P(OIY) is highly de-pendent on the choice of prior distribution P(O), which is the primary criticisms leveled against Bayesian statistics by proponents of classical statistics, which does not specify prior distribution. Nonetheless, because hierarchical Bayesian inference offers a principled approach to incorporating background information to inference based on new evidence, it has been embraced as a popular mean to characterize the
human mind and how it learns [791.
Below, we demonstrate an application of hierarchical Bayesian inference using a simple example.
2.1.1
Example: Beta-Binomial Model
Conjugate priors are a class of probability distributions in the exponential family of distributions (e.g. Normal, Gamma, Beta, Poisson, etc.) wherein posterior distribu-tion follows the same parameter form as the prior distribudistribu-tion. Due to this property, use of conjugate priors offer a mathematically convenient, closed-form solution to derivation of posterior distribution. Here, we use Beta-Binomial model in which Beta distribution is a conjugate prior of Binomial distribution. We borrow a popular ex-ample from Bayesian Data Analysis [28] to demonstrate how one applies hierarchical Bayesian modeling framework to a solve an inference challenge.
In a clinical experiment, researchers are interested in estimating the probability that a rat develops a tumor in a population of female laboratory rats that did not receive a dose of drug treatment. In the latest experiment, four out of fourteen rates developed a tumor, which is equivalent to 28.5% of rats in this experiment. In addition to this result, researchers obtained results of seventy other experiments (Table 2.1). How can researchers incorporate data obtained from the latest experiment and the results from the previous experiments to arrive at more accurate predictive model to estimate the probability that a rat develops a tumor?
0/20 0/20 0/20 0/20 0/20 0/20 0/20 0/19 0/19 0/19 0/19 0/18 0/18 0/17 1/20 1/20 1/20 1/20 1/19 1/19 1/18 1/18 2/25 2/24 2/23 2/20 2/20 2/20 2/20 2/20 2/20 1/10 5/49 2/19 5/46 3/27 2/17 7/49 7/47 3/20 3/20 2/13 9/48 10/50 4/20 4/20 4/20 4/20 4/20 4/20 4/20 10/48 4/19 4/19 4/19 5/22 11/46 12/49 5/20 5/20 6/23 5/19 6/22 6/20 6/20 6/20 16/52 15/47 15/46 9/24
Table 2.1: Tumor incidents in rats in seventy clinical experiments [78]. The numbers on the left sides denote the number of rats that developed a tumor; the numbers on the right sides denote the total sample population of rats.
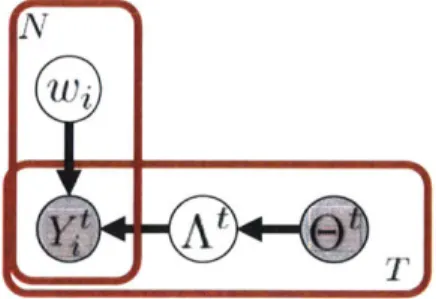
Consider a model in which each experiment i is an independent experiment that provides no insight about other experiments. We call this unpooled model because the probability that a rat develops a tumor in i-th experiment 0, is expressed as an independent Beta distribution with hyperparameters ozi and /3. The full joint
al 01 a2 132 aN ON
a
3
01
02 ONk111 Yi k, Y1
(a) (b)
Figure 2-1: (a) Unpooled model (b) Pooled model
posterior distribution of the unpooled model parameters is
N Al
P(0, a,
31Y)
oc17
P(Oilai, #3)P(aj)P(03)17
P(y,j 10,) (2.2)where 0 = (01,...,ON), a (a1,--, aN), and /3 ( 3
1,.--, 3N). Observed variable
Y = (Yi, ... , YN) where y, is a vector of size M where each element yij represent
outcome for j-th rat in i-th experiment. This Bayesian network is schematically
represented as a graphical model shown in Figure 2-la.
