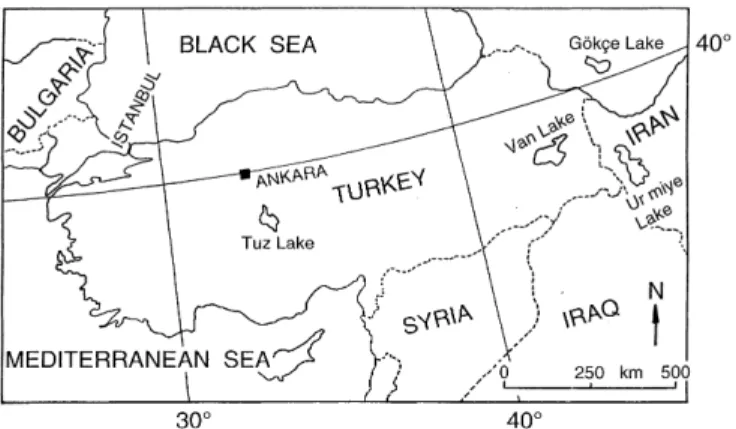
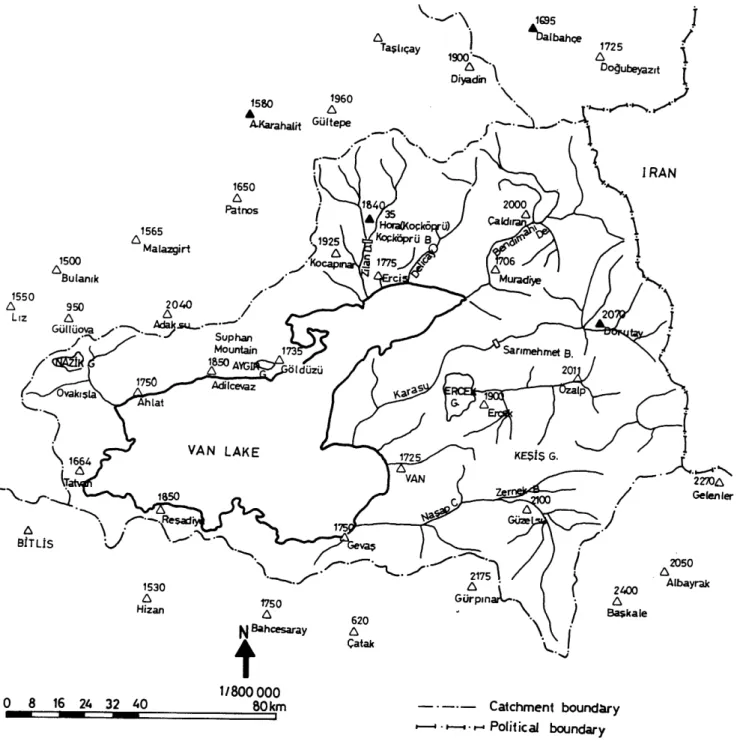
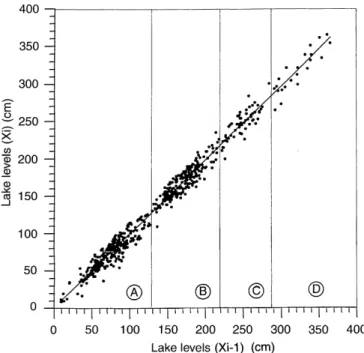
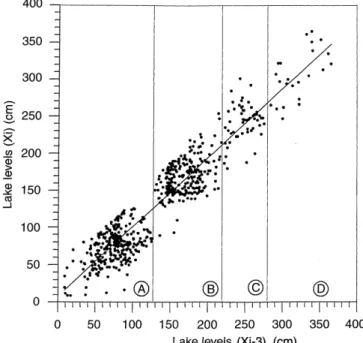
Cluster regression model and level fluctuation features of Van Lake, Turkey
8
0
0
Texte intégral
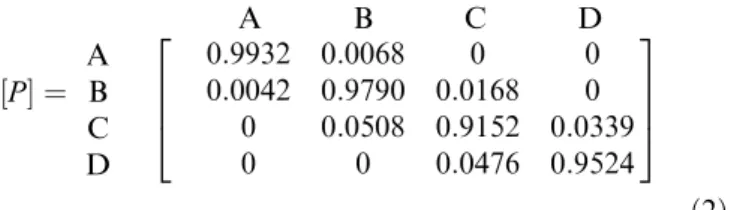
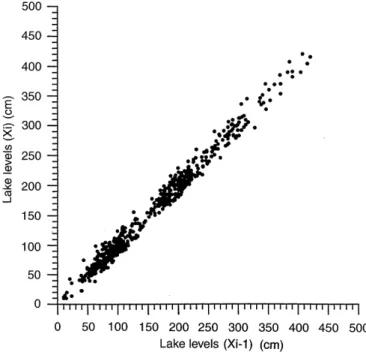
Figure
+3
Documents relatifs