Analyses canoniques etlistes d’occurrencesd’espèces
Texte intégral
Figure
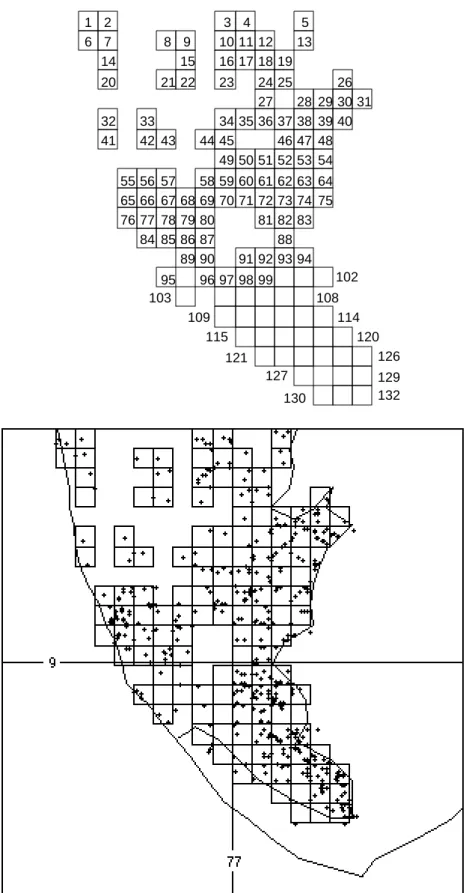
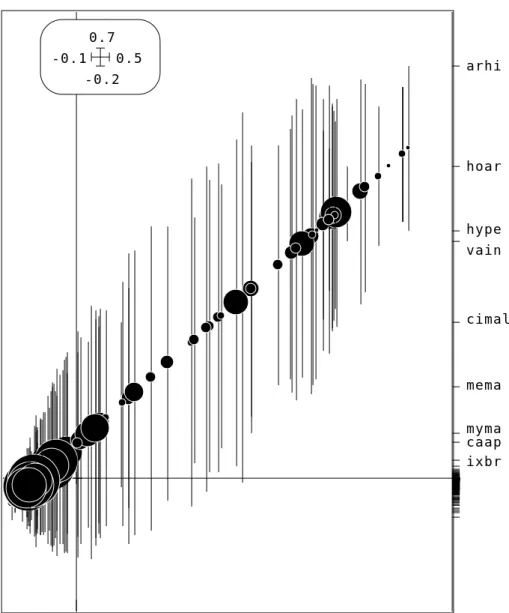
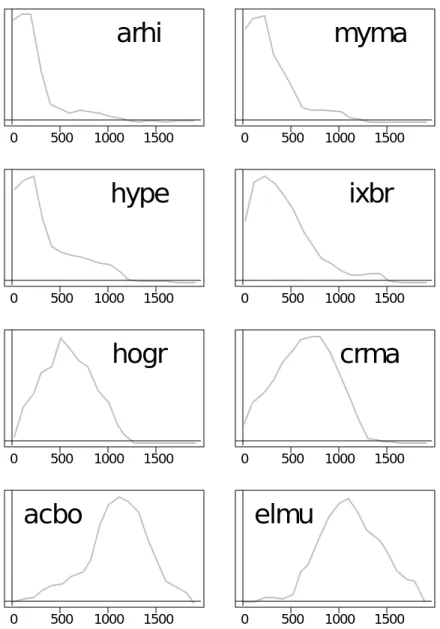

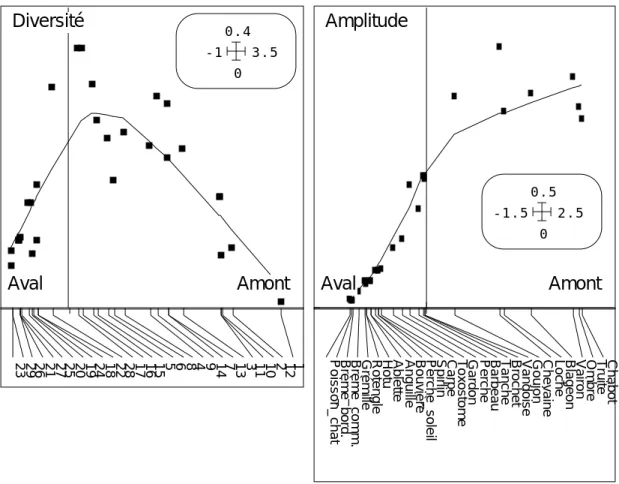
Documents relatifs
alors le critère concorGM de type procruste (toutes les métriques Mi et Nj sont les métriques identité), et les modifications successives des tableaux Xi sont
5) Ecrire l’équation cartésienne de la droite passant par les deux points moyens On trouve ainsi l’équation de la droite de Mayer. On doit remplacer x par 14 pour répondre à
A deux variables, le gradient pointe dans la direction o` u la fonction augmente le plus, et plus il est long, plus la fonction augmente (”en premi` ere approximation”)....
Le cas le plus important que nous mentionnerons est le suivant : les formes ƒ et cp ont leurs coefficients réels*, et il existe une forme du faisceau [*ƒ-+-7^ réduc- tible h la
On trace au jugé une droite D (on peut s’aider du point moyen) en s’efforcant d’équilibrer le nombre de points situés de part et d’autre. Ensuite on détermine par
A l’aide de la calculatrice, déterminer un ajustement affine de z en fonction de x par la méthode des moindres carrés (les coefficients seront arrondis au millième)?. En utilisant
La méthode Sumcor mon- tre une opposition entre la transgression (modalité tout le temps), la transgression conditionnelle (modalité plutôt tout le temps) et le respect
3) Avec la souris, sélectionner le tableau créé, puis, avec un clic droit, créer une liste de points... 4) Cliquer sur la fenêtre graphique afin de pouvoir déplacer l’origine