Here, researchers gain no insight into the parameter value of the new experiment from the results of previous experiments. The probability of rat developing a tumor
in the latest experiment is 071 - Beta(a
+
4, 3+
10) with the expectation of a+4If one assumes uninformative Beta prior with hyperparameters a = 0,/3 = 0, then
the expected probability is equivalent to the solution achieved via classical statistics,
4 = 0.285.
14
Alternatively, let us consider a model in which all outcomes of seventy experiments are modeled as instances of a single Binomial distribution parameterized by 0, which
has a Beta prior with hyperparameters a and 3. We call this pooled model because it
only accounts for a single population distribution. Posterior distribution of the model parameters is
N M
P(0, a, /, Y) oc P(0 1a, )P(a)P()
fJ
]7
P(yi,j 1)
(2.3)
% jFigure 2-1b provides graphical representation of this model.
Similar to the unpooled model, posterior distributions of the model parameters can also be derived using conjugacy of Beta distribution to Binomial likelihood. Hence,
the posterior distribution is 6 ~ Beta(a + 267, /3+ 1472), and assuming
hyperparam-eters a = 0, 3= 0, the expectation is a+263 = 0.153. Note that the expected
value of the probability is substantially smaller than the previous model. Also, variance of the population parameter
(a + 267)(3 + 1472)
(a +
/
+ 1739)2(a +/
+ 1739)suggests that the outcome of the latest experiment is an extreme outlier that cannot be explained by this model. This is due to the pooled model ignoring the differences in the rats and conditions of the experiments.
Finally, we consider a hierarchical Bayesian modeling approach where we separate the parameters of individual experiments and the population statistics. We call this
model partially pooled model. We set the parameters 0 (1, ... , ON) of the individual
experiments using Beta distributions similar to the unpooled model. However, instead
of each i-th experiment having its own hyperparameters a, and /i, we pool the
hy-perparameters into a set of population parameters a and / shared by all experments.
The full joint posterior distribution is
N M
P(0, a,
/,Y) 0c P(a)P(3)
fJ
P(Oia,
/3)]7
P(yg 10)
(2.5)
i j
where 0 = (61, ON). This model is displayed as a graphical model shown in Figure
2-2.
In this model, we derive the probability of a rat developing a tumor in experiment
71 as 071 ~ Beta(a + 4, / + 10), not unlike the solution in the unpooled model.
However, we use a more informative prior on a and 3 that is derived from properties
of Beta distribution:
E[01(1 - E[O])
a
/
N
0(
(b)
Figure 2-2: (a) Partially pooled (i.e. hierarchical) model (b) The in plate notation. Plate N indicates that there are N variables
experiments indexed by i. Plate N x.Al indicates that there are M
for each of N experiments.
3
=(a + 3)(1 - E[])
hierarchical model 9i representing N observed variables (2.6) (2.7)resulting in a = 1.4 and 3 = 8.6. As a result, the posterior distribution on the
parameter of the new experiment is 671 Beta(5.4, 18.6), which has expectation of
E[67 1] = 0.223. Contrast this figure with the original estimation using a classical
statistical method -14 = 0.285. Taking into account historical results of the past
ex-periments, researchers can arrive at an estimation that is closer to the population mean. Yet, the model also enables the researchers to respect the idiosyncratic differ-ences in rats and laboratory conditions in every experiment to derive unique solutions to parameter estimation in each experiment.
Although the example here has a closed-form solution thanks to the conjugacy of Beta distribution to Binomial likelihood, most statistical modeling tasks must extend beyond conjugate priors. In the following section, we turn our attention to inference frameworks that has enabled Bayesian modelers to incorporate more complex and
arbitrary relationships between model parameters.
(a)
2.2
Approximate Bayesian Inference
Although convenient in finding solution to posterior distribution, conjugate priors alone cannot express large and complex Bayesian models. For more sophisticated models that involves large interdependent relationships between model variables, many sophisticated algorithms have been introduced to approximately infer posterior
distributions. Principally, these algorithms belong to two families of methodology
-Markov Chain Monte Carlo and Variational Inference (or, Variational Bayes).
