Stress Testing Engineering: the real risk measurement?
Texte intégral
Figure





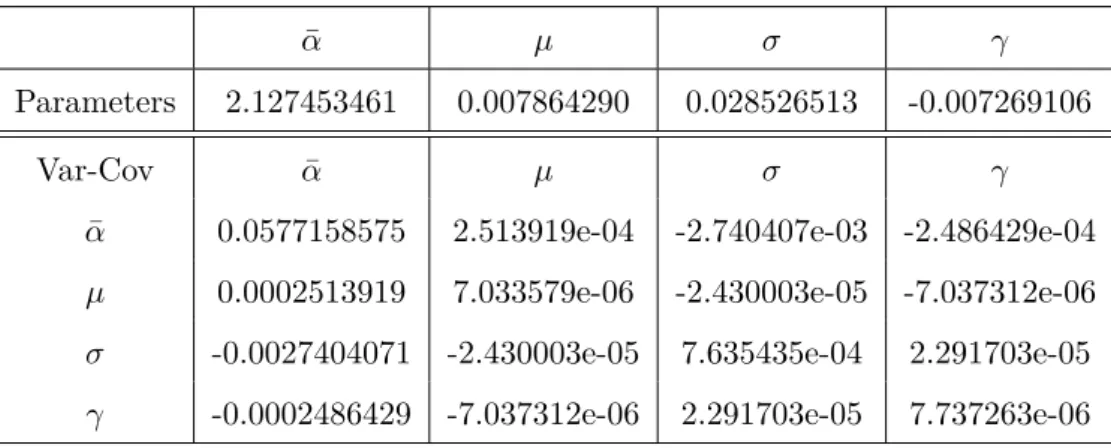
Documents relatifs
Although mies are well established to identify risk potential on the base of the quantity of dangerous substances (Airnexe I of the Councii Directive 96/82/EC), there is no
They carried out a comparative test on an indicator and a model applied to three small catchment areas in Brittany (France). The indicator in this case is the nitrogen balance and
Distribution-based risk measures with this convexity property are characterized in Section 7: As shown by Weber (2006) and Delbaen, Bellini, Bignozzi & Ziegel (2014), they
When the condition (9) is met, the CAPM produces a maximum pricing error larger than that of the basic model which ignores the trade-off between risk and return. It is thus so
The second contribution of this paper is a characterization of the Lebesgue property for a monetary utility function U in terms of the corresponding Fenchel transform V introduced
keywords: Value-at-Risk; Conditional Value-at-Risk; Economic Capital; Credit Risk; Gauss hypergeometric function; Beta-Kotz distribution..
In the reality, the late implementation of the legal framework concerning the prevention of this type of risk, the lack of control of urban development in flood-prone areas and
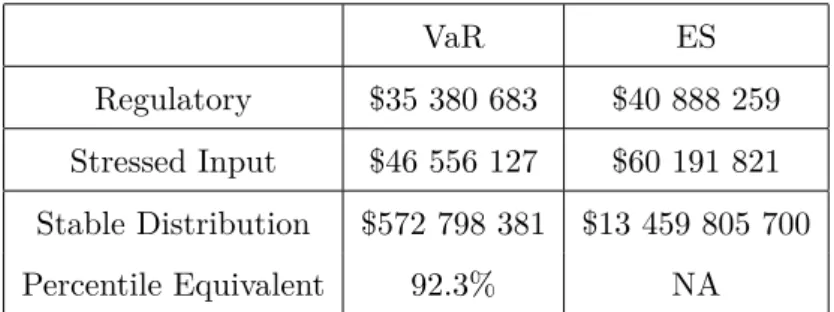
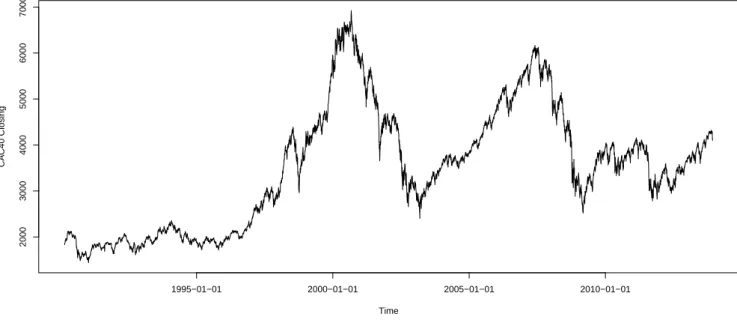
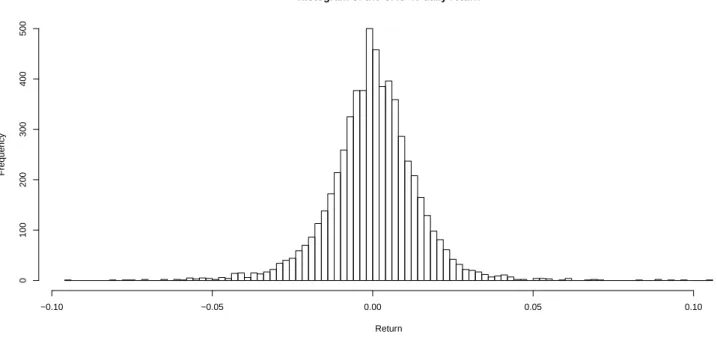
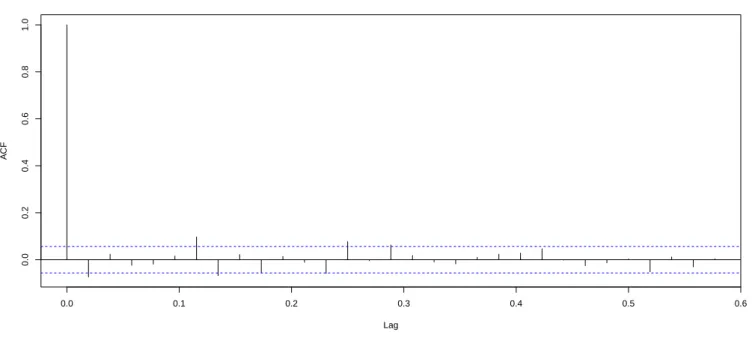
We show that the Risk Map can be used to validate market, credit, operational, or systemic risk estimates (VaR, stressed VaR, expected shortfall, and CoVaR) or to assess the
