~-1 1
_
_
,
Université de Jijel
r---.... -
...
---~ ~\...-J."r'l'i.!"'j.s,~'J ~.ll, ~ ~' ~
Â.-<
Q J\...
Q
.Q.
~.
i:i
...
~~l~J
T
::Jl
.
IA .o-'1/-1+
Faculté des Sciences Exactes et de l'informatique
Département d'Informatique
Mémoire de Fin d'études pour l'obtention du diplôme
Master en Informatique
Opnon : Intelligence Artificielle
Thème
'avt
~'L--Conception et Réalisation d'un Système Expert
Distribué
Application : Résolution des Exercices de la
Géométrie
Réalisé par:
Bounar Fatima Zahra
Encadré par :
Mme. Kerada Ramdane Ouidad
-~ ,.
~·
~
Promot1on: 2017/1438
-Avant tout je remercie le
Dieu
qui m'a donné le courage et
la
force
pour continuer, c'est grâce a lui que mon chemin est éclairé pour
finir ce modeste travail
Je remercie très vivement mon encadreur Mm.Kerada
Ramdane Ouidad
de m'avoir encadré, orienté, conseillé tout au
long de mon travail
Je remercie également les membres de jury qui ont accepté
d'examiner et jurer mon travail
Ma reconnaissance s'adresse
à
ma famille
qui a su m'approcher,
sans relâcher les soutiens durant toutes ces longues années d'études.
En fin je remercie également, tous les enseignants, qui ont assuré ma
formation durant mon cycle universitaire.
Je tiens à dédier ce modeste travail à :
Ma chère mère
eta mon cher père
qui m'ont soutenu tous le
temps et
qui m'a toujours encouragé.
A
meschers frères
et
à
mes
chères sœurs.
A
mes NeveuxMohammed et Tasnim.
A
mes chères amies et collègues.
A
tous ceux qui j'aime et tous ceux qui m'aiment.
A tous, un grand merci.
Sommaire
Introduction générale
1. Problématique ... 01
2. Orientation et objectif ... 02
3. Plan de lecture du mémoire ... 02
Chapitre I: L'intelligence artificielle classique
Introduction ... 031. Les premiers pas de l'intelligence artificielle ... 03
1.1. Définition de l 'IA ... 04
1.2. Les caractéristiques de l'IA ... 04
1. 3. Les types de l' IA ... 0 5 1.4. Domaine d'application de l'IA ... 06
1.5. Généralité sur la connaissance ... 06
1.5 .1. La représentation des connaissances ... 07
1.5.2. Les types des connaissances ... 07
2. Les systèmes experts ... 08
2.1. Définition d'u système expert ... 08
2.2. Les composantes d'un système expert ... 08
2.2.1. Les acteurs ... 09
2.2.2. Les composantes logicielles ... 10
2.2.2.1. La base de connaissance ... 10
2.2.2.2. Les interfaces ... 13
2.2.2.3. Le module d'explication ... 14
2.2.2.4. Le moteur d'inférence ... 15
2.3. Le fonctionnement d'un système expert ... 21
2.4. Avantages et inconvénient des systèmes experts ... 22
2.5. Limitation des systèmes experts ... 22
Chapitre
II:
L'intelligence artificielle
distribué
Introduction ... 24
1. Les systèmes distribué ... 24
1.1. Objectif des systèmes distribué ... 25
2. L'intelligence artificielle distribué ... 26
2.1. Pourquoi distribuer la connaissance ... 26 2.2. Pourquoi distribuer l'intelligence artificielle ... 26 2.3. Définition de l'intelligence artificielle distribué ... 27
2.4. Thèmes de recherche de l'IAD ... 27 2.5. Problématique de l'IAD ... 28 3. Les systèmes multi agents ... 29 3.1. Définition d'un système multi agents ... 29 3.2. Concept d'agent ... 30
3.2.1. Définition ... 30
3.2.2. Caractéristique d'un agent ... 31
3.2.3. Structure conceptuel d'un agent ... 32
3.2.4. Les types des agents ... 33
3.2.5. Communication entre les agents ... 34
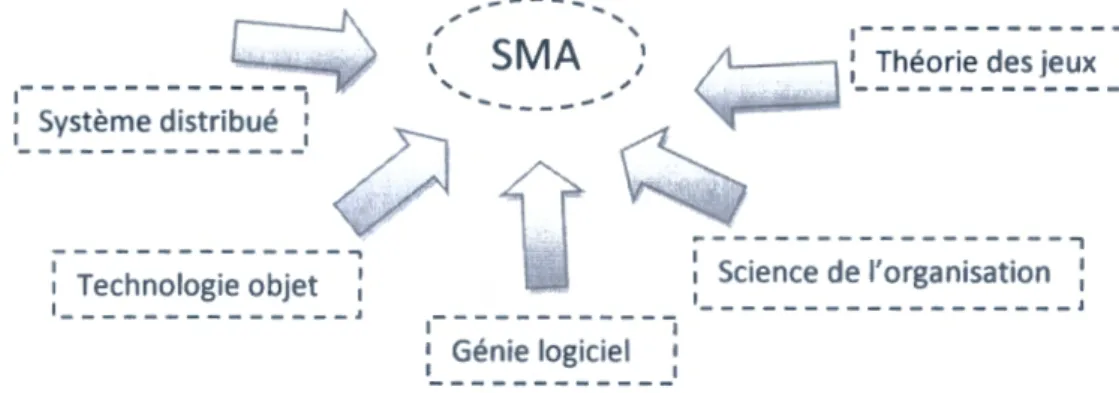
3.3. Disciplines de recherches contribuant les SMA ... 36
3.4. Interaction dans un système multi -agents ... 36
Chapitre III: la conception
Introduction ... 40
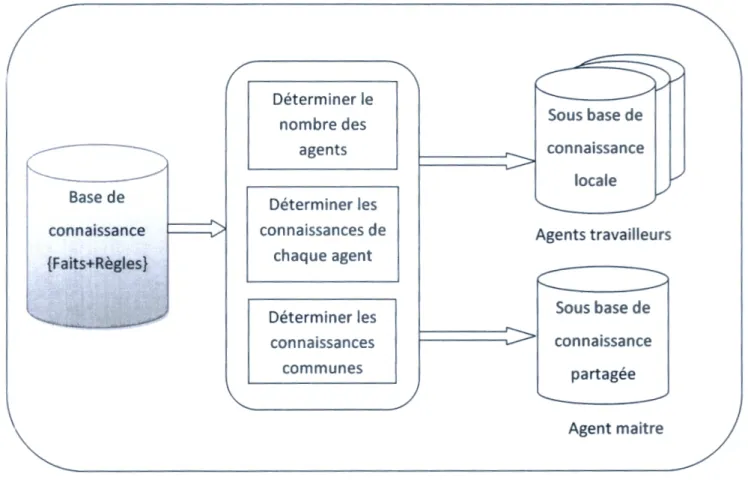
1. La base de connaissance du système ... .40
1.1. Modélisation des connaissances du système ... .40
1.2. Formalisation des règles de production de la base de connaissance ... .41
1.2.1. La syntaxe des règles de production ... .41
1.2.2. La logique d'ordre 1 ... .41
1.2.3. Les règles de production ... .42
1.2.4. L'unification des termes ... 43
1.3. L'architecture d'un agent ... .45
2. Approches de distribution ... .46
2.1. L'approche de distribution orienté agent (DOA) ... .46
2.2. Approche de la distribution parallèle (ADP) ... 50
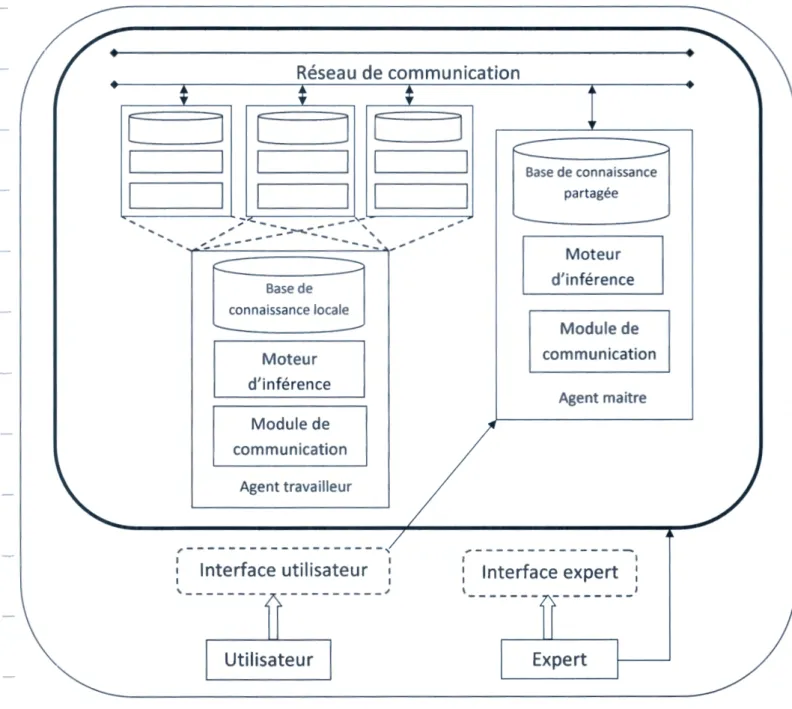
2.3. Architecture générale du système ... 51
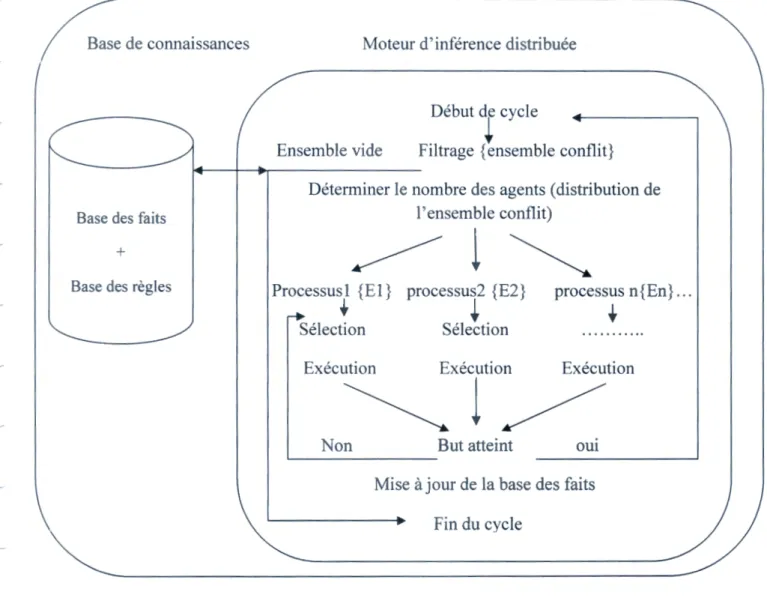
3. Le moteur d'inférence ... 52
3. ! .Principe du raisonnement ... 52
3.3.1 Cycle du moteur d'inférence selon l'approche DOA ... 53
3.3.2 Cycle du moteur d'inférence selon l'approche ADP ... 54
3.2. Etapes d'inférence ... 55
3.3. Mode de raisonnement ... 58
Chapitre IV: La réalisation
Introduction ... 60 1. Environnement de développement ... 60 1.1. Environnement matériel ... 65 1.2. Environnement logiciel ... 67 2. Description du logiciel ... 68 2.1. Interface graphique ... 68 2.2. Exemple de manipulation ... 72 2.3. Résultat expérimentaux ... 733. Synthèse des résultats ... 73
4. Conclusion ... 74
figures et tableaux
1
Liste des figures et tableaux
:
Figure I.2.2 : architecture principale des systèmes experts ... 10
Figure I.2.2 .2.4: Cycle d'un moteur d'inférence ... 18
Figurell.2.4 : les thèmes de recherche de l'IAD ... 30
Figure II.3.1. Représentation d'un système multi-agent. ... 33
Tableau II 3.2.4 : comparaison entre l'agent cognitif et l'agent réactif. ... 38