2.2.1
Markov Chain Monte Carlo
Markov Chain Monte Carlo (MCMC) is a general methodology for drawing sample values from the posterior distribution of model parameters using approximate
distri-bution. The methodology draws sequence of values 01, 02, o3, ... that form a Markov
Chain. More specifically, the algorithm starts with some starting point value 00, and
then for each t = 1, 2, ... , it draws 0' from a transition distribution Pt(OtI1-l) that
depends on the previous draw 0 1 to create the sequence of values. Although it is an approximation methodology, MCMC algorithms guarantee that the sequence
asymptotically converge toward the the true posterior distribution 1681.
The first MCMC algorithm, which was hailed as one of "The Top Ten Algorithms
of the 20th" Century[19], is the Metropolis algorithm [531. Metropolis algorithm
begins by starting from a random first value 00. Then, for t = 1, 2, ... , its draw a
proposed value 0* from from current value Ot using a transition distribution, typically
Normal or Uniform distribution with a step size at that determines the strength of the change. We set Ot = 0* with acceptance probability
A(6*10t) =min 1, (2.8)
otherwise, we maintain Ot = Ot-1. It's extension, Metropolis-Hastings algorithm,
extends the earlier version by enabling transition distribution to be specified to any arbitrary distribution, other than Normal or Uniform distribution, as long as it meets
certain restrictions [34].
Since the introduction of Metropolis-Hastings algorithm, many other MCMC
al-gorithms have been proposed. Slice sampling [591 eliminates the need to tune the step
size in Metropolis algorithm by using auxiliary variable to automatically adjust the step size to the local contour of the density function. A recent addition to the
fam-ily of MCMC algorithm is Hamiltonian Monte Carlo (HMC) [21, 58], which borrows
ideas from Hamiltonian physics to reduce the random walk property of Metropolis-Hastings algorithm in order to rapidly move through the target distribution. It is also frequently called Hybrid Monte Carlo as the algorithm combines stochastic and deterministic sequence of steps. HMC has been shown to be more robust against high dimensional problems than the Metropolis-Hastings [4]. Finally, no-U-turn sampler
[38] further extends HMC by automatically adjusting the number of steps between stochastic and deterministic steps.
2.2.2
Variational Inference
While MCMC algorithms are indispensable tools for today's Bayesian statisticians, they are computationally intensive. Consequently, certain large-scale problems with large data sets or those requiring complex models with hundreds, if not thousands, of latent values become intractable to solve using MCMC algorithms. An alternative
to MCMC algorithms, Variational Inference (or, Variational Bayes)
1401
is a classof algorithms that resorts to optimization to approximate the posterior distribution instead of stochastic simulation using Markov chain. Variational Inference (VI) al-gorithms do not provide asymptotic guarantees; however, they tend to significantly faster than MCMC, which makes them attractive tools for large-scale problems [6].
The main idea behind VI is to search for a set of parameters
4
in anotherdistri-bution Q(#) that minimizes the Kullback-Liebler (KL) divergence between Q(#) and
the original posterior distribution P(OIY). VI algorithm is formally summarized as
Q*(#)
= arg min KL(Q(O)I|P(OIY)) (2.9)where KL divergence is defined as
KL(Q(#)
I
P(OIY))
=E[log
Q(#)] -
E[log P(OIY)]
=
E[log
Q(#)] -
E[log P(O, Y)] + log P(Y)
However, because evidence P(Y) cannot be easily derived, directly minimizing the the KL divergence is usually not easy. Instead, one maximizes the Evidence Lower-Bound
(ELBO),
ELBO(Q) = E[log P(O, Y)] - E[log Q(#)] (2.10)
which is equivalent to negative value of KL divergence plus the evidence P(Y), which is a constant with respect to Q(#). One can show that maximization of the ELBO with respect to Q(O) is equivalent to minimization of the KL divergence and that
optimal approximation
Q*
(q) is close approximation, with bound P(Y), of the originalposterior distribution P(91Y) 16].
