Proximity-based approaches to blog opinion retrieval
140
0
0
Texte intégral
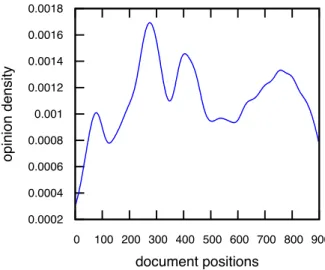
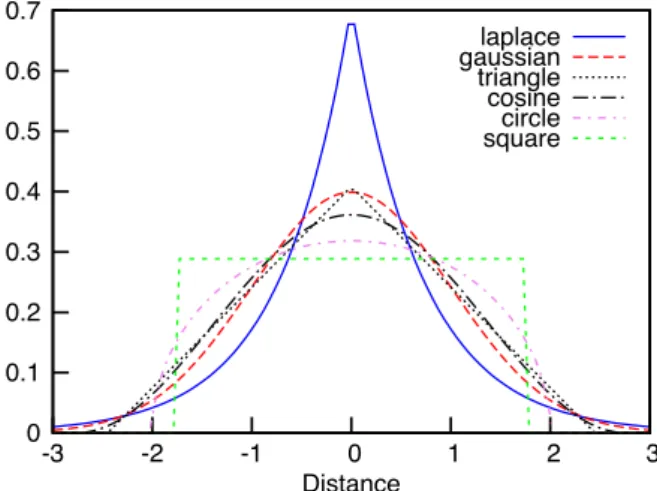
Figure


+7






Documents relatifs