Figure 11.3.2.5.1 : communication par envoi de message ... 38
Figure II.3.2.5.2 : communication par partage d'information ... 39
Figure II.3.3 : disciplines de recherches contribuant les SMA ... .40
Figure 1.3 : les différents modules d'un agent ... .49
Figure 2.1.1 : Fonctionnement du système ... 51
Figure 2.1.2: Architecture du système selon l'approche DOA ... 52
Figure 2.1.3: Architecture de l'agent maitre ... 53
Figure 2.1.4 : Architecture d'un agent travailleur. ... 54
Figure 2.2.1 : fonctionnalité du système selon l'approche ADP ... 55
Figure 2.2.2 : l'architecture globale du système ... 56
Figure 3.1.1 : cycle de moteur d'inférence selon l'approche DOA ... 58
Figure 3.1.2 : cycle du moteur d'inférence selon l'approche ADP ... 59
Figure IV.2.1.1. Interface principale du système ... 68
Figure IV .2.1.2. Interface du choix de la résolution ... 69
Figure IV.2.1.3. Interface utilisateur du système ... 70
Figure IV.2.1.4. Interface expert du système ... 71
Figure IV .2.2. Exemple de manipulation ... 72
Glossaire
IA : Intelligence Artificielle
IAC : Intelligence Artificielle Classique IAD : Intelligence Artificielle Distribuée SE : Système Expert
BF : Base de Fait BR: Base de Règle
BC : Base de Connaissance MI : Moteur d' Inférence SMA : Système Multi Agent DOA: Distribution Orienté Agent
Introduction générale
1.
Problématique
Depuis l'apparition des systèmes experts, les règles de production sont devenues un formalisme de représentation de connaissances standard et efficace. Après l'essor connu par ces systèmes au début des années soixante-dix, les chercheurs du domaine se sont vite retrouvés confrontés au problème suivant : les systèmes experts sont monolithiques et représentent des limitations, certaines sont dues essentiellement à la quantité de connaissances croissante (problème d'inférence, problème d'acquisition des connaissances, etc ... ). ainsi qu'à l'inadéquation d'un contrôle centralisé pour des applications de plus en plus distribuées.
Motivés essentiellement par un souci d'efficacité, des travaux dont la problématique est la distribution de systèmes à base de connaissances sont apparu, Cette distribution a porté sur les connaissances (factuelle et/ou opératoire), ainsi que sur le contrôle. A ce titre, dans les années quatre_ vingt, des modèles sont développés autours des systèmes multi-experts, les systèmes distribués à base de tableaux noirs, etc.
A la différence entre l'intelligence artificielle classique (IAC) qui modélise le comportement intelligent d'un seul agent, L'intelligence artificielle distribuée (IAD) s'intéresse à des comportements intelligents qui sont le produit de l'activité coopérative de plusieurs agents.
La pluralité et la diversité des connaissances et des expertises ont rendu nécessaires le passage du comportement individuel aux comportements collectifs. ce passage est considéré non scellement comme une extension mais aussi comme un enrichissement de l'intelligence artificielle, qui présente plusieurs limitations certaines dues essentiellement à la quantité des connaissances croissante ainsi qu'à l'adéquation d'un contrôle centralisé pour des applications plus en plus distribuées.
2. Orientation et
Objectif
Nous avons choisit la solution basé sur l'IAD, l'IAD interviennent dans les même domaines de l'IAC en lui apportent de nombreux avantages :
• L'aspect naturel de certains problèmes qui sont naturellement distribué • La fiabilité puisque un système distribué est tolérant aux pannes
• L'efficacité qui réside dans l'accroissement de la capacité de calcul, du fait que les machines parallèles peuvent être le support matériel du système distribué
• La modularité qui permet un développement une maintenance et un test beaucoup plus facile du système
L'objectif de notre travail est d'augmenter l'efficacité et les performances d'un système à règles de production. Nous situons cette efficacité au niveau de : ! 'Organisation et la structuration de la base de règles ; la réactivité du système et le déclenchement parallèle des règles qui n'interfèrent pas et par conséquent l'optimisation du cycle d'inférence.
Notre travail consiste à concevoir et réaliser un système expert orienté agent pour la résolution des exercices de géométrie dans un plan. Le système intègre deux méthodes de répartition de connaissances supportées par un raisonnement distribué et semi distribué .
3. P
l
an
de l
e
c
t
u
re de mémoire
Après avoir posé la problématique et situé le cadre de notre projet, nous avons précisé l'objectif de ce travail, ensuite
);;;:- Dans le chapitre 1 nous rappelons des notions sur l'intelligence artificielle classique (caractéristiques et types), une généralité sur la connaissance, et la notion des systèmes experts comme étant un outil de l'intelligence artificielle et nous terminons avec les limites des systèmes experts
);;;:- Dans le deuxième chapitre, nous présentons la discipline des systèmes experts distribué, débutant avec une introduction sur les systèmes distribué et son objectif ensuite nous décrivons quelques notions sur l'IAD, nous exposons ensuite des notions générales sur les systèmes multi agents comme étant l'une des branche de l'IAD.
