Navigation, perception et apprentissage pour la robotique
Texte intégral
Figure
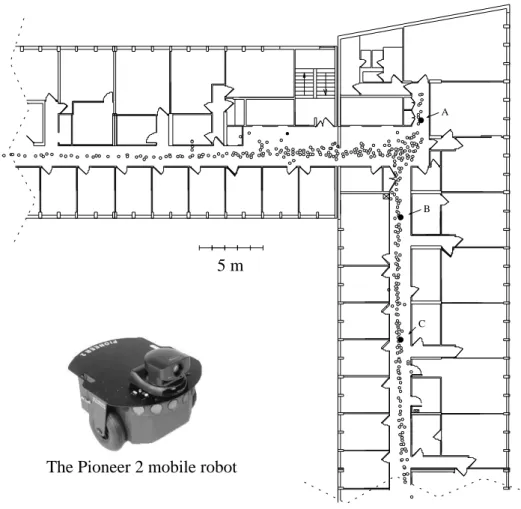

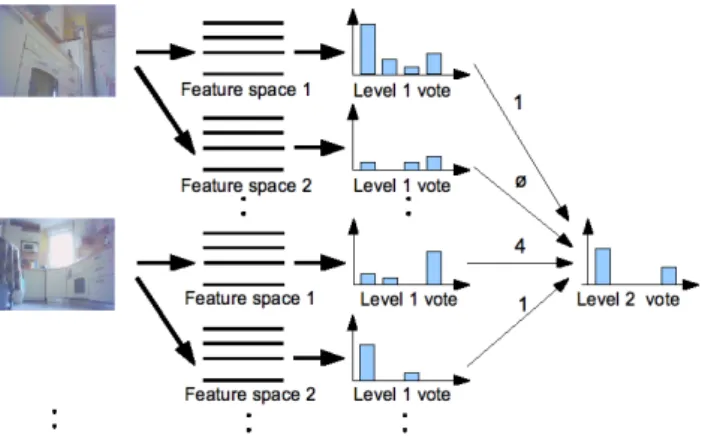


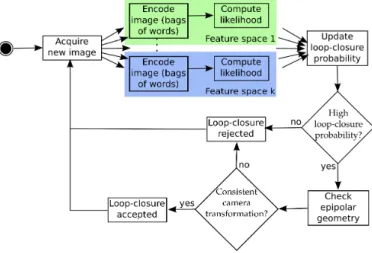

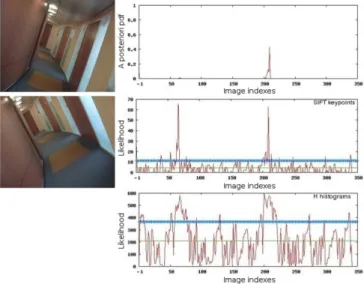

Outline
Documents relatifs
Tout simplement, la navigation du robot mobile dans la première méthode se fait par un simple calcul de l’angle de braquage par la fonction du champ de potentiel basée sur un modèle
Pour les solutions de navigation avec un seul IMU, le recours aux données d’attitude de la trajectoire de référence ainsi que l’ajout du modèle stochastique de la dynamique du
Dans cette thèse nous étudions le mouvement actif d’un capteur binaural pour la localisation d’une source sonore.. Ce travail s’inscrit dans la thématique de la perception active
Dans cette thèse nous étudions le mouvement actif d’un capteur binaural pour la localisation d’une source sonore.. Ce travail s’inscrit dans la thématique de la perception active
Une pyoverdine modèle (pvdC7R12), utilisée dans plusieurs études antérieures, et une plante modèle (A. thaliana), ont également été intégrées à ce travail pour
Cette notion de chaos, liée à la physique d'un problème, est indépendante du modèle mathématique utilisé et encore plus de la méthode numérique utilisée pour résoudre ce
Afin de valider notre modèle nous avons utilisé des traces réelles provenant d’une plate-forme Cloud et pour compléter cette validation nous avons également utilisé des
Comme nous l’avons énoncé dans l’introduction, nous proposons dans cette thèse un modèle multi-agents réactifs pour la navigation.. Dans ce contexte, nous nous concentrons
