J
OURNAL DE
T
HÉORIE DES
N
OMBRES DE
B
ORDEAUX
J
EFFREY
S
HALLIT
Automaticity IV : sequences, sets, and diversity
Journal de Théorie des Nombres de Bordeaux, tome
8, n
o2 (1996),
p. 347-367
<http://www.numdam.org/item?id=JTNB_1996__8_2_347_0>
© Université Bordeaux 1, 1996, tous droits réservés.
L’accès aux archives de la revue « Journal de Théorie des Nombres de Bordeaux » (http://jtnb.cedram.org/) implique l’accord avec les condi-tions générales d’utilisation (http://www.numdam.org/conditions). Toute uti-lisation commerciale ou impression systématique est constitutive d’une infraction pénale. Toute copie ou impression de ce fichier doit conte-nir la présente mention de copyright.
Article numérisé dans le cadre du programme Numérisation de documents anciens mathématiques
Automaticity
IV:Sequences, Sets,
andDiversity
par JEFFREY SHALLIT
RÉSUMÉ. Dans cet article nous étudions la
complexité
de lade-scription
(i)
de suites sur unalphabet
fini et(ii)
de sous-ensembles de l’ensemble N des entiers naturels.Soit
(s(i))i~0
une suite sur unalphabet
fini 0394. Nous définissonsla k-automaticité de s, notée
Ask(n),
comme leplus petit
nombrepossible
d’états d’un automate déterministequi,
pour tout i telque
0 ~ i ~
n,prend l’expression
de i en base k comme entréeet calcule
s(i).
Nous donnons desexemples
de suitesqui
ont unegrande
automaticité dans toutes les basesk;
parexemple
nous montrons que la k-automaticité de la fonctioncaractéristique
des nombres
premiers
satisfaitAsk (n)
=03A9(n1/43)
pour tout k >2,
rendant ainsiquantitatif
le théorèmeclassique
deMinsky
etPapert
suivantlequel l’ensemble
des nombrespremiers exprimés
en base 2 n’est pas
régulier.
Nous donnons des
exemples
de suites dont la k-automaticitéest
petite
dans toute base, ainsi que desexemples
de suites dontla k-automaticité est
petite
dans certaines bases etgrande
dans d’autres. Nous obtenons aussi des bornes pour l’automaticité decertaines suites
qui
sont despoints
fixesd’homomorphismes,
parexemple
les mots infinis de Fibonacci et de Thue-Morse.Enfin nous définissons un concept
voisin, appelé diversité,
et nous donnons desexemples
de suites ayant une diversité élevée.ABSTRACT. This paper studies the
descriptional complexity
of(i)
sequences over a finite alphabet; and(ii)
subsets of N(the
naturalnumbers).
If
(s (i )) i ~0
is a sequence over a finitealphab et 0394,
then we definethe
k-automaticity of
s,Aks(n),
to be the smallestpossible
numberof states in any deterministic finite automaton
that,
for all i with0 ~ i ~ n, takes i
expressed
in base k asinput
and computess(i).
We
give
examples
of sequences that havehigh automaticity
in all basesk;
forexample,
we show that the characteristic sequence ofthe
primes
hask-automaticity
Aks(n) =
03A9(n1/43)
for allk ~ 2,
thus
making
quantitative
the classical theorem ofMinsky
andPapert
that the set ofprimes
expressed
in base 2 is notregular.
Research supported in part by a grant from NSERC. Manuscrit regu le 5 avril 1996.
We
give examples
of sequences with lowautomaticity
in allbases
k,
and lowautomaticity
in some bases andhigh
in others.We also obtain bounds on the
automaticity
of certain sequencesthat are fixed
points
ofhomomorphisms,
such as the Fibonacciand Thue-Morse infinite words.
Finally,
we define a related concept calleddiversity
andgive
examples
of sequences withhigh diversity.
1. Introduction and Definitions
In this paper, I
study
thedescriptional complexity
of(i)
sequences overa finite
alphabet;
and(ii)
subsets of N(the
naturalnumbers).
In
1972,
Cobham[5]
introduced the notion of what is now called ak-automatic sequence.
(In
theliterature,
one can also find the termsk-recognizable
sequence and uniformtag
sequence.)
Roughly speaking,
asequence over a finite
alphabet
is k-automatic if andonly
ifs(i)
is a finite-state function of the base-k
representation
of i.However,
most sequences are not k-automatic for any k. Instead ofsimply
saying
that a sequence is notk-automatic,
we can measurequanti-tatively
how "close" a sequence is tobeing
k-automaticusing
theconcept
of
automaticity
studied inprevious
papers of the author and co-authors[26,
27, 20,
10].
In addition to its evident intrinsicinterest,
automaticity
hasproved
useful inobtaining
nontrivial lower bounds incomputational
complexity
theory;
see[7,
8, 16,
17].
More
formally,
define a deterministic finite automaton withoutput
(DFAO)
M to be a6-tuple,
(Q, E, 8, qo, 0, T),
whereQ
is a finite set ofstates, E is a finite
input alphabet,
qo is the start state, and A is a finiteoutput
alphabet.
Themap 8 : Q
x E -~Q
is called the transitionfunction,
and is extended in the obvious way to a map 8 :Q
x E* 2013~Q.
The mapr :
Q -~
A is theoutput
function. Oninput
w EE*,
the machine Moutputs
thesingle
symbol
r(8(qo,w)).
For more on theseconcepts,
see, forexample,
[15].
Let k be an
integer >
2 and defineEk
={0,1, ... , k-l~.
If w EEk,
thenby
I mean w evaluated as a base-kinteger,
thatis,
if w = wlw2 ... wv,.,then = If n > 0 is an
integer,
thenby
(n)k
I meanthe default
base-k representation
of n - thatis,
one notcontaining
leading
zeroes. Note that
(O)k
= e, theempty
string.
