Policy Evaluation Using Causal Inference Methods
Texte intégral
Figure




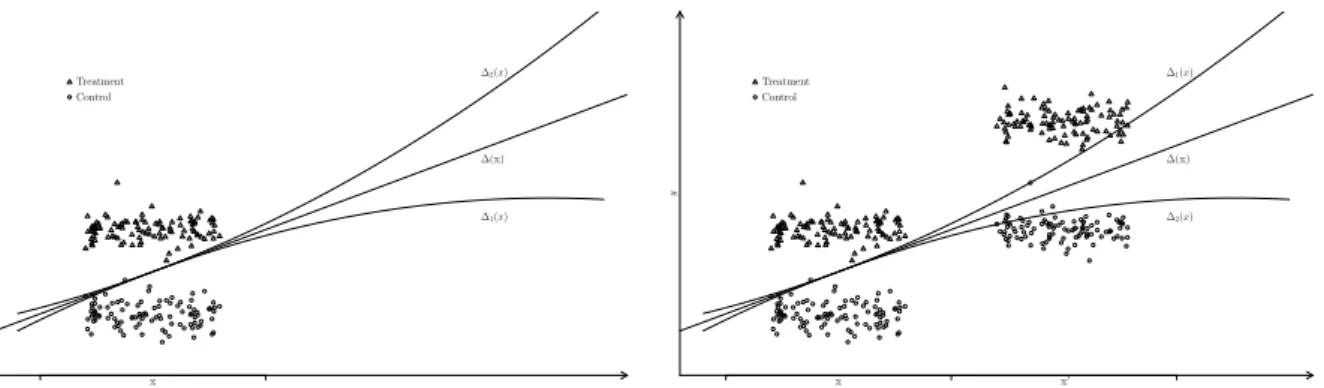

Documents relatifs
With the examples shown above, we have obtained two clear qualitative characteristics of the electron density in Sat- urn’s magnetosphere: 1) The electron density generally de-
(1997) showed that the seasonal cycle of water vapour in the tropical lower stratosphere, which is due to the seasonal cycle of tropical tropopause temperatures (e.g. Mote et
The mass of carbon in the dissolved inorganic carbon reser- voir (DIC) may change as a function of the inputs of DIC from land via rivers, surface runoff and groundwater
Les anticoagulants oraux directs par leur simplicité d’utilisation, leur grande efficacité et sécurité dans cette indication, constituent le traitement de choix
Or, l’individu exacerbé dans ses désirs, ses besoins, sa conscience même, exige toujours plus de lien social, de communication, d’implication au sein du groupe et
Ensuite, baissez vos yeux en direction de votre jambe, qui tremble encore, et là faites comme si vous veniez de comprendre, ayez l’air gênée puis refermez les yeux.. Ce jeu de
ﺔﺟﻣرﺑﻣ رﯾﻏ وأ ﺔﺟﻣرﺑﻣ (. - تارارﻘﻟا ذﺎﺧﺗا بﯾﻟﺎﺳأ ثﯾﺣ نﻣ ) ﺔﯾﻣﻛ وأ ﺔﯾﻔﯾﻛ. ﺔﻌﺑرأ ﻰﻠﻋ مﯾﻘﻟا ﻰﻠﻋ ﺔﻣﺋﺎﻘﻟا ةدﺎﯾﻘﻟا زﻛﺗرﺗ ﺔﯾﺳﺎﺳأ ئدﺎﺑﻣ. ﺎﻬﯾﻟإ نوﻌﺳﯾو
A previously developed pipe-soil interaction model was combined with failure theories to determine the fuzzy factor of safety with uncertainties represented in input data