Until recently, with the introduction of Stochastic Variational Inference (SVI) [371 algorithms starting with Black-box Variational Inference (BBVI) [641, application of VI has gained increased traction among Bayesian statisticians as an alternative to MCMC. This is because SVI uses simulation methods to automatically compute
the gradient of the ELBO with high precision. As a result, researchers are able
to approximate posterior distribution without painstakingly deriving the gradient information of the ELBO on any model that uses continuous probability distributions.
The latest method is Automatic Differentiation Variational Inference (ADVI) [471,
which has significantly improved the precision of the gradient estimation.
While SVI is faster than MCMC, it does not have asymptotic guarantee that
MCMC provides. As it relies on approximation of the target distribution, SVI is
susceptible to getting stuck in the local maxima of the ELBO. This is one of the
principle issues that researchers are currently aiming to address [6]. Finally, SVI
methodologies utilize gradient of ELBO, which requires that the density functions of both the original posterior distribution P(OIY) and approximation Q(#) only contain continuous distributions. Extending SVI to discrete distribution is another area of
Chapter 3
Moral Machine Data
Proliferation of autonomous vehicles in our roads in the near future have made it imperative that we understand ethical implications of yielding control over to artificial intelligence. To this end, Moral Machine was deployed to collect data in order to understand society's preferences in how AI should resolve moral dilemmas in the road. In this chapter, we describe the details of Moral Machine platform and how we intend to use its data for models introduced in later chapters.
In Section 3.1, I describe the background behind the original goal of Moral Ma-chine. I clarify the differences in the goal of this work and the original work that motivated the deployment of Moral Machine. Afterwards, in Section 3.2, I describe salient aspects of Moral Machine for our purpose, and in Section 3.3, I explain data representation of Moral Machine scenarios that will become important for under-standing the models that we will introduce in later chapters.
3.1
Background
Moral Machines is a web platform built with the goal of aggregating human perception of ethical decisions made by autonomous vehicles (AV) and facilitating discussions about the ethical implications of widespread adoption of AV. It was built by Edmond Awad and Sohan Dsouza of Scalable Cooperation research group with guidance from Iyad Rahwan, Jean-FranAgois Bonnefon, Azim Shariff and contributions from many
other members of Scalable Cooperation.
Despite popular misconception by critics [74, 26, 67], Moral Machine was never built with the goal of crowdsourcing human judgments in moral dilemmas in order to use them as a training data for building ethical AV. Rather, it was built to collect people's preferences about how an AV should make a decision when faced with a moral dilemma and to understand how those preferences are different from society-to-society at global scale.
Since its launch in June 2016, Moral Machine has garnered intense public interest thanks to the though provoking and timely nature of the topic it addresses. As a result, it has served as a catalyst for vigorous discussions in the media about Al ethics and public policy surrounding AV. As of April 2018, Moral Machine has collected over 40 million responses from approximately 4 million unique respondents from over 200 countries and territories around the world. Measured in number of participants, it is considered the largest psychological experiment in ethics.
In this work, our goal is not to perform comprehensive analysis of all the responses recorded by Moral Machine nor to uncover cross-cultural differences in ethics between people of different countries. Rather, the goal here is to utilize the response data from Moral Machine to demonstrate learning of moral values using hierarchical Bayesian models. With this goal in mind, we use different representation of data from Moral Machine from that of the original work, and our understanding of the salient design features of Moral Machine will be critical to understanding how we use this data to evaluate the models discussed in later chapters.
3.2
Description of Moral Machine Scenarios
When a visitor participates in the judge mode of the Moral Machine platform, she is requested to complete thirteen scenarios such as an example shown in Figure 3-1. In each scenario, respondent is asked to choose one of two outcomes that they personally deem preferable to another.
-A-4 MORA
MACHINE
What should the self-driving car do?
111111111 I~ R 111I
Figure 3-1: An example of Moral Machine scenario
Man Woman Boy Girl Senior Senior Baby Pregnant Large Large
Man Woman Woman Man Woman
Fit Fit Business Business Male Female Homeless Criminal Dog Cat
Man Woman Man Woman Doctor Doctor
Figure 3-2: Twenty Characters of Moral Machine
3-2) that represent people of various demographic backgrounds found in a general
population.
