AI Attack Planning for Emulated Networks
by
Bryn Marie Reinstadler
B.A. Chemistry, Williams College, 2015
M.Phil. Computational Biology & Chemistry, University of Cambridge, 2017 SUBMITTED TO THE DEPARTMENT OF ELECTRICAL ENGINEERING
AND COMPUTER SCIENCE IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF
MASTER OF SCIENCE AT THE
MASSACHUSETTS INSTITUTE OF TECHNOLOGY FEBRUARY 2021
©2021 Massachusetts Institute of Technology. All rights reserved. Author:
Department of Electrical Engineering and Computer Science January 27, 2021 Certified by:
Una-May O’Reilly Principal Research Scientist of Computer Science & Artificial Intelligence Lab Thesis Supervisor Accepted by:
Leslie A. Kolodziejski Professor of Electrical Engineering and Computer Science Chair, Department Committee on Graduate Students
AI Attack Planning for Emulated Networks
by
Bryn Marie Reinstadler
Submitted to the Department of Electrical Engineering and Computer Science on January 27, 2021 in Partial Fulfillment of the Requirements for the Degree of
Master of Science in Electrical Engineering and Computer Science ABSTRACT
In recent decades, cybersecurity has become one of the most pressing problems facing the private and public sectors alike. Cybersecurity threats are pervasive but extremely difficult to defend against, given the constantly changing vulnerability sur-faces of ever-evolving networks. There has been an increasing drive for automated cyber attacking or red teaming, which allows cyberdefenders to build better discov-ery and response workflows. The last few years has seen a rise in availability of structured threat data for cybersecurity, which has made possible the use of new techniques for automated red teaming. This thesis proposes the use of traditional artificial intelligence (AI) planning with domain-specific adaptations for solving this cybersecurity automation problem. Our development of two successful AI planning systems for automated red teaming, ClassAttack and ConAttack, demonstrate the utility of our approach.
ClassAttack consists of a classical planner which constructs static, executable attack scenarios that can be run on an emulated network. An extra degree of com-plexity but also realism is available in ConAttack, a contingent planner that inter-leaves planning and execution, to better simulate the attack of a real red teamer in real time. Both systems utilize a complex knowledge base which was engineered specifically for this cybersecurity application. These two systems and the knowledge engineering required to build them represent a significant and novel effort in the cybersecurity space.
Thesis Supervisor: Una-May O’Reilly
Acknowledgements
This thesis work was completed with the support and encouragement of many people. I would first like to thank my supervisor, Dr Una-May O’Reilly, for her support through the last year. Her encouragement of my curiosity and exploration allowed this project to blossom into what it is today.
A great deal of gratitude also due to my sponsors at SimSpace, whose resources and expertise in cybersecurity were invaluable to this project. Their time and energies devoted to helping me learn more about the field were instrumental in bringing this project to its completion. Special thanks are due to Dr Tom Klemas, who spearheaded the effort on the SimSpace side and was a constant champion for this work.
I would also like to thank the rest of the Any-Scale Learning For All (ALFA) group, especially Dr Erik Hemberg, for their support and insights on this project and others during my time at MIT.
Finally, I could not have completed this dissertation without the support and love of my family, my friends, and my partner.
Contents
1 Introduction 7
1.1 Emulated Networks for Cybersecurity Research . . . 9
1.2 Planning for Cybersecurity . . . 10
1.2.1 Planning paradigms . . . 12
1.2.2 Implementation choices . . . 14
1.3 Overview . . . 16
2 Offline Classical Planning 19 2.1 Design elements of an automated red agent . . . 20
2.2 The classical planning paradigm . . . 21
2.3 Knowledge engineering: Bridging formalism & application . . . 23
2.4 The design of ClassAttack . . . 27
2.4.1 Modular design elements for ClassAttack . . . 28
2.4.2 The Knowledge Base . . . 29
2.4.3 The Agent Module . . . 31
2.4.4 The Inference Engine . . . 34
2.4.5 Assembling an executable plan . . . 37
2.4.6 Additional practical features . . . 37
2.5 Using ClassAttack: A brief, practical overview . . . 39
2.5.1 Goals . . . 40
2.5.2 Initial state . . . 41
2.5.3 Skill level . . . 41
2.5.4 Personality . . . 41
2.5.5 Search algorithms . . . 42
2.5.6 Other planner configuration options . . . 43
2.6 Running ClassAttack on an emulated network . . . 44
3 Online Contingent Planning 46 3.1 Design elements of an extended attack planner . . . 47
3.2 The contingent planning paradigm . . . 49
3.3 Solving the contingent planning problem . . . 52
3.4 ConAttack: An online, contingent planner . . . 55
3.4.1 Bringing ConAttack online . . . 55
3.4.2 Action adaptations . . . 61
3.4.3 Parameter adaptations . . . 62
3.4.4 Goal adaptations . . . 65
3.5 Using ConAttack: A brief, practical overview . . . 67 3.5.1 Goals . . . 69 3.5.2 Initial state . . . 70 3.5.3 Skill level . . . 70 3.5.4 Personality . . . 71 3.5.5 Search algorithms . . . 72
3.5.6 Other planner configuration options . . . 72
3.6 Running ConAttack on an emulated network . . . 73
4 Related Work and Analysis 75 4.1 AI Planners . . . 75
4.1.1 Classical planners . . . 75
4.1.2 Contingent planners . . . 76
4.2 Online planning . . . 77
4.3 Software for Automated Red Teaming . . . 77
4.3.1 Open-source Automated Red Teaming Software . . . 78
4.3.2 Commercial Vendors for ART software . . . 79
5 Conclusion & Future Work 81 A Appendix: Knowledge Base Facts 88 B Appendix: Knowledge Base Actions 99
List of Tables
1 A brief, simplified overview of several subareas in planning. . . 142 Parameters for a classical planning problem . . . 21
3 CRAFT TTPs . . . 25
4 Parameters for a contingent planning problem . . . 51
5 A brief, simplified overview of several subareas in planning. . . 75
List of Figures
1 Schematic of ClassAttack . . . 172 Schematic of ConAttack . . . 18
3 Design Schema of the Red Agent . . . 33
5 Combining code fragments into a plan . . . 44
6 Schematic of action and parameter adaptation . . . 53
7 Parameter adaptation: choosing a world state . . . 54
8 Parameter adaptation: changing a world state . . . 55
9 Review: combining code fragments into a plan . . . 57
1
Introduction
The international adoption of TCP/IP protocols in the 1980s marked the beginning of a new era of connected computing, where networks of computers could work together and communicate with one another over long distances: the beginnings of the Internet. However, with this newfound capability came newfound vulnerability. Within a few years, the first cyber attack was released on the internet, with innocent intentions but with disastrous consequences.
In 1988, Robert Morris, then a graduate student at Cornell University, had a sim-ple question: could he put a program on every computer connected to the internet?[1] He developed a program that would trawl through the internet, finding other com-puters and installing itself on those comcom-puters as long as it wasn’t already there. But there was a problem; he worried that some systems administrators would attempt to frustrate his program by erroneously reporting back to the program that it was already installed. So in an effort to bypass this potential issue, he made the pro-gram install itself 14% of the time, regardless of the infection state of the machine. This simple implementation choice transformed a relatively harmless program into a raging attack that multiplied on machines, rendering many completely unusable. Today, this is known as a Denial of Service attack (DoS). Despite the innocence of the programmer, Morris’ program, sometimes called “Morris’ worm," exposed the nascent security dangers of the internet.[1]
Today, these security dangers are still present and ever-growing. As networks grow increasingly more complex, their vulnerability surfaces grow as well. Security flaws in these networks leave vulnerable people and information at risk, as bad actors
can target cyber assets to gain information, to deny service, or to perpetrate other harm. As a result of this growth in complexity, there has been massive growth in the field of cybersecurity, which aims to protect cyber resources and assets from potential attack. These attacks that specifically target cyber resources are known as “cyberattacks".
