Prédiction de performance d'algorithmes de traitement d'images sur différentes architectures hardwares
130
0
0
Texte intégral
Figure

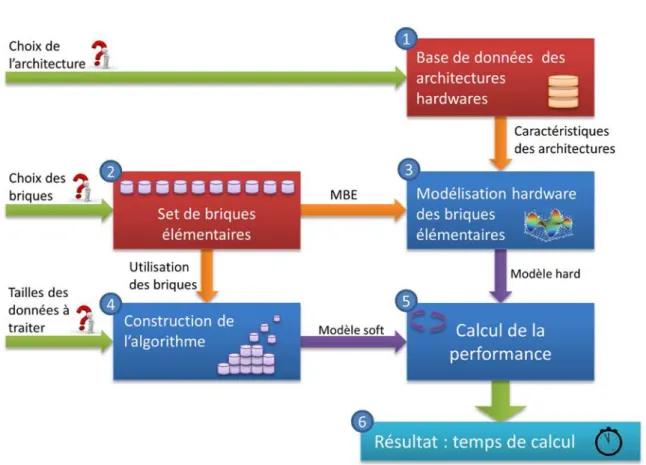
![Figure 14 Méthodologie d’évaluation de la performance par des concepts algébriques[29]](https://thumb-eu.123doks.com/thumbv2/123doknet/14707765.566702/42.892.309.615.780.998/figure-méthodologie-évaluation-performance-concepts-algébriques.webp)
+7
![Figure 15 Classification des méthodes d’évaluation de la performance [15]](https://thumb-eu.123doks.com/thumbv2/123doknet/14707765.566702/44.892.248.664.215.523/figure-classification-méthodes-évaluation-performance.webp)
![Figure 16 Exemple d’arbre M5’ pour l’analyse de performance [35]](https://thumb-eu.123doks.com/thumbv2/123doknet/14707765.566702/45.892.192.675.221.692/figure-exemple-arbre-m-l-analyse-performance.webp)
![Figure 26 Procédure d’estimation du modèle de prédiction d’un software [43]](https://thumb-eu.123doks.com/thumbv2/123doknet/14707765.566702/53.892.234.634.592.825/figure-procédure-estimation-modèle-prédiction-software.webp)


Documents relatifs