Suppose
is a sequence over the finitealphabet
A. If there existsa DFAO M such that for all i >
0,
we haves(i)
=r(8(qo,
w R))
for allw E
Ek
such that[w]k
=i,
then the sequence is said to beawkward definition results from the
problem
of"leading
zeroes"input,
andour convention that the machine M reads the
input
numberstarting
withthe least
significant digit.
Here is one alternate definition of k-automatic sequences. Define the
k-fiber of the sequence a to be
Then is a
regular
set for all a E Ll if andonly
if the sequenceis k-automatic.
Another alternate definition of k-automatic sequences can be
given
in terms of a set called the k-kernel. Let(s(n))n>o
be a sequence over a finitealphabet.
The k-kernel of which we denoteby
K:,
is defined asfollows:
Eilenberg
[9,
Proposition
3.3,
p. 107]
proved
that a sequence is k-automaticif and
only
if its k-kernel is finite.Given a sequence we can define its
k-automaticity
asfollows: is the smallest
possible
number of states in any DFAO M =(Q, E,
ð,
such that for all i with 0 i n, we haves (i)
for all u~ E
~~
with[w]k
= i. Weemphasize
that theautoma-ton is fed with the
digits
ofi,
starting
with the leastsignificant digit.
This convention isactually
important
tospecify,
since it is known that there arelanguages
of lowautomaticity
whose reversal hashigh
automaticity;
see[10].
There is another way to define
k-automaticity.
Suppose
we define then-truncated k-kernel of the sequence s, as follows:
The n-truncated k-kernel consists of finite sequences. Call two such
se-quences v, w E n-dissimilar if there exists a
position j
for whichboth
v(j)
andw ( j )
are defined andv(j)
~
w(j). (Note
that under thisdefinition,
if v is aprefix
of w, then v and w aresimilar.)
Then isdefined to be the maximum number of
pairwise
n-dissimilar sequences inK~ (n) .
It is not hard to see that this definition is identical to theprevious
one; see
[27].
Note that the condition m(n -
a)/k’
isequivalent
tokim
+ a n; in otherwords,
the variable that is boundedby
n is not mbut the "true" variable
kim
+ a.The
following
basic results onautomaticity
are easy to prove[27]:
(b)
A~ (n)
=0(1)
if and only if s is k-automatic;
(c)
There exists an absolute constant c such thatif
s is notk-automatic,
then
As (n) >_
c logk n for infinitely
many n.(d)
For any sequence s we have =n) .
As
parts
(b)
and(c)
of this theoremshow,
if a sequence is notk-automatic,
then itsk-automaticity
must begreater
thanc logk n
infinitely
often. Thissuggests
studying
sequences that are notk-automatic,
but which are "as close aspossible"
to k-automatic. We say that a sequenceis
k-quasiautomatic
if =0(log n).
We then have thefol-lowing
theorem,
whoseproof
is easy and is omitted:PROPOSITION 2. A sequence is
k-quasiautomatic if
andonly if
itis
ke-quasiautomatic f or
all e > 1.So far we have discussed the
k-automaticity
of sequences, but the sameterminology
can be used for sets ofnon-negative integers.
We say a set S C N is k-automatic if its characteristic sequence is k-automatic.Similarly,
if S is a set, thenby
AS (n)
we meanAxs
(n).
2. Classical sets with
high automaticity
in all basesIn this
section,
we examine two classical sets(the
primes,
the square-freenumbers)
and show that their characteristic sequences havehigh
k-automaticity
(that
is,
Q(n")
for some e >0)
in all bases k > 2.(By
f
=0(g)
we mean there exist
positive
constants c, no such thatf (n) > cg(n)
for alln >
no . )
For theprimes,
our results can be viewed asmaking
quantitative
the classical result of
Minsky
andPapert
[19]
that theprimes
expressed
inbase 2 cannot be
accepted
by
a finite automaton.Our method is based on the
following
useful lemma:LEMMA 3. Let
(s(i))i>o be a
sequence over afinite alphabet A,
and supposethat there exists a constant d such that
for
all r, a, b with r >2,
1a, b
r,a ~ b,
andgcd(r, a)
=gcd(r, b)
=1,
there exists anon-negative
integer
m =0(rd)
such thats(rm
+a) ~
s(rm
+b).
Thenf or
2,
where theimplied
constant in thebig-Q
does notdepend
on k.Proof. Since m =
0(rd),
there exists a constant c such thatm ~ crd -1
for all r > 2. Let i =
L(10gk n -
logk
c)/(d
+ ThenPut r =
k’.
It follows that there exists m such thats(kim
+b).
However,
kim
+ a1~i
= c .and the same bound holds for It follows that the two
subsequences
~s(k~t + a) )t>o
and are n-dissimilar. Sincea, b
werearbitrary
integers
relatively
prime
to r, we know that there are at leastcp(ki)
pairwise
n-dissimilar sequences, where cp is Euler’s
phi-function.
By
[21,
Theorem15],
we know thatp(n) >
n/(5loglogn)
for n > 3.Hence
Thus
As (n) _
We first examine the
automaticity
of the characteristic sequence of theprimes.
We need thefollowing
lemmas.LEMMA 4. For all x > 1 we have
ez/3,
where theproduct is
over
primes
only.
Proof. Let
~9(x) _
log p,
where the sum is overprimes
only.
We knowthat
t9(x)
1.000081x for x > 0[22,
p.360],
and .84x 101[21,
Theorem10].
It follows thatlOg p
> 1.68x -1.000081x >x~3
for x >101/2.
Now it iseasily
verifiedby
computer
or hand calculationthat
logp
>X13
for 1 x101/2.
It follows that > for all x > 1.