However, stopping cyberattacks is non-trivial. Cyberattackers utilise a huge and growing number of techniques.[2] Malicious software, ranging from worms and Trojan horses to viruses, may be installed on remote machines. They may be passive, simply monitoring networks, or active, infiltrating networks to gather information, or even disable or destroy. Some may simply allow the cyberattacker direct access to the machine, allowing them to do whatever they want within the confines of the network itself. Making the job even more difficult is the fact that information on how to perform these types of attacks is freely available on the Internet for those who wish to search for it. So the cyberattackers and the cyberdefenders end up in an arms race, each learning new techniques to stymie the other in an endless cycle perpetuated by buggy software releases, new operating systems, and other technological advances that feed in a new stream of techniques and vantage points.
Today’s cyberdefenders are operating with more knowledge and tools than ever, but the security landscape is still difficult, with cybercrime costing the banking industry alone millions of dollars each year.[3] As such, there has been increasing interest in finding better ways to get ahead in the arms race.
One particular method that has been used to great effect is known as red teaming, where a team of trained experts will try to infiltrate and attack a network in order
to test the detection and response capabilities of those defending the network (also called blue teamers). Red teaming is traditionally performed with human experts.
However, the cybersecurity industry has become increasingly interested in auto-mated red teaming, which allows companies to hire fewer expensive cyberexperts as well as allowing them to run training drills and exercises on their networks whenever they like, rather than depending on a human’s schedule. Automated red teaming has proven difficult, due in no small part to the fact that structured knowledge about cyber attacks has, up until the last few years, been scarce. Without structured knowledge on the type and severity of attacks that are in play on the world stage, it is difficult to build automated tools that can cover the breadth of techniques used by actual cyberattackers in the wild.
The advent of structured threat information about the habits and tools of cyber attackers has allowed the red teaming process to become more automated than ever. The most popular framework for reporting threat data is the MITRE ATT&CK framework, or MITRE ATT&CK Matrix, which reports on all levels of threat in-formation from abstract goals to specific attack strategies, from tools used to the software versions that they target.[2]
1.1
Emulated Networks for Cybersecurity Research
A key component to building an automated red teaming system is a partnership with SimSpace, a local cybersecurity company that furnishes cyber ranges, or emulated networks, for customers. Cyber ranges give a client means to evaluate the readiness and training of their cyber security personnel, by creating relevant, high-fidelity
network configurations plus security tools and practices that can be used in training exercises. These ranges may be based off of real client networks, and include routers, firewalls, Point-of-Service machines, and more, so that networks can be evaluated in a safe and secure fashion. The machines are emulated using VMs with full operating systems installed and running, all connected so as to emulate an actual enterprise network. To add even more realism, emulated users on the range check email, browse the web, store files and send each other information over the intranet.
The cyber range provided by SimSpace provides a unique opportunity for using automated red teaming in an extremely realistic scenario without the risk of actually infiltrating or damaging any real network, or potentially accidentally participating in illegal activity.
A further crucial contribution from SimSpace is that of their CRAFT software (Cyber Range Attacks For Training). CRAFT is a software package that contains modules which perpetrate atomic attacks, as derived from the MITRE ATT&CK Matrix, on the range. These atomic attacks, sometimes called tactics, techniques and procedures (TTPs), or just procedures, will form the basis of our automated red teamer or attack planner, as discussed below. Details on the CRAFT system will be discussed in Sections 2 and 3. At present, CRAFT is used by expert human red team members to manually build attack scenarios which can then be run in the range.
1.2
Planning for Cybersecurity
Our work seeks to propose an answer to the question of how best to build an auto-mated red teaming system. Our goals are to build a system that has domain-specific
knowledge about cybersecurity, that can leverage threats against a cyber-range in a way similar to how a human would behave. We propose to use an AI planning approach to meet these goals. The new set of structured threat information avail-able from MITRE, paired with implementations of known threats from SimSpace’s CRAFT, is what will allow us to build an automated red team, or red agent.
There is a clear isomorphism between the automated attack strategy problem and the classic artificial intelligence (AI) planning problem. Planning is a long-standing area of research within AI that is concerned with finding and executing strategies, or sequences of actions; its foundations date back to John McCarthy, who coined the term Artificial Intelligence.[4] The solutions to planning problems are complex and must be discovered and optimized in a multidimensional problem space. These solutions are then executed by intelligent agents.[5]
Many industry research teams use AI planning in their efforts, including their cy-bersecurity efforts. IBM has an entire research division on AI planning that adapts AI planning to various applications areas, including cybersecurity. Their AI plan-ning division has created many planners, include such projects as Planner4J, a gen-eralizable planner resource, and DOCIT (Dynamic optimization of city intermodal transportation).[6][7] Google’s Deep Planning Network, PlaNet, uses AI planning to reduce the need for training.[8] The Hubble Space Telescope is another example of AI planning being used for corporate, rather than purely academic, applications.[9]
In this project, we chose to use a planning approach to solve the problem of automated attack planning for a variety of reasons. Traditional AI Planning has several advantages over other methods, such as reinforcement learning, for finding
solutions in a complex multidimensional space:[10][11]
• No training data required: Unlike deep learning, planning does not require massive amounts of training data.
• Adaptability: Even though humans are not in the loop, the planner can still dynamically re-plan when encountering blockages, representing a significant advantage over sequentially-designed automatic attacks.
• Computational cost: Because of the computational efficiency of a planner that does not require training on large datasets, the time to solution can be quite low.
• Rapid Prototyping: Because planning is well-suited for modular design, de-veloping a good, modular planner is relatively straightforward and allows for rapid prototyping of different algorithms, cost structures, etc.
These factors influenced our decision to use a planning approach for building the automated red team agent. However, planning is a large and still-active field; there are many design and implementation choices that must be made when designing a planner.
1.2.1 Planning paradigms
Planning is a model-based approach for programming autonomous behavior. Plan-ners in general utilise a simple state model, which may be extended as desired and required for the problem statement.[12] A general classical planning problem is
pa-space. Then, if an initial state and goal state are defined, the planning problem is formulated simply as the ordered list of actions that, when applied to the initial state, achieves the goal state (if any such ordered list exists).
This basic paradigm can be extended to work in a variety of cases, when the designer makes choices about whether the action model will be deterministic or non-deterministic, whether the model will explicitly describe the temporal component of the plan, or many other features.[13] This feature space has been well-explored and has given rise to a variety of subareas within planning.
