Augmenting a Neural Agent with an Oracle
by
Zachery A. Miranda
Submitted to the
Department of Electrical Engineering and Computer Science
in partial fulfillment of the requirements for the degree of
Master of Engineering in Electrical Engineering and Computer Science
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
June 2018
c
2018 Zachery A. Miranda. All rights reserved.
The author hereby grants to M.I.T. permission to reproduce and to
distribute publicly paper and electronic copies of this thesis document
in whole or in part in any medium now known or hereafter created.
Author:
Department of Electrical Engineering and Computer Science
May 24, 2018
Certified by:
Armando Solar-Lezama
Associate Professor
Thesis Supervisor
Accepted by:
Katrina LaCurts
Chair, Master of Engineering Thesis Committee
Augmenting a Neural Agent with an Oracle by Zachery A. Miranda
Submitted to the Department of Electrical Engineering and Computer Science
May 24, 2018
In Partial Fulfillment of the Requirements for the Degree of Master of Engineering in Electrical Engineering and Computer Science
Abstract
In this thesis, I approached deep reinforcement learning agents with the novel idea of augmenting the agent with another neural network called an “Oracle” to gain more insights about the game environment. The Oracle is trained through supervised learning and can be used in various ways with the agent such as a reward shaper or in a pipeline with the agent through which it can transform the original input state into a more enhanced input state with more information. Overall results were not positive as creating a good Oracle can be hard. Creating a better Oracle could possibly display promising results.
Acknowledgments
I would like to thank Yewen (Evan) Pu for the incredible mentorship, ideas, and general assistance that was given to me throughout this thesis. This thesis would not have happened without Evan’s immense help. I would also like to thank Armando Solar-Lezama and Leslie Kaelbling for further thoughts and critiques on the ideas in this thesis. Additionally, I would like to thank my parents, Moises and Dynl Miranda, for all of the support that they gave me throughout my life to enable me to have the opportunity to attend MIT and learn everything that I needed to know in order to write this thesis. Lastly, I would like to thank Seung-Hyun Brianna Ko for all of the support during my late nights working on this thesis.
Contents
1 Introduction 11
1.1 Why use reinforcement learning? . . . 11
1.2 Reinforcement Learning Algorithms . . . 13
1.2.1 Q-Learning . . . 13 1.2.2 Policy Gradient . . . 14 1.3 The Problem . . . 14 2 Game Environments 17 2.1 Mastermind . . . 17 2.2 Zoombinis . . . 18 3 The Oracle 19 3.1 Difficulties in Constructing an Oracle . . . 19
3.2 Binary Cross Entropy Loss . . . 20
4 Using the Oracle 23 4.1 Methods . . . 23
4.1.1 Reward Shaping Oracle . . . 23
4.1.2 State Transformation . . . 24
4.2 Experimental Results . . . 25
5 Conclusion 27
List of Figures
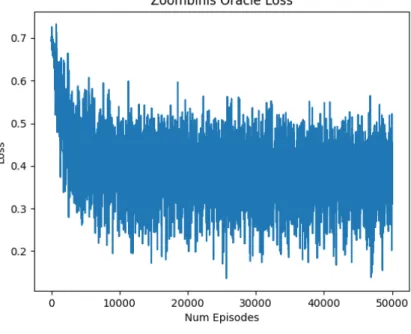
3-1 The binary cross entropy losses for the Oracle in each game after train-ing on random episodes. . . 22
4-1 Performance of DQN Agent with different uses of the Oracle . . . 25 4-2 Accuracy of the Oracle when trained jointly with the agent . . . 26
Chapter 1
Introduction
Reinforcement Learning is a technique in which one trains an agent to solve some sort of task [11]. Much of research uses reinforcement learning in the context of games. Games are great testing grounds for reinforcement learning agents because games are easily interfaced with agents and are environments where agents have many possible actions resulting in many different outcomes. Agents are trained by playing the game and gaining a reward whenever tasks are accomplished, such as winning the game. The performance of an agent is measured in terms of how much reward it can achieve. In this thesis, we use reinforcement learning on various information gathering games. The focus of this thesis is to enhance the performance of the agent through the introduction of an oracle that learns something fundamental about the game.