);;;:- Dans le troisième chapitre, nous détaillons l'ensemble des outils conceptuels et algorithmiques que nous utilisons, adaptons et proposons pour concevoir et réaliser un système multi-agents qui intègre au fonctionnement du moteur d'inférence.
);;;:- Dans ce chapitre, nous présentons le langage de programmation utilisé qui est java. Et représentons une application de réalisation d'un système expert résolveur d'exercices de la géométrie mathématique.
Nous terminons le chapitre par l'interprétation des résultats obtenus en comparons l'exécution centralisée avec l'exécution distribuée.
Nous terminons par une conclusion générale qui résume l'apport de notre travail.
L 'intelligence artificielle
Classique
Introduction
1.
Les premiers pas de l'intelligence artificielle
2.
Les systèmes experts
Introduction
L'intelligence artificielle est née dans les années cinquante et connaît depuis une vingtaine d'années un essor considérable. Les chercheurs dans ce domaine se sont fixé pour objectif d'analyser les comportements intelligents de l'homme, en particulier dans les domaines de la perception, de la compréhension, de la décision et de la conception, afin de les reproduire sur un ordinateur adoptant un comportement très proche du comportement humain. Ces travaux ont entraîné une modification dans la conception des méthodes de résolution de bon nombre de problèmes.
Le concept de système expert est directement issu des travaux réalisés en intelligence artificielle depuis de nombreuses années. À l'origine, l'objectif des chercheurs était de doter les ordinateurs de mécanismes logiques leur permettant de résoudre des problèmes très généraux comme la vision, la démonstration de théorèmes, la génération de plan d'action en robotique et le jeu d'échec.
1.
Les premiers pas de l'intelligence artificielle (IA)
L'objectif de base de l'IA est de créer une machine intelligente qui possède la faculté de raisonner, de comprendre, de déduire et de réagir.
Ainsi on à essayé tous d'abord de définir et cerner la qualité de l'intelligence chez les hommes, ensuite la transcrire au domaine des machines informatiques.
Depuis on a abouti a plusieurs résultats et réalisé plusieurs outils, on a alors obtenu plusieurs définitions.
La plupart des travaux portant sur la construction de système de ce genre on fat intervenir un ensemble de concepts logiques, ces travaux qui aboutissent parfois a des systèmes experts ont aussi introduit des notions de base de connaissance et des méthodes et techniques de représentation de connaissances.
1.1.
Définition de l'IA
Le terme intelligence artificielle, créé par John McCarthy, abrégé par IA (AI en anglais : Artificial intelligence). D'après l'un de ses créateurs, Marvin Lee Minsky.
C'est la construction de programmes informatiques qui s'adonnent à des tâches qui sont: Accomplies de façon plus satisfaisante par des êtres humains car elles demandent des processus mentaux de haut niveau tels que:
~ l'apprentissage perceptuel,
~ l'organisation de la mémoire
>-
le raisonnement critique. Nous proposons de citer aussiLes Problèmes non Résolus où la résolution est en un temps exponentiel voir même indéterminé tel que :
>-
les problèmes classés NP complets~ les problèmes NP difficiles
Un système
«
intelligent»
est destiné à remplacer ou à assister l'homme dans des domaines où l'expertise humain est :• non suffisamment structuré
sujette aux révisions et à l'enrichissement selon l'expérience cumulée.
Définition plus formelle :
L'IA offre un ensemble de techniques, de méthodes, et d'outils de formation, de modélisation, de représentation et d'utilisation des connaissances humaines (implicites et/ou explicites) pour reproduire certaines capacités cognitives et dépasser certaines capacités calculatoires humaines par l'intermédiaire d'un système informatique
1.2.
Les caractéristiques de l'IA
L'I.A investit les nombreux domaines où l'informatique classique n'est pas applicable. Ses caractéristiques majeures sont :
• Un programme d'I.A manipule des informations symboliques sous forme de concepts, d'objets ou de règles. En informatique classique on ne traite que des données de type numérique.
• Les systèmes d'I.A utilisent des méthodes heuristiques par opposition aux méthodes algorithmiques classiques. L'utilisation d'heuristiques permet d'aborder les problèmes sans solution algorithmique telle que la perception, la conception ou
la prise de décision et les problèmes dont la solution algorithmique est très complexe (exemple les jeux d'échecs).
• Une conséquence de la caractéristique précédente : les systèmes d'I.A emprunte des voies non déterministes dont le succès n'est pas garanti mais que lorsqu'elle marche permet un gain important en temps de calcul. A l'inverse, un algorithme consiste en une description exhaustive de la séquence d'opération à mener pour
résoudre un problème donné.
• L'I.A permet le traitement des informations incomplètes et inexactes par le biais de techniques de raisonnement particuliers (approximatif, non monotone, etc.).
• L'I.A est pluridisciplinaire, elle fait appel aux techniques avancées de l'informatique mais elle puise également des ressources dans la logique, la psychologie cognitives, la linguistique, l'ergonomie, la philosophie, les neurosciences et la biologie. [ 1]
1.3.
Les types de l'IA
• IA «faible»: La notion d'intelligence artificielle faible constitue une approche
d'ingénieur: chercher à construire des systèmes de plus en plus autonomes, des algorithmes capables de résoudre des problèmes d'une certaine classe, etc. Mais la machine simule l'intelligence, elle semble agir comme si elle était intelligente.
• IA « forte » : Le concept d'intelligence artificielle forte fait référence à une machine capable non seulement de produire un comportement intelligent, mais d'éprouver une impression d'une réelle conscience de soi, de « vrais sentiments » (quoi qu'on puisse mettre derrière ces mots), et « une compréhension de ses propres raisonnements
»
Pour résumer : L'IA faible imite de façon grossière notre intelligence, elle est seulementcapable de résoudre des problèmes. L'IA forte peut non seulement "réfléchir" mais aussi éprouver des "sentiments". [web 1]
1.4.
Domaines d'application de
1
IA
L'IA s'attache aux plusieurs types de problèmes et différentes applications, dont on Cite: [1]
• La robotique.
• La reconnaissance des formes.
• Traitement de la langue naturelle.
• Techniques de résolution des problèmes.
• Programme de jeux.
• Développement des systèmes experts en différents domaines.
• ... etc.
1.5.
Généralité sur la connaissance :
La connaissance est un terme générique que n'importe quelle personne peut comprendre
d'une manière intuitive.
Le terme connaissance correspond a un aspect plus large que celui de donnée, ou le
raisonnement et la solution peuvent être présent. Il est généralement plus vaste que celui
d'information puisqu'il comprend non seulement l'information, c'est-à-dire l'ensemble des
connaissances mises en forme, mais aussi les connaissances sans forme ou non explicitées.
Les problèmes liés à la connaissance vont être d'identifier, d'acquérir, de représenter et de
manipuler la connaissance. Ceci se fait au sein de système dits a base de connaissances [2]
1.5.1. La représentation des connaissances
La construction d'un système intelligent nécessite en générale un ensemble de connaissances sur le domaine d'application correspondant, et donc un moyen de les représenter, il s'agit de trouver un formalisme compréhensible, bien adapté a la nature de la connaissances, logique et souple dans sa réalisation, ainsi plusieurs techniques de la représentation de la connaissances ont été adopté :
• Représentation procédurale : chaque procédure décrit un raisonnement ou un cheminement particulier.
• Formalisme logique : à l'aide d'un langage symbolique permettant une représentation déclarative, il s'agit de la logique de proposition, logique de prédicat, logique floue, logique modale ... etc.
• Les réseaux sémantiques.
• Langage de frames et langages d'acteurs qui rentrent dans le cadre de la programmation orienté objet. [1]
1.5.2. Les types de connaissances
On peut distinguer deux types de connaissances : les connaissances explicites et les connaissances implicites, cette distinction est importante car selon qu'elles sont explicites ou
implicites, les connaissances ne pourront être traitées de la même façon. [3]
• Connaissances explicites
Correspond a des connaissances formalisées, c'est une connaissance collective, ayant un
caractère un peut générale et assez loin de la pratique
Les connaissances explicites sont celles qui sont déjà exprimé et conservées sur un rapport
quelconque, elles comprennent les procédures, les plans, les manuel d'entretien, les notes
techniques, les bases de données, les systèmes experts etc ....