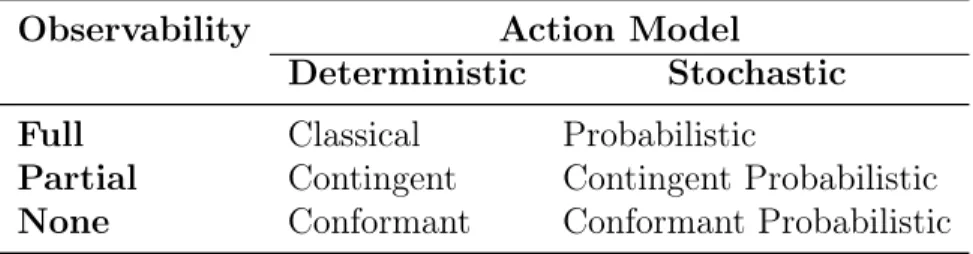
The most common subarea is that of classical planning, which assumes a deter-ministic action model and full knowledge of the environment in which the planning is to take place. However, in the real world, it is very unlikely that full information is known about a situation in advance. For example, the Hubble Telescope needed to be able to adapt to circumstances in space that could not be predicted with great accuracy ahead of time by the human teams working from Earth.[9] The nature of its work was inherently exploratory and therefore uncertain. Thus, of particular inter-est to the planning community has been the problem of planning under uncertainty, where some aspects of the problem cannot be known in advance. In particular, two important dimensions along which planners can differ are action model and the observability of the environment (Table 1, reproduced from [14]).
The action model axis refers to whether the action model is deterministic or stochastic (also called nondeterministic). A deterministic action model covers those actions which, when applied to state, have a deterministic outcome. A nondeter-ministic or stochastic action model covers those actions which may have a stochastic
Table 1: A brief, simplified overview of several subareas in planning.
Observability Action Model
Deterministic Stochastic
Full Classical Probabilistic
Partial Contingent Contingent Probabilistic
None Conformant Conformant Probabilistic
procedure, such as rolling a die or flipping a coin. These stochastic procedures are such that their outcome cannot be known in advance.
The observability axis refers to the availability of a full description of the state of the environment. Classical planners operate under an assumption of full observ-ability, which means that all relevant facts about the environment are known to the planner in advance. However, planners may operate under the more realistic partial observability assumption, where it is assumed that part but not all of the relevant state is known in advance and sensing is possible, or may operate under an assumption of no observability, where no sensing actions and no prior information are available to the planner.
1.2.2 Implementation choices
In our case, we are operating under a deterministic action model where each action has at most one outcome state for every state, as intuitively makes sense for this application area. Because we know that we can at the very least perform sensing actions in the cyber range environment, we can operate with either full or partial observability.
planner, ClassAttack, which assumes full observability of the relevant parts of the cyber range. This development fulfilled part of the goal of this work, which is to build an automated red teamer; that is, an automated cyberattacker that doesn’t need a human to tell it what to do to achieve its goals.
However, another equally important part of this work was to build a system that not only achieved its goals but did so in a manner similar to that of a human. To reach this goal, a different paradigm is required. Classical planning requires full observability of the environment and deterministic actions, which means that plans can be deterministically generated in advance with full knowledge of what will happen during execution. This set of assumptions gives us some very convenient guarantees; classical planners can be made to find optimal solutions in the search space, depending on the types of search algorithms used.
This fact has implications for the realism of the executed attacks. A human cyberattacker will rarely, if ever, start to levy an attack against a network with full knowledge of the internals. It is therefore much more realistic to allow the planning system to operate with only partial observability of the environment, similar to what a human attacker would experience. This is not realism for realism’s sake; the partial observability of the environment will lead to different types of plans as the attacker will have to adapt to circumstances it could not have known about ahead of time. Whereas the classical planner could be made to work offline, this variety of what is called contingent planning will need to work online, interleaving planning and execution, making observations at each stage to know where to move next. Therefore, we have also developed a contingent planner, ConAttack.
1.3
Overview
My work contributes two systems that use the modular actions of CRAFT to build complete, cohesive cyberattacks without a human in the loop; given only an abstract goal for the outcome and some other meta-level configuration, the systems plan and execute attack strategies from start to finish, reporting on various heuristics and success throughout. Both systems also utilize a custom-built knowledge base full of domain-specific information about the emulated networks and the abilities and actions available to the agents.
This work showcases two such systems. One system, ClassAttack, consists of a classical planner that assumes full observability of the cyber range (Figure 1). The ClassAttack system is discussed at length in Section 2. The other, ConAttack, consists of a more sophisticated contingent planner that only assumes partial observ-ability of the cyber range environment (Figure 2). This system is covered in Section 3. These two planners are both useful to the end user under different circumstances, and each represents a contribution to the nascent field of AI attack planning.
In Section 4, we discuss and compare related work in the AI attack planning space. Conclusions and future work are covered in Section 5.
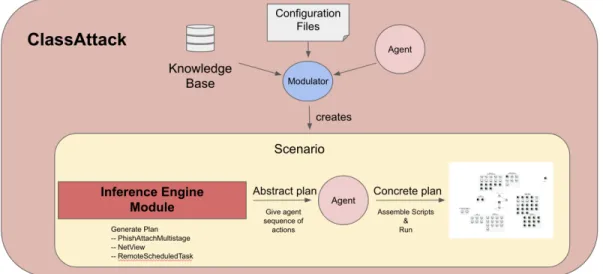
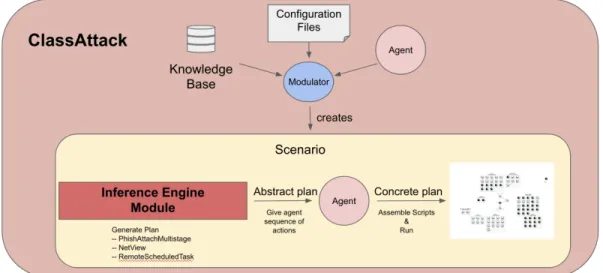
Figure 1: Schematic of ClassAttack. The knowledge base, configuration files, and agent are all combined through the use of the modulator to create a Scenario. Within this scenario, the inference engine creates an abstract plan which is fed to the agent, who then compiles a static, executable scenario to be run on the emulated network.
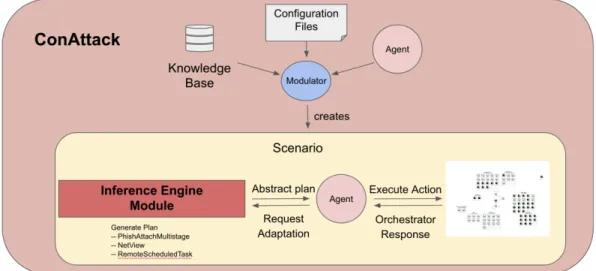
Figure 2: Schematic of ConAttack. The knowledge base, configuration files, and agent are all combined through the use of the modulator to create a Scenario. Within this scenario, the inference engine creates an abstract plan which is fed to the agent, who then runs the plan, one action at a time, receiving feedback and observations from the emulated network throughout. These observations are fed back into the inference engine module for re-planning and adaptability.
2
Offline Classical Planning
The ClassAttack system consists of a classical planner that assumes full observability of the cyber range. This choice guarantees that we will be able to find optimal and complete solutions in polynomial time, relative to the size of the state space, using traditional and familiar search techniques.[15] In this section, we will explore the implementation choices made when developing ClassAttack for this specific cyberse-curity application.
First, we will cover the required design elements for the application area. These required design elements lead us to the natural choice of a planning solution, and so the formalism for classical planning problem is laid out. Then, we will explain how we have mapped the formalism into a concrete realization using atomic actions drawn from our understanding of cybersecurity actions that a red teamer may make; this mapping from formalism to realism, sometimes called “knowledge engineering," is a crucial contribution of this work.
Finally, we will discuss the actual implementation considerations of ClassAttack and how it combines formalism and domain knowledge to bring together a classical planner with some limited re-planning capabilities that can levy automated cyberat-tacks on a range without a human in the loop. Finally, practical information about use of the software and agent performance will be given.