LEMMA 5. Given
integers
k, l
> 1 withgcd(k, l)
=1,
there exists aprime
p = km + 1 with m =
O(max(k,I)11/2).
The constant in thebig-0 is
independent of k
and l .Proof. Choose x =
max(1,I/k,310gl).
Then from theprevious
lemmawe have so there exists a
prime
qfl
with xq
2~.Now q > so
kq > l,
and = 1. Henceby
Heath-Brown’sversion of Linnik’s theorem
[14],
there exists aprime p =- 1
(mod kq)
with p =
Q((~q)11/2).
Sinceq
2~ = we havep =
O(max(111/2, (~ log l)11/2’ ~11/2)),
Hence m =
(p - l)~~
=O(nlaX(lll/2~-1’ ~9/2(lOgl)11/2)’ ~9/2)’
and theresult follows.
LEMMA 6. Given
integers
r,a,b
with r >_
2,
gcd(r,a) =
gcd(r, b) -
1~
1 ~
a, b
r, anda ~ b,
there exists m =O(r165/4)
such that rm + a isProof. We use a trick
suggested
by
papers of Hartmanis and Shank[12]
and Allen
[1].
By
Heath-Brown’s version of Linnik’s theorem[14],
there exists mo =0(r9/2)
such that p =rmo + a is a
prime.
Define q = rmo + b. Thenq = If q is
composite,
we’redone,
and mo= ~ (r9 /2 ) .
Otherwise,
assume q is
prime. Now,
in Lemma5,
take k =qr and 1 =
qr + p. Then
there exists mi =
0((qr
+p)11/2) = O(r143/4)
such that(qr)ml
+(qr
+p)
is
prime.
However, t
=(qr)ml
+(qr + q)
iscomposite,
since q I t
andq t.
Take m =
qml + q + mQ. Then m =
0(rls5/4).
THEOREM 7. The set P
o f prime
numbers hask-automaticity
~ (nl/43 )
for
allintegers
l~ > 2.Proof. Combine Lemmas 3 and 6.
We note that the constant
1/43
in Theorem 7 is notoptimal. Indeed,
theconstant
11/2
in Lemma 5 is almostcertainly
notoptimal. Wagstaff
[31]
has
provided
a heuristic model thatpredicts
that the leastprime
congruent
to 1
(mod k)
is If thisprediction
weretrue,
itwould
improve
the constant1/43
in Theorem 7 to1/(2
+ E) .
We now turn to
providing
a lower bound on thek-automaticity
of thesquarefree
numbers. Recall that a number n is said to besquarefree
ift21n
for all
integers t
> 1.LEMMA 8. Let
defined
asfollows:
Then
for
all e >0,
andr, a, b
such that r >2, 1
a r, and 0 b rwith
gcd(a,r)
squarefTee
anda :0 b,
there exists an m =O(r13/9+E)
suchthat rm + a is
squarefree
and rrri + b is notsquarefree.
Proof. Let q be the least
prime
notdividing
rib -
Sincerib - at I
r2,
by
theprime
number theorem we have q =O(logr2)
=O(logr).
Nowrk + b - 0
(rrzod
qz)
if andonly
if k =(mod
Let c be such that0 c
q2
and c -(mod
q 2).
Consider the arithmeticprogression
We have
gcd (r q 2, rc
+a)
issquarefree,
because anyprime
divisor ofrq2
and rc + a must be a divisor of r orq2.
implies
t
a,
and we knowgcd(r, a)
issquarefree by hypothesis.
On the otherhand,
rc + a = 0(mod q)
implies
that rc m -a(mod q).
But rc - -b(mod q),
Then, by
a result of Heath-Brown[13],
there exists an mo =O(r13/9+E)
such that
(rq2)mo+(rc+a)
issquarefree.
Take m =q2mo +c.
Then rm+ais
squarefree,
but rm + b is divisibleby
q2.
THEOREM 9. The set S
of
squarefree
numbers hask-automaticity
S~ (n2~5 )
for
all k > 2.Proof.
Apply
Lemma 3 with d= 13/9
+6. ’Again,
the constant2/5
in Theorem 9 is notoptimal.
3. A set with low
automaticity
in all basesIn this section I
give
anexample
of a sequence that isk-quasiautomatic
for all
k 2::
2.THEOREM 10.
Define
a(l)
=1,
anda(i
+1)
=a(i)
+for i >
1. Then the set A =~a(i) : i >
notk-automatic,
but isk-quastautomatic
f or
all k > 2.The sequence
(a(i))
begins
1,3,39,331815,114126085737676800331815,...
Proof.
First,
we note thefollowing
observation.Suppose
there exists aninfinite
string
w = *over
Ek
={0,1,... , ~ 2013 1}
such that allbut
finitely
many members s of a set S have the"prefix property",
thatis,
(s)’
is aprefix
of w. Then =O(logn).
To seethis,
note that inthis case we can write S =
Sl
US2,
whereS,
is finiteand 82
has theprefix
property.
To build an automaton thataccepts
all the base-krepresentations
of elements of
82 n
~0, n~,
wesimply
create a linear chain ofnodes,
withtransitions between them labeled with the
symbols
of w. Theaccepting
states
correspond
to the members ofS2,
and of course we need asingle
deadstate in addition to handle the other transitions. The
resulting
automatonhas
1092 n + 0 (1)
states.Since
Sl
isfinite,
we canaccept
it with a finite automaton. The resultnow follows because we can
accept
Sl
US2
using
a directproduct
construc-tion.
The construction of the sequence should now be clear. For bases
k >
2,
the sequence has theproperty
that(a(i))’
is aprefix
of(a(i +
1))~
provided i
> 1~ -1. Hence the observation of theprevious
twoparagraphs
applies,
and theautomaticity
of A isO (log n)
for all k > 2.Note,
however,
that the constant in the
big-0 depends
on k.To show that A is not k-automatic for any
k,
it suffices to show that= oo. But this
follows,
since from the recurrence we have4.
