Cloud simulation
29
0
0
Texte intégral
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
(12)
(13)
(14)
(15)
(16)
(17)
(18)
(19)
(20)
(21)
(22)
(23)
(24)
(25)
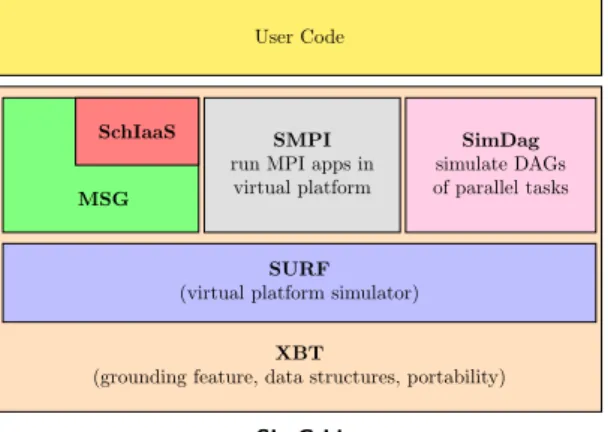
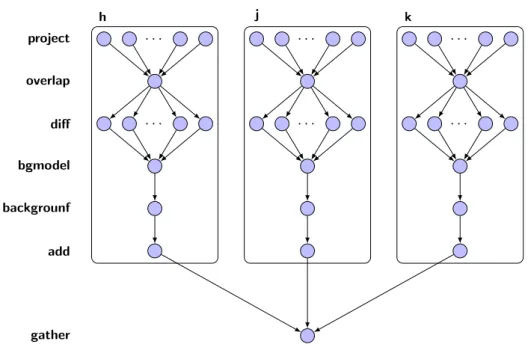
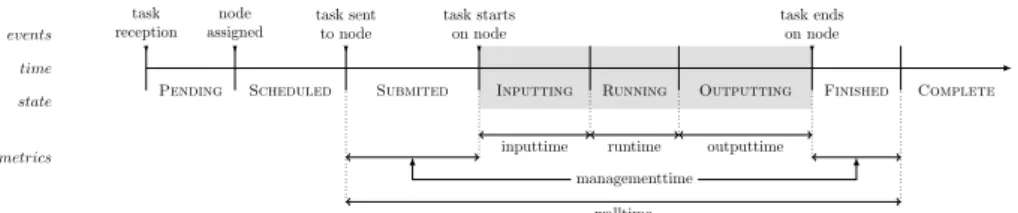
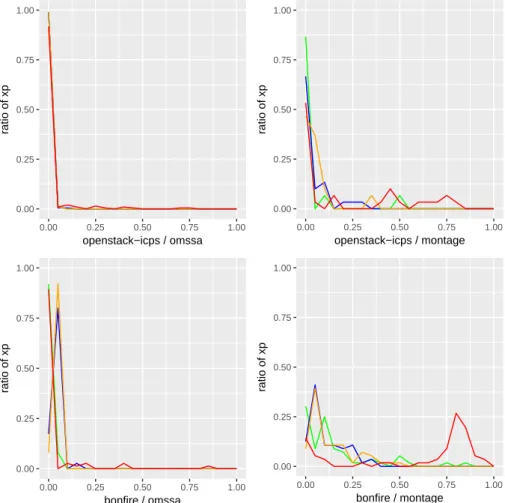
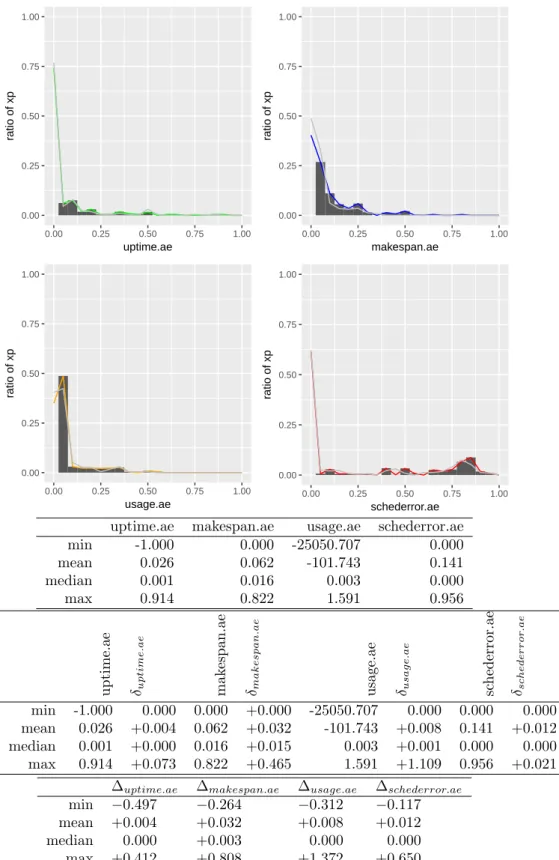
Figure



+7


Documents relatifs
The literature on continuous-state and continuous-time control on networks is recent: the first two articles were published in 2012: control problems whose dynamics is constrained to
Thèse de Doctorat Unique présentée par : ELEGBEDE MANOU Bernadin pour l’obtention du grade de Docteur de l’Université d’Abomey-Calavi Page 152 Table XVII: Result of
The topic of ecosystem services, ecological services, environmental services (ES) and payments for environmental services (PES) has recently become the main reference for
- Travel characteristics: number of trip undertaken, trip distance, departure time, travel purposes, travel mode, travel day - the day of week that travel was
Moreover, it is interesting to note that there exist only two other experimental data sets allowing such an analysis as the present one. One data set ~comprising about 400 events!
Dans le cancer du sein, au-delà de l’apport du 18 F-FDG comme traceur du métabolisme tumoral dans le diagnostic initial des cas difficiles (seins denses ou
Then, there are two natural ways to define a uniform infinite quadrangulation of the sphere: one as the local limit of uniform finite quadrangulations as their size goes to
Nachr. Mertens, Ueber einige asymptotische Gesetze der Zahlentheorie, J. Montgomery, Fluctuations in the mean of Euler’s phi function, Proc. Titchmarsh, The theory of the