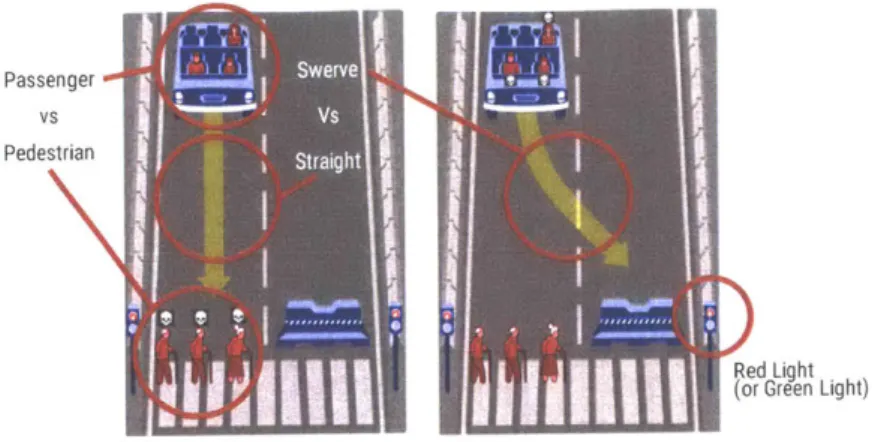
Besides the characters, Moral Machine incorporates three non-demographic
fea-tures - interventionism, relationship to vehicle, and concern for law. Every Moral
Machine scenario involves choosing to stay or to swerve. Some Moral Machine sce-narios require choosing to save characters inside an AV or pedestrian characters who are in a crosswalk. Finally, in some scenarios, pedestrians may be abiding by the law
by crossing at the green light or violating the law by crossing at the red light. Figure 3-3 shows how these factors are represented in Moral Machine scenarios.
In addition, each time a scenario is shown to a respondent, Moral Machine cap-tures response time, number of miliseconds that the respondent waited to submit an
Passenger r
vs _-7 V
Pedestrian
(or Green Light)
Figure 3-3: Non-demographic Factors in Moral Machine
answer. This information is recorded along with the features of the scenario and the respondent's answer.
Since its launch, Moral Machine platform has been translated into eight languages
- French, German, Spanish, Chinese, Japanese, Korean, Arabic, and Russian - in
order to ensure that the platform captures cross-cultural variations in the perceptions of ethical decisions. Figure 3-4 shows distribution of the respondents by language that was used to partake in the Moral Machine experiment.
0.8 0.7 0.6 c 0.5 a 0.4 0 ae 0.3 0.2
0.1-0.0 English Spanish Japanese Portuguese German Russian French - ,--Chinese Korean Arabic
Figure 3-4: Distribution of responses by language of instruction.
Moral Machine also attempts to record the approximate locations of the respon-dent by tracking tIP addresses of the devices that they used to log on to the website. Using the IP addresses, we are able to locate the country where the respondents were
from more than 230 countries and territories around the world visited the website. Figure 3-5 shows distributions of respondents by country.