Chapter two describes the two environments that were used for testing, Zoombinis [1] and Mastermind [6].
Chapter three describes the creation of the oracle and the various difficulties that can be present while trying to create such an oracle.
Chapter four describes the attempted uses of an oracle in improving the agent.
1.1
Why use reinforcement learning?
Many environments can be modeled as Markov Decision Processes (MDPs) in which the agent can exist in various states. Transitions between each of these states can
be accomplished through actions. In each environment there is a goal state that will usually be defined as winning the game. We seek to find an optimal policy, which is an optimal set of actions to advance from any state to the goal state as to maximize the reward.
There is a class of MDPs called POMDPs (Partially Observable Markov Decision Problems) where the actual states that govern the world are not known to the agent [3]. At each time state, the agent will receive some partial observation about the world which can help the agent figure out which state it is in. After each action, the agent will transition to another state with some probability.
A well known example of a POMDP is the Monty Hall problem. The actual state of the world, which is the door that the prize is behind, is hidden from the player. However, each of the observations that the agent receives after each action are based on this state of the world.
In a normal MDP, the optimal policy can be trivial. An example of this is an agent exploring a maze where the agent knows where he is and what the maze looks like. However, making the game partially observable by either not giving the map of the maze to the agent or not allowing the agent to know where he is at that point in time and limiting the size of his visibility can make the game much harder. In POMDPs there is the question of finding the balance between exploration and exploitation. The agent starts out not knowing anything about the world, but as the agent learns more about the world it is usually unclear if it is better to continue to explore or to use what the agent already knows to get the reward. In the maze context with the agent knowing the map but not initially knowing where he is, this can be demonstrated as the agent narrowing down his location to one of two places and trying to figure out his next action. If he is in one place he can either finish the maze in t1 time steps
while if he is in the other place he can finish the maze in t2 time steps, but he will
not gain any information about which place he is in along the way of those time steps and he would have to move in a different direction for t3 time steps to discover his
exact location where t3 < t1 < t2. It is not clear about what is the optimal strategy
In POMDPs, reinforcement learning allows us to let an agent run free within the world and figure out a strategy for gaining the most reward that it can. After many episodes of training, it is possible for this agent to learn an optimal or near-optimal solution. However it is not guaranteed to learn an optimal strategy as the agent could settle on a local maximum reward if it did not get to explore a path that leads to the optimal strategy in training.
1.2
Reinforcement Learning Algorithms
In reinforcement learning, there are two main approaches for solving problems: policy gradient [12] and Q-learning [8]. In this thesis, we used deep reinforcement learning using both of these approaches and these algorithms will be explained in the context of deep reinforcement learning.
1.2.1
Q-Learning
Q-Learning involves using a Q(s, a) function to predict a value associated with each state and action (s, a) pair to evaluate how “good” it is to take a certain action a from a state s. The way that this evaluation occurs is by taking the Q-value to be an estimate of the cumulative reward that the agent will receive after taking action a in state s. With an accurate Q function, the agent’s policy will be choosing the action with the max Q-value from any state that it is in.
The Q function can be approximated using a neural network. After each game is played, the discounted reward at each time step will be compared against the neural network’s predicted Q-value and used to calculate a loss to update the neural network. Often, the loss that is used is the squared error [4]:
E = (Qi− Ri)2
The discounted reward [11] is the reward gained at each timestep (ri) plus the
Ri = ri+ γ ∗ ri+1+ γ2∗ ri+2+ ...
γ is a tunable parameter which lets the programmer decide between the balance of the focus on current rewards and future rewards.
One big challenge in tuning for Q-learning is finding the balance between exploring a lot to find good strategies and following the policy to refine the behavior of the neural network along the policy.
