FReM – scalable and stable decoding with fast regularized ensemble of models
Texte intégral
Figure
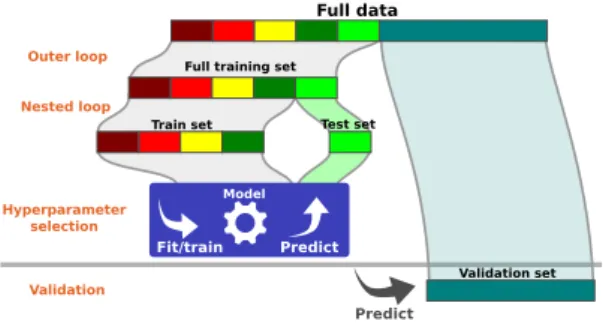
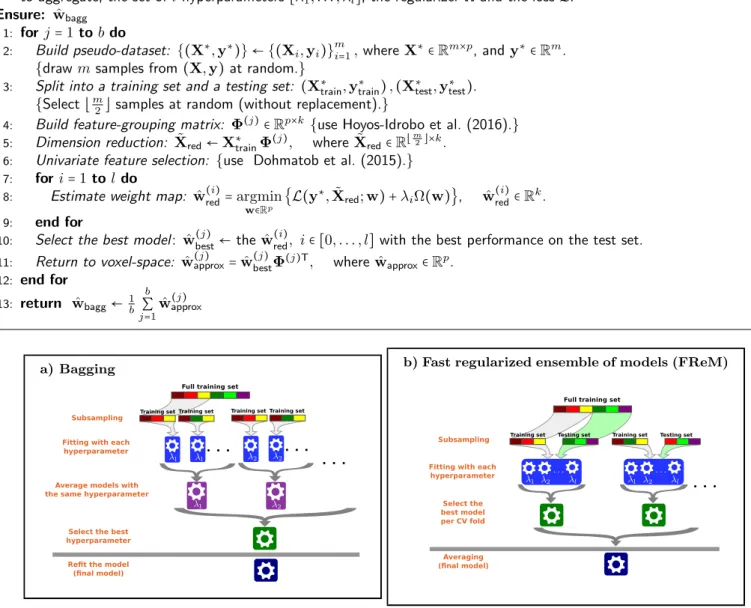
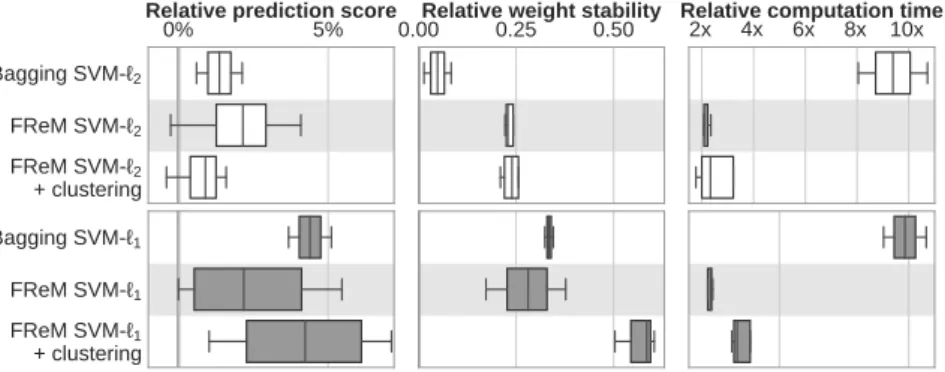
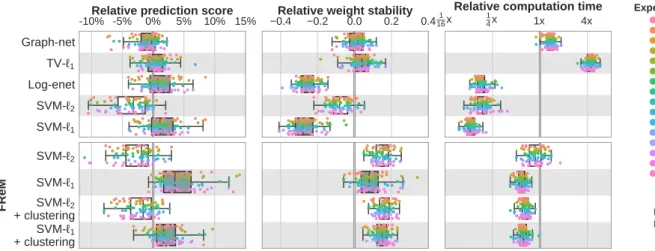
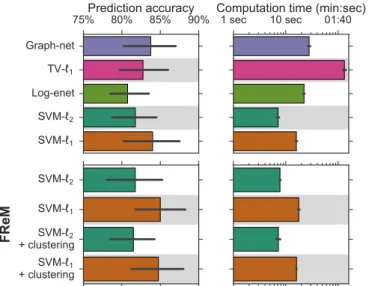
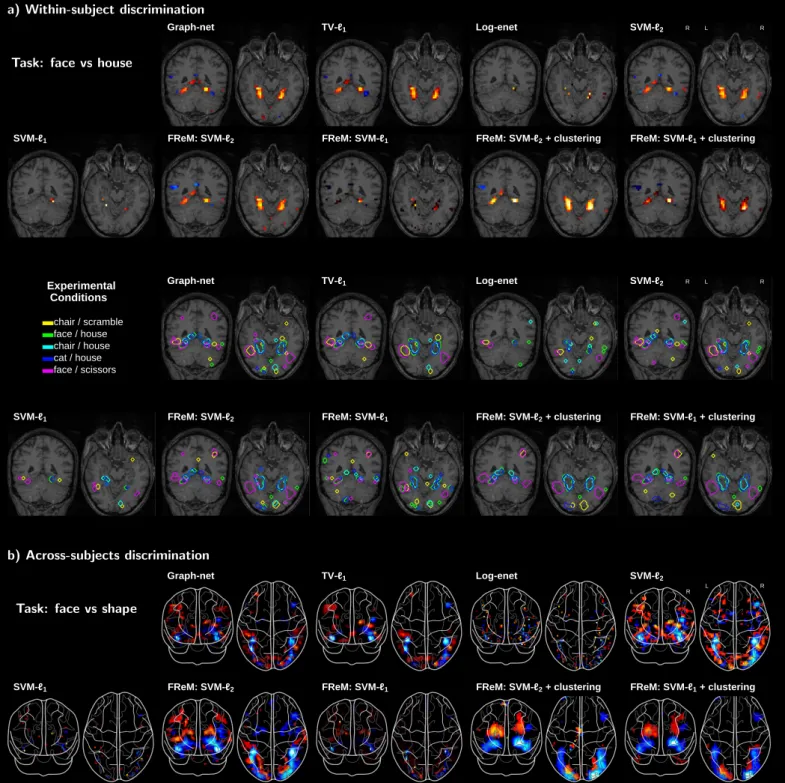

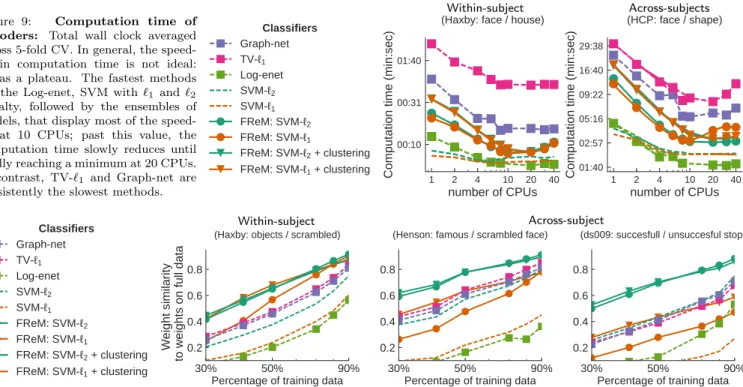

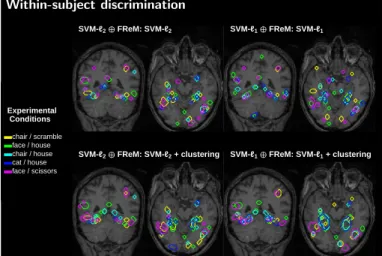
Documents relatifs
Give examples of complete, redundant and indeterminate systems in Whittaker classification
The study's objectives were on the one hand to identify the spatial distribution, and on the other to deduce the traditional knowledge regarding fodder tree
This thesis, motivated by the kind of optimization problems arising from geostatistical data analysis, makes two types of con- tribution: it develops new algorithms which solve
In this respect, projective clustering and clustering ensembles represent two of the most important directions: the former is concerned with the discovery of subsets of the input
The reduced model for a non-axisymmetric ellipsoid and the model of Busse ( 1968 ) for a spheroid agree within 0.3 %, leading to a mean differential rotation amplitude of the order of
- measure the principal indicators of health status, medical practices during pregnancy and delivery, and perinatal risk factors; their changes from earlier national
Circles indicate maximum LL of the given matrix, and triangles indicate the best fitting parameters to the real data (that were also used to generate the simulated data).. In this
The machines of this class having a greedy behaviour are united into a sub- class whose instances are called preautomata. Machines of the subclass are used for modelling