Automaticity
of fixedpoints
ofhomomorphisms
Let cp
be ahomomorphism
from A* to A*. If there is asymbol
a E 0such that
cp(a)
= ax for some x EA*,
thenis a fixed
point
of p; thatis,
cp(y)
=y. If further cp is
nonerasing
(i.e.,
p(b)
~
E for all b EA),
then y is infinite. IfIcp(b)1
= k for all b EA,
then ~p is said to be k-uniform. A 1-uniform
homomorphism
is called acoding.
A well-known theorem of Cobham[5]
states that is theimage
(under
acoding)
of a fixedpoint
of a k-uniformhomomorphism
if andonly
if is k-automatic.A natural
problem
is to determine theautomaticity
of fixedpoints
of non-uniformhomomorphisms.
Inparticular,
are there fixedpoints
ofhomo-morphisms
which arequasi-automatic,
but not automatic? Thisquestion
was raisedby
the author in 1992 in the context of the fixedpoint
of thehomomorphism
1 -121;
2 - 12221. The sequence(tn)
and itsrelationship
to the classical Thue-Morse sequence was studiedby
Alloucheet al.
[2].
Computation
strongly
suggests
that(tn)
is2-quasiautomatic.
Forexample,
= for 0 n1864134,
but not for n = 1864135.Although
we are notyet
able to prove the2-quasiautomaticity
of(tn),
itis
possible
to prove that it is not 2-automatic[24].
(This
last result was,according
to J.-P. Allouche(personal communication),
alsoproved by
M.Mkaouar.)
We now
give
threeexamples. First,
we exhibit ahomomorphism
whosefixed
point
is2-quasiautomatic,
but not 2-automatic.Next,
wegive
aho-momorphism
whose fixedpoint
is2-automatic,
but notk-quasiautomatic
for any odd k.
Finally,
we use somesimple
theorems ofDiophantine
approximation
to exhibit ahomomorphism
whose fixedpoint
is notk-quasiautomatic
for any k > 2.THEOREM 11. Let =
cba,
= aa, and = b. Let(si)i>o
be thefixed
point
of
’Pbeginning
with c. Let X =f 2i
+ j : j >
0~.
Then(a)
so = cand si = b
if
andonlyifi E X;
(b)
(si)i>o is
not 2-automatic.(c)
2-quasiautomatic.
For
part
(b),
it sufhces to show that L =F2 (s, b)
is not aregular
set. It is easy to see thatNow a routine
argument
using
thepumping
lemma[15]
completes
theproof.
Finally,
forpart
(c),
it suffices to construct an automaton withoutput
with0(log
n)
states thatgenerates
the terms of the sequence(si)
correctly
for all i n. We sketch the construction of such anautomaton,
leaving
thedetails to the reader. Let
E:5n
= If L is alanguage,
we say thatL’ is an nth-order
approximation
to L if L flE:5n
= L’ n~~n.
The basic idea of our construction is that it suffices to concentrate onLl
=~’2(s,
b)R
and create an automaton
accepting
a(1
+hog2
nJ )th
orderapproximation
to
LR.
This is easy, sincestrings
inLR
begin
with a short sequence of bitswhich are followed
by
many zeroes and then a 1.The state set consists of four
parts.
The firstpart
is A =~qw : w
E(0
+ Thispart of the
automaton forms abinary
treethat can handle all
possible
strings
oflength
[log2 log2 nJ
+ 1. Thetran-sitions between states in the first
part
aregiven by
8(qw, e) =
qwe forIwl :5
Llog2log2 nJ
and e E{0?1}’
Theoutput
function for the statesin A is
given by
= c,r(qw)
= b ifX,
and = a for allother w.
The second
part
of the automaton consists of a linear chain ofstates,
B =
fpi :
0 ’L’092
The transitions between states in the secondpart
aregiven by
b(pz, 0)
= pi-i for 2 ihog2
n ] ,
I
b(pl,1)
= po, and6 (po, 0)
= po. Theoutput
function for these states is = a for i~
0,
and
r(po)
= b.The third
part
of the state set is C =fp’ :
0 iL’092
a copy ofB. The
output
function for these states isr(p~)
= b for all i.The fourth and final part consists of a
single
dead state d. We setb(d, e)
= d for e E~0,1~,
andT(d)
= a.The start state is qe. We leave to the reader the task of
specifying
the connections between the different groups of states,observing
that transi-tions6(qw, 0)
forL’092
log2 nj
+ 1 that are notself-loops
go to a statein C if
[wR]2
EX,
and otherwise go to a state in B. As anexample,
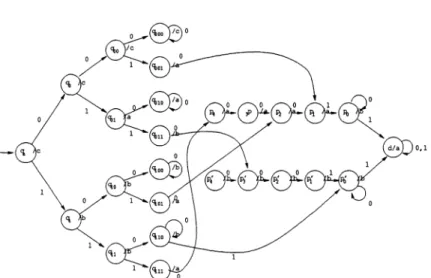
the machine in
Figure
1computes
(si)
correctly
for all i28.
The total number of states needed isIAI
+IBI
+ 16 log2
n.Next,
we exhibit ahomomorphism
whose fixedpoint
is2-automatic,
buthas
high k-automaticity
for all odd k.Define
~p(0)
=01;
p(1)
=00,
and consider the fixedpoint
(p(i))i>o
starting
with 0. It is easy to see thatp(i)
=v2(i
+1)
mod2,
wherev2(n)
FIGURE 1. Automaton
computing
s(i)
for 0 i 256. Theinput
is the base-2expansion
ofi,
starting
with the leastsignificant
bit. Theoutput
iss(i).