Page 8
f
i
,
• Connaissances implicites
Acquise par imitation ou expérience et non par les mots, ne sont pas formalisé, elle sont d'ordre plus individuelle, elles vivent en chacun de nous mais sont difficiles a exprimé.
Les connaissances implicites concernent les savoir faire non écrits qui se transmettre de bouche à oreille, et qui résident dans la tête des employées. Souvent ces connaissances sont essentielles ne serait-ce que pour pouvoir utiliser les connaissances explicites, par exemple savoir ou chercher l'information pertinente dans la documentation).
Les connaissances implicites ne sont pas toutes explicitables.
2. Les
systèmes
experts :
Les systèmes experts sont des outils de l'intelligence artificielle, c ad qu'on ne les utilise que lorsque aucune méthode algorithmique exacte n'est disponible ou praticable.
On peut dire qu'un système expert comme finalité est un logiciel qui reproduit le comportement de l'être humain dans ses activités de raisonnement afin de parvenir à un gain
en temps et en efficacité dans le traitement de tâches de décision complexes.
2.1.
Définition d'un système expert
Un système expert est défini comme un programme informatique qui peut conseiller,
analyser, classer, communiquer, consulter, concevoir, explorer, anticiper, former, interpréter,
justifier, gérer, planifier, apprendre et tester. Ces tâches constituent des problèmes complexes
qui se réfèrent généralement à l'expertise humaine pour l'élaboration d'une solution. [3]
Un système expert est un programme interactif qui a un mécanisme de raisonnement qui
intègre jugements, expériences et règles de décision dans le but de faire des suggestions
logiques pour des types de problèmes variés. [5]
Un système expert est un programme intelligent qui utilise des connaissances et des
procédures d'inférences pour résoudre des problèmes. [5]
2.2.
Les composants d'un s
y
stème
ex
pert
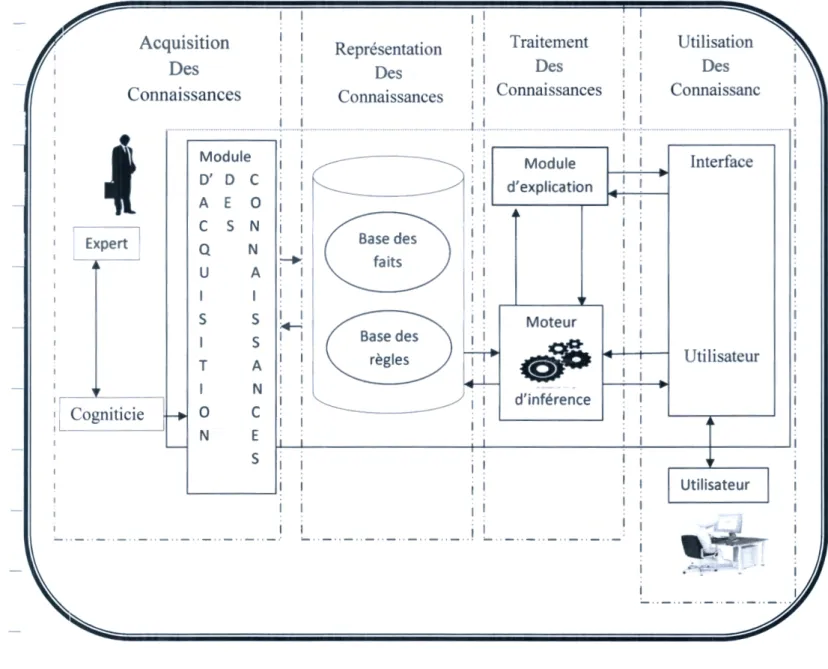
L'architecture générale d'un système expert est illustrée par la figure I.2.2
Acquisition ' Représentation 1 ' Traitement
1 Utilisation 1 1 . 1 1 1 Des Des 1 Des 1 Des • 1 1 1 1 • 1 • Connaissances
1 1 Connaissances · Connaissances 1 Connaissanc
t
Module 1 1 1 1 1 Modulem
1 Interface D' D C · : . 1 1 d'explication 1 A E 0 1 1 C S N~
1 E xper t 1 1 1 Q N /n---
..J-- " \ . 1 U A;-i
~
11 1 1 1 1 1 1 S S ~.J Moteur 5 1 1 Base des 1 1!
1T A 1 1 règles
·o~
~
Utilisateur1 N 1 1
I
[
H
1 1 d'' f' C .. :o
c
in erence 1 ogmtic1e 1 1 1 1 1 N Es
11 1 1 1 1 : 1l
Utilisateur 1!
1 1 1 1 - ··- ··- ·· -··- ··- ··-··- ··- · '---··- ··- ··- ··- ··- ··- ··- .1 '---·· -··- ··- ·· -··- ··-Figure 1.2.2 : architecture principale des systèmes experts
Nous pouvons classifier ces éléments en deux parties : les acteurs et les composants logiciels
[6]
2.2.1. Les acteurs
../ L'expert
Enrichit la base de connaissance du système. Cette phase appelée "la phase
d'acquisition de la connaissance " est une première tâche à effectuer pour constituer un système expert. Le système possède en général une interface pour l'introduction et la mise à jour des connaissances. Il est préférable d'assister l'expert par un cogniticien.
Un cogniticien est une personne qui a une double compétence. Il a des connaissances approfondies dans le domaine de l'expertise. Déplus, il possède les connaissances du domaine de l'IA afin de proposer des représentations adéquates pour formaliser et pour structurer les données de l'expertise .
./ L'utilisateur
Interroge le système à travers une interface dédiée. Il n'est pas forcément un
expert dans le domaine traité par l'application. Bien entendu, l'interaction entre l'utilisateur et le système doit se faire au travers d'une interface de dialogue dont
l'ergonomie n'exige pas de connaissances informatiques.
2.2.2. Les composants logiciels
2.2.2.1. La base de connaissances:
Se décompose en deux parties :
La première partie contient des faits spécifiques au domaine d'application. On parle Alors
de la base de faits.
La seconde partie, contient l'ensemble des règles qui vont permettre au système de
raisonner à partir de la base de faits.
;.... La base de faits
Mémoire de travail
Constitue la mémoire de travail du système à base de connaissances. Elle contient les données initiales et les données recueillies par les hypothèses émises ainsi quels nouveaux faits prouvés.
Par conséquent, la base de faits, spécifique au problème à résoudre, s'emichit au cours de la résolution de manière dynamique.
Type d'un fait
Les faits peuvent prendre des formes plus ou moins complexes. Nous n'envisagerons que des faits élémentaires dont les valeurs possibles sont booléennes (vrai ou faux), symboliques ce qui appartenant à un domaine fini de symboles, réelles pour représenter les faits continus.
Par exemple, Actif est un fait booléen, profession est un fait symbolique et rémunération est un fait réel.
Un système expert qui n'utilise que des faits booléens est dit d'ordre
O.
Un système qui utilise des faits symboliques ou réels, sans utiliser de variables, est d'ordre O+. Uns système utilisant toute la puissance de la logique du premier ordre est d'ordrel
Méta fait et méta valeurs
Pour qu'un système expert puisse modéliser un raisonnement humain, il est indispensable qu'il puisse raisonner sur ses propres raisonnements, réfléchir aux faits qu'il manipule, aux formules qu'il peut construire, etc ....
Autrement dit, il n'est pas suffisant que le système ait des connaissances, il faut aussi qu'il ait des métas connaissances. Il faut par exemple qu'un système expert puisse savoir si une valeur a été attribuée à un fait. Dans la négative, cette valeur pourra être demandée à l'utilisateur.
Mais, si l'utilisateur ne peut pas répondre, il faudra que le système puisse le savoir afin de ne pas poser éternellement la même question.
La seule manière d'attribuer une valeur à un tel fait sera alors de la déduire d'autres faits. On dira que la valeur d'un fait est :
./ Connue si une valeur lui a été attribuée ;
./ Inconnue si aucune valeur ne lui a été attribuée et si aucune question à son sujet n'a été posée à l'utilisateur;
./ Indéterminée si le système ne lui a attribué aucune valeur et si l'utilisateur a
répondu «je ne sais pas
»
à une question concernant sa valeur.~ La base de règles
Contient l'ensemble des règles de raisonnement du système, qui sont décomposé d'un
ensemble de prémisses ou condition d'activation et un ensemble de conclusions ou l'action à
exécuter, Un règle de production est une expression de la forme: si Hypothèses alors
Conclusions.