0.30 0.25 C 0.20-0 0.15-0 * 0.10. 0.0
3.3
Data Description
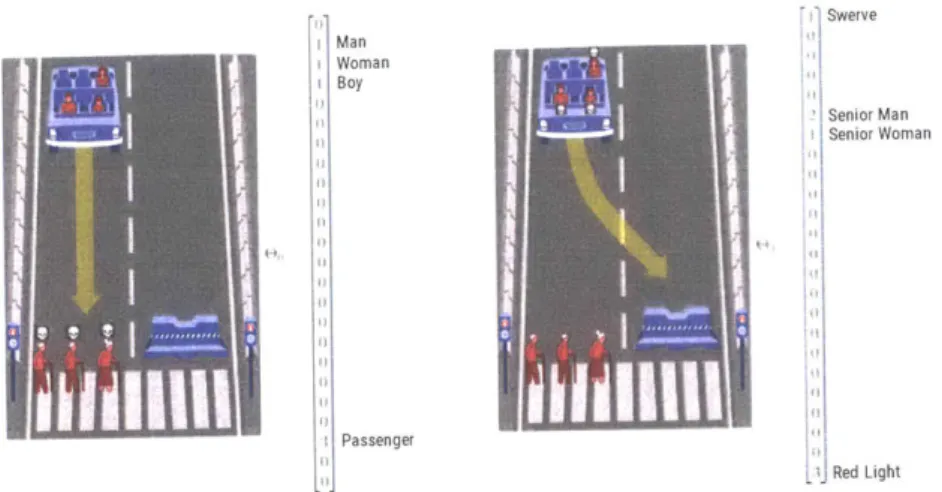
In this work, I represent respondent's choice in a Moral Machine scenario as a random
variable Y and count vector
e,
of twenty-four dimensions in which each element of the vector denotes the number of salient features associated with choice y. Together,a scenario is a set of vectors
e=
{
0,
1}, in which Y = 0 denotes the choice of stay,
and Y = 1 denotes the choice of swerve.
Figure 3-6 guides the discussion with an example of the vector representation of a scenario. The choice of allowing the AV to go straight will save a man, a woman, and a boy who are passengers. Therefore, we present this choice as vector
e
0
with values of 1 in elements of the vector that represent these characters. The element of"passenger" is encoded with value of 3 to denote that there are three passengers. On the other hand, the choice of swerving will save two elderly men and one elderly woman who are crossing at the red light. We represent the choice to swerve by assigning the first element of the vector with value of 1. Similar to the passenger variable, we represent the fact that three characters are crossing at a red light with
Swerve Man Woman Boy S enior Man Senior Woman I Passenger - Red Light
Figure 3-6: An example of vector representation of a choice in a Moral Machine
scenario
3.4
Conclusion
I used this chapter to thoroughly describe the salient features of Moral Machine
that are relevant to this work, which is exploration of cognitive mechanism in moral
learning. In Chapter 4 and Chapter 5, we will use the vector representation of scenario
as a basis to build cognitive models of decision making by Moral Machine respondents.
Although I limited the discussions to aspects that are relevant to this work, Moral
Machine is a rich and sophisticated web platform with many aspects that we did not
explore here. For example, it has a section in which visitors can design and submit
their own scenarios and a section in which visitors can come together to engage in a
discussion about the dilemma posed by a user-generated scenarios. These aspects of
Chapter 4
A Computational Model of Moral
Learning
Moral aptitude is the capacity to know what is right and wrong in a moral dilemma. While some aspects of the moral aptitude may be innate in our nature, it is also learned through examples and shaped by our experiences. However, moral aptitude also can't be explained by our past experiences alone because developmental studies show that even infants exhibit some capacity for moral aptitude. What intuitions can we employ from what we know about human moral learning to build an Al system that can rapidly learn from limited number of examples?
Here, we study two mechanisms that enable the human mind to rapidly infer moral values of others and express them through hierarchical Bayesian modeling framework. Employing these mechanisms, we propose a Bayesian model of moral judgment to characterize human judgments in Moral Machine scenarios and demonstrate the ben-efits of these mechanisms by testing the model's capacity to learn using data from Moral Machine.
In Section 4.1, I briefly explain the background of the challenge posed by moral learning. This section also includes an overview of the recent framework introduced in cognitive psychology literature that inspired this work. In Section 3.2, I discuss the details of the Hierarchical Moral Principles model, which is followed by Section 4.3 where we evaluate the model's predictive performance against various benchmarks.
Finally, I conclude this chapter in Section 4.4 with a brief discussion about the limi-tations of our approach and potential future extensions.
This chapter is based on a work to be published in the Proceedings of First Annual
AAAI/ACM Conference on Artificial Intelligence, Ethics, and Society.
4.1
Background
Fundamental to the basic concept of morality is system of measuring trade-offs in welfare of individuals in the consequences of our decisions in moral dilemmas. Study of moral decision making in young children suggests that children at an early age can base their decisions by weighing the trade-off of utilities of other individuals
[46, 16, 32, 33].