The states are labeledwith the name of the
state,
followedby
aslash,
followedby
theoutput
associated with that state. All unmarked transitions go to the deadstate,
labeledd/a.
We first
give
twosimple
lemmas:LEMMA 12. Let be a sequence over a
finite
alphabet A,
andsup-pose that there exists a constants d such that
for
allr, a, b
with r >2,
0 a, b r, and
a ~
b,
there exists anon-negative integer
m =0(rd)
suchthat
s(rm
+a)
s(rm
(
+b) .
Then =f2(nl/(d+l)
k
for
all k>
2,
s
)
I )
J-where the
implied
constant in thebig-Q
does notdepend
orc k.Proof.
Exactly
the same as theproof
of Lemma 3.LEMMA 13.
Suppose
r is odd and 1 a b r. Therc there exists m suchthat 0 m 4r and
v2 (rm
+a) fl v2 (rm
+b) (mod
2).
Proof. Let b - a =
2C .t,
where t is odd. Let m -(2c+l-b)r-l
(mod
2~+2);
the definition is
meaningful
since r is odd. Then rm+b ==(mod
2~+2),
sov2 (rm
+b)
= c + 1. On the otherhand,
Since t is
odd,
we have +a)
= c. Now 2cr, so
2c+2
4r,
andNow we can state and prove our theorem on the
k-automaticity
ofTHEOREM 14.
If
p(i)
=v2(i
+1)
mod2,
then is 2-automatic.If
k > 3 is
odd,
thenA(n)
=P(nl/2 Ik)
pProof. The fact that p is 2-automatic follows from the fact that the
defining
homomorphism p
is2-uniform;
see[5].
To
get
theautomaticity
bound for oddl~,
simply
combine Lemmas 12 and 13.As a
corollary,
we can obtain a lower bound for theautomaticity
of theThue-Morse sequence in all odd bases.
Let sk
(i)
denote the sum of thedigits
of i when
expressed
in base J~. Then the Thue-Morse sequence is defined as follows:t(i)
=s2 (z)
mod 2.It is easy to see that the Thue-Morse sequence is 2-automatic.
However,
we have thefollowing
THEOREM 15. Let k > 3 be an odd
integer.
Then =O(nl/4/k1/2).
Proof. Our
proof
is based on thefollowing
identity,
which is well-knownand
easily
proved
by
considering
the base-2expansion
of i + 1:Taking
this modulo2,
we obtainwhere p is the function defined in Theorem 14.
Let
M~ _
be a DFAOcomputing
t(i)
for all i with0 i n, and assume that
~In
has states. Now consider andcreate a
slightly
modified automaton M’ =(Q’, ~~, b’, qo, a, T’)
such thaton
input w
with[W’lk
=i,
M’computes
the shifted sequencet(i
+1)
for0 i n. This can be achieved as follows: define
Q’
=Q
x~0,1},
wherethe second
component
of every state denotes a carry to bepropagated,
and letqo
=[qo,1].
DefineAlso define
r’([~0])
=r(q)
andT’([~l])
=T(S(q,1)).
We leave it tothe reader to
verify
that the construction does indeedcompute
the shiftedWe now
implement equation
(2)
by
forming
the directproduct
of theautomata and
M’,
andusing
anoutput
function thatcomputes
thefunction
p(i)
correctly
for all i with 0 i n. It follows thatSince
~p (n)
=O(n1/2/k),
the desired result follows.We now turn to the third
problem:
finding
a fixedpoint
of ahomomor-phism
ofhigh
automaticity
in all bases. Our methods are based on thetheory
ofDiophantine approximation
[4]
and Sturmian words(also
called characteristic words or Christoffelwords).
For a survey on Sturmianwords,
see[3].
First,
we introduce some notation.If a is a real irrational
number,
we canexpand
ituniquely
as aninfi-nite continued
fraction, a
=[ao,
a1, a2, ...].
The ai are called thepartial
quotients
of a. We say thepartial
quotients
of a are boundedby
B if ai B for all 2 > 1.(For
a survey on boundedpartial quotients,
see[25].)
We define
pn/qn
=[ao,
a1, ... ,
an],
and callpn/qn
the nthconvergent
to a.We define
a~,
the nthcomplete
quotient,
to be an+ 1, ...] .
We define~a~
= a - the fractionalpart
of a, and =min(a -
[a] - a),
the distance to the nearest
integer.
We then have
LEMMA 16. Let a be an irrational real
number,
0 a1,
withpartial
quo-tients
bounded by
B. Let the numbers.0,
~a~, ~2a~, ... , Ital, 1
bearranged
inascending
order and let them be labeled ,Pt+t. ThenProof. Let be the
convergents
to a. It is a consequence of thethree-distance
theorem(also
called Steinhaus’conjecture)
thatexample,
[29,
30,
28].)
Now we knowand the result follows.
Our next lemma is a version of the
inhomogeneous
approximation
theo-rem. Unlike the traditional versions of this
theorem,
therequirement
that a has boundedpartial quotients
allows us to bound the size of theintegers
that effect the desiredapproximation.
LEMMA 17. Let a be an irrational real
numbers,
0 a1,
withpartial
quotients
boundedby
B. Let0 ,Q
1 be a real number. Thenfor
allN > 1 there exist
integers
p, q with 0(B
+2)N2
such thatN
Proof.
By
Dirichlet’s theorem(see,
e.g.,[4,
TheoremI]),
there existintegers
n, r with 1 n N and 0 r
N,
such thatrl [
1/N.
Choose ksuch that N qk, where are the
convergents
to a.Then,
as in theprevious
theorem,
Without loss of
generality,
assume na - r >0,
and setp’ =
L8/(na - r) J .
