On the verification of climate reconstructions
14
0
0
Texte intégral
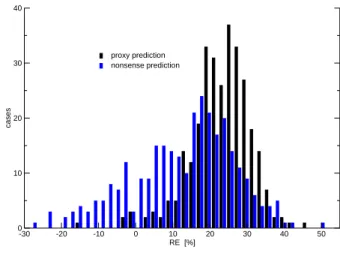
Figure

+4

Documents relatifs