2.1
Design elements of an automated red agent
When designing a solution for the problem of building an automated cyber attacker, or automated red teamer, there were several aspects that we knew would be core to its function:
• Key objective: Build a system that would have the ability to formulate and execute an attack without a human in the loop.
• The system should leverage the CRAFT module which contains atomic, pro-grammatic options for executing attacks, and should be implemented in the SimSpace cyber range.
• The system should be able to be moved around to different cyber ranges, and should not need any re-training upon moving.
• Ideally, the system will need little upkeep except for modification to remain current with the development of the CRAFT internal system.
With these constraints in mind, it was clear that a classical planning approach would give a good solution; and thus, ClassAttack was conceived. While the classical planning paradigm has its limitations, it fulfills the brief above. One limitation in particular, the lack of online adaptation, is addressed and solved in Section 3 with the development of the follow-on product, ConAttack.
2.2
The classical planning paradigm
The classical planning problem can be formalized as a finite, deterministic, fully-observable state-transition model characterized by Σ = (S, A, C), and the classical planning problem P = (Σ, s0, G) as given in Table 2.
Table 2: Parameters for a classical planning problem Object Description
S A finite, discrete state space
A A finite set of actions. Each action a ∈ A is a function
map-ping states to other states
C(a) A cost function that maps actions to a scalar cost
s0 A known initial state
G A non-empty set of goal states, G ⊆ S
Given a classical planning problem P = (Σ, s0, G), a solution can be found by
minimizing the value of the expression Σn
i=1C(ai) where s0 is the initial state, sn ∈
G, and the result of applying a0 through an to s0 is sn. That is, the solution to
the classical planning problem is a set of a minimum-cost actions to be applied sequentially to the initial state, resulting in a state that satisfies the goal.[14] Note that the cost function does not depend on the state that the action is applied to; rather, the cost per action is modelled independently of the current state. Other classical planners may not make this simplifying assumptions.
Any finite state-transition model can be easily interpreted as a graph structure. Here, there is a straightforward isomorphism between states and nodes, and between actions and edges. Each of the finitely-many states can be viewed as a node in a state-space graph. Each of the finitely-many actions can be viewed as edges a ∈ A
that join together any two states s, s0 ∈ S such that a(s) = s0.
We are therefore left with a choice of representation for state-nodes and action-edges. Here, we will use a popular representation based on STRIPS (STanford Re-search Institute Problem Solver).[16] STRIPS, first developed by Fikes and Nilsson in the 1990s, utilizes graph analysis to find efficient classical plans with proven opti-mality, and it has maintained popularity as a simple, action-based planner that finds plans based on the pre- and post-conditions assigned to each action, often in the form of atomic variables that reflect the state space. Today, the name STRIPS more com-monly refers to the formal language of the planner, and that is the sense in which we refer to STRIPS. We use its formal definition of preconditions and effects to help us represent the planning problem so that we can use classical search techniques to find solutions. In ClassAttack, we will characterize each state as a collection of variables (features) and their Boolean values. An action will be characterized by preconditions, a list of required feature values that must be present in a state before that action can be applied, and effects, a list of feature values that will be present after the action is applied to a valid state. Actions will have several other attributes as well, which will be covered in more detail later; but these are the attributes required for a minimum viable planner.
By treating the planning problem, with its states and actions, as a graph traversal problem, where edges are actions that bring one from a valid start state to a new state, we can use efficient graph search algorithms with proven optimality bounds to find effective plans.[17] We maintain a portfolio of several graph search algorithms, such as A search and Branch and Bound, which will allow the user to use different
types of algorithms in different situations, or even mix algorithms; this technique is known as algorithm portfolio design.[18]
2.3
Knowledge engineering: Bridging formalism &
applica-tion
A critical piece of building any planner is the knowledge engineering process, whereby relevant features of the world or environment are carefully chosen by the system de-signer to be included in the state features. These feature choices decide the scope and abilities of the final planner. Knowledge engineering also encompasses the decisions about action definitions, including deciding which feature values should be required preconditions or obvious effects for any given action.
In our case, the relevant actions to our planner were set out in advance by the team developing CRAFT. Our goals were several:
1. Understand the available actions. These actions are derived from Tactics, Techniques, and Procedures (TTPs), the specifications of which are available through the MITRE ATT&CK Matrix.[2]
2. Define the preconditions and effects for each of the atomic CRAFT TTPs, after consultation with red team experts at SimSpace.
3. Define the cost function C(a) as it relates to each action, based on consultation with red team experts at SimSpace.
4. Determine the information that will be required from the environment (fea-tures), and add that information to a fact repository that shall be maintained
in conjunction with the planner.
At the beginning of the project, we were provided with a set of TTPs available for use in ClassAttack. We have organized the available TTPs according to their Tactic subgroup heading as in the MITRE ATT&CK Matrix [2] (See Table 3).
Notably, there is uneven coverage of the Techniques and Procedures within the Tactics. Some Tactics, such as Defense Evasion, do not have any accompanying Techniques and Procedures. Other Tactics, such as Initial Access, have several op-tions to use to achieve a similar result. These opop-tions within a Tactic allow us the flexibility to try different Techniques and Procedures to try to gain initial access, and allow us to provide true adaptability with the AI planner.
Using these TTPs, 29 actions were designed to maximize planner flexibility. The preconditions and effects of each action were determined by direct examination of the source code from CRAFT, which is not reproduced here due to its proprietary nature. Each action follows the pattern shown by the HashCrack action shown in Listing 1.
Here, it can be seen that each action comes with a name and a set of information relating to the STRIPS formulation: a set of preconditions, effects, and costs. Some other information is also associated with each action, but those have been omitted here for clarity. Further action attributes will be discussed in the next section.
The HashCrack action above has one feature each in preconditions and effects. The action requires that unpriv_session_uuid be true, which means that it requires access to a session UUID (which does not need privileged access) in order to perform.
Table 3: CRAFT TTPs
Tactic Name Notes
Collection gatherFiles Gather multiple files in single dir
Command and Control
- Not yet implemented.
Credential Access
mimikatzDumpCreds Dumps credentials using mimikatz tooling
hashCrack Crack (obtain) password with hash
credsInFile Finds credentials for user in a given file
credsInFileFirefox Finds credentials for user in a Firefox file
Defense Evasion
- Not yet implemented.
Discovery systemInfo Gathers various system information
PortScan Scans ports for activity (finds useful ports)
user_enumeration Enumerates all users on a machine
remoteSystems Gathers information on remote hosts
netView Uses netview, an automation and network
man-agement tool, to scrape information
Execution execCLICommand Executes command on CLI
execPSFile Executes a given ps file
simpleShell Opens a Windows simpleShell
Exfiltration exfilOverC2 Exfiltrates files; 3 versions available
Impact - Not yet implemented.
Init. Access phishLinkSession Phish in an email attachment to open session
phishAttach Phish using an attachment
phishAttachSession Phish using an attachment
phishAttachMultistage Phish using an attachment
Lateral Movement
mimikatzPassTheHash Uses mimikatz tool to pass the hash
remoteScheduledTask Lateral movement using windows schtasks
Persistence logonScript Allows attacker to persist on machine by setting
a script to run on login/startup
persistTask Creates persistent reverse shell callback when
specific user logs in Privilege
Escalation
1 " HashCrack ": { 2 " name ": " HashCrack ", 3 " strips ": { 4 " preconditions ": { 5 " unpriv_session_uuid ": true 6 }, 7 " effects ": { 8 " t4_domain_admin_pass ": true 9 }, 10 " cost ": 1,
11 # ... omitted for clarity
12 },
13 # ... omitted for clarity 14 }
Listing 1 HashCrack action code fragment, showing the formal STRIPS language used to specify elements of the action.