While certain aspects of human morality may be innate to our nature, evidence points to substantial reliance on learning as a mean to acquire moral aptitude [561. We know this to be true because how we weigh the trade-offs is shaped to a large
extent by society and culture in which we are raised [5, 35, 391.
What is remarkable about human moral aptitude is that the despite the infinite variations dilemmas we face wherein the individuals involved and degrees of harm may differ in every circumstance, we are able to aptly weigh the trade-offs of those involved to make an ethically sound decision. Putting aside minority of individuals who are psychologically impaired, the vast majority of individuals are morally apt, and even those whose actions are inconsistent with their own moral compass know that their actions violate ethical standards, which triggers feeling of guilt and shame. However, how does the human mind learn to make ethical judgments from limited amount of experience? In building autonomous systems such as self-driving cars, what insights about the human mind and the way in which it learns inform us about building ethical AI agent with human-like learning capacity?
Our understanding of moral learning draws on an analogy to the problem of learn-ing abstract knowledge in other domains of human intelligence such as llearn-inguistic gram-mar or morphological rules. Our mind is capable to making powerful generalization
guided by our capacity for abstraction, building abstract structured knowledge, which enable us to learn beyond our limited experience. The power of abstraction in aiding our learning has been described as "the blessings of abstraction" [79]. This powerful mechanism also extends to our capacity to weigh the trade-offs in moral judgment through abstract representations of people and situations, making judgments across multiple variations of moral dilemma tractable based on limited past experiences
[55, 57].
How one weighs the abstract concepts to make moral judgments can vary widely from one culture to another. Studies by anthropologists have shown that societies across different regions and time periods hold widely divergent views about what
actions are ethical [36, 39, 5]. For example, certain societies strongly emphasize
respect for the elderly while others focus on protecting the young. These views in a society are what we refer to as the society's group norms. Every individual, as a member of society, has shared views with other members of the society based on shared collective experience; as a result, we are able to infer preferences of an individuals based on the ethnic, cultural, and religious information [41, 20]. While judgments based on demographic attributes such as these are commonly called "stereotypes," they can be a powerful mechanism that aides in inferring the preferences of another individual [51, 8]. We call this mechanism society-individual dynamic throughout the rest of this work.
Knowing what we know about how abstraction and society-individual dynamics contribute to learning moral values. How can we formalize these mechanisms such that they can be expressed as parts of a computational model of moral learning? A recent work from the cognitive psychology literature provides a framework to model the dynamics of moral learning by agents through interactions with other agents in their environment [45]. This framework characterizes ethical decisions as utility maximizing choice over a set of outcomes whose values are computed from weights people place on abstract moral concepts such as "kin" or "reciprocal relationship." In addition, given the complex dynamics of interactions between individuals in a group, the framework provides an approach to model how an individual's moral preferences,
and the actions resulting from them, lead to a development of the group's shared moral principles (i.e. group norms) through hierarchical Bayesian modeling framework.
In this work, we explore an application of the framework introduced in [45] to study the two mechanisms of moral learning, abstraction and society-individual
dy-namics, using real-world human ethical decisions in Moral Machine scenarios. We
characterize moral judgment as a net utility maximizing decision over a function that computes trade-offs of values in the choices of Moral Machine scenarios, and these values are computed via the weights that people place along abstract dimensions of the scenarios. Furthermore, we represent individual Moral Machine respondents as members of group defined by country. Exploiting the hierarchical structure of re-spondents and countries, we show that hierarchical Bayesian model [281 is a powerful modeling methodology to characterize rapid moral learning from sparse and noisy data.
4.2
Hierarchical Moral Principle Model
We introduce hierarchical moral principle model (HMPM), which is an instance of hierarchical Bayesion model that incorporates the two mechanisms in moral learning
described above. HMPM describes how a moral agent arrives at a decision in a
binary-choice moral dilemma such as those depicted in Moral Machine scenario. Our aim is to model how Moral Machine respondents arrive at their decisions based on the values that they place on abstract dimensions of moral dilemma. For instance, when a respondent chooses to save a female doctor in a scenario over an adult male, this decision is in part due to the value that the respondent places on the abstract concept of Medical, a rare and valuable concept in society associated with improvement of social welfare. The abstract concept of Female gender would also be a factor in his or her decision.