Elle peut être modélisée par différents modes de représentation des données. Cette base
rassemble la connaissance et le savoir-faire de l'expert. Elle n'évolue donc pas au cours d'une
session de travail et constitue la partie statique du système
Les métarègles et méta connaissances
De même que dans un système expert, la connaissance est traduite en règles, Les métas
connaissances s'expriment par des métarègles (c'est-à-dire des règles sur la manière d'utiliser
les règles).
L'organisation d'une base de connaissances au moyen de métarègles reste essentiellement
déclarative, contrairement à toute organisation basée sur une structuration a priori de l'ensemble des règles (écrire les règles dans un ordre donné, ... )
Le mécanisme d'exploitation de la base de connaissances
La base de connaissances va exploiter la base des faits pour rechercher la ou les solutions
(sinon l'échec). Le système essaie de simuler le raisonnement humain en utilisant certains
concepts:
• Les heuristiques : par opposition aux algorithmes. • La décomposition d'un problème en sous problème. • La progression par avancement et retour arrière.
• L'évolution vers la solution par une progression d'étapes successives différentes.
Le raisonnement peut être certain : aucune connaissance n'est pondérée.
Le raisonnement peut être incertain : à chaque connaissance est attaché un coefficient de plausibilité (ou de vraisemblance) permettant d'utiliser une logique dite floue ou de l'incertain par laquelle il existe un continuum de possibilités allant du vrai au faux
Le contrôle de cohérence de la base de connaissance
Quand les connaissances sont exprimées sous forme de règles, la vérification de bases de connaissances peut être abordée en profitant de leur lisibilité par la machine c'est-à-dire du fait que la machine peut examiner et interpréter en terme de validité, le système a base de connaissance qu'on lui a fourni.
De fait, les systèmes qui vont être présentés travaillent tous avec seulement la base de connaissances.
Les vérifications consistent à combiner de toutes les façons possibles les connaissances contenues dans cette base, de manière à détecter:
• les cas de réponse absurde à un problème reconnu de la compétence du système, • les bizarreries dans les règles, qui peuvent conduire à des déductions fausses ou
incomplètes.
Concrètement, ces systèmes procèdent à un ou plusieurs des contrôles suivants:
• contrôle que les règles contradictoires ne peuvent conduire, lors d'un processus d'inférence à partir d'une base de faits initiale valide à la déduction de faits contradictoires
• Deux règles r: P =>A et r': F =>A sont contradictoires si A contient a et A contient a tel que:
D dans le modèle d'expression des connaissances utilisé, on sait que a et a=> absurde
D on possède un ensemble de propriétés associées à la base de règles qui permettent de déduire que a et a=> L.
Les systèmes diffèrent les uns des autres par leur définition de la validité d'une base de faits initiale, par la prise en compte ou non de propriétés associées à la base de règles, et dans un cas, par une définition plus stricte des règles contradictoires.
Quand la base de règles satisfera ce premier contrôle, on dira qu'elle est cohérente. • contrôle que la base de règles ne contient pas de règles:
~ indéclenchables: r : P=>Q est indéclenchable si P n'est jamais démontrable lors d'un processus d'inférence à partir d'une base de faits initiale valide
~ redondantes: r: P=>Q est redondante s'il exister': P'=>Q' tant que P => P' et Q'=>Q ~ formant des cycles: un n-uplet de règles RI: PI => QI , ...
,Rn:
Pn
=>
Qn forme un cycle
si Vi tq 1 < i < n, Qiz >Pi+ 1 , et Qnz >Pl
Remarque: Les deux dernières propriétés ne concernent pas directement la fiabilité du système expert, sauf :
• s'il manipule des faits possédant des coefficients de vraisemblance: dans ce cas. la présence de règles redondantes peut entraîner de déduire trop de fois un même fait, faussant ainsi le coefficient de vraisemblance qui lui est associé.
• s'il raisonne en chaînage arrière ou mixte: dans ce cas, la présence de cycles peut entraîner des bouclages dans le processus d'inférence. [8]
2.2.2.2. Les interfaces
Les interfaces sont des modules programmés qui tiennent lieu d'unité d'entrée et d'unité de sortie d'un système expert, elles permettent 1 interaction avec les deux types d'operateurs d'une part l'expert et le cogniticien qui construit la base de connaissances et d'autre part les utilisateurs qui ont recours des services du système. [8]
L'interface expert
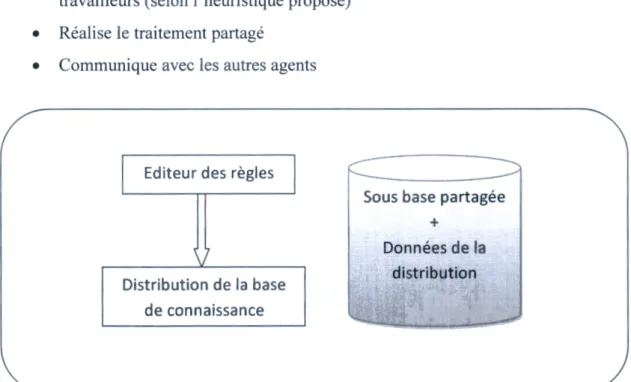
c'est par l'intermédiaire de l'interface expert que l'on peut transmettre a un système a base des règles les connaissances requises a la solution de problème dans un domaine d'application, on 'y parvient on éditant une base de règles. en générale l'interface expert comporte les modules suivantes :
./ Un éditeur de règles pour initialiser ou modifier le contenu de la base .
./ Un éditeur de dialogue avec l'usager permettant aux experts de prévoir les questions que le système a base des règles devra poser a l'usager pour le guider dans sa recherche de solution .
./ Un analyseur ou un compilateur de base pour traduire les connaissances des experts en structures de données reconnues par le moteur d'inférence.
En générale l'interface expert sert le lien entre les experts, les cogniticiens et la base de connaissances. Mais elle peut également transposer en règles des données factuelles entreposées dans une base de données ou dans un chiffrier.
L'interface utilisateur
l'interface utilisateur assure la communication entre l'utilisateur et la base de connaissance, il s'agit d'un module subordonné au moteur d'inférence, le module pose des questions a l'utilisateur au besoin, et recueille les réponses de ce dernier pour les transmettre au moteur d'inférence, la convivialité de cette interface varie selon le prix du système. Actuellement, on essaie de concevoir des interfaces graphiques ou des interfaces qui reconnaitraient des requêtes en langage naturel pour permettre une plus large diffusion de système expert.
L'interface utilisateur est décomposée de deux modules : un module de dialogue avec la base de connaissance et un module d'explication par lequel le moteur d'inférence explique comment il utilise le contenu de la base de connaissance pour répondre aux questions de l'utilisateur, il récupère les données empilées par le moteur d'inférence pour restituer la race du raisonnement effectué.
2.2.2.3.
Le module d'explicationLe module d'explication a pour rôle de rendre compte du raisonnement suivi par le système expert, pour cela il exploite en donnée une trace du raisonnement, deux types d'interlocuteurs sont à distinguer, l'ingénieur de la connaissance et l'utilisateur
Pour l'ingénieur de la connaissance l'explication est une aide indispensable pour l'acquisition et la mise au point de la base de connaissance pour objectif de rendre explicite la façon dont les connaissances sont interprété
Pour l'utilisateur l'explication est une faculté important dont dépond l'acceptation du logiciel auprès de l'utilisateur, qui permettre à comprendre le raisonnement, pou Convaincre du bien-fondé des conclusions et enseigner la démarche de résolution des problèmes. [8]
2.2.2.4.
Le Moteur d'inférence~ Définition
C'est un véritable interpréteur de connaissances. Il s'agit du cerveau su système expert,
c'est un programme ou procédure qui simule le raisonnement humain par une application
Constitue la partie du système qui fournit des réponses aux questions des utilisateurs. Il
met en œuvre le mécanisme de raisonnement chargé d'exploiter les connaissances. Il effectue
les déductions nécessaires afin de proposer une réponse au problème posé.