Note that the domain of the features is {true, false} and not the set of all possible session UUIDs. This choice drastically simplifies the computation required in terms of state-space size, since the size of the search problem is exponential in the size of the feature domain. However, when it comes time to execute the plan, a real session UUID is required. To address this problem, we also created a fact repository, which stores either the actual value of a feature to be used in run-time, or stores a look-up command that finds the actual value at run-time. For example, the feature red_agent_port is represented in the fact repository as shown in Listing 2.
1 " name ": " red_agent_port ",
2 " cmd ": "ta. rangeLookup ({\" name \": red_agent_hostname }, \" Red - Team .
port \") ",
3 # ... omitted for clarity
Listing 2 red_agent_port fact code fragment, showing a partial specification for a fact from the fact repository.
At run-time, when the planner needs access to a red agent port, it finds that it should run a look-up command to find the red agent port name. Facts in the fact repository also contain other attributes which will be covered in the next session, as they are not as directly related to the knowledge engineering effort.
These two components, the action repository and the fact repository, provide the practical information required for the system to “know" about the application area and to execute that plan in the actual environment. However, it does not provide a way to actual solve for the required plan. In the next section, we will discuss the design of the entire planning, building on the knowledge engineering effort explored in this section.
2.4
The design of ClassAttack
In this section, we give a comprehensive survey of the design for the classical AI planner, ClassAttack. We begin with an overview of the different modules involved, then proceed to explore an in-depth analysis of the functioning of each module, including code snippets where necessary.
2.4.1 Modular design elements for ClassAttack
ClassAttack is comprised of several different modules that work together to build an offline plan using the classical planning paradigm:
1. The knowledge base contains information about the environment (the cyber range) necessary for the planner’s function. It has two submodules: the action repository which stores all relevant information about all possible actions, and the fact repository, which stores information needed by the planner at run-time such as ports, IP addresses, or names of users.
2. The agent module contains meta-level information for the planner. An agent is initialized from a personality input file with a goal, a personality, and a skill level. The personality and skill level determine the actions available to the agent and their weight (that is, the value of C(a) for each a ∈ A). The agent is given the final plan, in a graph-based format, to build an executable version on the range.
3. the inference engine uses the agent’s goal and actions, and builds a scenario using a scenario input file that contains the initial state and other meta-level information for the planner submodule, such as the type of search algorithm to be used. With this information, a planning problem is defined and then compiled into a search problem on the state space graph. The desired search algorithm is run and the resulting plan is stated in terms of edges (actions) from the start node (state).
Each of these modules is critical for the function of the planner. The user must supply a personality input file and a scenario input file, and from these, the problem is formulated, the plan discovered, and the executable created. In the next subsections, we will cover the functionality of each module in detail.
2.4.2 The Knowledge Base
The knowledge base contains information about the environment necessary for the planner’s function. As mentioned above, it consists of two main submodules: the action repository and the fact repository.
In Section 2.3, we showed a partial entry for the action repository; here in Listing 3, we will show the full entry for HashCrack used by ClassAttack.
It can be seen that in addition to the name, STRIPS information, and cost, there also exist a list of other relevant attributes (here, empty) as well as a skill level. These are meta-level information about the action that is used by the inference engine when building the scenario specifications to be fed to the planning submodule. The attributes list at present may contain the string “noisy" which has the effect of raising the action’s cost when the agent has a stealthy personality. Other personality types and attribute types, and their effects, may be added easily due to the list-type attribute format. 1 " HashCrack ": { 2 " name ": " HashCrack ", 3 " strips ": { 4 " preconditions ": { 5 " unpriv_session_uuid ": true
6 }, 7 " effects ": { 8 " t4_domain_admin_pass ": true 9 }, 10 " cost ": 1, 11 " attributes ": [] 12 }, 13 " skill_level ": 4.4 14 }
Listing 3 HashCrack action code fragment, showing a full specification for an action to be stored in the action repository.
The skill level attribute will be noted throughout the planner. In order to define the sophistication level of a plan, each action and each fact in the fact repository comes marked with a skill level related to the difficulty of performing that action or gaining access to that fact. The default skill level, indicating that a total novice could perform that action or gain access to that fact, is 1. Higher skill levels are given to more difficult actions or more difficult-to-attain facts.
For actions, the skill levels were obtained using SimSpace-internal metrics on the difficulty of performing actions in the MITRE ATT&CK Matrix. The full details of their sophistication rankings of different TTPs in the MITRE ATT&CK Matrix will not be shared; however, the skill level (or sophistication level) of each action, which may be composed of multiple TTPs, is given in Appendix B.
Facts also have a skill level attribute, called skill, which can be manually altered to with-hold information from the planning system so that it must be obtained
by completing an action (if it is to be obtained at all). Listing 4 shows the full specification for the red_agent_port fact.
1 {
2 " name ": " red_agent_port ",
3 " cmd ": "ta. rangeLookup ({\" name \": red_agent_hostname }, \" Red
-Team . port \") ", 4 " skill ": 1, 5 " precond ": [ 6 " red_agent_hostname " 7 ] 8 }
Listing 4 red_agent_port fact code fragment, showing a full specification for a fact from the fact repository.
The last attribute of a given fact is a list of dependencies. When a fact cmd contains a look-up command, it may rely on other pieces of information. For example, in this case, the look-up command to find the red agent port requires a red agent hostname as well. These dependencies are noted in a precond list that specifies what must be known in advance in order to make the look-up request. This knowledge is used later in the building of the executable plan.
2.4.3 The Agent Module
As mentioned above, the agent module contains more meta-level information for the planner. An agent is initialized from a personality input file with a goal, a personality, and a skill level. The personality and skill level determine the actions
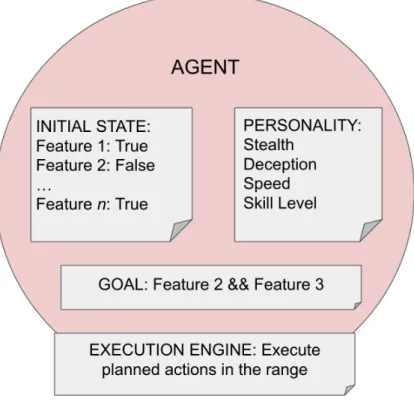
available to the agent and their weight (that is, the value of C(a) for each a ∈ A). The agent submodule may also be referred to as the CRAFT control agent, or CCA. Agents have several attributes (see Figure 3):
• They have a goal which consists of a preferred state for the cyber range to be in.
• They have an initial state which determines what information/range knowl-edge is available to the agent at the outset of the planning operation. The initial state consists of all the relevant features that have been defined by the configuration file; so each feature and its value are set in the initial state and passed to the agent as part of its attributes.
• They have a personality which puts weights on which actions are preferred or not preferred. Personalities comprise four separate traits: One, a skill level that indicates whether the agent is a novice (skill level == 1) or an expert (skill level == 10) or somewhere in between; two, speed, which is a mean amount of time that the agent takes to complete actions in minutes; three, stealth, which produces an adjustable for those actions with the noisy attribute; and four, deception, which is a probability between 0 and 1 that determines the likelihood that an agent will perform any “off-task" actions to distract or deceive any watching blue team members.
