Active Subspace Methods in Theory and Practice: Applications to Kriging Surfaces
Texte intégral
Figure



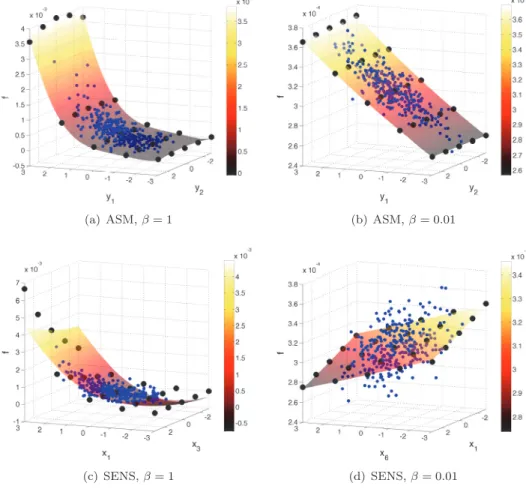
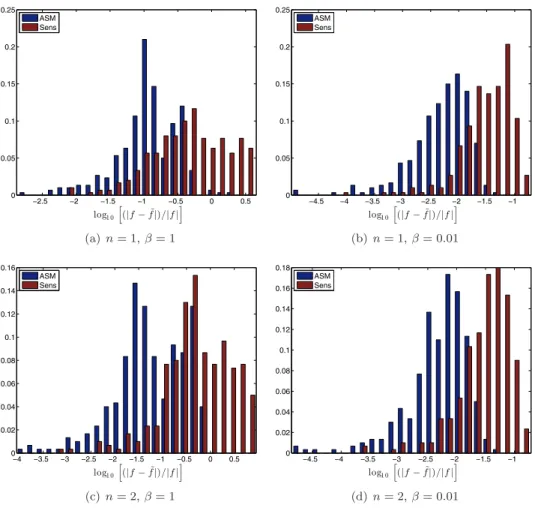

Documents relatifs
Joit¸a [1] in which the authors considered this question and gave the answer for the case of open subsets of the blow-up of C n+1 at a
Nevertheless, there are only few publicly available data generators and none for generating data containing subspace clusters, even though some are used in di- verse subspace
Under the assumption that the state order is a priori known, a new quadratic criterion has been proposed to estimate recursively the subspace spanned by the observability matrix.
An approach for rail monitoring, where eddy current measurements are processed by a subspace approach bor- rowed from the multiple signal classification (MUSIC) method, is
By periodically modulating the coefficient of friction at a constant frequency of 11 Hz, we expected that scanning of the fingertip against the display would induce an SS-EP
Afin d’approcher le comportement dynamique de l’ensemble, les résultats de l’homogénéisation analytique sont injectés dans le data des données pour simuler numériquement des
Moreover, performing a WL simulation on the whole energy range for small lattices, in order to determine the nature of the transition before using the CMES method should be
In this section, we develop a test function plug-in method based on the minimization of the variance estimation in the case of the family of indicator functions for Ψ H.. Actually,