Then 0
p’
(B
+2)N,
and 0# -
(na - r)p’
1/N.
HenceIp’na
The next lemma shows that Sturmian sequences
corresponding
to real numbers with boundedpartial
quotients
have theproperty
that for allpairs
ofsubsequences
of the form withc ~ d,
there is a smallwitness i = m that shows that these
subsequences
are different.LEMMA 18. Let 0 a 1 be an 2rrational reat number with
partial
quo-tients bounded
b y
B.Define
the Sturmian wordby
8i =L(i
+for i
> 1. Let r > 2 be aninteger.
Thenfor
allintegers
c, dwith 0
c, d
r,c ~
d,
there exists aninteger m
with 0 m4(B+2)3r3
such that 8rm+c
7-
Proof. We use the "circular
representation"
for intervals in[0, 1),
identify-ing
thepoint
0 with thepoint
1,
andconsidering
eachpoint
modulo 1.Thus,
for
example,
the interval we write as(2/3,1/3)
isreally
(2~3,1)
U(o,1/3).
See,
forexample,
[11,
§3.8,
§23.2].
It is easy to see
that si
= 1 -{ia~
E[1 - a,1).
Hence if we could find m such thatit would follow that
s,,,+, 0
NowWe have +
A(Id)
1,
where p isLebesgue
measure; hence these intervals have nontrivial intersection wheneverc #
d. Infact,
theendpoints
of these intervals areprecisely
of the form1-ia}
for some i with 0 i r.Let po, pi , ... , denote the
points 0,
fal, ~2a~,
... ,arranged
inincreasing
order. It follows that andby
Theorem16,
we know thisquantity
is bounded belowby
B 12 r
(B+2)r
Now let m’ be the
midpoint
of the intervalI, n
Id.
To find m withSrm+d, it suffices to find
integers
m, t
withBy
a folklore result(see,
e.g.,[23]),
since a haspartial quotients
boundedby B,
we know that ra haspartial
quotients
boundedby
r(B
+2).
By
Theorem
17,
it follows that such an m exists with mr(B
+2)(2(B
+THEOREM 19. Let 0 a 1 be an irrational real number with bounded
partial
quotients.
Let si =L(i
+1)aj - LiaJ
for
i _> 1. Thenfor
allk >_ 2,
the
k-automaticity of
the sequence(Si)i21
isO(nl/4/k).
Proof. Combine Lemmas 12 and 18.
It now follows from this
result,
forexample,
that the fixedpoint
of thehomomorphism
1 ~10,
0 - 1 is notk-quasiautomatic.
This followsbecause this fixed
point
can be obtained as a Sturmian sequenceby setting
a =(J5 -
1)/2.
It is known for which a thecorresponding
Sturmiansequence is the fixed
point
of ahomomorphism;
see[6].
5.
Diversity
As we have seen in Section
1,
a sequence is k-automatic if andonly
if itsk-kernel
(defined
inEq.
(1))
is finite. The mostspectacular
way a sequence can fail to be k-automatic is for all the sequences in the k-kernel to bedistinct;
we call such a sequencestrongly
Results of theprevious
sections
suggest
that theproperty
ofstrong
diversity
and relatedproperties
deserve further
study.
We make the
following
definitions:DEFINITIONS 20. A sequence
weakly
k-&verseif the
p(k)
sub-sequences
gcd(a, k)
=1,1
al~~
are all distinct. Asequence is
weakly
diverseif
it isweakly
k-dzversefor
all 1 > 2. A sequence(s(I))j>o
isif
the ksubsequences
{(s(ki
+0 a
k}
are all distinct. A sequence is diverseif
it is k-diversefor
allk > 2.
A sequence
strongly
k-diverseif
thesubsequences
( (s(k’ . j
+a))i>o :
0 a01
are all distinct. A sequence isstrongly
diverseif
it isstrongly
k-diversefor
all l~ > 2.A
sequence is maximally
diverseif
thesubsequences
+a) )j>o :
0 a
k, 1~ >
1}
are all distinct.The results of
previous
sections can now berephrased
in thelanguage
of
diversity.
In Section 2 we showed that the characteristic sequences ofthe
primes
andsquarefree
numbers areweakly
diverse. In Section 4 weshowed that the sequence
(v2(i
+1))i>o
is k-diverse for all odd1~,
and wealso showed that if a is a real number with bounded
partial quotients,
thenis diverse.
We now
give
anexample
of a sequence that isstrongly
k-diverse fork = 2. Consider the set X =
{2~
+ j : j >
0}
introduced in Theorem11,
and let be the characteristic sequence of this set. Then we have
THEOREM 21. The sequence
strongly
2-diverse.Proof We must show
that,
given
any fourintegers j, k,
a, b0,
0 a2~,
0 b2k,
and(j, a) 54 (k, b),
there exists n > 0 withC23n+a
0
Without loss ofgenerality, assume j k
andif j
=k,
then a b. Let no = and set n =
2noo23_;+a
+ no. Then + a =+ no
2~
+ a =2’
+ i for i = no2~
+ a. Hence C23n+a = 1.It remains to show = 0. To see
this,
it suffices to show thatTo prove the first
inequality,
it suffices to show thatThere are three cases to examine.
(i)
If k= j,
then thisinequality
follows from theassumption
that a b.(ii)
+1,
then we must show a - b + 1 =no2k-l.
Since a
2j
=2k-17
it suffices to show2k-l
no (2~ - 2k-1)
=no2k-l,
which is true since no > 2.
(iii) If k > j
+2,
then we must showl~ - j
+2i
no (2 k - 2~).
Nowl~ - j
2 k
2 k,
and2i
2k -
2 ~2j
provided
2k
> 3 ~2j,
which is true + 2.Adding
theseinequalities,
we find1~ - j
+2i
2 (2k - 2~ )
no (2k - 2j ),
as desired.To prove the second
inequality,
we must showThere are two cases to consider.