• Finally, agents also have an execution engine that allows them to write an executable script based on a plan received from the Inference Engine.
Figure 3: Design schema of the red agent. The agents are endowed with an initial world state, parameterized by different features; a personality, parameterized by stealth, deception, speed, and skill level; a goal; and an execution engine that allows the agent to execute the planned actions in the range.
These attributes allow the agent to be associated with those actions that are allowed; any actions with a skill level at or below the skill level of the agent are considered “legal" for use in that planning scenario. These agent actions are those atomic actions which are derived from CRAFT TTPs with pre- and post-conditions that specify their effect on the range.
2.4.4 The Inference Engine
The final functional module included in ClassAttack is the inference engine. The inference engine uses the agent’s goal and actions, and builds a scenario using a scenario input file that contains the initial state and other meta-level information for the planner submodule, such as the type of search algorithm to be used. With this information, a planning problem is defined and then compiled into a search problem on the state space graph. The desired search algorithm is run and the resulting plan is stated in terms of edges (actions) from the start node (state); this plan is passed to the agent to piece together the real code required to write the executable plan file. The inference engine comprises the actual classical planner itself, which is not domain-dependent. When a suitable-formed planning problem is handed to the plan-ner, it can and will build a plan; it does not require any special knowledge about the planning environment or features other than what it is given during initialization.
The planner itself has three main components: a component for generic graph path building, a component to define a planning problem and corresponding graph, and a component to run a search on a graph. We will cover each of these in detail to understand the exact working of the planner at this stage.
The generic graph path components are simple, and made of two separate Python classes: one for an Arrow (which is a directed edge), and one for a Path (which is either a node or a path followed by an arrow). These two types allow us to recursively define paths within a graph.
The component that allows us to define a planning domain and problem, and its corresponding search structure, is slightly more complex. A planning domain consists
of a set of actions, a set of features and their values, and a mapping of actions to their STRIPS representation (allowing us to access their preconditions and effects). This construction is isomorphic to the construction of Σ found in Section 2.2. The planning problem, isomorphic to P in Section 2.2 is then made up of the planning domain, the initial state, and the goal. The search problem (or graph problem) can then be defined using the planning problem.
Search problems (as part of the Search class) consist of a start state, a function that specifies whether a state is a goal state, a function that specifies reachability of state s0 from s using only one action, and an optional heuristic function. Two types
of search problems are available in ClassAttack: A forward search problem and a backward (or regression) search problem.
The forward search problem works by starting the search from the initial state and working forwards to find a goal state. The forward search problem operates in a way that is very intuitive, but unfortunately is often slower than the backwards or regression problem.
The backward search problem works by starting the search from a goal state and working backwards to find the initial state. This functionality requires a slightly different (“backwards") definition of a reachable state; in this problem, a state s is reachable from a state s0 if there exists an action that is applied to state s that will
result in s0. Further, the preconditions are constrained to be consistent with the goal
that needs to be achieved. This constraint leads the backwards problem to be much quicker than the forwards problem, in the general case.
search component. ClassAttack, like many classical planners, maintains a portfolio of different search algorithms that can be specified by the user depending on the use-case.[18] Specific details of implementation are left to the source code, but are all standard for these algorithms. The available algorithms and their justification for inclusion are given here:
• A∗: A simple, well-known algorithm with optimality guarantees in the presence
of a consistent and admissible heuristic function, A∗ is a great general-purpose
search algorithm and is therefore included in the algorithm portfolio.
• Multi-path pruning: This algorithm is an extension of A∗ that will continue
to provide paths even after the optimal path is found. This behavior is ideal when generating multiple contingency plans for an agent that may not know that a particular plan is guaranteed to succeed.
• Branch & Bound: Another well-known algorithm that limits the amount of search time by putting a bound on the total search depth; it is therefore useful for potentially large search problems such as are generated by the forward search problem.
• Iterative Deepening: An extension of Branch & Bound that continues to enlarge the bound when all paths up to the bound length have been explored and none reach the goal. This algorithm is also useful in cases of potentially large search spaces.
may allow for faster results. In practice, one of these search paradigms is then used to search the corresponding state graph (whether forward or backward) to produce a plan in the form of a Path through the graph. This plan is then passed back to the agent, who assembles an executable plan.
2.4.5 Assembling an executable plan
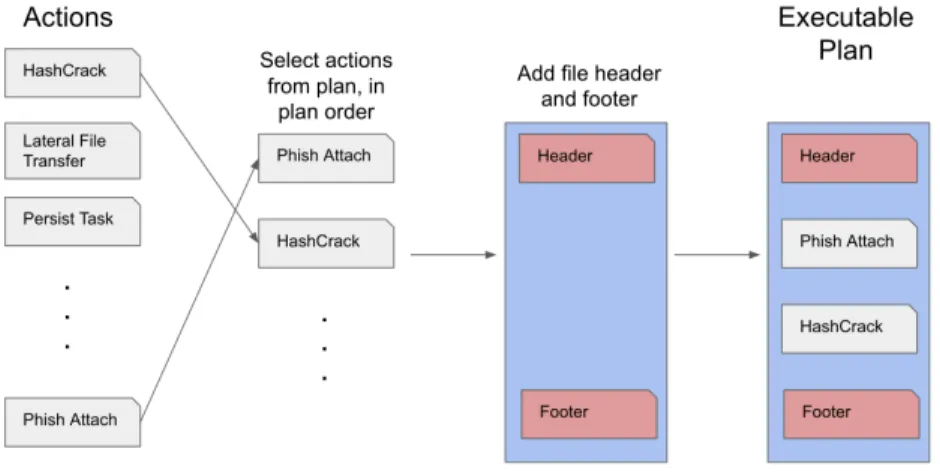
The assembly of an executable plan is done by the execution engine of the agent module. It receives a plan in the form of a Path from the classical planning module. The name of the output file has been specified by the user (or has been set to the default). A pre-written file header is outputted to the output file. This file header dynamically imports all CRAFT modules (TTPs and others) required in the running of a scenario plan. Then, for any variables which were set to be available in the initial state, the agent declares them recursively at the top of the file to ensure that the agent has access to these during run-time. Next, the agent uses the string of actions available in the plan to, one-by-one, append the relevant code snippets to the file. These code snippets are stored in the Knowledge Base; there is one code snippet for each action. Finally, a pre-written file footer is outputted to the output file which marks the end of the plan. This plan file can then be run using the CRAFT engine. A schematic of the full process can be observed in Figure 4.
2.4.6 Additional practical features
In addition to the base functionality outlined above, we created two additional pieces of functionality: one, goal adaptation, and two, minimal back-up planning.
Figure 4: A full schematic of ClassAttack. The knowledge base, configuration files, and agent are all combined through the use of the modulator to create a Scenario. Within this scenario, the inference engine creates an abstract plan which is fed to the agent, who then compiles a static, executable scenario to be run on the emulated network.