4.2.1
Feature Abstraction
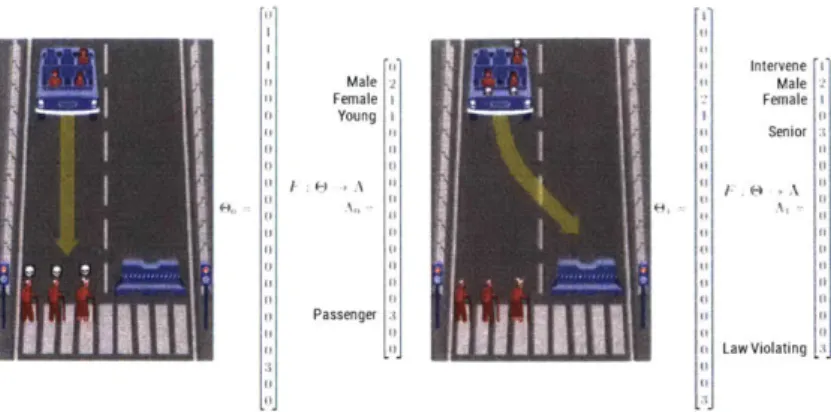
In Moral Machine, twenty characters share many abstract features such as Female,
Senior, and Non-human. Hence, the original character vector
E8
can be decomposedinto a new vector in the abstract feature space Ay C ND where D < K via feature
mapping F :
E
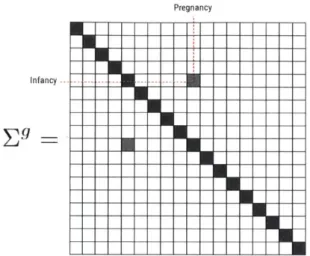
- A. In this work, we use a linear mapping F(E) = AE where A isa 18 x 24 binary matrix shown in Figure 4-1.
Intervene Male Female Young Senior Infancy Pregnancy Large Fit Working Medical Homeless Criminal Human Animal Passenger Law Abiding Law Violating
Figure 4-1: An example of a binary matrix A that decomposes the characters in Moral Machine into abstract features. Black squares indicate the presence of abstract features in the characters.
Figure 4-2 demonstrates as an example of how the original vectors in the Moral
Machine character space
E
is mapped on to a new state vector in the abstract featurespace A.
Critics of our approach may point out that Moral Machine characters are already abstractions of people in the real-world and the scenarios are already simplifications of true moral dilemmas in the road. However, given that our goal is to demonstrate contribution of abstraction to moral learning, deeper levels of abstraction of Moral Machine characters sufficiently serves this goal. Moreover, we do not make the claim that the feature abstraction shown in Figure 4-1 is the definitive feature mapping that best describes the cognitive processing of respondents when they observe the Moral
t Intervene I Male 24 Male2 Female i Female i Young r It
~Senior
: Passenger ;111 to (I Law ViolatingFigure 4-2: Vector representation of abstract features of a scenario choice.
Machine characters.
4.2.2
Utility Calculus
We express the trade-offs of choices in Moral Machine as a quantitative measure of net utility, which we define as a weighted linear combination of the number of abstract features present in Moral Machine scenario. To formalize, utility of choice Y = y is
u(6y) = W T F(OY) (4.1)
We call the weights along the D abstract dimensions w E- R Dmoaprnils
These weights represent how respondent values abstract features such as Young, Se-nior, or Medical to compute utility values of the choices in scenarios.
After computing the utility values of the choices to stay Y = 0 and to swerve
Y = 1, respondent's decision to swerve is seen as probabilistic outcome based on the
sigmoid function of net utility of the two choices U(6):
P(Y = 110) = 1(4.2)
1+ e-U(6)
where the net utility is defined by