1.2.2
Policy Gradient
The policy gradient approach involves using the neural network itself as the agent. The state is fed into the neural network and a distribution over the action is predicted. The loss functions for these types of neural networks are much more complicated.
Originally, using an Actor-Critic approach [7] (which uses both policy gradient and even Q-learning to some extent) was favored in this thesis due to the demonstrated performance of Actor-Critic agents in many games. However, for the purposes of this thesis, Q-learning showed to be much more stable in dealing with the games we used because it was harder to act off-policy for policy gradient. This case of facing instability in policy gradients is discussed in Appendix A.
1.3
The Problem
Reinforcement learning has the ability to learn how to play games over time, but it is often difficult to actually tell the agent information about the game. Humans tend to share information with each other such as some situation to avoid in a game, an easy way to win, or how the internals of the game work. If thse internals of the game can be approximated, then the player can build a mental model of the game. This ability to build a model can be built possibly before playing the game for the first time. It is not completely clear how to give the agent this kind of information.
The approach to this problem that is taken in this thesis is through the creation of another model in addition to the agent which is referred to as the ”Oracle”. The Oracle is used to approximate the ”truth”, which is defined to be the actual states in the POMDP, as opposed to just the observations that the agent will normally see. This truth is not automatically generated and must be figured out for each game. The Oracle is trained through supervised learning with random traces of the game. The main idea is that the truth is a significant amount of information that will make the game much easier for the agent.
Chapter 2
Game Environments
Each of the environments in this game are POMDPs. Each of these environments have a large amount of information gathering and once the hidden truth is known, a winning strategy is trivial. In each case the hidden truth is static throughout an entire game.
2.1
Mastermind
Mastermind is a classic board game that was created in 1970 [6]. It is based on the early pencil-and-paper game called Bulls and Cows. In this game, there is a hidden code represented by 4 pegs, where each peg can take on one of 6 values. There are 64 different possible codes. The player acts by proposing a hidden code. The feedback to this proposed code is how many pegs are the correct value in the correct location and how many pegs are the correct value but not in the correct location. These feedbacks are the only observations that the player receives. This game is difficult for reinforcement learning agents because of how difficult it is to find the correct code and the fact that the reward is only given at the very end after the hidden code is found. Many random games will have to be played to figure out how to win the game. A model of the game could encourage an agent to discover how to play the game quicker through showing what the remaining options are or what options are most likely to be good options at the end of the game.
2.2
Zoombinis
Zoombinis is a series of puzzle computer games released in 1996 [1]. The specific game that is used in this thesis is the first level called ”Allergic Cliffs”. In Allergic Cliffs, the player is given a set of 16 ”Zoombinis”, which each have 4 different features that can take on 5 different values, and two bridges that lead from one cliff to another. These Zoombini features include the hair, eyes, nose, and feet. The goal of the game is to choose the correct bridge for each Zoombini since each Zoombini can only cross one bridge. Each bridge has some kind of boolean expression over the the Zoombini features that chooses which Zoombini can cross them. The other bridge is the not of the first bridge. The player loses the game if 6 mistakes are made. If all Zoombinis make it across, then the player wins. Unlike Mastermind where the reward can only be given at the very end, Zoombinis allows the creation of a nicer environment for reinforcement learning because a reward can be given after each Zoombini makes it across, around 50% of the time. The observations that are given in this game are whether or not a selected Zoombini makes it across a bridge.
Chapter 3
The Oracle
The main idea in this thesis is to create an ”Oracle” to represent the hidden state of a game to assist a reinforcement learning agent in playing the game. The Oracle is trained through supervised training on random traces of the game with the ”truth” being a mask on the full truth based on only what was discovered in that random trace.
3.1
Difficulties in Constructing an Oracle
The first game that was experimented with was Mastermind. The way that the hidden state was represented was by trying to predict for a given guess and observations what the feedback was. This seemed like a valid approach since actually choosing among the actions seemed difficult. This ended up being more like 2 different problems. Also no masking was necessary since in Mastermind the answer is revealed at the end of the game.