(i)
If 1~= j,
we must show b - a2noo2j+a
+ 1. Since b2k,
it sufficesto show
2k
2no + 1 and for this it suffices to takeno > k.
(ii)
If k >j,
then no(2 k -2j)+j-k+b-a
no(2 k -2j)+2 k
(no+1)2 k
Thus it suffices to show
(no
+1)2k
2n°. Chooseno >
2k+r.
Then2 no
provided no >
2,
which itis,
since no > 2 k+l
0We now show the
following:
Proof. Since the set of
pairs
~(1~, a) :
0 a1~, l~ >
1}
iscountably
infinite,
it suffices to show that if(k, a) ~
(1, b),
then the set of sequences for whichs(ki
+a)
=s(li
+b)
for all i > 0 is of measure zero.Let g
= Ifgfb -
a, or if k = l and and
a ~
b,
then the linearprogressions
(ki
+ and +b)j>o
contain no terms at all in common.Therefore the
subsequences
and areindependent
and hence the
probability
thatthey
are identical is 0.Otherwise,
assume 1~ a. In order that(k/g)i - (t/g) j
=(b -
a)/g,
we must have i =(l/g)i’
+io,
and j
= +jo,
for someconstants
io, jo. Since k :A 1,
at least one ofllg, k/g
must be different from1. Without loss of
generality,
assume it is Choose a constantil
~ io;
then the set
contains no terms in common with
Hence the
subsequences
io)
+ andio)
+are
independent,
and so theprobability
thatthey
are identical iszero.
Although
almost all0,1-sequences
aremaximally
diverse,
it is not so easyto prove that any individual sequence has the
maximally
diverseproperty.
We now
give
someexamples
ofmaximally
diverse sequences.Let a be a real irrational number with 0 a 1. Recall the definition
of the Sturmian infinite word from Section 4:
THEOREM 23. All Sturmian sequences are
maximally
diverse.Proof. We must show that
given j, k >
1,
0 aj,
0 bk,
and(j,
a) #
(k, b),
there exists an n > 0 such thatSkn+b-It is easy to see
that sn
=1 4==~~na}
E[1-
a, 1).
Hence it suffices toexhibit n such that
First,
let us consider thecase j
= k. We have In this case, weintersection. Define I =
Ia
nIb;
thenp(1)
> 0. It now suffices to choose n suchthat ~ jna}
E I. Such an n existsby
Kronecker’s theorem(e.g.,
[11,
Theorem
438]).
Second,
let us consider the l~. Without loss ofgenerality,
let usassume j
k. Definep(I),
theprojection
of anordinary
intervalI,
to bep (I )
= EI } .
Thus,
forexample,
p([e,7r))
=[e
-2, ~r -
3).
Consider
Ia,
and let its left andright
endpoints
be t and urespectively.
If h
"wraps
around"0,
then choose u E[l, 2)
so thatp([t, u))
=Ia.
DefineIo
and11
I claim that
p(Ii)
> For ifIa
contained a subinterval of measure> then
7i
=[0,1),
and so =1 >Otherwise,Ia
containsno subinterval of measure so
ti(I,,)
In this case,>
Now + =1. Hence
tc(h)
+ > 1 and soII
andIb
havenontrivial intersection. Let
I,
n 76;
then > 0.By
our definitionof
Io
andI,,
there is an interval13
gIo
such that if13 =
[v, w],
then[kv, kw]
C12.
Also,
since13
g
Io,
it is clear thatUv, jwl
9 1..
Again,
by
Kronecker’s
theorem,
we can find n such thatinal
E13.
For this n wehave ~ jna}
E7~
and~kna}
E12
CIb,
as desired.If a sequence is
diverse,
then we know that for allr, a, b
with0
a, b
r andb,
there exists an m such thatd(rm+a) i= d(rm+ b).
If there is a function
f
such that m =0 ( f (n) ),
thenf (n)
is said to bea
diversity
measure for d. In aprevious
section weshowed,
forexample,
that the
diversity
measure for Sturmian sequencescorresponding
to real numbers with boundedpartial
quotients
is0(r3).
We now show that the
diversity
measure for almost all sequences is low:THEOREM 24. Almost all
binary
sequences have theproperty
thatfor
allr >
1,
andfor
all a, b with 0 a, b r anda ~
b,
there exists m =O(log r)
such that
Srm+a 0
srm+b .Proof.
By
Theorem22,
we may restrict our attention to sequences thatare diverse.
We have
Choose
f (r) - r4log2rl;
thenr~ 21~2~f~r~
=0(r-2).
(Here
f =
0(g)
means
f
=0(g)
and g
=0( f ).)
Thenr~ 21~ 2-f ~r~
converges. Hence
by
the Borel-Cantellilemma,
withprobability
1 at mostfinitely
many of the events of the form(3)
occur. Thatis,
withprobability
1,
the eventV
pairs
(a, b)
3mr 4log2 r~
such that Srm+boccurs all but
finitely
many times. Hence withprobability
1 we have m =0(log r).
Interestingly enough,
I do not know asingle
expticit example
of a diversesequence with
diversity
measure 0 (log n).
6.Acknowledgments.
I thank Mark Turner for
suggesting
the term"diversity" .
DrewVandeth,
EricBach,
and Jean-Paul Allouche read a draft of this paper and mademany useful
suggestions.
I thank the referee for his comments. REFERENCES[1]
D.Allen,
Jr. On a characterization of thenonregular
set ofprimes.
J.Comput.
System
Sci. 2(1968),
464-467.[2]
J.-P.Allouche,
A.Arnold,
J. Berstel, S. Brlek, W.Jockusch,
S.Plouffe,
and B. E.Sagan.