In the case of goal adaptation, true goal adaptation is a difficult problem that requires compilation of soft goals down to hard goals.[12] Therefore, we designed a much more constrained paradigm; if the agent cannot complete all subgoals in the goal using the actions available to it during the planning phase, the agent may check a user-specified list of negotiable subgoals that may be dropped from the main goal. The agent will drop the subgoals one at a time, in the order specified, until either it finds a valid plan that satisfies the current subset of the original goal, or it cannot find any valid plan that satisfies any of the subsets of the goal. This amount of goal adaptation allows ClassAttack to provide more flexibility in the design of scenarios. We also designed a method for minimal back-up planning. In the case where the
user specifies the multi-path pruning algorithm, the searcher may be used several times to output as many plans as exist that get the agent from the start state to a goal state. These plans are scored by the total cost of the actions required, which is printed to the top of the output file. Therefore, when multiple paths from start to goal exist, as many as desired (up to the total number possible) may be outputted and tried. While this is far from true contingency planning, it is a start at an ability to try multiple ways of achieving a goal.
2.5
Using ClassAttack: A brief, practical overview
To use the planner, first navigate to planner’s top-level directory, then follow the directions below.
Scenario configuration files are placed in the example_scenario_configs/ di-rectory. Some examples are present already. Listing 5 gives an example of a scenario config file, expert_mimikatz.yml.
The scenario consists of a goal (a set of states that the agent will try to attain), an initial state (set to empty to populate initial state with entire knowledge base), a skill level for the agent, a personality for the agent, and a variety of configuration options for the planner itself.
1 --- # expert agent goal of persistence + mimikatz binary session 2
3 goal : {" mimikatz_binary_uuid ": True , " persistence ": True }
4 initial_state : {} # an empty initial state will be populated with all knowledge base facts ; to limit to certain
factname ": True , " factname2 ": True } 6 skill_level : 10
7 personality : " personality_configs / stealthy . yml " 8 searcher : " IterativeDeepening "
9 forward : False # or True for forward planning ; but that 's slower 10 auto_run : False
11 output_file : " expert_out .py" 12 n_plans : 5
Listing 5 Scenario configuration file.
2.5.1 Goals
Goals are a set of atomic features that are either True (present) or False (absent) in the goal state of the agent; that is, the agent will try its best to execute a plan which creates a world where the goal is satisfied. If the goal is {"persistence": True} the agent will pursue a plan where the final state has the agent persisting on a remote machine.
There is a further option, goal_adapt, which allows the user to specify an or-dered list of subgoals (identical to the ones in the goal) which may be compromised on. For example, in the scenario above, the goal_adapt parameter could be set to ["persistence"], which would indicate to the agent that if a plan could not be made to satisfy the full goal, the agent could drop the persistence subgoal and try to make a new plan.
The action_repository.json file defines pre- and post-conditions which contain all of the features available to the agents at present. To add a new feature to the
planner, it must be added to at least one action as a pre- or post-condition to have an effect on the plans of the agent. Any feature that is a pre- or post-condition of any action can be used as a feature in the goal.
2.5.2 Initial state
Some features are only pre-conditions, and not post-conditions. These include cer-tain file paths, names of remote hosts, etc. Crucially, many of these features must be handed to the agent before the start of planning, or it will not have enough information to proceed.
You can choose what information is passed to the agent at the start of planning by manually filling in the initial state in the scenario configuration file.
Alternatively, if you leave the set of initial state features empty as shown above, a "sensible" set of preconditions will be added to the initial state.
2.5.3 Skill level
Certain features are only unlocked to an agent with a sufficiently high skill-level. Experts (level 10) have access to some information that novices (level 1) do not. Check the fact_repository in Appendix A for more.
2.5.4 Personality
Agents may also possess a list of personality traits. These personality traits are checked by the modulator upon agent creation. Each personality trait is specified within the personality config file, an example of which is given in Listing 6.
1 --- # agent personality that is reasonably speedy but also stealthy 2 speed : 10 # jittered mean , in seconds , of the wait time between
actions
3 stealth : 10 # stealthiness penalty for noisy actions ; suggested weighting 1 - 10
4 skill_level : 10 # skill level , 1 - 10
5 deception : 0.4 # probability of deceptive action in between each directed action ; 0 - 1
Listing 6 Configuration file for agent personality.
The speed parameter specifies an average time, in seconds, for the agent to wait between actions. The actual wait time will be jittered, meaning it will vary randomly around the average. The stealthy penalty is added as an extra cost to actions with the noisy attribute in the knowledge base. Deception is given as a probability of a deceptive action between each directed action.
While the agent will always find a path to the goal if one exists, when there are multiple paths, this penalty will force the agent to choose the quietest path to be consistent with its personality preferences.
2.5.5 Search algorithms
A variety of search algorithms are available as part of an algorithm portfolio, includ-ing A∗, a multi-path-pruning algorithm, branch and bound, and iterative deepening.
In addition, all algorithms now have an optional parameter for cycle pruning, which will keep the agents from “running in circles" if a cycle is found in the state space graph.
The details of these algorithms is outside the scope of this document; however, different algorithms present different strengths in terms of time-to-result for different configurations of the state space. If the planner is running too slowly using one configuration, try another.
The planner may either plan forward (from the initial state to the goal) or reverse (from the goal back to the initial state). Often it is faster to do a reverse search, so by default ‘forward: False‘, but it is configurable.
The default cost for an edge in the state space graph is 1. That is, there is no default penalty for any particular action. However, different personalities may cause penalties to be layered upon certain actions, which results in a higher cost for those edges; see above.
2.5.6 Other planner configuration options
The next set of configuration options has to do with the actual operation of the planner itself.
The auto-run feature allows the agent to automatically execute the final generated plan, in the case of several plans being output.
The output file base name can be set.
Finally, you can also set the number of plans to be output. In many cases, there is more than one valid way to get from the initial state to the final.
2.6
Running ClassAttack on an emulated network
We were able to verify the functionality and effectiveness of ClassAttack through a mixture of testing strategies. For all reasonable subcomponents of the planner, such as the various Python classes and utility functions, tests were written using the Python unittest module. Upon running the unittest, we verify that all compo-nents passed the tests.
Figure 5: This figure shows how abstract actions are used to form the basis for selection and combination of CRAFT code fragments into an executable file. A plan consists of a list of abstract actions; these are used to select code fragments from within the knowledge base that are then combined with a header and footer file to make an executable Python script.
Further testing was also required for the individual plan elements, however. The plan itself is assembled from fragments of code stored in text files (Figure 5). Each of these fragments required separate testing, but it was nontrivial to do so in an automated way due to the requirement that each test be able to actually run on the range, having fulfilled all relevant preconditions. Therefore, a set of pre-built
scenarios is available within the planner; creating a static output file for each of these scenarios ensures that each action will be used at least once, and running each of the output files successfully is a test of the functionality of each action.
Using these two systems — one fully automated using Python unittest func-tionality and the other requiring extensive run-time testing — we are able to verify the effectiveness and functionality of ClassAttack on the range.
In this section, we outlined the design and development of a classical planner for AI attack planning, ClassAttack. We were able to verify the functionality of the AI attack planner by creating scenarios (as outlined above) and running them on the emulated network, or cyber range. We were able to successfully create and run these scenarios and can verify the effectiveness of ClassAttack.
3
Online Contingent Planning
In Section 2, we discussed the formalism and implementation of a classical planner for automated attack planning, ClassAttack. In this section, we extend the work done for ClassAttack to a new type of planner that works within a different paradigm; the contingent or conditional planning paradigm. In contrast to the classical problem, here we do not assume an offline planner with full observability; instead we assume that we will have an online planner, one which interleaves actions with observations, which only has partial knowledge of the world state at the beginning of planning.