The first neural network design that was used was a single layer with ReLu acti-vation [9] and then another layer with two different softmax actiacti-vations [11] for half of the nodes each. For training, cross entropy loss was used. This configuration led to many issues with the main issue being that the network simply did not learn. The network would always predict the same distribution. Adding more layers before the multiple softmax layer and increasing the size of each layer did not add much
more than slightly modest improvements in terms of less loss, but the main problem remained.
The next attempts stemmed from the idea that the main issue was a data balancing problem. For each of the different possible class labels, the weight for the loss of each label was multiplied by the inverse frequency as a way of using balanced cross entropy. This had nearly no effect. The next idea was to use an idea for data balancing invented at Facebook called focal loss [5]. It is a loss function that takes class imbalances into account. However, focal loss also did not show promising results.
The next thought was that the game of Mastermind was just too hard in terms of complexity for the neural network to learn. Effort was shifted towards Zoombinis where the truth was which bridge each Zoombini belongs on. The same problem persisted in that the neural network could not predict the truth from a set of par-tial observations. This hinted that something was fundamentally wrong with the approach.
3.2
Binary Cross Entropy Loss
The solution to his problem was to frame the problem slightly differently. Instead of framing the problem as multiple multi-class problems, the problem was changed to being binary labels for every single label. This mindset puts more control towards the neural network being able to learn patterns. Instead of enforcing that there can only be one label for a certain class, the neural network needs to learn it by itself. Surprisingly, the neural network was able to learn much better with this approach.
The main change in architecture of the neural network is shifting from multiple softmaxes on the output to a sigmoid layer. During training the binary cross entropy loss function was used [2]. Now the neural network tries to find each label indepen-dently. In the case of Zoombinis, this would be stated as “Given the observations, what is the probability that Zoombini z is on the top bridge” instead of “what is the probability that Zoombini z is top and the probability that Zoombini z is bot-tom” predicted jointly. It is a subtly different problem that led to better results in
this problem. Originally only the Zoombini’s Oracle was able to work. Thus, the Zoombini Oracle was the only one that was used for experiments.
Mastermind’s Oracle continued to have problems and was not used for the next round of experiments. However later on through deeper inspection and comparison to the Zoombini’s Oracle, the ”truth” for Mastermind was not correct either. Previously, the observation was what was tried to be predicted. However, that is not the hidden state that drives the Mastermind game. Thus, the Oracle should be trying to predict the actual final answer. If the Oracle gets a strong prediction, then the winning guess should be obvious just like in Zoombinis. This change allowed the neural network to be able to actually learn because the objective is more clear and has more of a correlation to all of the previous observations. The predicted label did not appear as random as before since there was a clear target that was approached as observations were made.
Figure 3-1: The binary cross entropy losses for the Oracle in each game after training on random episodes.
Chapter 4
Using the Oracle
With an Oracle that can predict the hidden state of the POMDP game, we sought to develop a reinforcement learning agent that took advantage of the knowledge of the Oracle. The information that the Oracle learned through supervised learning was hypothesized to give an agent with the Oracle more information about the game than a vanilla agent. The Oracle should have figured out the game, but experiments did not show that the introduction of the Oracle added any value for the agent and was worth building.
4.1
Methods
Various methods were attempted to use the Oracle. All of them showed lackluster performance with some being much worse than the others.
4.1.1
Reward Shaping Oracle
The first idea was to use the Oracle to influence the actions of the agent through the reward that is given. As more observations are made, the Oracle should get closer to approximating the truth. If good observations are chosen then the Oracle would approximate the truth faster. Thus, the best observations would be the observa-tions that maximize entropy, where entropy is the Shannon Entropy [10] over the
probabilities that the Oracle predicts:
H(x) = −X
xi
p(xi) log p(xi)
The reward would be the difference in entropy from some starting state to the resulting end state. Over time the entropy should decrease and give the agent a positive reward in every step. Actions that give the Oracle more information would result in greater rewards since there would be a greater change in entropy.