A relative of the Thue-Morse sequence. Discrete Math. 139(1995), 455-461.
[3]
J. Berstel. Recent results on Sturmian words. To appear, Proc. of DLT ’95.Also available at
http :
//www-litp.
ibpfr/berstel/Liaisons/magdeburg.
ps . gz.[4] J. W. S. Cassels. An Introduction to
Diophantine Approximation.
Cambridge
University
Press,1957.
[5]
A. Cobham. Uniform tag sequences. Math.Systems Theory
6(1972),164-192.
[6]
D.Crisp,
W. Moran, A.Pollington,
and P. Shiue. Substitution invariantcut-ting
sequences. J. Théorie Nombres Bordeaux 5(1993),123-137.
[7]
C. Dwork and L.Stockmeyer.
On the power of2-way probabilistic
finite state automata. In Proc. 30th Ann.Symp.
Found.Comput.
Sci.,
pages 480-485.IEEE
Press, 1989.
[8]
C. Dwork and L.Stockmeyer.
A timecomplexity
gap for two-wayprobabilistic
finite-state automata. SIAM J.
Comput. 19
(1990), 1011-1023.
[9]
S.Eilenberg.
Automata, Languages,
andMachines,
Vol. A. AcademicPress,
1974.[10]
I. Glaister and J. Shallit.Automaticity
III:Polynomial automaticity
and context-freelanguages.
Submitted,1996.
[11]
G. H.Hardy
and E. M.Wright.
An Introduction to theTheory of
Numbers. OxfordUniversity
Press, 1989.
[12]
J. Hartmanis and H. Shank. On therecognition
ofprimes
by
automata. J. Assoc.Comput.
Mach. 15(1968),
382-389.[13]
D. R. Heath-Brown. The leastsquare-free
number in an arithmeticprogres-sion. J. Reine
Angew.
Math. 332(1982),
204-220.[14]
D. R. Heath-Brown. Zero-freeregions
for Dirichlet L-functions and the leastprime
in an arithmeticprogression.
Proc. Lond. Math. Soc. 64(1992),
265-338.
[15]
J. E.Hopcroft
and J. D. Ullman. Introduction to AutomataTheory,
Lan-guages, and
Computation. Addison-Wesley, 1979.
[16]
J.Kaneps
and R. Freivalds. Minimal nontrivial spacecomplexity
ofprobabilis-tic one-way
Turing
machines. In B.Rovan, editor,
MFCS ’90(Mathematical
Foundationsof Computer
Science),
Vol. 452 of Lecture Notes inComputer
Science,
pages 355-361.Springer-Verlag,
1990.[17]
J.Kaneps
and R. Freivalds.Running
time torecognize
nonregular
lan-guages
by 2-way
probabilistic
automata. In J. LeachAlbert,
B.Monien,
and M.Rodríguez Artalejo,
editors,
ICALP ’91(18th
InternationalColloquium
on
Automata, Languages,
andProgramming),
Vol. 510 of Lecture Notes inComputer
Science,
pages 174-185.Springer-Verlag,
1991.[18]
D. E. Knuth. The Artof
Computer
Programming,
Vol. III:Sorting
andSearch-ing. Addison-Wesley,
1973.[19]
M.Minsky
and S.Papert.
Unrecognizable
sets of numbers. J. Assoc.Comput.
Mach. 13
(1966), 281-286.
[20]
C.Pomerance,
J. M.Robson,
and J. O. Shallit.Automaticity II: Descriptional
complexity
in the unary case. To appear, Theoret.Comput.
Sci.[21]
J. B. Rosser and L. Schoenfeld.Approximate
formulas for some functions ofprime
numbers. Ill. J. Math. 6(1962),
64-94.[22]
L. Schoenfeld.Sharper
bounds for theChebyshev
functions03B8(x)
and03C8(x).
II. Math.Comp.
30(1976),
337-360.Corrigenda
in Math.Comp.
30(1976),
900.[23]
J. Shallit. Some facts about continued fractions that should be better known. TechnicalReport CS-91-30,
University
ofWaterloo,
Department
ofComputer
Science,
July
1991.[24]
J. Shallit. The fixedpoint
of 1~121,
2 ~ 12221 is not 2-automatic.Unpub-lished
manuscript,
datedSeptember
10, 1992.[25]
J. Shallit. Real numbers with boundedpartial quotients:
a survey.Enseign.
Math. 38
(1992),151-187.
[26]
J. Shallit and Y. Breitbart.Automaticity: Properties
of a measure ofdescrip-tional
complexity.
In P.Enjalbert,
E. W.Mayr,
and K. W.Wagner,
editors,
STACS 94: 11th Annual
Symposium
on TheoreticalAspects of Computer
Sci-ence, Vol. 775 of Lecture Notes inComputer Science,
pages 619-630.Springer-Verlag, 1994.
[27]
J. Shallit and Y. Breitbart.Automaticity
I:Properties
of a measure ofde-scriptional complexity.
To appear, J.Comput.
System
Sci.[28]
N. B. Slater.Gaps
and steps for the sequence n03B8 mod 1. Proc.Cambridge
Phil. Soc. 63(1967), 1115-1123.
[29]
V. T. Sós. On the distribution mod 1 of the sequence n03B1. Ann. Univ. Sci.[30]
S. Swierczkowski. On successivesettings
of an arc on the circumference of acircle. Fundamenta Math. 46
(1958), 187-189.
[31]
S. S.Wagstaff,
Jr. Greatest of the leastprimes
in arithmeticprogressions
having
agiven
modulus. Math.Comp.
33(1979),
1073-1080.Jeffrey
SHALLITDepartment
ofComputer
ScienceUniversity
of WaterlooWaterloo,