De façon générale, moteur d'inférence est capable de répondre à des questions, de
raisonner et de déduire des conséquences impliquées par la connaissance incluse dans le
système. [ 1]
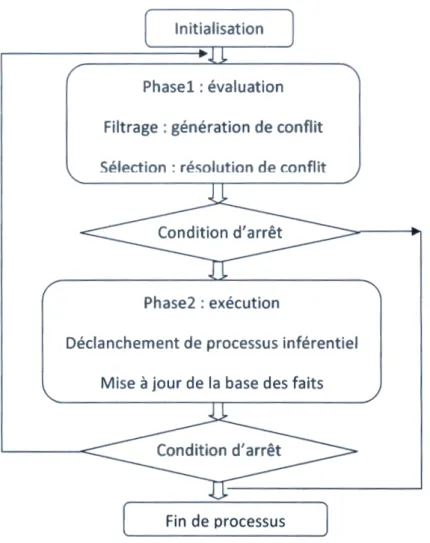
~ Cycles d'un Moteur d'inférence
Le MI enchaîne une séquence de cycles au cours de son raisonnement jusqu'à aboutir au
résultat désiré ou jusqu'à saturation. Un cycle du MI est composé de deux phases: [1]
Une phase d'évaluation
Une phase d'exécution
• Phase d'évaluation
Pendant cette phase, le MI essaye de dégager l'ensemble des règles qui peuvent être
tirées ou déclenchées à la phase suivante. Cette phase d'évaluation est effectuée en 3 étapes :
./ La restriction : c'est une étape optionnelle pendant laquelle le MI détermine un
sous ensemble de règles et de faits dans lequel il est probable de trouver la
solution. Dans ce cas, la base de connaissance est supposée être décomposée en des sous ensembles ou groupes de domaines distincts. Ainsi, pour la réponse à une
requête utilisateur dans un domaine particulier, il est suffisant de faire une
recherche uniquement dans le groupe correspondant.
./ Filtrage ou génération de conflits : dans cette étape, on fait la sélection des règles
qui peuvent effectivement être déclenchées. Exemple : les règles dont les
prémisses appartiennent à la base de faits. On obtient un sous ensemble de règles
appelé ensemble de conflits
./ Sélection ou Résolution de conflits : Dans cette étape, on fait le tri des règles déjà
sélectionnées, et on choisi la première règle (ou les premières règles) à déclencher.
• Phase d'exécution
Dans cette phase en déclenche les règles dernièrement sélectionnées. Les nouveaux faits
résultants seront ajoutés à la base de faits. Dans ce cas, si le but est atteint la recherche est
arrêtée, sinon, on recommence un nouveau cycle.
Généralement cette phase consiste à ajouter des faits à la base de fait, mais il est aussi
possible d'en retirer d'autres ou de déclencher des réactions ou exécuter des tâches
supplémentaires. Remarque:
Le traitement du MI peut aussi être arrêté lors du cycle de recherche dans le cas où la
génération de conflits abouti à un ensemble vide.
Le schéma suivant représente le cycle d'un moteur d'inférence :
Page18 f
Initialisation
Phasel : évaluation Filtrage : génération de conflit Sélection : résolution de conflit
Phase2 : exécution
Déclanchement de processus inférentiel Mise à jour de la base des faits
Fin de processus
);;> Caractéristiques d'un Moteur d'inférence
Le but est de présenter un ensemble de critères qui peuvent distinguer entre les différents moteurs d'inférence. En effet, la programmation d'un moteur d'inférence nécessite la sélection d'un ensemble de critères à réunir dans celui-ci.
Les critères de base d'un moteur d'inférence sont : son mode d'invocation des règles, la stratégie de recherche qu'il utilise, son régime de contrôle et le critère de monotonie. Ainsi, en choisissant à chaque fois un mode d'invocation des règle donné, une stratégie de recherche un régime de contrôle et en fixant la monotonie, on obtient un moteur d'inférence complet et
bien définie. [ 1]
• Modes d'invocation des règles
Les MI sont distingués par leur mode d'invocation des règles. En effet, on peut classifier les MI en 3 catégories : [9]
1) Les MI à chaînage avant : un MI à chaînage avant (forward chaining) détermine le résultat (ou but) à partir de la BDF. Les règles à déclenchera chaque cycle sont celles dont les prémisses appartiennent à la BDF. L'exécution de ces règles modifie la BDF et d'autres règles peuvent alors être déclenchées au cycle suivant. Ce principe sera répété jusqu'à ce que le but soit dans la BDF.
Exemple:
Soit BDF = {A, B, C, D} et soit la règle : A, C ~o cette règle est déclenchable et on obtient
BDF = {A, B, C, D, G}
L'étape de génération de conflit correspond à rassembler toutes les règles dont les
prémisses sont dans la BDF.
Algorithme chainage avant
Algorithme chainage_avant () Entrée : BF (base de faits),
BR (bases de règles (R)),
F (fait que l'on cherche à établir)
Début
Tant que F n'est pas dans BF et qu'il existe dans BR une règle applicable -choisir une règle applicable R (étape de résolution de Conflits) -BR= BR - R (désactivation de R)
-BF = BF
+
conclusion R (déclenchement de la règle R sa conclusion estFin tant que
Si F appartient à BF Alors Fest établi
Sinon
F n'est pas établi
Fin si
Fin
rajoutée a la base de faits)
2) Les MI à chaînage arrière : un MI à chaînage arrière (backward chaining) détermine
l'ensemble des règles qu'il faut invoquer pour aboutir au but (fait à établir). Le but sera alors remplacé par les prémisses qui vont constituer les nouveaux faits à établir. Les règles à tirer à chaque cycle sont alors celles dont les conclusions sont égales au (ou contiennent le) fait à établir. L'exécution de ces règles ne modifie pas la BDF mais elle remplace le problème initial par d'autres. Ce type de raisonnement correspond à une décomposition du problème en un ensemble de sous problèmes.
Exemple:
Soit le but
à
établirP,
et soit la règle : A,B,
C ~P
Pour résoudre le problème
P,
il suffit de résoudre les sous problèmes A,B
et C. Ce mécanisme sera répété jusqu'à ce que la dernière liste de faits à établir soit entièrement dans la BDF.L'étape de génération de conflit consiste rassembler toutes les règles dont les
conclusions contiennent le fait à établir. Algorithme chainage arriéré
Algorithme chainage_ arriére ()
Entrée : F base de faits F, R base de règles, P ensemble de faits à prouver Début
Tant que P
-f.
0Extraire (en l'effaçant) de P un fait f Si le fait f est absent de F alors
S = ensemble des règles concluant sur f Si S
-f.
0 alorsA = choix d'une règle de S
Prouver tous les faits en prémisse de A Si A est applicable alors
Appliquer la règle A Fin si
Fin si Fin tant que
3) Les MI à chaînage mixte
Ce type de moteur d'inférence peut être choisi lorsqu'une partie des faits du
problème est à établir, l'autre est considérée déjà établie. Les conditions de
déclenchement des règles dans ce cas peuvent porter sur les deux types de faits. Donc,
pour résoudre le problème on sera amené à prendre en considération les faits déjà
établis et de remplacer le problème à résoudre par une liste de sous problèmes. Ceci,
correspond à un mode de raisonnement mixte faisant intervenir simultanément le
chaînage avant et le chaînage arrière.
Algorithme chainage mixte
Algorithme chainage_ mixte () Entrée : F (à déduire)
Début
Tant que F n'est pas déduit mais peut encore l'être Faire - Saturer la base de faits par chaînage_ avant
- Chercher quels sont les faits encore déductibles - Déterminer une question pertinente à poser à
L'utilisateur et ajouter sa réponse à la base de faits Fin tant que
Fin
• Stratégies de recherche
Au cours des cycles de recherche d'un moteur d'inférence, on développe un arbre de recherche dans lequel chaque niveau correspond à l'ensemble de règles déclenchable (ensemble de conflits). Chaque règle déclenchée crée une nouvelle situation et de nouvelles règles à invoquer.
Deux stratégies de recherche de la solution se présentent :
../ Soit on développe toutes les règles d'un même niveau de l'arbre l'une après l'autre avant de passer au niveau suivant. Cette stratégie correspond à une recherche en largeur d'abord .
../ Soit on passe d'un niveau à un autre à chaque fois qu'on déclenche une règle et on ne revient aux règles restantes que si on épuise toutes les règles en profondeur sans avoir trouver la solution. Ceci correspond à une stratégie de recherche en profondeur d'abord.
Le retour-arrière dans le cas où la recherche en profondeur échoue sera appelé
backtracking.
Remarque:
1- Un moteur d'inférence à chaînage avant ou arrière peut être en profondeur ou en
largeur d'abord.