The problem with trying to maximize entropy only is that the agent will run out of turns to figure everything out because the best action may not be an action that helps maximize reward. A balance needs to be found between discovering the most information and trying to maximize the immediate reward in order to create the best agent. The goal is to train the reinforcement learning agent to find this balance. By giving an entropy reward, the agent could be encouraged to take more ambitious information gathering steps instead of purely trying to gain the intrinsic rewards of the game.
4.1.2
State Transformation
The second idea is to use the Oracle to transform the state that is inputted into the agent. The Oracle has the power to update the state with more assumptions and enhance the original input state of past observations with a prediction of the future. This should empower the agent to make more intelligent decisions about the future just like predictive analytics do for humans every day.
The main question lies in when to train the Oracle. The two options are to “pre-train” the Oracle with random traces before training the agent or to train both the Oracle and the agent jointly.
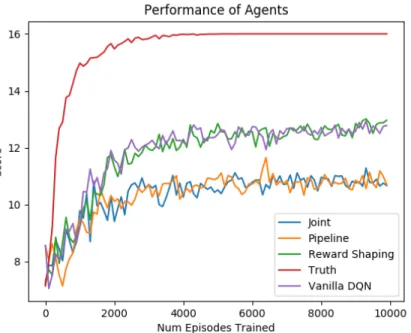
Figure 4-1: Performance of DQN Agent with different uses of the Oracle
4.2
Experimental Results
As the Oracle was not able to be trained for Mastermind until after Zoombinis results did not show to be favorable, only Zoombinis was used for the experiment. Zoombinis is a much simpler game than Mastermind. The experiments were run with a set of 1000 training games for the Oracle, 10000 training games for the agent, and a total of 1000 testing games. The same games were used for every experiment. While each of the agents was training, a measurement on the testing set was taken after every 100 games of training for the agent.
The results of each of the experiments are shown in Figure 4-1. Vanilla DQN is the original Deep Q Network without any changes. Pipeline refers to pre-training the Oracle and then using it to transform the input to the agent. Joint refers to training the Oracle jointly with the agent. Reward Shaping is when the Oracle’s entropy is used to define an additional reward for the agent. Truth is the unrealistic scenario of simply giving the agent the hidden state of the game along with observations. Clearly, the Vanilla DQN has great performance compared to the other viable approaches.
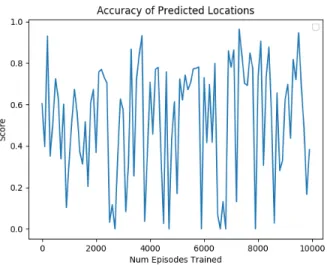
Figure 4-2: Accuracy of the Oracle when trained jointly with the agent
achieve around the same score. Likely what happens is that the rewards from the entropy are ignored by the agent as they are not useful enough. On closer inspection after running the experiment, it was a common occurrence for the entropy to increase after more observations were made. It is unclear how to remedy this issue since the entropy is supposed to only decrease as more observations are made. However, an action that drastically revolutionizes the Oracle’s prediction should also be rewarded well, although it currently was not.
Both of the approaches that used the Oracle to transform the state did not perform as well as Vanilla. As shown by the accuracy of the Oracle when trained jointly in Figure 4-2, it was difficult for the Oracle to be able to learn when trained jointly. The measured accuracy of the pre-trained pipeline approach was on average around 0.93 so it is unclear why that was not performant. The accuracy of the Oracle was measured on a trace of a game by the argmax of the predicted label of the network for each bridge as compared to the masked truth of what should be known by that point in the game. The performance of ”Truth” implies that the Oracle that was used was possibly just not strong enough. If more work is placed in creating a better Oracle, the Pipeline or Joint approaches may be more viable. One bottleneck for this thesis was a lack of computational resources so larger networks could prove more powerful in solving this.