This relaxation of the strict classical assumption comes with benefits and draw-backs. There is a concomitant increase of complexity, in the sense of engineering complexity and user experience complexity as well as in the sense of space and time complexity, as a bigger state space must be searched. However, the relaxation of the classical assumption also allows us to build an automated attack system which is much more realistic and which will have more behavioral similarities to an actual red team member trying to break into a network about which they may not have full information.
With this trade-off in mind, we built ConAttack. In this section, we begin with a more in-depth discussion of the features that we wanted to put in place that led us to the conclusion that a contingent planner would be the best choice for this application. Then, we set out the formalism of the contingent planning problem for deterministic action spaces, followed by an exploration of the extension of the current classical implementation to one that allows for a relaxation of the assumptions about full observability and about offline planning. We conclude with a brief discussion of
the usage of ConAttack as well as the observed performance and practicality of such a system.
3.1
Design elements of an extended attack planner
When designing ConAttack, it was critical that we include a few pieces of functional-ity that were not present in ClassAttack. One key component missing in ClassAttack was that of robust adaptation. A realistic red agent would have agile adaptability in the face of obstacles or difficulties that are encountered, real-time, when executing a cyber attack. While ClassAttack is able to provide multiple different plans or routes to achieve a goal, which would be scored based on their efficiency, ClassAttack is not able to robustly adapt to a changing cyber environment. Robust adaptation in the classical planning space is not possible for several reasons:
1. ClassAttack uses a classical planning paradigm which assumes full observabil-ity. So there is no element of the “unknown" around which ClassAttack would need to plan or adapt; it requires knowledge of everything that is relevant to its functioning, or it will not be able to produce a plan at all.
2. ClassAttack is an offline planner, not an online planner. So there is no way for ClassAttack to respond or adapt to real-time changes in the environment. 3. ClassAttack has a very limited set of features, and each of the features was
Boolean-valued; essentially a simple form of propositional logic. It is not pos-sible to express certain types of adaptation in propositional logic.
Therefore, due to early design choices, our initial software for automated attack planning has a limited capacity for adaptation, despite the fact that ClassAttack creates effective plans that can be executed in the emulated network environment. This design choice is what we aim to modify in the development of ConAttack.
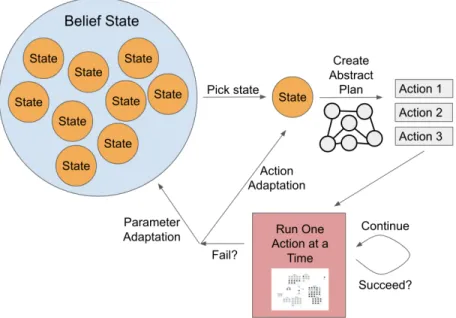
We identified adaptive properties that can be thought to operate along four dis-tinct lines:
• Action adaptations: Within a planning formalism, action adaptations con-sist of the ability to use a different set of actions to achieve the same result (or a “good-enough" result). In terms of the application area, sometimes a red teamer may be blocked, either by direct or indirection action by the blue team or different configurations on the network. The planner should attempt technique and procedure adaptation to achieve the tactic of the current stage in a different way that still leads to the fulfillment of the goal, the same way a real red teamer would.
• Parameter adaptations: Similarly, network blockages levied by blue teamers may also be circumvented by changing parameter types in the techniques, such as IP addresses, hostnames, or usernames. This changes the arguments to the action without necessarily changing the action itself. These parameter types should be changed quickly and automatically by accessing the IP addresses, hostnames, etc from the knowledge base. The red agent should access these quickly on the fly as they traverse the cyber range in order to try all possibilities as efficiently as possible during online planning.
• Goal adaptations: Typically, goal adaptations will be based on an updated understanding of the environment or defensive posture. Attacks may range from being purely opportunistic to being highly targeted attacks by a focused adversary. By broadening the objective to become more opportunistic, the attack may follow new directions based on what is discovered. The agents may therefore choose to change the goal if attaining the goal is otherwise seen as impossible.
• Personality adaptations: Red agents are endowed with several attributes that allow them to form a type of personality that can heavily weight their choice of action when it comes to building a plan. Some types of personalities may be maladaptive to certain types of situations; for example, it may be impossible to solve a problem using only “quiet" actions, leading an agent with a fully “stealthy" personality to fail. Therefore, the agent would require a slight change to personality in order to achieve its goals.
These types of adaptation are encoded into ConAttack in one form or another so that it will have maximum ability to re-plan dynamically to allow a flexible, realistic red team emulation.
3.2
The contingent planning paradigm
In order to allow for the incorporation of the above types of adaptation, it was necessary to move to a new conceptual model. Recall from Subsection 2.2 that the conceptual model for a classical planning problem is a finite, deterministic,
fully-observable state-transition model characterized by P = (Σ, s0, G), where Σ is the
state-transition model made of a finite set of states S, a finite set of actions A, and a cost function C(a) representing the cost of applying action a ∈ A. The state s0 ∈ S
is an initial state, and G ⊆ S is the set of goal states. The optimal solution for the planning problem is the one that minimizes the value of the expression Σn
i=1C(ai)
where s0 is the initial state, sn ∈ G, and the result of applying a0 through an to s0
is sn.
The classical planning paradigm relies on the assumption of full observability. When we relax this assumption but, crucially, allow for deterministic observations to take place during plan execution, we can create a new conceptual model that accounts for this relaxation, often referred to as planning under uncertainty. Because we maintain a deterministic action model, we will be exploring a contingent planning paradigm. However, the result of the fact that our initial state is partially unknown is that we must reason now about belief-states rather than concrete states. Further, we make the simplifying assumption that the probability of a particular observation result is uniform across all possible results of an observation (qualitative rather that probabilistic). Therefore, since the outcomes of observations cannot be predicted, the contingent planning task is one that is formalized using a non-deterministic, finite, belief-state-transition model Σ consisting of a 4-tuple (B, A, C, O) (See Table 4). By analogy to the classical planning problem, the contingent planning problem is therefore expressed by P = (Σ, b0, G) where Σ is the belief-state-transition model
laid out below, b0 is an initial belief state (set of possible concrete states), and G is
Table 4: Parameters for a contingent planning problem Object Description
B A finite set of belief states (compare to states in the classical planning paradigm). A belief state is not a particular state, but rather a set of states that the environment could possibly be in at any given moment. Note therefore that B is a set of sets of states, rather than a set of states; B = P(S)
A A : B → B is the finite set of actions. Here, actions are
functions that map a belief state b ∈ B to a new belief state b0 ∈ B. Recall that both b and b0 are belief states, which are
sets of states. Therefore, we can say A : P(S) → P(S) C(a) C(a) : A → k is a function that gives a scalar cost to every
action a ∈ A.
O(a, b) O(a, b) : A × B → B is the sensor model, or observation,
function, which is required to be noise-free. In other words, it may not given “deceptive" feedback or probabilistic feedback. The observation function returns the new belief state after applying action a in belief state b. So O(a, b) = {o(a, s)|∀s ∈ b}, where o(a, s) is the observed state after applying action a to state s. The o(·) function can be thought of as a special observation action which acts upon a belief state returned by an action and returns the subset of those states which are consistent with an observation performed in those states. G A non-empty set of belief states that contain only goal states,
G ⊆ B
b0 An initial belief state
The solution to a contingent planning problem is not as straightforward as a set of minimal-cost actions that lead from an initial state to a goal state, since we must deal with the uncertainty of the initial state and all consequent states, which leads to uncertainty about the effects of actions as well. Instead, solutions to contingent planning problems are usually expressed as a belief-state-action policy π(bi−1) = ai