2- Le mode d'invocation des règles et la stratégie de recherche constituent les critères de
base pour la réalisation d'un moteur d'inférence. [1]
• Régime de contrôle
Le régime de contrôle pour un moteur d'inférence peut être irrévocable ou par tentative .
./ Dans le cas d'un régime irrévocable, l'application d'une règle dans un cycle du
moteur d'inférence n'est jamais remise en cause et on n'opère pas de
backtracking. S'il n'y a plus de règles à appliquer le moteur d'inférence s'arrête
et signale un échec sans faire de retour-arrière .
./ Les régimes de contrôle par tentatives peuvent remettre en cause des règles déjà
appliquées si elles n'ont pas abouti, et faire un backtracking en retirant aussi les
faits qui en étaient déduits. [l]
• La Monotonie
Un Moteur d'inférence peut être monotone ou non-monotone .
./ Un moteur d'inférence monotone garde chaque fait initial ou ajouté à la BDF
jusqu'à la fin de la recherche, et tout fait ajouté n'introduit pas de
contradiction avec les autres faits de la BDF .
./ Un moteur d'inférence non-monotone, peut retirer de la BDF un fait
précédemment ajouté. Cette situation peut être rencontrée en cas de
backtracking par exemple. Les faits déduits d'une règle qui n'a pas abouti
seront supprimés à l'occasion de la remise en cause de la règle en question et le
choix d'une autre en faisant un retour-arrière. Certains faits peuvent aussi être
retirés de la base de faits s'ils présentent des contradictions avec d'autres .
./ La monotonie concerne aussi les règles. Ainsi un système monotone n'élimine
jamais une règle de la BDR, toutes les règles sont considérées correctes jusqu'à
la fin du raisonnement. Cependant un système non-monotone peut retirer des
règles en constatant des contradictions avec d'autres. [ 1]
2.3.
Le fonctionnement d'un système expert
Un système expert fonctionne selon un cycle [l O]
• L'engagement des paramètres: Dans un premier temps, le moteur d'inférence
doit obtenir les connaissances et l'objectif par l'utilisateur via l'interface graphique.
• L'application des règles d'inférence: Ensuite, le système expert fait appel aux règles d'inférence adéquates pour traiter les données courantes en fonction de
l'objectif et les appliquent
• L'enregistrement des résultats: Dans un troisième temps, les résultats récupérés
sont enregistrés dans la base de connaissances (base de faits) et les solutions
potentielles renvoyées vers l'utilisateur pour la validation
• Le rendu du résultat (fin du cycle): Lorsqu'une solution potentielle est trouvée elle est proposée à l'utilisateur qui valide (ou non) celle ci. Elle est, dans ce cas,
enregistrée comme solution validée (ou non) dans la base de faits
L'étape d'engagement des paramètres diffère selon qu'on se trouve au premier cycle
• Engagement des paramètres (deuxième cycle) : Lors du prochain engagement de
paramètres, les faits enregistrés (base de faits) sont rappelés
2.4.
Avantages et inconvénient des systèmes experts
• AvantagePage 24
f
Permanence : l'expérience est permanente, contrairement aux spécialistes
humains qui peuvent se retirer, renoncer ou mourir, la connaissance s'un système
expert durera indéfiniment.
Expérience multiple : la connaissance des plusieurs spécialistes peut être
disponible pour travailler simultanément sur un problème a toute heure de la nuit
ou du jour.
Grande disponibilité: l'expérience est disponible pou tout matériel de traitement adéquat.
Cout réduit : le cout de mettre l'expérience
a la disposition de 1
'utilisateur
est
Danger réduit: les systèmes experts peuvent être utilisés dans les
environnements qui pourraient être dangereux pour un être humain. • Inconvénient
Ils créent le chômage parce qu'ils émulent les humains.
Dans les systèmes experts, on fait inférence à des connaissances même si elles sont dépassées.
2.5.
Limitations des systèmes experts :
Ces systèmes apportent des solutions nouvelles ou parfois plus rapides mais soulèvent plusieurs difficultés. [ 11]
• Acquisition des connaissances : l'acquisition des connaissances requiert le codage des connaissances dans la base, ce qui mobilise l'intervention de deux spécialistes Le premier expert du domaine d'application, fournit les connaissances nécessaires à la réalisation de l'application.
Le second expert en IA, extrait le savoir-faire du premier et le code dans la base.
L'expert du domaine a souvent des difficultés pour exprimer explicitement ses connaissances, ce qui nuit à l'élaboration du système.
• Cohérence de la base de connaissances: la vérification de la correction et de la complétude de la base de connaissances est une tâche complexe. selon le domaine
d'application, cette tâche peut même s'avérer impossible dans la mesure où des
incohérences et des contradictions sont parfois inhérentes ou consubstantielles du
domaine, par exemple dans le cadre juridique.
• La rigidité de la base de connaissances: l'autre défi des systèmes experts est une
conséquence de la représentation uniforme des connaissances. Toutes les
connaissances sont représentées dans un formalisme unique. Les règles de la base de
connaissances sont alors dédiées à un type de raisonnement particulier. Il en résulte la
difficulté de construire la base pour des problèmes qui s'expriment naturellement dans des formalismes différents.
• La faiblesse de raisonnement: cette limitation est une conséquence directe du codage
de la base de connaissances, puisque généralement la procédure de raisonnement
dépend du mode de représentation de la base de connaissance
Conclusion
Dans ce chapitre, nous avons dans un premier temps donné une introduction de l'intelligence artificielle classique et des généralités sur les connaissances, ensuite nous avons
représenté la notion de système expert et le cycle de fonctionnement du moteur d'inférence. Alors L'évolution des domaines d'applications de l'IA a montré les limites de cette approche classique qui s'appuie sur une centralisation de l'expertise au sein d'un système umque.
Les travaux menés sur la concurrence et la distribution ont contribué à la naissance d'une nouvelle discipline dite l'intelligence artificielle distribuée.
Dans le chapitre suivant, nous allons présenter quelques fondements et méthodes de l'intelligence artificielle distribuée.
L'intelligence artificielle
distribuée
Introduction
1.
Les systèmes distribués
2.
L'intelligence artificielle distribuée
3.
Les systèmes multi agents
Introduction
L'évolution des domaines d'application de l' Intelligence Artificielle Classique dans la modélisation des domaines complexes et hétérogènes, a montré les limites de l 'IA classique qui s'attache à la centralisation et à la concentration de l'expertise au sein d'un seul et même
système. Les travaux réalisés sur la concurrence et la distribution, ont contribués à la naissance d'une nouvelle bronche, à savoir !'Intelligence Artificielle Distribuée (IAD).
L'objectif initiale de l'IAD était de remédier aux défaillances de l'approche I
classique, en offrant la distribution de l'expertise sur un groupe d'agents. suffisamment
autonomes pour pouvoirs êtres capables de travailler et d'agir dans un environnement
commun et résoudre les conflits éventuels. Par la suite on baptisait ces systèmes par Systèmes
Multi-Agents.
1.
Les Système distribué
Un système distribué est un logiciel faisant apparaitre un ensemble de machines indépendantes comme une machine unique qui coopèrent et échangent des informations.
En tant que système un système distribué doit tout d'abord assurer la gestion des ressources physique (processeurs, mémoire centrale, périphériques, divers) et doit d autre part masquer tous (ou au moins le maximum possible) les détails inhérents à la nature repartie et éventuellement hétérogène de ces ressources. [ 1 O]
Il s agit donc d offrir aux utilisateurs une machine virtuelle incluant touts les ressources on peut dire :
• Un système distribué est un système comprenant un ensemble de processus et un système de communication
• Les processus sont décrits dans un langage de programmation
• Le système de communication met en œuvre une méthode de communication (par variable partagée, par envoi de messages)
• On discerne deux modèles de systèmes distribués :
./ Les systèmes fortement couplés ou systèmes à mémoire partagée, ./ Les systèmes faiblement couplés ou systèmes par envois de messages.
1.1.