Chapter 5
Conclusion
Overall, the results of these trials were not great. It seems that it is difficult to create a good Oracle. Once a good Oracle is created and the truth can be properly approximated, then there is promise in improving the DQN with the use of an Oracle. Additionally there are various other paths that can be taken with the Oracle. Other uses can possibly be to try to learn “options” with some Oracle and assist the agent in playing the game through the creation of these “options”. There may be other creative uses of the Oracle that could also prove useful. However, the current uses of an Oracle that were tried in this thesis did not show favorable results. There is hope that a stronger Oracle could mirror the performance of giving the agent the truth.
Appendix A
Unstable Policy Gradient
In the Zoombinis game, it was very common for the reinforcement learning agents to repeatedly make duplicate actions and never make progress in learning, especially for policy gradient. To mitigate this issue, the concept of ”forbidding” actions was added. In the normal game there are several actions that are forbidden such as trying to send a certain Zoombini across a bridge after it has already made it across some bridge. For a normal player playing the game, it is obvious that the move is disallowed, but it is not so simple to tell a reinforcement learning agent that it cannot make an action. Originally policy gradient was used for this thesis so all of the probabilities were predicted for every action, even ones that were not able to be used. One way to mitigate this problem was to set the probabilities to zero for any forbidden action and then to normalize the vector with the new probabilities. However, over time the probabilities for valid actions would approach zero in favor of a forbidden action with a probability of 1.0. Thus, when probabilities were set to zero for all of the forbidden actions (including the probability of 1.0), the remaining probabilities would be 0 and choosing a probability would give undefined behavior because the probability values were needed to compute the loss. Often what would happen is that the gradients for backpropagation would start to approach infinity and cause the neural network to degrade once the unstable gradients would occur. The solution was to use Deep Q Learning instead of Policy Gradient because it was much more straightforward to forbid moves by setting the Q value to negative infinity when making a decision.
Bibliography
[1] Brøderbund. Logical journey of the zoombinis. [CD-ROM], 1996.
[2] Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. MIT Press, 2016. http://www.deeplearningbook.org.
[3] Leslie Pack Kaelbling, Michael L. Littman, and Anthony R. Cassandra. Planning and acting in partially observable stochastic domains. Artif. Intell., 101(1-2):99– 134, May 1998.
[4] E.L. Lehmann and G. Casella. Theory of Point Estimation. Springer Texts in Statistics. Springer New York, 2003.
[5] Tsung-Yi Lin, Priya Goyal, Ross B. Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection. CoRR, abs/1708.02002, 2017.
[6] Mordecai Meirowitz. Mastermind. [Board Game], 1970.
[7] Volodymyr Mnih, Adri`a Puigdom`enech Badia, Mehdi Mirza, Alex Graves, Tim Harley, Timothy P. Lillicrap, David Silver, and Koray Kavukcuoglu. Asyn-chronous methods for deep reinforcement learning. In Proceedings of the 33rd International Conference on International Conference on Machine Learning -Volume 48, ICML’16, pages 1928–1937. JMLR.org, 2016.
[8] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin A. Riedmiller. Playing atari with deep reinforcement learning. CoRR, abs/1312.5602, 2013.
[9] Vinod Nair and Geoffrey E. Hinton. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, ICML’10, pages 807–814, USA, 2010. Omnipress.
[10] C. E. Shannon. A mathematical theory of communication. SIGMOBILE Mob. Comput. Commun. Rev., 5(1):3–55, January 2001.
[11] Richard S. Sutton and Andrew G. Barto. Introduction to Reinforcement Learn-ing. MIT Press, Cambridge, MA, USA, 1st edition, 1998.
[12] Richard S. Sutton, David Mcallester, Satinder Singh, and Yishay Mansour. Pol-icy gradient methods for reinforcement learning with function approximation. In In Advances in Neural Information Processing Systems 12, pages 1057–1063. MIT Press, 2000.