Cognitive conflict in learning three-dimensional space station structures
Texte intégral
Figure
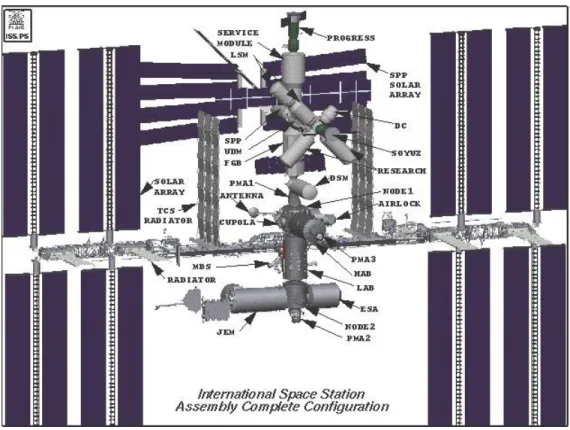
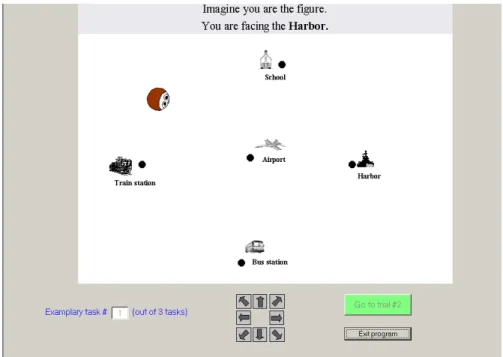
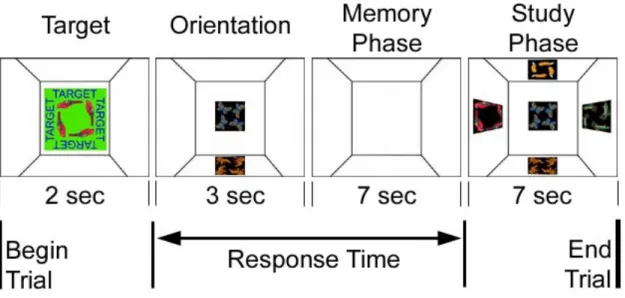

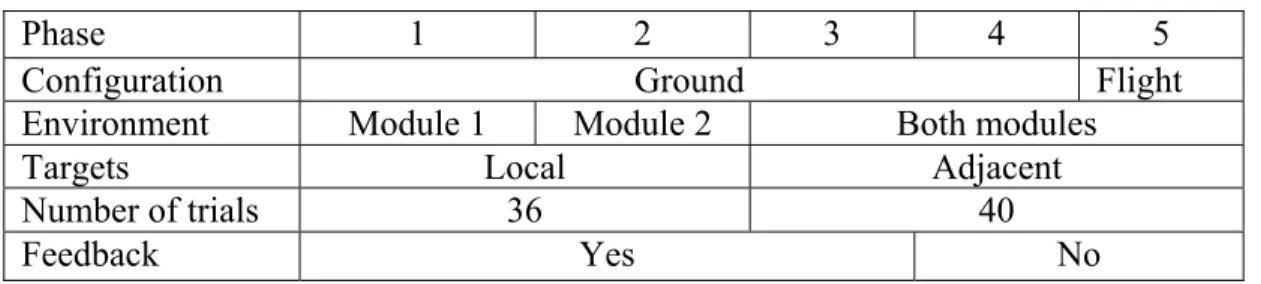
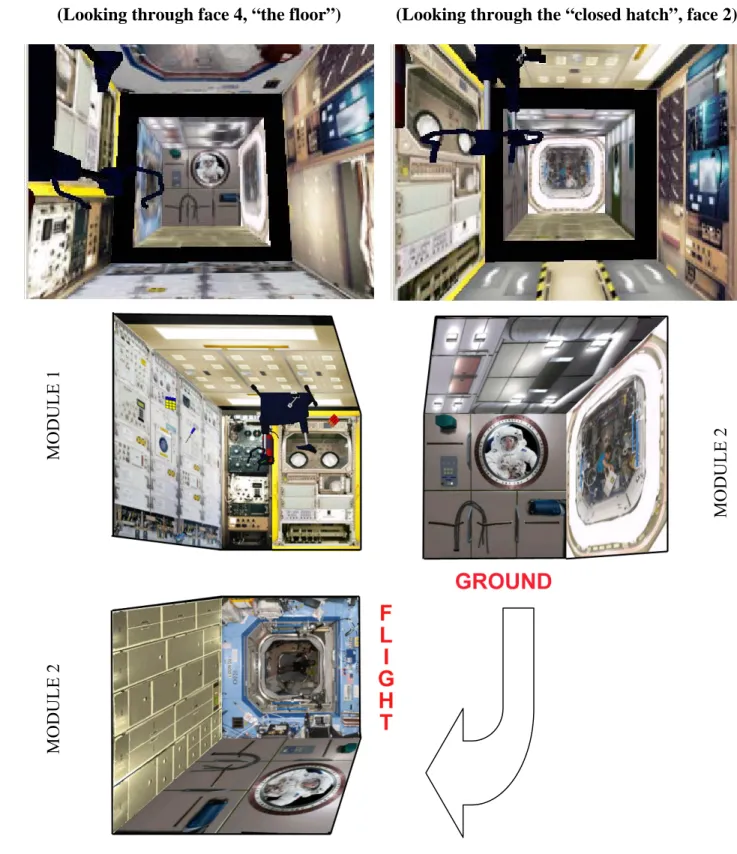
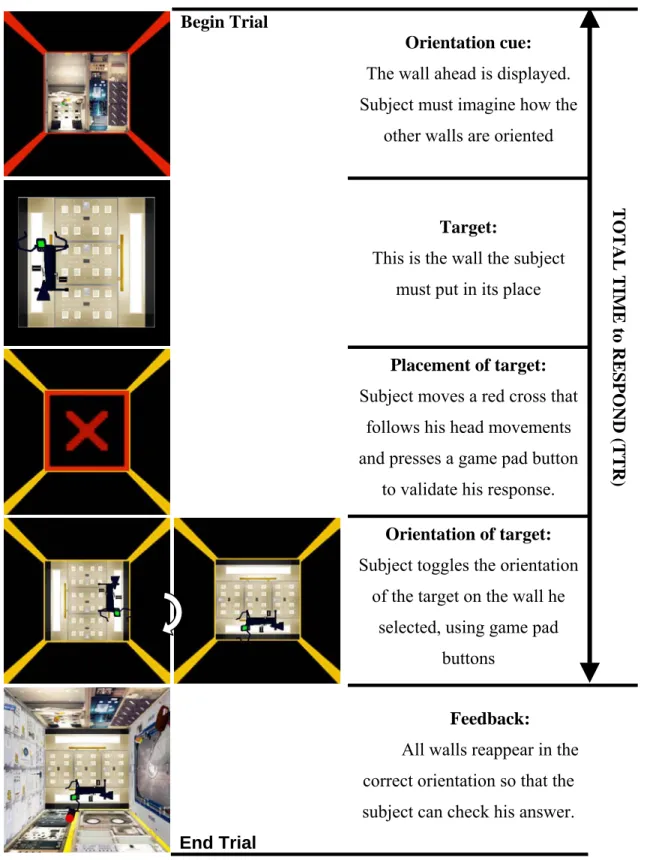
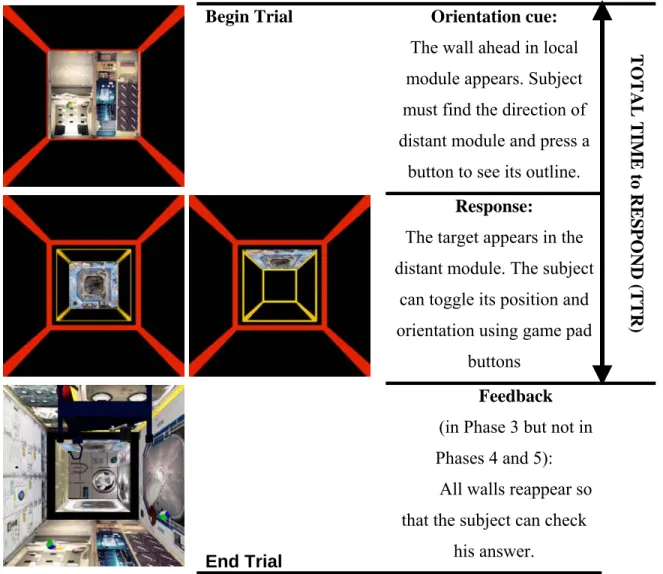

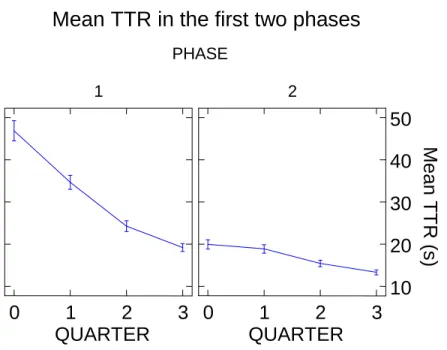
Documents relatifs
Our theoretical model (see Theorem 3.6, Subsection 3.1) favours the case in
CAMPONOVO - ANALYSING THE M-BUSINESS LANDSCAPE 75 : ISSUES scenario planning Multi-actor decision INDUSTRY perspective ACTORS Industry analysis Business model
The results can be summarized as follows: (1) The execution of the serve shows in many characteristics (e.g., ball drop, turning back the hitting side shoulder, and body extension
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Les différentes études présentées dans ce travail, bien qu’elles n’évaluent pas de façon globale le phénomène de déconnexion entre corps et esprit, rendent compte de
The goal of the article is the use of the hypercomplex number in a three-dimensional space to facilitate the computation of the amplitude and the probability of the superposition
In this paper, we are discussing simple models that can help us study the immersion trade-offs created between user position that affects the size of the visual field that is covered
Value-based assessment of new medical technologies: Towards a robust methodological framework for the application of multiple criteria decision analysis in the context of