Objectifs des systèmes distribués
• Transparence : cette notion de transparence correspond à la possibilité d'accéder à un service ou une donnée indépendamment de certaines propriétés liées à la distribution,
cette notion de transparence présente différente aspects
• Accès : correspond à la possibilité d'accéder à une ressource par une interface unique
que cette ressource soit locale ou distante :
./ Localisation : exprime la possibilité d'accéder à une ressource sans connaitre la
localisation
./ Réplication : permet d'accéder à des exemplaires multiples de ressources sans
connaitre l'existence à des fins de performances et/ou de fiabilité
./ Concurrence : correspond à la possibilité pour plusieurs processus d accéder
«
simultanément» à une même ressource sans que ces accès n'interférent entre eux./ Mobilité / migration: autorise la mobilité (ou migration) d'objets (ressources
ou processus) sans affecter le déroulement des opérations en cours
./ Défaillance : correspond au masquage des pannes de sites ou d inaccessibilités des objets jusqu' au recouvrement de l'erreur correspondante
• Fiabilité-disponibilité : un des buts de recherche est d'améliorer la disponibilité du système et donc d'offrir un service plus fiable 1 idée est que si un composant tombe en panne, le système continuera d'être accessible, contrairement a ce qui se passe dans un système monoprocesseur classique ce volet de tolérance aux pannes est un champ d'études important du domaine des systèmes distribués
• Performances : un système reparti peut offrir la possibilité de distribuer les calculs sur plusieurs processeurs ou de permettre l'exécution d une application sur un processeur adapté à ses besoins (soit par exemple qu'il soit peut charge ou que l'espace disponible en mémoire y soit plus adapte aux besoins de 1 application) [ 1 O]
2. L'intelligence artificielle distribuée
2.1.
Pourquoi distribuer la connaissance
Les raisons de la distribution de la connaissance peuvent répondre aux investigations
suivantes : [ 11]
Distribution fonctionnelle :
• multi-expertise /points de vue multiples;
• décomposition de problèmes
Distribution physique :
• Problèmes intrinsèquement distribués : réseaux. contrôle aérien.
• Robotique.
Distribution informatique :
• développement de machines parallèles ·
• développement des langages à objets.
• Faire coopérer des systèmes préexistants, hétérogènes. distribués
autonomes.
2.2.
Pourquoi distribuer l'IA
Les raisons de la distribution de l'intelligence artificielle peuvent répondre aux investigations suivantes : [12]
~ Résolution distribuée de problèmes
• Résolution d'une tâche complexe par un ensemble de spécialistes ayant des
compétences complémentaires,
• L'expertise est distribuée mais le domaine ne l'est pas,
~ Résolution de problèmes distribués
• Le domaine est distribué,
• Analyse, identification, contrôle de systèmes physiquement distribués,
~ Résolution par coordination
• L'expertise par coordination,
• Surmonter des problèmes d'interface utilisateur
2.3.
Définition de L'IAD
L' IAD propose la distribution de l'expertise sur un groupe d'agents
devant être capables de travailler, d'agir et de s' organiser pour arriver
à résoudre un problème posé, dans un environnement commun et résoudre les
conflits éventuels.
Cette distribution de l' expertise peut être géographique et / ou
fonctionnelle. D'où la naissance de notions nouvelles en IA, telles que la coopération, la coordination d'actions, la négociation et l' émergence.
La distribution de l' expertise fait que chaque agent dispose d une connaissance parcellaire, qui ne requiert qu' un mécanisme de raisonnement
simplifié. Cette simplification est acquittée par la complication des
interactions entre agents, qu' il s' agisse de déterminer les structures de
communication ou de définir la connaissance commune dont ils disposent. [13
J
2.4.
Thèmes de recherche de l'IAD
L' IAD peut alors être définie comme étant la branche de l' IA qu1
s'intéresse à la modélisation de comportement 'intelligent' par la
coopération entre un ensemble d'agents. Nous distinguons ainsi trois axes fondamentaux dans la recherche : [14]
IAD
RDP
SMA
IAP
Figure 11.2.4: les thèmes de recherche de l'IAD
• Les systèmes multi agents (SMA) : il s'agit de faire coopérer un ensemble d'agents
dotés d'un comportement intelligent et de coordonner leurs buts et leurs plans d'action
pour la résolution d'un problème
• La résolution distribué des problèmes (RDP) : elle s'intéresse la manière de diviser
un problème particulier sur un ensemble d'entités distribuées et coopérantes, elle s'intéresse aussi a la manière de partager la connaissance du problème et d on obtenir
la solution.
• L'intelligence artificielle parallèle (IAP) : elle concerne le développement de
langages et d'algorithmes parallèles pour l'IAD, l'IAP vise l'amélioration des
performances des systèmes d'intelligence artificielle, sans. toutefois s'intéresser à la
nature du raisonnement ou au comportement intelligent d'un groupe d'agents.
Cependant il est vrai que le développement de langage concurrents et d'architecture
parallèle peut avoir un impact important sur les systèmes d 'IAD .
2.5.
Problématique de 1 l'IAD
Les problèmes que l' IAD s'attache à résoudre les problèmes classiques
de
l'
IA qui ont pris une nouvelle dimension dans le contexte multi-agentset les nouveaux problèmes proprement liés au thème de l' IAD, on peut
citer [13]
• La modélisation de la connaissance et le problème de la répartition sur les différents agents : Comment formuler, décrire, décomposer, allouer des problèmes et synthétiser les résultats parmi un groupe d'agents.
• Comment permettre aux agents de communiquer et d'interagir. Quels langages ou protocoles de communication utiliser, quoi et quand communiquer.
• Comment s'assurer que les agents agissent d'une manière Cohérente dans la phase de prise de décisions ou d'exécution d'actions en évitant les interactions nuisibles. • Comment s'assurer que les agents individuels représentent et raisonnent au sujet des
actions, des plans et de la connaissance des autres agents afin qu'ils puissent être coordonnés entre eux.
• Comment reconnaître et réconcilier des points de vue dispersés et des intentions conflictuelles parmi une collection d'agents qui essayent de coordonner leurs actions.
• Comment construire des systèmes d'IAD pratiques; comment créer des plates-formes
et des méthodologies de développement pour l'IAD.
3. Les systèmes moiti agents (SMA)
Les systèmes multi-agents sont l'une des branches les plus prometteuse de l'IA. sont
d'abord utilisés pour la modélisation de systèmes complexes et conduisent la plupart du temp
à des séries de simulations exploratoires. C'est une communauté d'agents autonome
travaillant en commun selon des modes de coopération, conflit, concurrence pour aboutir a un
objectif global.
Autrement dit, il s'agit de faire coopérer un ensemble d'entités dotées d'un comportement
intelligent et de coordonner leurs buts et leurs plans d'action pour la résolution d'un
problème.
3.1.
Définition d'un SMA
Les systèmes multi-agent empruntent à l'intelligence artificielle distribuée les modes de
communication et de déconcertassions entre agents.
(Ferber 1995) donne la définition suivante :
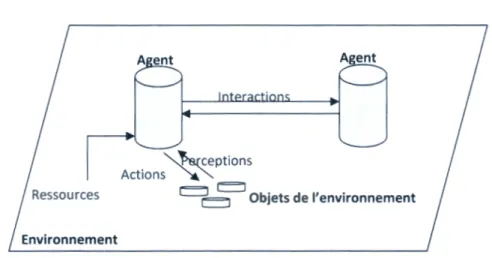
Le système multi-agents est un système composé des éléments suivants :
• Un environnement, c'est à dire un espace disposant généralement d'une métrique.
• Un ensemble d'agents, qui représentent les entités actives du système.
• Un ensemble d'objets. Ces objets sont situés, c'est à dire que, pour tout objet, il est
possible, d'associer une position dans l'environnement. Ces objets sont passifs, c à d
qu' 'ils peuvent être perçus, crées, détruits et modifiés par les agents.
• Un ensemble de relations qui unissent les objets et les agents entre eux.
• Un ensemble d'opérations permettant aux agents de percevoir, produire, consommer, transformer et manipuler les objets.
• un ensemble d'opérateurs chargés de représenter l'application de ces opérations et la réaction du monde à cette tentative de modification. [14]
. ""'~ceptions
Actions ~~
~~~Objets
de l'environnement EnvironnementFigure II.3.1. Représentation d'un système multi-agent
3.2.
concept d'agent
Le terme agent est très souvent utilisé, notamment en IA. Cependant, il n'existe pas une définition unique de ce terme. De nombreux articles ont proposé des définitions. [15]
3.2.1.
Définition
On appelle agent une entité physique ou virtuelle
./ qui est capable d'agir dans un environnement,
./ qui peut communiquer directement avec d'autres agents,
./ qui est mue par un ensemble de tendances (sous la forme d'objectifs individuels ou d'une fonction de satisfaction, voir de survie, qu'elle cherche
à
optimiser),./ qui possède des ressources propres,
./ qui est capable de percevoir (mais de manière limitée) son environnement,